


卷首语
解读自然语言处理的 2020 年:“大力出奇迹”的 GPT-3 证明了大算力、大模型的价值
作者 | 赵钰莹
嘉宾 | 于政
2019 年,自然处理领域最受关注的模型便是 BERT。这一年,各大公司和高校陆续发布了自己的预训练语言模型,如:Facebook 发布的 RoBERTa,CMU 发布的 XLNet,Stanford 发布的 ELECTRA,还有百度的 ERNIE 模型等,不断刷新自然语言理解任务的最高表现。2020 年,我们又迎来了 GPT-3 的发布,该模型自出现便引起了开发者圈内的激烈讨论,到底该模型的出现会对整个领域带来哪些值得注意的变化?展望未来,哪些技术是开发者应该关注的?各大公司的动向又是如何?InfoQ 采访了明略科技资深科学家于政,对自然语言处理领域过去一年的重大事件进行总结、回顾与探讨。
2018 年,BERT 诞生,其在 11 项 NLP 任务上达到最高水平,被认为开启了自然语言处理的新篇章。BERT 一个革命性的工作是将 Transformer 的架构引入了预训练语言模型,并开启了 Pretraining-Finetuning 的框架,这让 2019 年涌现了一大批有效、实用并且带给人启发的预训练语言模型方面的成果。根据介绍,该框架在预训练阶段基于大规模无监督语料进行两个预训练任务,分别是词级别和句子级别的,一个是 MLM(Masked Language Modeling),另外一个是 NSP(Next Sentence Prediction),MLM 是从一个部分被 Mask 的句子恢复这些被 Mask 掉的确实词,NSP 是判断一个句对是不是上下句,从而获取基于上下文的词和句子的表示。在 Finetune 阶段,针对具体的下游任务,BERT 会微调中间层参数以调整词的 Embedding 以及调整预测层的参数,成功的将预训练学到的词和句子的表示迁移到下游任务中,实现了对低资源任务的有效支撑。
在于政看来,自 BERT 问世,大部分自然语言处理模型基本遵循了类似结构,以 Transformer 或者 attention 的模型机制进行相关变化。从 GPT-1 到 GPT-2,再到 GPT-3 又让大家逐步认识到增大数据量、模型,以计算流的方式将计算发挥到极致,可以解决很多问题。当前,学术界、工业界的趋势之一是如何用更大的数据训练更复杂的算法系统去解决相关问题。但是,面对领域、细分行业的特殊任务,大的模型并不适用,要基于 pre-training 模型做领域的 fine-tuning。具体而言:
基于 BERT 的模型压缩,让小模型在训练过程从大模型的嵌入层、注意力矩阵以及输出层学习知识,通过减少 transformer 层数获得更快的推理速度,同时模型的精度损失有限。
基于知识图谱的 BERT 模型,BERT 在大规模的通用语料上做预训练,但是在特定领域下效果不好,通过将特定领域知识图谱的信息融入 BERT,获得特定领域的 BERT 模型。
在 2020 年,GPT-3 的论文一经发表就引发了业内轰动,因为这一版本模型有着巨大的 1750 亿参数量。事实上,GPT-2 凭借将近 30 亿条参数的规模已经在 2019 年拿下了“最强 NLP 模型”的称号,而 GPT-3 更甚:放大了 100 倍(96 层和 1,750 亿个参数),并且接受了更多数据的训练(CommonCrawl,一个包含大量 Internet 的数据库,以及一个庞大的图书库和所有 Wikipedia),支持的任务广泛且旨在测试快速适应不太可能直接包含在训练集中的任务的几个新任务。
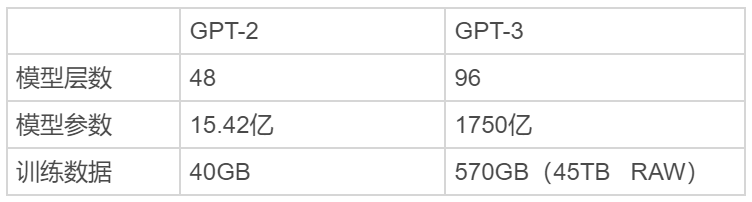
于政表示,GPT-3 是一种自回归模型,基于单向 transformer,采用只有解码器的体系结构,使用下一个单词预测目标进行训练。GPT-3 属于少样本学习语言模型,只需要少量标注数据,不管是 Zero-shot、One-shot 还是 Few-shot 都无需再进行微调。GPT-3 聚焦于更通用的 NLP 模型,主要目标是用更少的领域数据、且不经过精调步骤去解决问题。简单来说,GPT-3 是 GPT-2 的进化版,惊人的模型参数、训练数据和工作量以及结果证明了“大力出奇迹”的道理,扩展了 NLP 领域的想象力。虽然,GPT-3 没有在研究方面推动全球发展,但证明了现有技术的可扩展性,也积累了大模型训练经验。
未来展望
目前,自然语言处理领域较为成熟的方向是传统任务,比如文本分类、情感分析和机器翻译。在商业销售领域,还存在一些对认知能力要求高,技术挑战大的场景,比如话术分析,自然语言生成、理解、问答等,这些场景将产生巨大的商业价值,这也是明略科技重点投入的研发领域。
此外,于政表示,多模态自然语言处理肯定是未来的重要方向之一。人工智能领域发展到现在,已经有很多无法通过单一数据解决的问题出现。工业界比较热的数据中台、知识图谱解决的核心问题之一就是打通多源异构数据,将数据和知识链接起来,进而发挥数据价值,从这个维度看,多模态自然语言处理技术将发挥重要作用。例如:在对话系统场景下,多模态模型能够融合并理解用户输入的图片、文本和语音等信息,并以多模态的形式进行回复,多模态技术能给用户带来丰富的交互体验。在语音交互场景下,通过声学信号和文字信号,能够准确地识别用户交流中的情绪变化等。
未来几年,上述挑战将是自然语言处理领域重点发展和探索的方向,只要其中的相关技术得到解决,对学术界、工业界的贡献将是巨大的。
目录
生态评论
华人工程师失落硅谷
重磅访谈
腾讯李晓森:智能图平台将成为各领域“智能”的基础能力
对话 360 数科首席科学家张家兴:AI 技术在金融科技领域的落地现状如何?
落地实践
科大讯飞的 300 亿智能教育“小目标”
为什么阿里云要做流批一体?
推荐阅读
阿里达摩院预测 2021 年十大科技趋势
“被禁”的 2020:华为、中芯国际、台积电和 TikTok 都经历了什么?














评论 (1 条评论)