谷歌 Scholar 自推出以来已经成为很多科研工作者搜索学术资料的必备神器,在前段时间的谷歌重返中国风波中,也有相当多开发者和科研工作者表示希望谷歌 Scholar 也能快点进入中国市场。今天,谷歌继 Google Scholar(Google 学术搜索)之后,又为数据工作者和科研人员推出了一款重磅产品——Google Dataset Search(Google 数据集搜索)。虽然我们依然无法知道谷歌搜索到底什么时候才能重新回到中国,但好产品即使需要“梯子”也得先用起来!
在当今世界,数据成了诸多学科领域的科学家和数据记者的命脉。网络上有成千上万的数据存储库,提供了数百万个数据集,世界各地的地方和国家政府也会公布他们的数据。为了能够轻松访问这些数据,谷歌启动了 Dataset Search 项目,让科学家、数据记者、数据爱好者或其他人能够快速找到他们想要的数据,或者仅仅为了满足他们的求知欲。
Google Dataset Search 传送门: https://toolbox.google.com/datasetsearch
什么是 Dataset Search?
数据集搜索使用户能够查找网上数以千计的存储区中存储的数据集,从而让这些数据集可供大众使用,让人人受益。
数据集和相关数据往往分布在网上的多个数据存储区中。在大多数情况下,搜索引擎既无法提供这些数据库相关信息的链接,也不会将这些信息编入索引,这会导致数据寻找变得无比繁琐,或者在某些情况下无法实现。
Google 为用户提供了能够同时搜索多个存储区的单个界面,希望借此改变用户发布和运用数据的方式。
Ggogle 表示,这个项目能够带来下列好处:
- 形成数据共享生态系统,鼓励数据发布者依照最佳做法来存储和发布数据;
- 为科学家提供相应平台,方便大众引用他们创建的数据集,展现他们的研究成果所带来的影响力。
Dataset Search 与 Google Scholar 的工作方式类似,可以让用户找到托管在任何位置的数据集,无论是发布者的网站、数字图书馆还是个人主页。谷歌为数据提供者制定了一个指南,通过某种方式来描述他们的数据,这样,谷歌(和其他搜索引擎)可以更好地理解他们的数据。指南要求描述有关数据集的一些重要信息:数据集的创建者、发布时间、数据的收集方式、数据的使用条款等等。然后,谷歌会收集并链接这些信息,分析可能存在的相同数据集的不同版本,并尝试找与描述或讨论数据集相关的资料。谷歌所采用的方法是基于一种数据集描述开放标准(schema.org),数据发布者可以通过这种方式描述他们的数据集。数据集提供者可以采用这一通用标准,以便让更多的数据集成为这个强大生态系统的一部分。
Google 数据指南基于数据集的开放标准(schema.org),任何发布数据的人都可以通过这种标准方式来描述他们的数据集。以下是一个数据集定义的示例,完整数据集定义参见: http://schema.org/Dataset 。
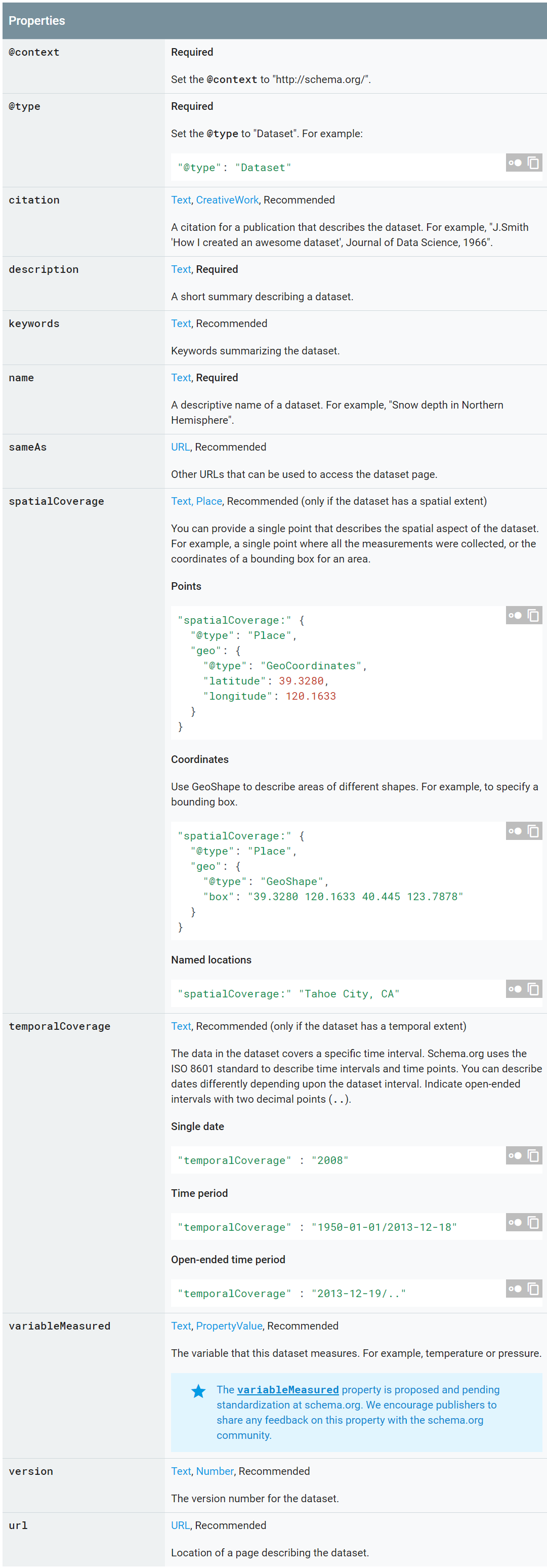
在这个 Dataset Search 版本中,用户可以找到环境科学和社会科学领域的大多数数据集引用,以及来自其他学科领域的数据,包括政府提供的数据和新闻机构(如 ProPublica)提供的数据。随着越来越多的数据存储库使用 schema.org 标准来描述他们的数据集,用户在 Dataset Search 中找到的数据集的种类和覆盖范围将会越来越多。
Dataset Search 支持多种语言,后续将推出更多的语言支持。只需输入要查找的内容,就可以访问到数据提供者发布的数据集。
例如,如果想要分析每日的天气记录,可以在 Dataset Search 中尝试搜索:
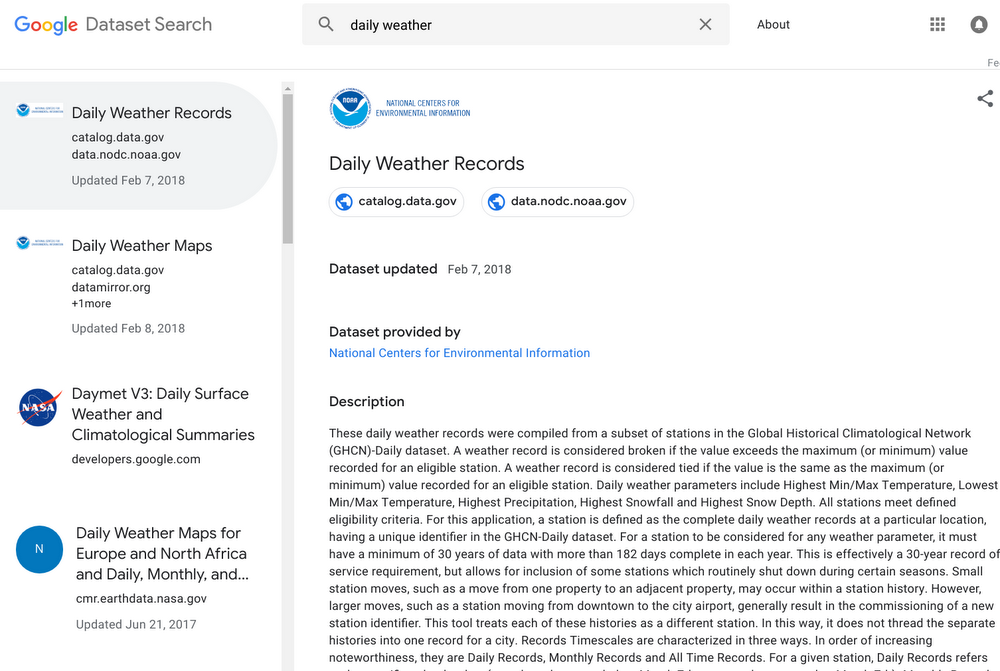
可以看到来自 NASA 和 NOAA 的数据,以及来自哈佛大学 Dataverse 和大学间政治与社会研究联盟(ICPSR)等学术资料库的数据。NOAA 首席数据官 Ed Kearns 是这个项目的坚定支持者,他让 NOAA 的很多数据集都可以在 Dataset Search 中搜索到。他说,“一直以来,这种类型的搜索是开放数据和科学社区众多研究人员的梦想。NOAA 的一个使命是与他人共享我们的数据,对于 NOAA 来说,这个工具是让更广泛的用户社区能够更容易访问到我们数据集的关键”。
Dataset Search 是谷歌为了更好地将数据集纳入到谷歌产品而采取的一系列举措之一。最近,谷歌的搜索引擎可以更容易的搜索到表格数据,这也是使用了相同的元数据和链接的表格数据,直接在搜索中提供这些结果。虽然这个工具更多关注的是新闻机构和数据记者,但无论是查找科学数据、政府数据还是新闻机构提供的数据,Dataset Search 都能助你一臂之力。
这个搜索工具依赖数据发布者提供的元数据。谷歌希望更多人能够使用开放标准来描述他们的数据,让其他用户能够找到他们需要的数据。如果数据发布者在搜索结果中看不到已发布的数据,可以访问谷歌的开发者网站,上面提供了提问和提供反馈的链接。
Google Dataset Search 使用尝鲜
目前 Google Dataset Search 已经支持多种语言,中英文均不在话下。
最近 Google 联手哈佛发布了一款 AI 工具用于预测地震余震位置,那么我们就来分析一下地震数据,可以在 Google Dataset Search 的搜索栏中输入 earthquake,结果如下图所示:
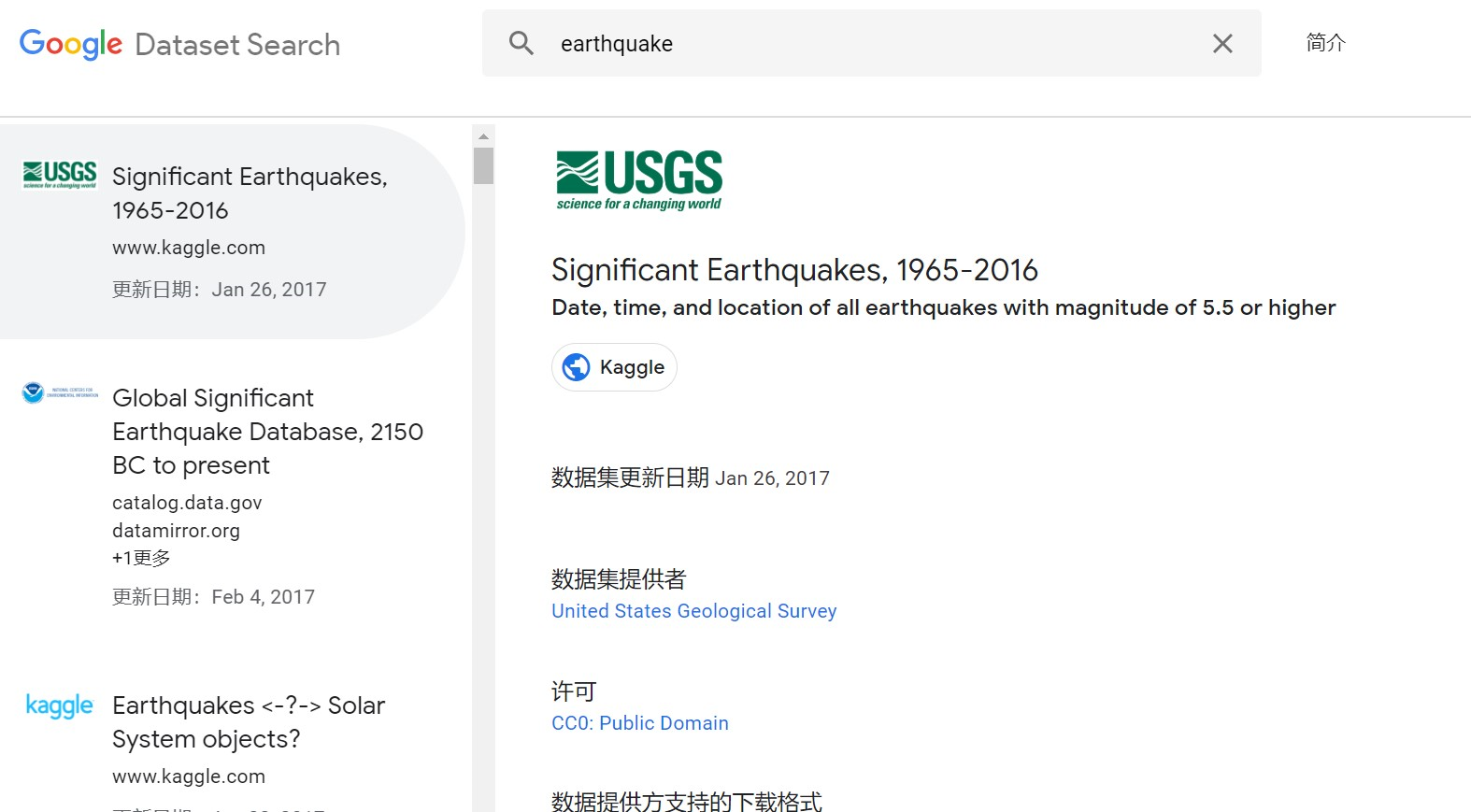
左侧会呈现出所有与关键词有关的数据来源,右侧则会显示每一个数据来源的详细信息,包括数据集名称、数据集更新日期、提供者、支持的下载格式和说明。
下面我们再试试输入中文的“地震”,得到的搜索结果如下:
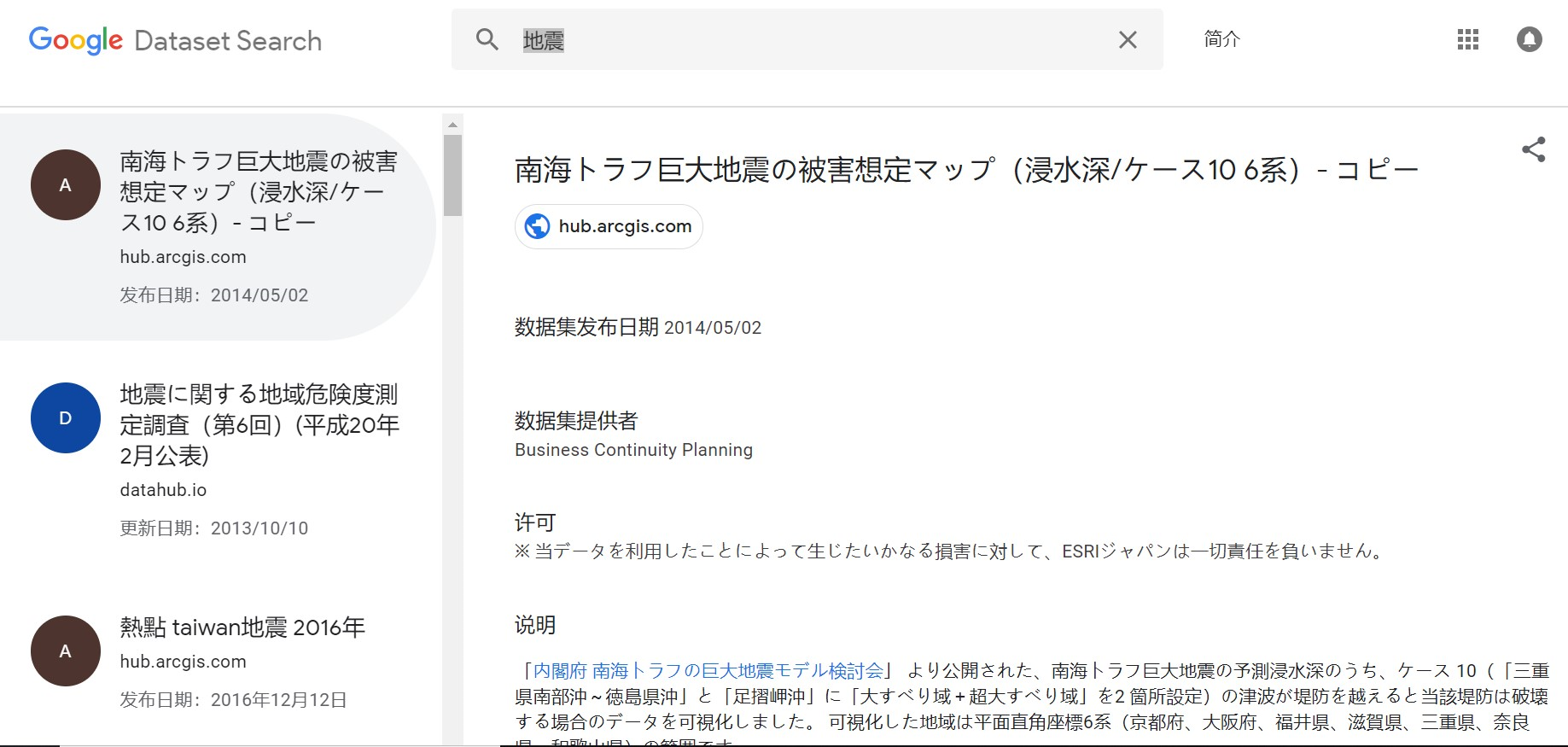
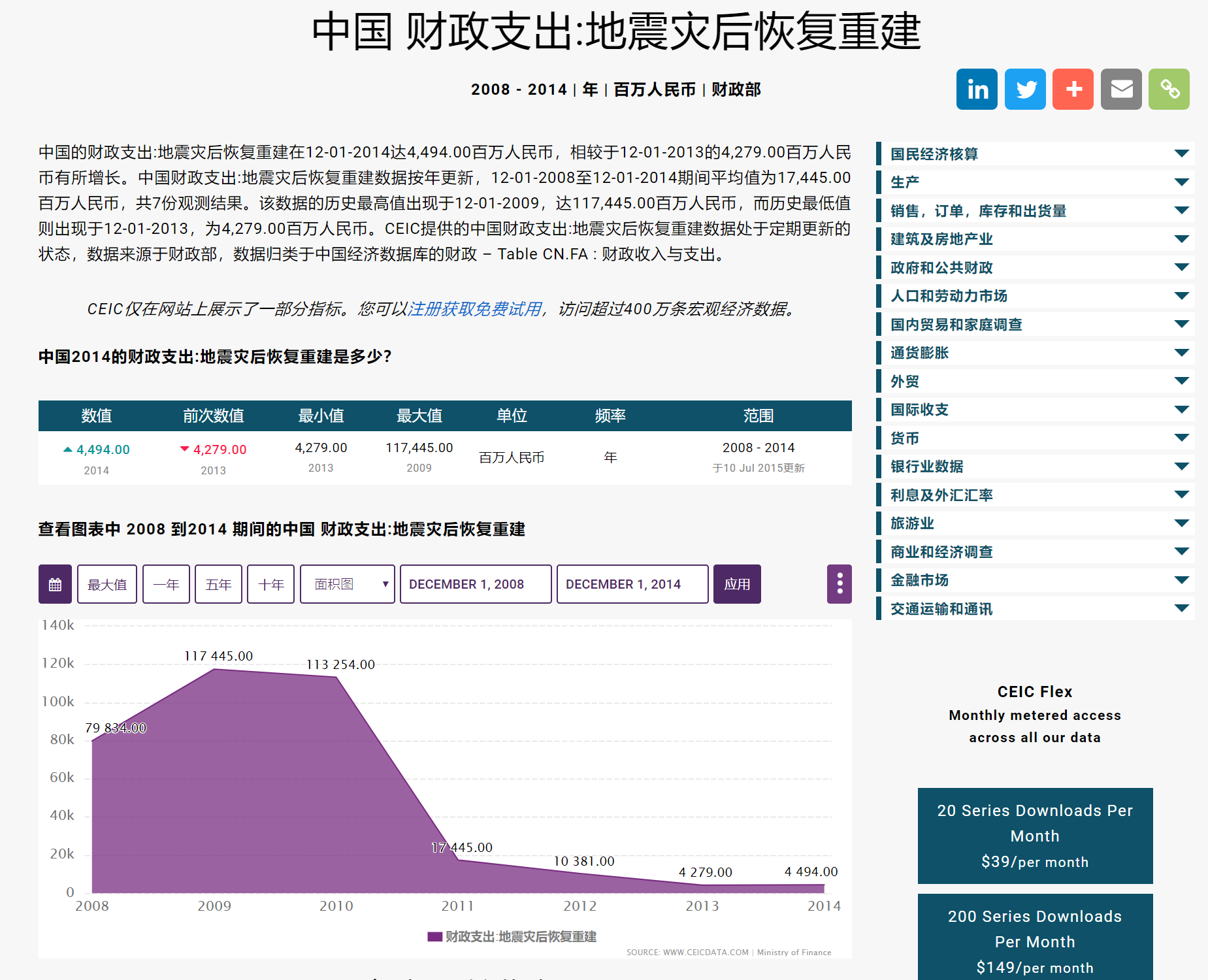
可能因为日本也属于地震多发地区,且“地震”二字在日语汉字和中文中是一样的,因此搜索结果中排在前面的是来自日本的地震数据集,不过左侧往下拉还是能看到不少中文数据集。比如下面这个中国地震灾后恢复重建财政支出的数据集。
目前 Google Dataset Search 仍然处于测试阶段,虽然已有中文界面且支持中文搜索,但中国大陆的用户想要使用依然需要“梯子”科学上网,直接打开是无法访问页面的噢!如果使用中遇到任何问题,可以通过页面右上角按钮向开发人员反馈,或者查看以下链接中的数据集搜索常见问题寻找解答: https://productforums.google.com/forum/#!topic/webmasters/nPq4BW6iPIA 。
查看英文原文: https://www.blog.google/products/search/making-it-easier-discover-datasets/




