生成对抗网络( Generative Adversarial Networks,GANs ),由 2014 年还在蒙特利尔读博士的 Ian Goodfellow 引入深度学习领域。2016 年,GANs 热潮席卷 AI 领域顶级会议,从 ICLR 到 NIPS ,大量高质量论文被发表和探讨。 Yann LeCun 曾评价 GANs 是“20 年来机器学习领域最酷的想法”。
GANs 在一个月前的 NIPS 大会的会议大纲被提到逾 170 次,Facebook、Open AI 等 AI 业界巨头都纷纷加入了对 GANs 的研究,连 Apple 公开发表的第一篇AI 论文,就是关于利用GANs 来训练AI 图像识别能力。
由此可见,从学术界到工业界,GANs 席卷而来。
Nikolai Yakovenko 是一名俄罗斯出生的美国人,现在 Twitter 供职,从事 AI 的研究。不久前,他写了一篇博文,阐述了他的看法: GANs 将改变世界。
InfoQ 梳理了 Nikolai 的观点,整理成文,带领读者来展望 GANs 将会给世界带来什么样的变化。
Nikolai 认为,GANs 将是深度学习中的下一件大事,它将会改变人类对世界的看法。
具体来说,对抗训练将改变我们思考如何教会 AI 执行复杂的任务。在某种意义上,它们学习如何模仿专家。一旦专家(判别器)无法区分你的生成和正在模仿的生成结果之间的差异,那就表示你已经掌握了足够的任务。这种可能不适用于大型任务,比如撰写一篇论文,因为每个人最终写出来的都有所差异。但是,对抗训练将是在中型产出方面取得进展的重要工具,例如书写句子和段落。它已经是真实感图像生成的一个关键。
GANs 的基本原理是什么?
Adit Deshpande 曾用清楚直白的语言来阐述 GANs 的基本原理:
GANs 的基本原理是它有两个模型:一个生成器,一个判别器。判别器的任务是判断给定图像是否看起来“自然”,换句话说,是否像是人为(机器)生成的。而生成器的任务是,顾名思义,生成看起来“自然”的图像,要求与原始数据分布尽可能一致。
GANs 的运作方式可被看作是两名玩家之间的零和游戏。原论文的类比是,生成器就像一支造假币的团伙,试图用假币蒙混过关。而判别器就像是警察,目标是检查出假币。生成器想要骗过判别器,判别器想要不上当。当两组模型不断训练,生成器不断生成新的结果进行尝试,它们的能力互相提高,直到生成器生成的人造样本看起来与原始样本没有区别。
这个概念主要就是让这两个网络相互竞争,以便在一段时间后,两个网络都不能相对另一个网络取得更进一步的进步。或者生成器变得如此有效,以至于对抗网络即使有无限的时间和海量的资源,也无法区分真实的样本和合成的样本。
细节很有趣,但我们暂且不表。GANs 用于绘制图像,给定图像类别和随机种子:
给我画出一只啄木鸟,但它不能是我之前给你看过的任何一只啄木鸟。
(点击放大图像)

由StackGAN 生成的合成鸟,已开源可用。
从数学方面来讲, Google Research 的科学家使用 GANs 发明了一种“加密”的协议。生成器 Alice 将消息传递给 Bob,使用了卷积网络和共享的密钥来加密消息。Eva 扮演了对抗的角色。它访问加密的消息,但不共享密钥。Eva 训练网络来区分噪声和 Alice 的加密信息,但不能区分两者。
现在为时尚早,我不知 GAN 以比前馈 LSTM 更好的方式写出扣人心弦的短文本的公众演示。虽然如果以前馈 LSTM(如 Karpathy 的字符 RNN )作为基线,很难想象不会有人很快创建 GAN 来改善类似 Amazon 产品综合评论的东西,给产品进行评级用。
人类通过直接反馈学习
对我来说,对抗过程听起来接近人类学习的过程,而不是强化学习(Reinforcement Learning,RL)。
强化学习是基于最大化(平均)最终奖励的训练。强化学习可以在不同的情景或者环境下学习采取不同的行动,以此来获得一个最佳的强化信号值。在强化学习中,通过强化信号你只能知道在一个特定的事件中所采取的方案的实际效果是好还是坏,强化学习不会告诉你一个最佳的方案。就比如说强化学习不会像前文提到的卷积神经网络那样,对于每一张特定输入的图片会给出一个与之对应的分类。强化学习的另一个比较独特的部分在于 agent 的行动将会影响后续接收的数据。比如说当一个 agent 左移而非右移的时候就表明该 agent 下一次在该环境中会接收不同的数据。
强化学习在 20 世纪 90 年代的人工智能、机器学习和自动控等领域得到了广泛研究和应用。也是 DeepMind 的 AlphaGo 的一个重要组成部分, DeepMind 甚至使用强化学习来节省 Google 数据中心冷却所耗费的费用。
可以想象得出,强化学习之所以能在数据中心发现优化方案,因为奖励函数(即保持最大温度的同时节省资金)被合理定义了。这也许是好莱坞之外罕见的一个现实世界问题完全参数化一个游戏的例子。
对于较少的游戏问题来说,什么是奖励功能?即使是像驾驶这样的类似游戏的任务,目标也不是真的很快到达,或者在虚线内尽可能接近。很容易定义消极的奖励(损坏汽车、以不合理的加速度吓跑乘客),但是很难正确定义在驾驶期间积累的积极奖励。
有样学样
我们如何学习类似手写的东西?除非你去一个非常严格的小学,因为这个过程不是为了正确地书写的奖励优化。更可能的情况是,你跟着老师在黑板上写出来的字迹来书写,直到你真正掌握了书写技巧。
你的生成器网络绘写出了字母,而你的判别器网络学会注意你所书写的和书写规范的差异。

小学三年级的对抗训练
你自己最严厉的评论家
五年前,Nikolai 在哥伦比亚大学橄榄球赛中头部受到重击,导致了身体右半侧瘫痪。两个星期后他出院了,回到位于 Brooklyn 的公寓,开始自学书写。

图为 Nikolai2012 年五月重新自学书写的字迹。
Nikolai 的大脑左半球受到了严重的伤害,他“忘记”了如何操作右臂。但是,大脑其他部分并没有受到伤害,因此,他知道什么样的字迹看上去是正确的。也就是说,他有一个很槽糕的生成书写模型,但是他的判别器网络仍然保持完好。
Nikolai 曾经开玩笑表示,由于这次意外事故,他学会了一个崭新的、更好的书写方式。无论如何,他通过自学很快学会了重新书写,写出来的笔迹风格和以前比较接近。
我们并不知道人类大脑是如何以“Actor-Critic”算法来进行学习。这真是一个很可爱的类比呢。但是,当我们能够尝试新事物,并得到专家的即时反馈时,我们的学习会更有效。
当我们学习编码或攀岩时,从专家那里接收“beta”时,进步会更快。直到有足够的经验作为自己的内部评论家,当一个好的外部评论家纠正每一个低级错误时,更容易训练你的大脑的生成器部分。即使有一个内部评论家,学习一个有效的生成器需要仔细的练习。我们不能将自己的个人训练切换到 Amazon AWS 的 GPU。
焚烧轮船?
GANs 能够解决一些问题。它们用于增加“逼真”的效果,例如使生成的图像边缘锐利,即使所生成的动物图像不一定正确。

Miles Brundage 在推特中说: GANs 学习生成类似动物的对象,但生理结构上并不正确。
将生成网络与一个有价值的对手竞争,迫使它做出艰难的选择。正如一个同行所说,有一个选择,你可以画绿鹦鹉,或者你可以画蓝鹦鹉。但它必须是两者中的一个。在没有敌对组件的真实鹦鹉上训练的监督网络将倾向于绘制某种平均的蓝色和绿色。因此模糊线。对抗网络必须画绿鹦鹉,或者蓝鹦鹉。或者它可以从{蓝色,绿色}鹦鹉空间的概率分布中采样。但它不会绘制具有一些中点颜色的图像,不存在于真正的鹦鹉分布。这是现在的前鹦鹉的分布。
Nikolai 的同行最近撰写了他关于GANs 的想法,透露了对GANs 的融合或推广能力的悲观情绪。
在某种程度上,这是因为跷跷板的方式:训练生成器一段时间,然后再训练判别器一段时间,如此循环——这并不能保证会趋于一个稳定的解决方案,更不是最优解决方案。正如 Alex J.Champandard 的这条推文中所说明的那样。
现在让我们忽略这些问题,做一点梦想。鉴于LSTM 模型能够写出连贯的产品评论、图片说明,并出现了模仿川普总统口吻的推特(奇怪的是,选举之夜后沉寂了)。
这是否表明,即使一个微小的认知判别器可以提高这些任务的性能?我们可以使用现成的生成器,并要求判别器在提供的前20 个选择中进行选择,假设LSTM 产生具有某种随机性的输出。难道不是@DeepDrumpf 推特背后的人在暗中操纵吗?
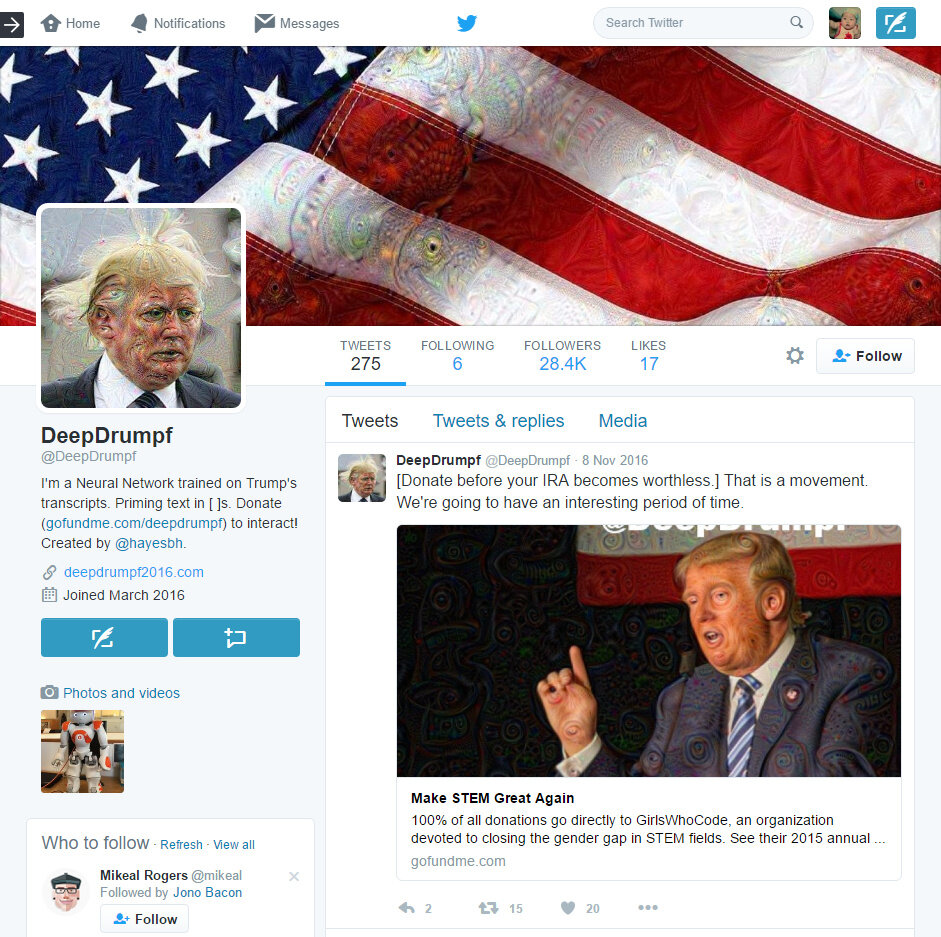
生成器或判别器:哪个知道最好?
一个自然的问题出现了:哪个网络内化了对生成器或者判别器问题的理解?是学生还是老师?谁更了解书写字母?
在现实世界中,它可能是老师,但在上面的例子中,我认为它必须是学生。产品评论生成器的判别器可以简单地通过标记人们通常不会做出的语法错误来使其自身有用。需要更多什么样的技能?学习像米开朗基罗一样绘画?或仰望西斯廷教堂?
据了解, Prisma 采用对抗框架为每一个风格训练生成网络。这就是大多风格如何生成清晰线条的原因。他们要是能够训练 GAN 一段时间,这样就能识别出照片中的阴影,为它们绘制出不同的颜色,没准儿会得到一个抽象派风格的作品。如果它处理光影正好,那么结果非常惊艳。

以这种思路很自然得出结论,就是生成 - 对抗方式赋予了 AI 运行实验和 A/B 测试的能力。AI 创建一个完全功能的生成解决方案。然后,它收集这个生成器与黄金标准相比有多好的反馈,或其它 AI 正在学习复制,或已经内化的反馈。你不必设计一个损失函数。这可能需要一段时间,但 AI 会找出自己的评估规则。
清楚什么时候收手,什么时候弃牌
Nikolai 写下这篇博文,自己并没有训练对抗网络。他表示正在等待别人显著改进 GANs 的性能,最好是文本生成问题。他预测,不久将会出现人人接受的技术,能够得出足以令人信服的结果。GANs 技术的进步,正如长江后浪推前浪。
Nikolai 说,他应该为今年的年度扑克计算机大赛花点时间来完善他的德克萨斯扑克AI“PokerCNN”。代码是2017 年1 月13 日。
对于明年的比赛,他计划增加一些对抗训练。不难想象,对抗性的训练可能有助于学习一个良好的扑克策略。特别是如果有一个强大的黑箱扑克AI 来竞争。
由于这个目标是学术,Nikolai 的扑克AI 代码已经开源,你可以尝试这个项目。
对GANs 的展望
要问AI 研究人员他们下一个大目标是什么,他们很可能会提到语言。我们真的希望在语音和图像识别方面取得惊人的进步,在其他领域中,还可以帮助计算机更有效地解析和生成语言。
AI 将会化身为新的移动应用。投资者在投资之前,将会关心管理层的 AI 战略目标;而警惕那些没有风险投资的那些公司。
关于这一点,我们希望能有一个快乐的、健康的、富有成效的 2017 年。不要被一个槽糕的问题羁绊,因为有那么多很好的难题等待被探索,没有人可以尝试所有的解决方案。
感谢杜小芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




