众所周知,技术能力的评价技术求职者的重要的一项指标。但是,求职者的面试表现到底是如何被判定的呢?怎样的面试分数统计才能更加靠谱地衡量求职者的真实水平呢?美国的在线技术面试平台 interviewing.io 通过分析海量数据,给出了自己的答案。
1 为什么面试数据能进行对比分析?
面试官和面试者通过我们的平台进行沟通时,他们面对的是一个协作的编码环境,可以进行语音、文字聊天,以及通过白板来直接讨论技术问题。面试官通常来自不同的大公司,比如 Google、Facebook 或 Yelp,还有专注于工程的新兴公司,例如 Asana、Mattermark、KeepSafe 等。
每一次面试后,面试官会对面试者进行全面打分,包括其技术能力。技术能力的打分范围是 1~4 分,1 分代表“资质一般”,而 4 分代表“非常棒!”(你可以在这里看到反馈)。在我们的平台上,通常 3 分及 3 分以上就意味着这个面试者能力不错,可以进行下一轮面谈。
这时候,你可能会说,这听上去还不错,但也没什么特别的吧?很多公司都将这类数据收集在它们的渠道之中。而我们的数据与众不同的是:同一位面试者可以进行不同的面试,每次和不同的面试官或者不同的公司进行面试,这就可以进行一定程度可控的、有趣的对比分析。
2 为什么你的面试表现波动不稳?
我们的数据显示:同一个人在一次面试中的表现,其数据有相当大的波动,这很让人惊讶。请先来看一个图直观感受一下。在下图中,每个 ICON 代表一个参加了 2 次及 2 次以上面试的面试者的平均技术分数。Y 轴表示其表现的标准差,数值越大,代表这个面试者的表现越不稳定。鼠标悬停在图中每个 ICON,你可以深度研究面试者的每次表现。(数据来自 2016 年 1 月的 299 份面试,去掉了分数小于 2 的面试记录。)
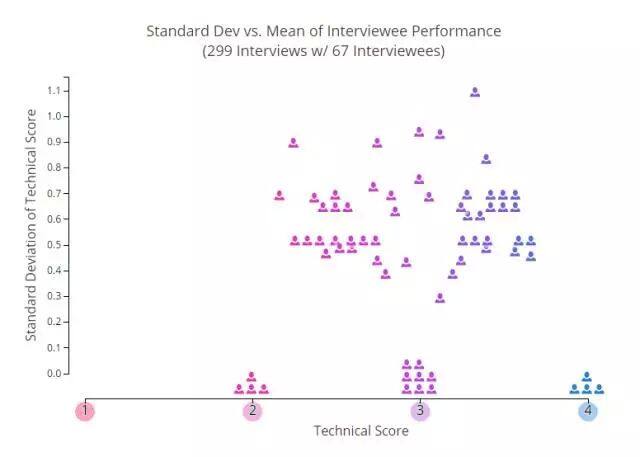
面试表现的标准差和平均值
(回复关键词「面试」查看原文,可以体会鼠标悬停在图表上的动态效果)
正如你所看到的,大约25% 面试者的表现非常稳定,其余的却布满了整个图(即非常不稳定)。我们非常好奇,波动性是否随人的平均分数而变化。换句话说,是实力较弱的参与者比实力更强的波动更为剧烈吗?答案是否定的——当运行标准差与平均值回归,我们想不出任何有意义的关系(R2~ = 0.03),这意味着人们布满整张图(即非常不稳定),不管他们有多强的实力。
- 许多人至少得到一次 4 分也至少得到一次 2 分。
- 看一看较高分区域范围(3.3 分或者更高),变化是在合理范围内的。
- 看一看“平均”表现者(2.6~3.3 分),数据看上去就很混乱不定。
如果是我,需要根据这些数据作出一个决定,聘用哪一位面试者,就是管中窥豹了。那就好像是,欣赏墙上的油画,或者挑选酒窖里的好酒,甚至可能只是看到沙发的背面而已,太主观随意了。
正因如此,你可能会说,无论什么原因,这样来比较技术分数都是错误且幼稚的,至少有种情况,对同一个面试者,一个面试官可能打 4 分而另外一个面试官可能打 2 分。我们在本文的附录中探讨了这个问题。这个问题确实需要讨论。然而我们大多数面试官都来自非常有实力的工程品牌公司,为了确保品牌实力,他们不会改变面试者面试表现的不稳定性,也不会修改面试官的打分。
那么,真实生活中,你要作出决定是否要招聘某个人时,你可能需要尽最大努力避免两件事——错误肯定(错误地引进低层次的人)和错误否定(拒绝了你本应该招聘的人才)。大多数顶尖公司的面试范例指出,错误肯定比错误否定还要恶劣。这有道理吗?因为有足够多的渠道和人才资源,即使有很高的错误否定率,你还是会得到你想要的人才。但是,如果错误肯定率很高,你招聘了更低层次的人才,潜在地,在某种程度上,你也给你的产品、文化以及未来招聘标准带来了不可逆的损害。当然,公司为整个产业设置的招聘标准和方式,看上去是有很多的渠道且源源不断的人才资源。
然而,优化高错误否定率的弊端,会给现有的工程招聘标准带来危机。目前典型的招聘案例是否给出了足够的信息?或者说,基于对人才如此大的需求,是否错过了有资质的人才,仅仅因为我们管中窥豹?
那么,抛开苍白夸张的说教,考虑到面试者表现的不稳定性,一位优秀的面试者在一次面试中可能失败的原因是什么呢?
3 面试失败的原因,源于你的表现
接下来,你可以看到整体接受面试人群的平均表现的分布图:
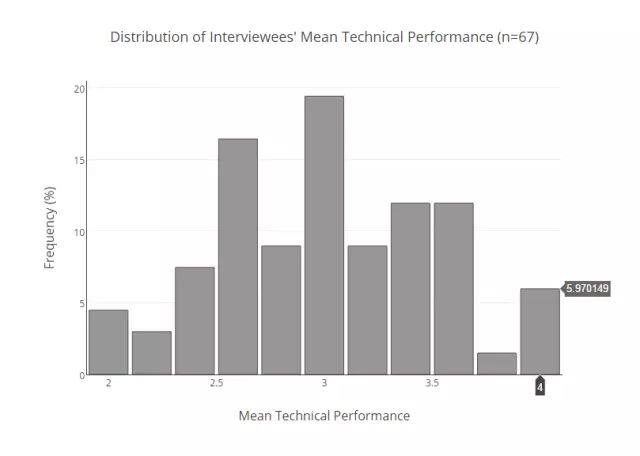
面试者平均技术表现分布图
要计算出一位给定平均分数的面试者面试可能失败的几率,我们必须做一些统计工作。首先,基于面试者的平均分数(近似 0.25),我们把面试者分成几组。然后,对每一组,我们计算出他们失败的可能性,即得到 2 分或者更少的分数。最后,为了让围绕着起始数据集的工作量不那么大,我们重新采样了数据。在重新采样的过程中,我们把一个面试结果当作一个多项分布,或者换言之,假设每个面试者都是一个加权的 4 面骰子,与所在的组群相对应。然后,我们再扔几次骰子,给每一组创建一个新的“模拟”的数据集,然后用这些数据集计算出新的失败概率。下面,你会看到 10000 次重复这个过程的结果。
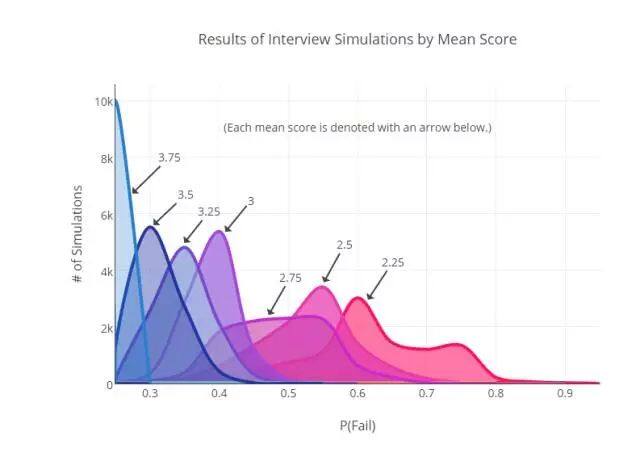
用平均分数模拟的面试结果
如图所示,上面的分布彼此重叠。这很重要,因为这些重叠告诉我们,这些分布组可能没有显著差异(例如 2.75 和 3 之间)。当然,随着更多海量的数据,每组之间的轮廓可能更加明朗。另一方面,如果需要大量的数据来检测失败率的差异,这可能表明,人的行为在本质上是高度可变的。在完成这些之后,我们可以非常肯定地说,低端光谱(2.25)和高端光谱(3.75)之间有显著差异,但居于中间的人的状态,还是混乱不定。
然而,使用这些分布图,只能计算出得到某个平均分数的面试者会失败的概率(参见下面阴影区域 95% 置信区间)。而整体素质很强的人(例如平均值~ = 3),可能会搞砸技术面试,高达 22%。这一事实,表明了面试过程肯定还有改进的余地,同时也使频谱中间模糊区域更大(即看不清楚状态的人会更多)。
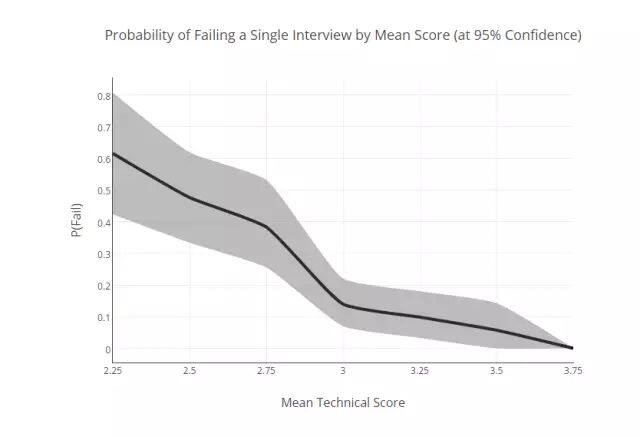
平均分数对应的面试失败概率
4 面试结果,真的是一锤定音?
通常,一想到面试,就会想到那些可重复的结果,可以得到关于面试者足够多的资历信息。然而,我们收集到的数据,虽然它可能很薄弱,却给出了一个截然不同的结果。而且,这个结果与我以往作为一名招聘人员的经验相一致,并且这些看法在技术社区中也是存在的。
Zach Holman 的 Startup Interviewing is Fucked(译注:《创业公司不切实际的面试工程师的方法》一文)认为:面试过程与亟需人才的工作是脱节的。TripleByte(译注:也是美国的一个技术招聘平台)通过观察自家的数据,也得出了类似的结论。最近,rejected.us(译注:一个分享用户面试失败经历的平台)也得出关于面试结果不稳定的更深刻的表述。
我绝对相信,许多曾经被 A 公司拒绝的人,会在另一次面试中表现得更好,最终以人格魅力结束面试,6 个月后被招入 A 公司。尽管每个人都付出最大努力,但是招聘流程陷入了一个怪圈,混乱不定、随机且糟糕。
是的,技术面试本身就是失败的,它没有为面试案例提供可靠的确定性信息,这当然有可能。算法面试是一个热议的话题,我们很感兴趣。特别让我们兴奋的一件事是,跟踪面试表现作为面试的函数类型,我们得到平台上越来越多不同的面试类型 / 方法。的确,我们的长期目标之一是,真正挖掘数据,看看不同的面试风格,以及写出重要的数据驱动语句,哪一种技术面试会给出最有力的信息。
然而,与此同时,相比这样一个重要的决定仅仅基于一次任意的面试,我会认为利用整体表现更有意义。整体表现,一方面可以帮助纠正异常不佳的表现,一方面也可能不小心淘汰那些最终在面试中表现很好的人,或随着时间的推移,淘汰那些仅仅记住 _Cracking the Coding Interview_(中文版:《程序员面试金典》)的人。我知道,像这样不严谨地收集整体表现数据,整体表现并不总是有效的。但至少,在这种情况下,只要面试者的表现勉强合格,或他们的表现与你所期望的大相径庭,那么就再做一次面试,或许能发现些许不同的特质,然后再作出最后的决定。
5 为什么面试的原始分数有说服力?
你们会充满疑问,使用原始分数来评估面试者,这肯定会有一些很明显的问题。我们现在来讨论一下。问题是,即使面试官可能是高级工程师级别,经验很丰富,原始分数仍只是由反馈组成,他们不会修正面试官的严格标准(例如,一个面试官给 4 分,而另一个面试官给 2 分),也不会适应面试技能的变化。在内部,使用一个更复杂的和全面的评级系统来确定面试技能,如果可以表明,原始分数与计算出来的评级紧密关联,那么,相对地使用原始分数,我们不会觉得不好。
我们的评级系统的工作原理是这样的:
- 基于每个反馈项的加权平均,为每次面试创建一个分数。
- 针对每位面试官,我们使用这个分数,对他们面试的每位面试者进行互相比较。
- 基于比较结果,使用贝叶斯排名系统(Glicko-2 修改版本),为每位面试者评级。
因此,每个人只能与同一位面试官面试的其他人比较,仅仅基于分数而排名。这意味着,一位面试官的分数从来没有与另一位面试官的分数直接进行比较,所以我们就避免了面试官严格标准的不一致问题了。
话又说回来,为什么我要提起这个?你们都是聪明人,你可以分辨,哪些人已经完成了面试题,哪些人还在假装做数学题。在做所有这些分析之前,我们想确保我们相信自己的数据。我们已经做了很多工作来构建一个可信的评级系统,与原始编码分数关联起来,来看看它们在决定实际技能上是如何强大。
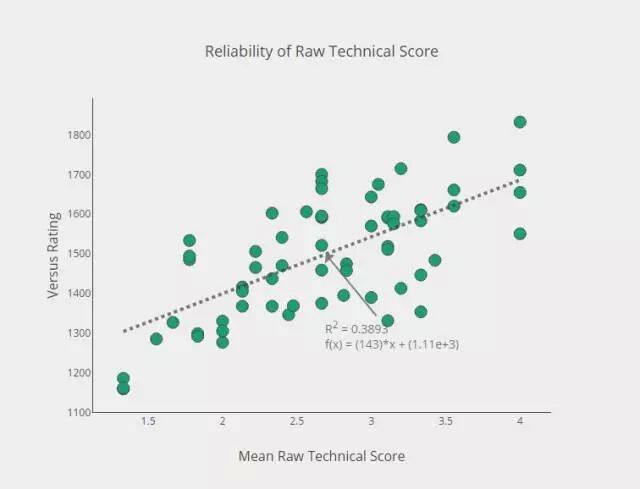
原始技术分数的可靠性
这些结果非常有说服力。虽然,还谈不上能够完全依靠原始分数,但足以相信原始分数是有用的,可以近似确定面试者的能力。
本文作者为著名的人力资源专家 Aline Lerner,已获其授权。感谢 InfoQ 编辑 Cindy 的精心编译。




