Netflix 的工程文化本质在于自由和责任,主要想法认为Netflix 的每个人(以及每个团队)需要承担某种核心责任。在这个框架下,履行使命的过程中大家可以自由开展工作。因此团队通常需要负责从系统设计、架构、开发、部署,再到运维的方方面面。与此同时,让所有团队从零开始开发自己需要的一切,这样的做法非常没有效率,毕竟需要相关基础设施的团队所需的组件往往有一定共性。我们(和其他人一样)很重视代码重用,并希望尽可能对代码进行整合。
在这两个想法(自由和责任,以及代码的可利用能力)影响下,个人和/ 或团队如何确定自己需要对哪些内容进行优化,哪些东西可以统一从一个集中的团队获取?工程决策过程中的这种权衡很普遍,Netflix 也不例外。
Netflix API 是一系列服务,用于处理用户使用各类设备执行操作(注册、内容查找和播放)时产生的流量。过去几年来,这套服务在不同方面有了显著增长:复杂度更高,请求数量激增,随着业务落地全球更多地区,Netflix 订户数量也有了显著增长。随着对 Netflix API 的需求持续增加,承担这一系列责任的系统架构逐渐开始面临局限。为了更好地适应未来增长,我们开始构建一套新架构(更多详情可参阅最近在QCon 活动中的演讲)。本文介绍了我们在重新设计系统架构的过程中遇到的挑战,以及我们是如何协调看似矛盾的工程原则:速率和完整的所有权vs. 最大程度的代码重用和整合。
Netflix API 微服务的编排
Netflix API 是 Netflix 微服务生态体系的“大门”。收到来自不同设备的请求后,API 提供了构建响应过程中调用不同服务所需的逻辑。API 会通过后端系统收集所需任何信息,以需要的顺序和格式收集并筛选数据,随后返回所需响应。
因此 Netflix API 的核心其实是一种编排(Orchestration)服务,可通过对微服务提供的细粒度功能进行组合暴露出粗粒度 API。为此 API 至少要满足四个主要需求:提供灵活的请求协议,将请求映射至一个或多个粒度更细的后端微服务 API,提供保护后端微服务所需的通用弹性抽象,在设备和后端团队之间创建上下文界限(“缓冲”)。
目前,该 API 服务可暴露三类粗粒度 API:非会员(注册、计费、免费试用等)、内容发现(电视和电影推荐、搜索等),以及 _ 内容播放 _(有关流媒体播放体验的决策、确保用户可以观看特定内容的许可机制、观看历史记录、用户书签心跳信号等)。
以内容播放类 API 为例。假设用户在手机上点击了怪奇物语(Stranger Things)第一集的“播放”按钮。为了开始播放,手机会向 API 发出“播放”请求。随后 API 会调用底层的多个微服务。其中某些调用由于相互之间不依赖,可并行进行。其他调用可能需要以特定顺序进行。API 中包含了顺序或并行执行调用所需的全部逻辑。因此客户点击“播放”后设备并不需要知道底层的各种安排。
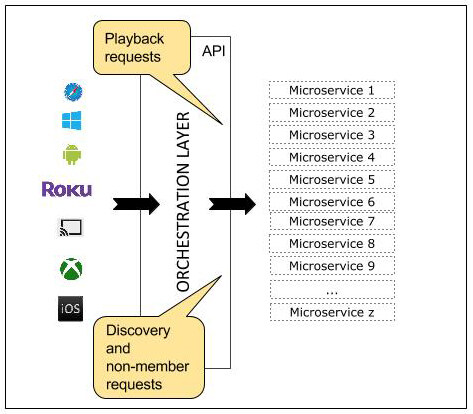
图 1:设备向 API 发出请求,API 对不同微服务进行编排
不过有关内容播放的请求有所例外,只需要映射至负责播放的后端服务。除了播放服务外,还有很多与内容发现和非会员有关的服务,但相互之间的界限非常明显,只有少数服务需要同时发出与播放有关和无关的请求。
这种需求对我们来说算不上新发现,我们的组织结构就反映出类似的情况。目前我们有两个团队(API 团队和播放团队)负责编排层的设计,其中播放团队主要负责与播放有关的 API。但 API 团队需要负责整个 API 体系的完整运作,包括发布、24/7 支持、回滚等。这样的做法可极大促进代码重用,但与我们所期待的,由开发不同内容的团队自行拥有并自行负责生产环境中的运作这一原则相违背。
因此新架构需要满足下列目标:
- 我们希望每个团队能自行拥有自己开发的代码并负责生产环境中的运维。这样即可实现更有针对性的预警以及更快速的 MTTR。
- 同理,我们希望每个团队自行管理自己的发布计划,并在可能的情况下让自己的发布计划不受不相关变更的影响。
两种相互竞争的方法
面对未来的需求,我们考虑了两种方法。在方法 1(见图 2)中,API 中的编排层将以直通(Pass-through)的方式处理所有播放请求,直接将这样的请求发送给与内容播放有关的编排层。随后负责播放的编排层将处理所有与播放有关服务的编排工作。但这种直通模式有一个例外:有一小批共享服务,API 中的编排层会用与播放有关的编排层所需的信息对请求进行扩充,借此让相关服务顺利响应请求。
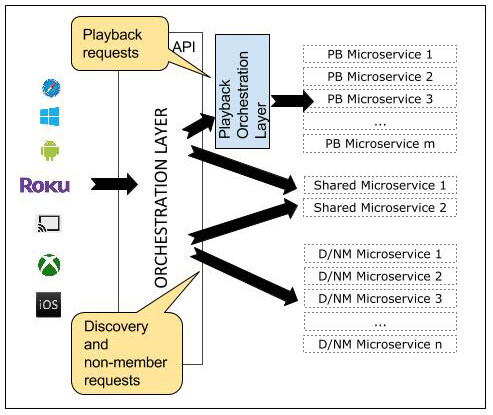
图 2:方法 1,直通式编排层以及与播放功能有关的编排层
或者也可以将其简单拆分为两套相互独立的 API(见图 3)。
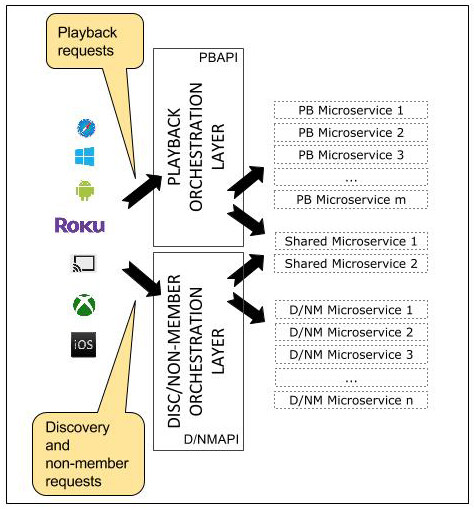
图 3:方法 2,为内容播放和内容发现 / 非会员使用相互独立的 API
这两个方法均可解决我们面临的挑战:对于每种方法,每个团队将自行负责自己编排层的发布周期以及生产环境中的运维,在我们看来这已经是很大的进步。这意味着到底选择哪种方法还需要考虑其他因素,我们的具体考虑如下。
开发者体验
在设计、构建、支持全新 API 的过程中,使用这套 API 的开发者(例如 Netflix 的设备团队)是我们优先考虑的目标。他们每天都在用我们的 API 写程序,对业务来说,必须确保开发者能获得优质的体验和生产力。这方面主要考虑了内容发现和文档两个领域:我们的合作伙伴团队需要知道如何与 API 进行交互,需要传递哪些参数,预期能获得怎样的回应。另一个目标则是灵活性:由于需求复杂,要为超过 1000 种设备提供支持,我们的 API 必须极为灵活。例如,某个设备可能想要请求不同数量的视频,并且对视频规格的要求可能与其他设备截然不同。无论与播放功能有关或无关的 API,这些都非常重要。那么这些因素与一套或两套 API 的决策有什么关系?采用一套 API 的方法可以让这些方面实现更高程度的统一:请求是如何创建和组合的,API 是如何进行记录的,团队如何以及在哪里找到与 API 的变更和增补有关的信息,API 的版本控制,优化开发者体验所需的工具等。如果采用两套 API,这些依然可行,但为了最终实现还需要在两个团队之间进行更努力的合作。
组织的牵涉和共享的组件
目前这两个团队在 API 方面正在进行非常紧密高效的协作。然而我们也非常敏锐地意识到,如果创建两套 API 并由两个独立团队进行管理,这种做法可能会产生深远的影响。我们的目标将会是,并且应当是将两套 API 之间的分歧减至最低。正如上文所述,开发者体验正是让我们这样做的原因之一。更广泛地说,我们希望让与所有 API 有关的任何组件能够实现最大化的重用。这也包含任何编排机制,以及与可缩放性、可靠性,以及弹性有关的任何工具,任何机制,任何库。使用两套 API 的风险在于,随着时间的流逝,这两套 API 可能会逐渐疏远。什么意思?首先,可能会造成一些与组织结构有关的后果(例如需要更多人手)。最终我们可能会面临这样一种情况:对组件所有权的重视高到了一定程度,以至于完全放弃了重用组件这一想法。这不是我们想要的结果,因此对于两套 API 之间的任何分歧都需要深思熟虑。
就算能够重用大量代码,运维方面的开销可能依然很大。正如上文所述,在 Netflix 为客户提供恰当服务的过程中 API 很关键。但直到现在也仅有一个团队开始着手解决系统高度缩放和高弹性的问题,并承担了相应的运维负担。该团队已经在与系统缩放和弹性有关的经验和技能方面花费了多年时间。通过创建两套 API,可以将这些任务和责任分摊给两个团队。
简化性
抛开与组织结构有关的考虑不谈,两套独立的 API 也可以让整个架构更简洁。在方法 1 中,如果 API 主要以“直通”方式运作,是否真的有必要设置这样一套额外的环节?API 收到的每个播放请求都将直接发送至与播放有关的编排层,那么直通方式在功能方面将无法提供太多价值(那一小批共享服务需要的功能除外)。如果为内容发现、洞察、弹性、编排等任务构建的组件可以在两套 API 中重用,使用两套独立 API 所能获得的简化性就显而易见了。更重要的是,上文也曾简单提到,方法 1 要求两个团队负责与播放有关的 API 推送,这会让交互模式产生变化,而方法 2 真正实现了相互独立的部署。
到底该怎么办?我们已经意识到这个决定将会产生深远的影响,但考虑到上述所有问题后,我们也开始认识到完美的解决方案是不存在的。不存在对错,只需要权衡。我们采取的做法是进行周全的假设,然后以此为基础进行实验和开发。尤其是需要通过实验确定能让多少已经开发好,或者打算开发的构建块能够实现通用化,以便在两套 API 中使用。如果这种做法证实有效,随后将构建两套 API。尽管面临诸多挑战,我们依然对这种方法保持乐观态度,并对服务的未来发展寄予厚望。
作者: Katharina Probst 、 Justin Becker ,阅读英文原文: Engineering Trade-Offs and The Netflix API Re-Architecture
感谢陈兴璐对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




