
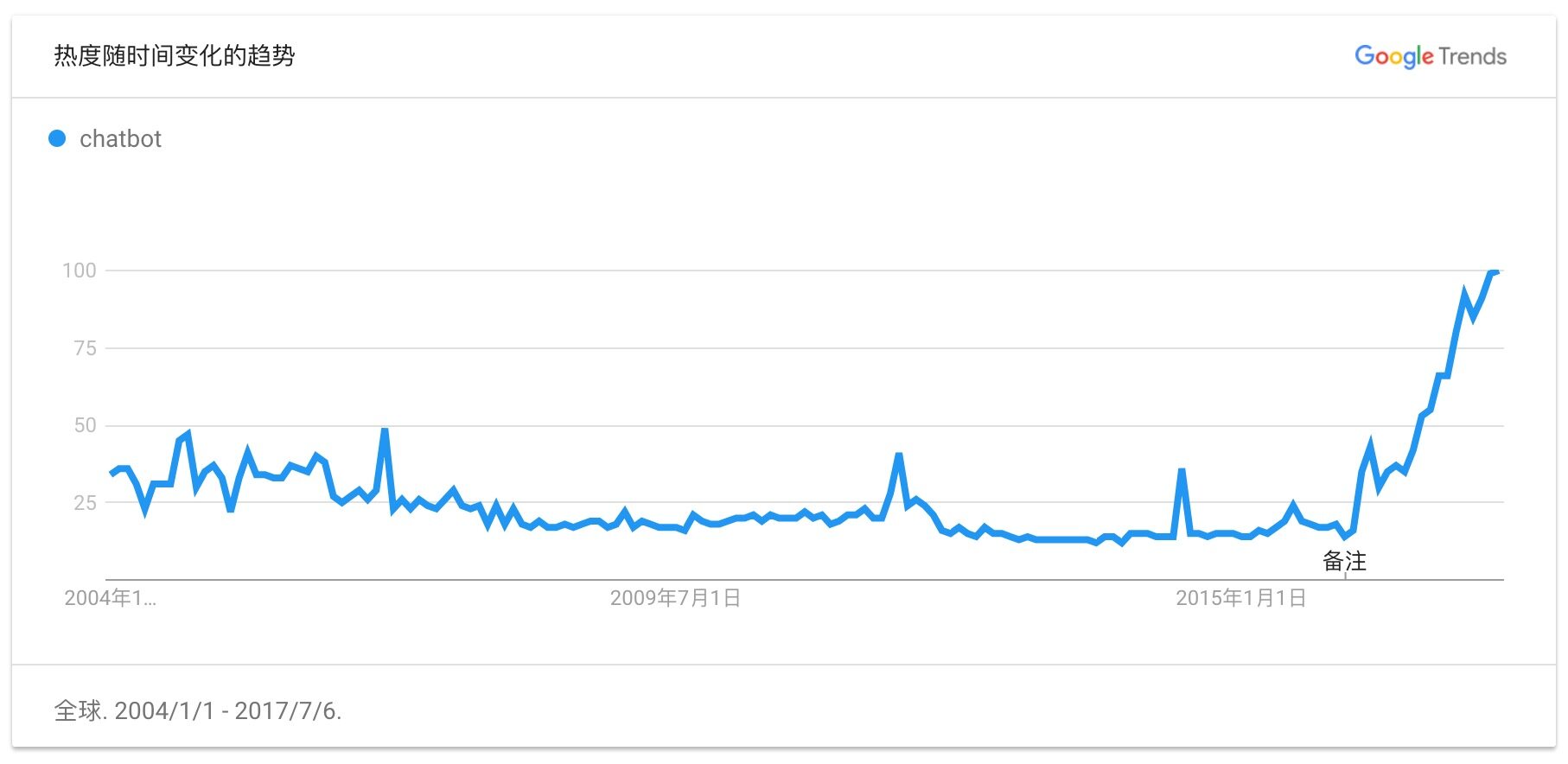
目前,聊天机器人是科技领域的一个热门话题。它刚好处于我们沟通交流方式转折的中心地带,在微软和 Facebook 这样的主流科技公司中,它也是策略与方向的中心。微软的 CEO Satya Nadella 说:“聊天机器人就是我们的 APP。”
为什么聊天机器人这么受欢迎?
聊天机器人变得十分受欢迎,部分原因在于人工智能的复兴以及它在工业领域的应用,但也有部分原因在于我们不知满足的对按需服务的渴望,还有我们从邮件、电话转向短消息应用的习惯。一个最近的研究显示,在客户关系方面,美国消费者中 44%的人倾向于使用聊天机器人而不是人类客服,61%的被试说,他们至少每个月和聊天机器人对话一次。这是因为聊天机器人符合当下的消费者需求,它们能不分昼夜地立刻回复消费者的问题。
大品牌和科技公司已经认识到这个消费者需求方面的转变,他们现在依靠这些机器收发员和智能助手为消费者提供更好的体验。尤其是从去年 Facebook 开始向第三方机器人开放它的 Messenger 平台后,情况更是如此。

所以,随着智能助手和聊天机器人大规模的增长,与流行的信仰和媒体炒作的虚假繁荣不同,智能助手和聊天机器人的确变得没什么新奇的了。我们已经在自然语言处理社区拥有这些技术 50 多年了,智能助手和聊天机器人是自然语言处理核心使命的绝好实例,也就是说,我们给计算机编程,让它能理解人类如何沟通交流。
在这篇文章里,我们要展示三种不同的聊天机器人,让你和它们互动,并理解它们如何进步。我将给出关于每个聊天机器人工作原理的一些技术性说明,以便你了解自然语言处理如何工作。
聊天机器人
我们在这篇文章里讨论三种聊天机器人:
1. ELIZA,它诞生于 1966 年,它是自然语言处理社区中最早的已知的聊天机器人;
2. ALICE,它诞生于 20 世纪 90 年代末,正是它启发了电影《她》(Her);
3. Neuralconvo,它是诞生于 2016 年的深度学习聊天机器人,它能从电影脚本中学习如何讲话。
要知道,我们这里提到的三种机器人都是用来“聊天”的机器人,而不是“面向任务的”机器人。面向任务的机器人是为特定用途而创造的,比如检查某个物品是否有库存,或者订购披萨等。而聊天机器人的功能就只是模拟一个真人,让你能和它聊天。通过了解这些聊天机器人的进步,你将会看到自然语言处理社区是如何使用不同的方法,来复制人类沟通交流的。
ELIZA,一个心理治疗机器人
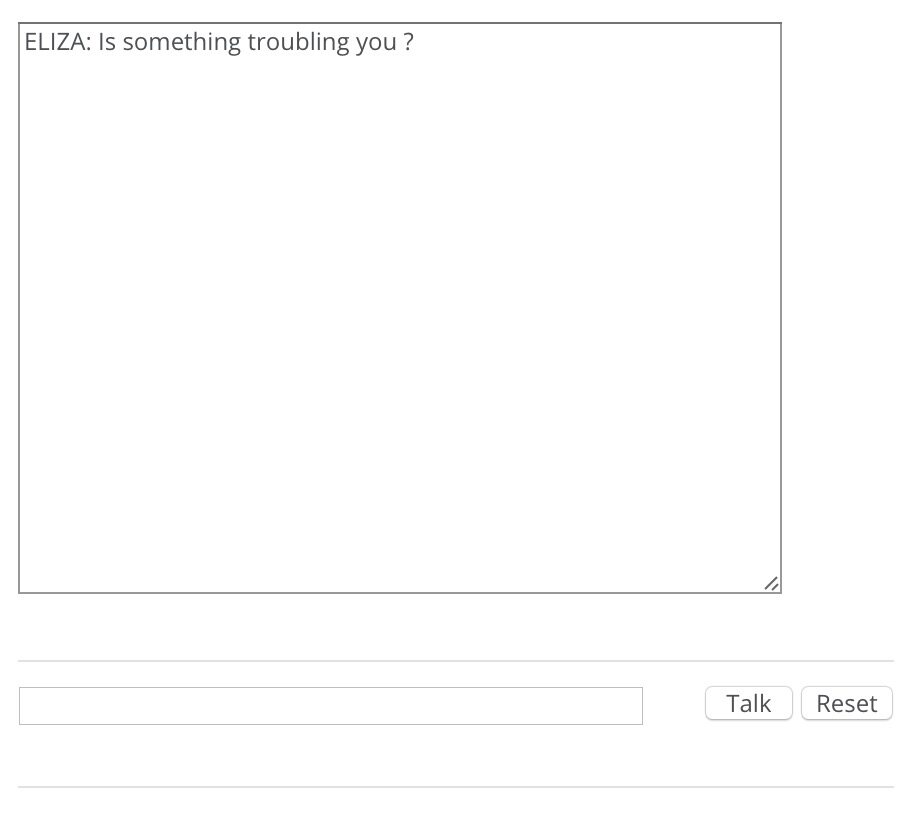
ELIZA 的第一个版本是在 1996 年由约瑟夫·魏泽鲍姆(Joseph Weizenbaum)完成的,他是麻省理工学院的教授,一个聪明的怪人,同时也被视为人工智能的创立者之一。ELIZA 模仿的是一个心理治疗师,魏泽鲍姆的同事们都信任它,并愿意向它透露非常个人化的信息,即使他们知道这是一个计算机程序。魏泽鲍姆震惊于他的同事们,因为他们如此相信 ELIZA 能帮助他们,即使知道它是计算机程序也相信,所以魏泽鲍姆在他的余生中一直倡导人工智能的社会责任。

但是 ELIZA 能模拟心理治疗师,是因为它非常聪明地用问句重复了你的话,并回复给你,就像是真正的心理治疗师会做的那样。这个聪明的策略意味着,ELIZA 能回答一个它并不理解的问题,回答的方式就是用一个相对简单的方法改写用户的输入,让它变成一个问句,这样用户就能继续保持在对话中了。
像所有的算法一样,聊天机器人需要规则来告诉它如何把一条输入改写成一条输出。对一个聊天机器人来说,输入就是你提供的文本,输出就是它返回给你作为回答的文本。仔细看看 ELIZA 给你的回答,你可以看出两个粗略的规则:
- 在句法层面上,它会转换人称代词(将“我的”变成“你的”,反之亦然);
- 要模仿语义上的理解,比如它假装了解你输入的句子的意思,它就要被编程为能识别出某些特定的关键词,并且回复出之前被设定好的合适的句子。举个例子,如果你输入了“我想要……”,它就会回答“如果你……那对你来说意味着什么呢?”
你可以去试试并找出 ELIZA 的局限,问它问题,并思考为什么它做出那些回答。记住:它可是 20 世纪 60 年代的产物,那时候消费者技术的顶峰就是彩色电视机而已。
这是一个完全依靠自然语言处理来建构聊天机器人的路径:机器人通过上面所说的那些规则来理解人类语言,也就是将语法规则编进计算机里。这种方法让人印象深刻,但如果你想通过自然语言处理的方法让 ELIZA 更像人类,你就必须要添加更多的语法规则,但语法是复杂且自相矛盾的,你很快会发现这样行不通。这种方法和机器学习的路径形成了鲜明对照,在用机器学习构建聊天机器人的路径中,算法将会基于它在其他对话中得出的观察结果,来猜测正确的回答。你将会在最后的聊天机器人 Neuralconvo 中看到这一点,但是首先,我们先来看看 ALICE。
ALICE,电影《她》中的明星
从 20 世纪 60 年代快进到 90 年代,你就遇到了 ALICE,第一个人们熟知的能在线交流的聊天机器人。导演斯派克·琼斯(Spike Jonze)说他在 21 世纪初得知了 ALICE 并与它聊天,这第一次让他产生了 2013 年电影《她》中的想法,这是一部讲述人和人工智能坠入爱河的故事,这个人工智能就是他的操作系统。

但就像 ELIZA 一样,ALICE 也是一个根据规则建构起来的计算机程序,接收输入并产出输出。事实上,ALICE 在以下三个方面优于 ELIZA:
- 它以一种被称为人工智能标记语言(AIML)的编程语言编写,这种语言类似于 XML,它允许 ALICE 在更为抽象的层面上做出回应;
- 它拥有成千上万种可能的回应;
- 它会存储之前与用户的对话,并将对话存储在数据库中。
ALICE 是一个开源的机器人,任何人都可以下载并修改或改进它。它最初由理查德·华莱士(Richard Wallace)写成,随后有 500 多名志愿者为这个机器人做出了贡献,他们为 ALICE 创造出了 10 万多条 AIML,让它在对话中重现。
所以,和 ELIZA 相比,ALICE 的进步让它能有更多的回应方式来适应用户输入的文本,这使得 ALICE 能够模仿一个普通人,而不是专门模仿心理治疗师。问题在于,它的缺点现在更为明显了,它没有开放式的陈述和问题,对你的输入缺少回应。

所以,虽然 ALICE 和 ELIZA 相比更为先进,但它的输出依然是由人写成的,算法只是来挑选什么样的输出更适合某一输入。从根本上说,人们写出了回答,也写出了用来挑选什么回答合适的算法,这都是为了模仿一场真是的对话。
改进聊天机器人的表现和智能是一个很流行的研究领域,目前,很多改进聊天机器人的兴趣点都围绕在深度学习方面。把深度学习应用到聊天机器人上,似乎可以大规模提升机器人更像人类地和人互动的能力。ELIZA 和 ALICE 重新组织的文本都是由人类写出的,而一个深度学习机器人,在分析人类言语的基础上,能够从无到有地创造它自己的文本。
Neuralconvo,一个深度学习机器人
Neuralconvo 是在 2016 年由 Julien Chaumond 和 Clément Delangue 使用深度学习训练创造出来的现代聊天机器人,他们二人还是 Huggingface 的联合创始人。深度学习是一种训练计算机学习数据中模型的方法,它使用的是深度神经网络。深度学习在计算机科学方面取得了巨大突破,特别是在人工智能和自然语言处理方面。把深度学习应用到聊天机器人中,它就能让程序去挑选回应,甚至让程序生成全新的文本。
Neuralconvo 能自己生成文本是因为它通过读取上千部电影脚本来“学习”,并识别出文本中的模型。当 Neuralconvo 读一个句子的时候,它能识别出你语句中的模型,然后到它受训练的语句中寻找类似的模型,然后生成一句新的句子返回给你,它认为,如果这个句子在某电影脚本中是某段谈话的一部分,那这个句子也就可以接上你说的话。基本上来说,它就是以它看过的电影为基础,尽量表现得很酷。
ELIZA 和 Neuralconvo 之间最根本的区别就是:ELIZA 是被编程来用特定的回答回复你输入文本中特定的关键词的,而 Neuralconvo 则是在它看过的电影脚本的基础上进行可能性的猜测。所以,没有任何规则让 Neuralconvo 对某一问题给出特定的回答,它的回答是充满无限可能性的。鉴于 Neuralconvo 是通过电影脚本接受训练的,所以它的回复也是相当戏剧性的。
这背后发生作用的具体模型是基于序列到序列的架构,这种架构最先被应用于生成 Quoc Viet Le 和 Oriol Vinyals 的对话。这种架构由两部分组成:第一部分将你的句子编码成一个向量,它基本上就是文本的代码;当所有输入的文本都被这样编码之后,第二部分就会解码这个向量,并通过预测最有可能再次出现的单词逐字逐句地生产出回答。
Neuralconvo 并非要愚弄你,让你在任何时候都认为它是一个人类,因为它只是一个在电影脚本中受训的演示机器人。但你想象一下,如果它能够使用特定上下文的数据来接受训练,比如你自己的短信或者 WhatsApp 短消息,这样一个机器人将会是多么高效啊!这就是聊天机器人的前景,但你要记住,它们仍然是将文本视为输入,使用规则,再将不同的文本作为输出返回给你的算法。
这就是我们从 20 世纪 60 年代至今的聊天机器人之旅。
查看英文原文: An Interactive History of Chatbots
感谢杜小芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论