
AI 前线导读:一年一度由世界知名科技媒体 InfoWorld 评选的 Bossie Awards 于 9 月 26 日公布,本次 Bossie Awards 评选出了最佳数据库与数据分析平台奖、最佳软件开发工具奖、最佳机器学习项目奖等多个奖项。在最佳开源数据库与数据分析平台奖中,Spark 和 Beam 再次入选,连续两年入选的 Kafka 这次意外滑铁卢,取而代之的是新兴项目 Pulsar;开源数据库入选的还有 PingCAP 的 TiDB。
Bossie Awards 是知名英文科技媒体 InfoWorld 针对开源软件颁发的年度奖项,根据这些软件对开源界的贡献,以及在业界的影响力评判获奖对象,由 InfoWorld 编辑独立评选,目前已经持续超过十年,是 IT 届最具影响力和含金量奖项之一。一起来看看接下来你需要了解和学习的新晋数据库和数据分析工具有哪些。

现如今,没有什么东西能够比数据更大的了!我们有比以前多得多的数据,我们有更多方式来存储和分析数据:SQL 数据库、NoSQL 数据库、分布式 OLTP 数据库、分布式 OLAP 平台、分布式混合 OLTP/OLAP 平台。2018 年数据库和数据分析平台方面的 Bossie 大奖获得者也包括了流式处理方面的创新者。

Apache Spark
尽管新的产品层出不穷, Apache Spark 在数据分析领域仍然占据着举足轻重的地位。如果你需要从事分布式计算、数据科学或者机器学习相关的工作,就使用 Apache Spark 吧。Apache Spark 2.3 在二月份发布,它依然着重于开发、集成并加强它的 Structured Streaming API。另外,新版本中添加了 Kubernetes 调度程序,因此在容器平台上直接运行 Spark 变得非常简单。总体来说,现在的 Spark 版本经过调整和改进,似乎焕然一新。

Apache Pulsar
Apache Pulsar 最初由雅虎开发,后来进入 Apache 孵化器,最近正式毕业,成为 Apache 顶级项目。Pulsar 旨在取代 Apache Kafka 多年的主宰地位。Pulsar 在很多情况下提供了比 Kafka 更快的吞吐量和更低的延迟,并为开发人员提供了一组兼容的 API,让他们可以很轻松地从 Kafka 切换到 Pulsar。
Pulsar 的最大优点在于它提供了比 Apache Kafka 更简单明了、更健壮的一系列操作功能,特别在解决可观察性、地域复制和多租户方面的问题。在运行大型 Kafka 集群方面感觉有困难的企业可以考虑转向使用 Pulsar。
Apache Beam
多年来,批处理和流式处理之间的差异正在慢慢缩小。批次数据变得越来越小,变成了微批次数据,随着批次的大小接近于一,也就变成了流式数据。有很多不同的处理架构也正在尝试将这种转变映射成为一种编程范式。
Apache Beam 就是谷歌提出的解决方案。Beam 结合了一个编程模型和多个语言特定的 SDK,可用于定义数据处理管道。在定义好管道之后,这些管道就可以在不同的处理框架上运行,比如 Hadoop、Spark 和 Flink。当为开发数据密集型应用程序而选择数据处理管道时(现如今还有什么应用程序不是数据密集的呢?),Beam 应该在你的考虑范围之内。
Apache Solr
尽管大家都认为 Apache Solr 是基于 Lucene 索引技术而构建的搜索引擎,但它实际上是面向文本的文档数据库,而且是一个非常优秀的文档数据库。不管你是要“大海捞针”,还是要运行空间信息查询,Solr 都可以帮上忙。
Solr 7 系列目前已经发布了,新版本在运行更多分析查询的情况下仍然能保证闪电般的速度。你可以加入很多文档,不到一秒钟就能返回结果。它还改进了对日志和事件数据的支持。灾备(CDCR)现在也是双向的。Solr 全新的自动扩展功能简化了集群负载增长时的扩展操作。

JupyterLab
JupyterLab 是新一代的 Jupyter ,一个基于 Web 的 notebook 服务器,颇受全世界数据科学家的喜爱。经过三年开发,JupyterLab 完全改变了人们对 notebook 的理解,支持对单元格进行拖放重新排布、标签式的 notebook、实时预览 Markdown 编辑,以及改良的扩展系统,与 GitHub 等服务的集成变得非常简单。预计在 2018 年底,JupyterLab 将发布 1.0 稳定版。
KNIME 分析平台
KNIME 分析平台是用来创建数据科学应用程序和服务的开源软件。它提供了可拖放的图形界面,用来创建可视化工作流,还支持 R 和 Python 脚本、机器学习,支持和 Apache Spark 连接器。KNIME 目前有大概 2000 个模块可用作工作流的节点。
KNIME 还提供了商业版,商业版旨在提升生产效率和支持协作。不过,开源版 KNIME 分析平台并不存在人为限制,可以处理包含数亿行数据的项目。
CockroachDB
CockroachDB 是基于事务性和一致性键值存储而构建的分布式 SQL 数据库。它的设计目标是能够在磁盘、机器、机架甚至是数据中心的故障中存活下来,最小化延迟中断,不需要人工干预。CockroachDB v1.13 曾经获得过五星的高分,虽然仍然缺少很多功能,不过现在情况有所改变。
四月份发布的 CockroachDB v2.0 版本有了明显的性能改进,通过添加对 JSON(和其他类型)的支持扩展了与 PostgreSQL 的兼容性,还提供了生产环境的跨区域集群管理功能。CockroachDB v2.1 的路线图中包含了基于成本的查询优化器(用于查询性能的改进)、相关子查询(ORM)、更好地支持模式变更以及企业版产品的加密。
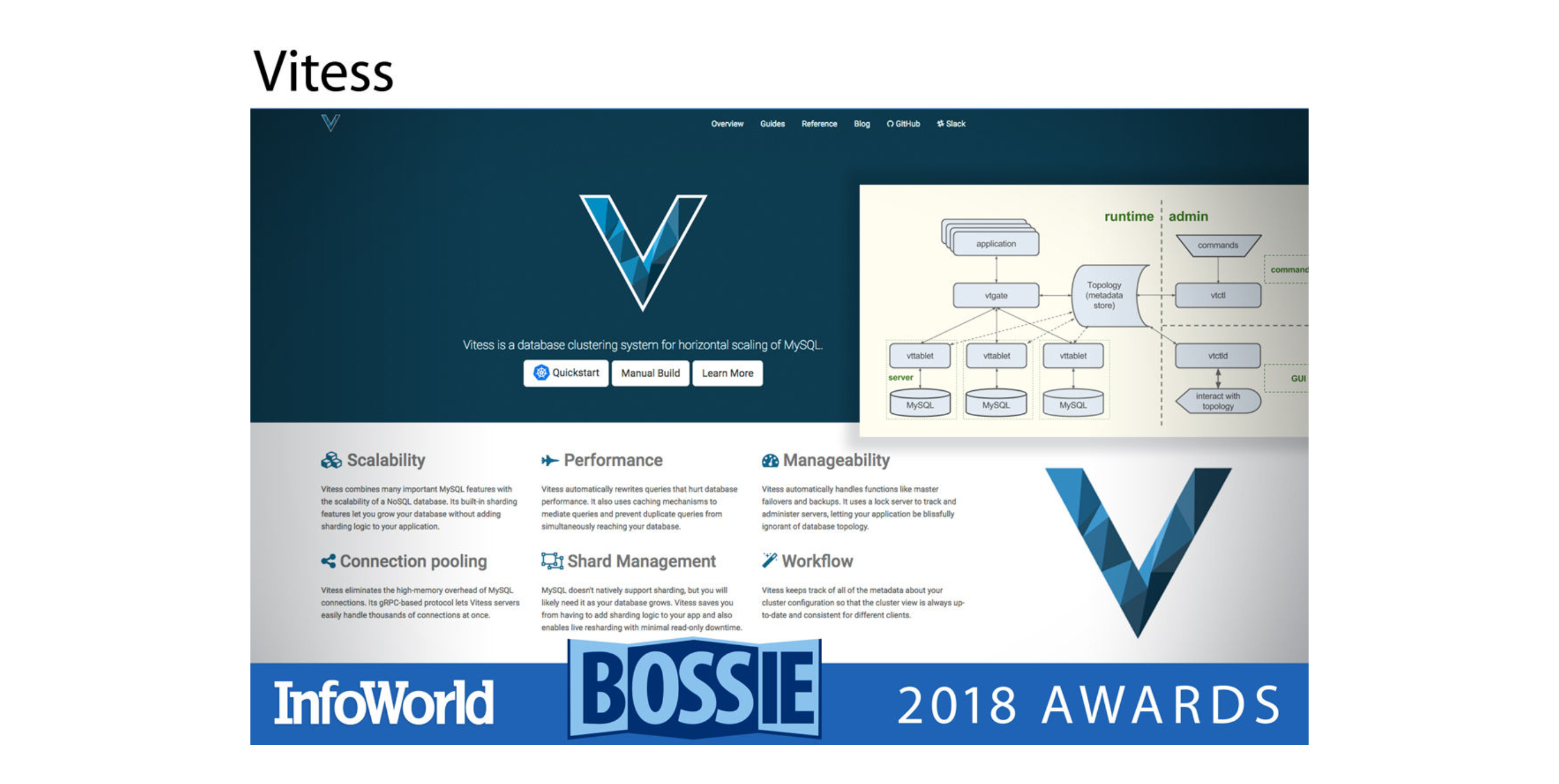
Vitess
Vitess 是通过分片实现 MySQL 水平扩展的数据库集群系统,主要使用 Go 语言开发。Vitess 将 MySQL 的很多重要功能与 NoSQL 数据库的扩展性结合在一起。它的内置分片功能可以让用户在不需要给应用程序添加分片逻辑的情况下对数据库进行扩展。Vitess 从 2011 年开始就是 YouTube 数据库基础设施的核心组件,它已经发展到成千上万个 MySQL 节点。
Vitess 并没有使用标准的 MySQL 连接,因为这会消耗很多 RAM,也会限制每个节点的连接数量。它使用了更有效的基于 gRPC 的协议。另外,Vitess 会自动重写会损害数据库性能的查询,通过缓存机制来调解查询,防止相同的查询同时进入数据库。
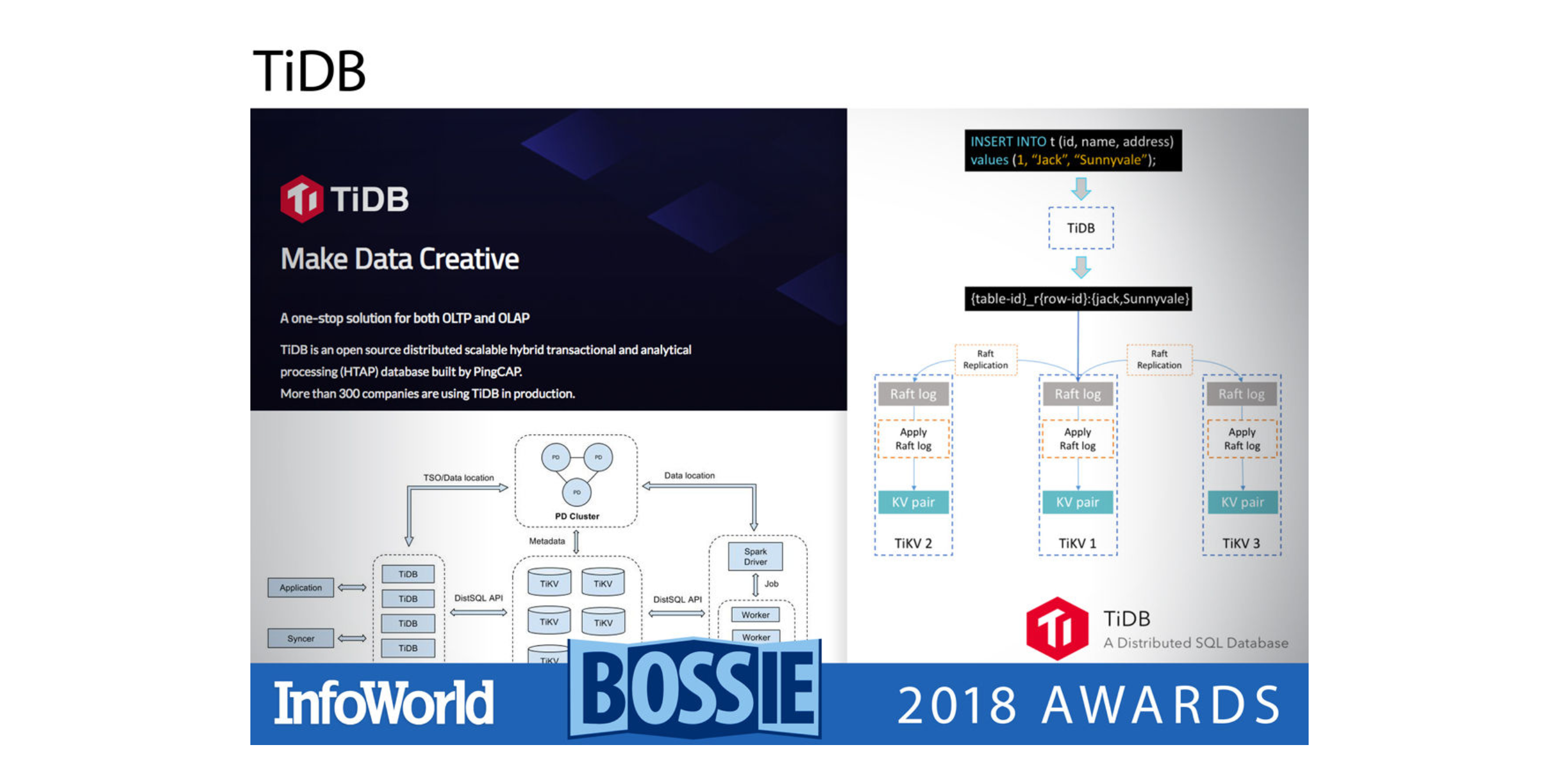
TiDB
TiDB 是一款兼容 MySQL、支持混合事务和分析处理(HTAP)的分布式数据库。它基于事务性键值存储而构建,提供全面的水平扩展性(通过增加节点)以及持续可用性。大多数早期的 TiDB 用户都在中国,因为 TiDB 的开发者在北京。TiDB 的源代码主要用 Go 语言编写。
TiDB 的底层是 RocksDB,RocksDB 是 Facebook 的日志结构键值数据库引擎,用 C++ 编写,因此能获得最好的性能。RocksDB 上面是 Raft 共识层、事务层,然后是支持 MySQL 协议的 SQL 层。
YugaByte DB
YugaByte DB 结合了分布式 ACID 事务、多区域部署、对 Cassandra 和 Redis API 的支持,对 PostgreSQL 的支持即将推出。相对 Cassandra 而言,YugaByte 是强一致性,而 Cassandra 时最终一致性。 YugaByte 的基准测试也比开源的 Cassandra 要好,但比商用的 Cassandra 要差一些,而 DataStax Enterprise 6 具备可调一致性。YugaByte 相当于快速、具有更强一致性的分布式 Redis 和 Cassandra。它可以对单个数据库进行标准化处理,比如将 Cassandra 数据库和 Redis 缓存结合在一起。

Neo4j
Neo4j 图形数据库在处理相关性网络的任务时,执行速度比 SQL 和 NoSQL 数据库更快,但图模型和 Cypher 查询语言需要进行专门的学习。最近,俄罗斯 Twitter 流氓分析、ICIJ 的 Panama Papers 分析以及 Paradise Papers 的分析指出,Neo4j 是非常有价值的。
经过 18 年的开发,Neo4j 已经成为了一个成熟的图数据库平台,可以在 Windows、MacOS、Linux、Docker 容器、VM 和集群中运行。即使是 Neo4j 的开源版本也可以处理很大的图,而在企业版中对图的大小没有限制。(开源版本的 Neo4j 只能在一台服务器上运行。)

InfluxDB
InfluxDB 是没有外部依赖的开源时间序列数据库,旨在处理高负载的写入和查询,在记录指标、事件以及进行分析时非常有用。它可以运行在 MacOS、Docker、Ubuntu/Debian、Red Hat/CentOS 和 Windows 平台上。它提供了一个内置的 HTTP API 和 SQL 风格的查询语言,并旨在提供实时的查询响应(100 毫秒之内)。
查看英文原文: The best open source software for data storage and analytics
感谢无明对本文的审校

暂无签名

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 1 条评论