
这是标准并行编程(Standard Parallel Programming)系列文章的第三篇,讲述了在标准语言中使用并行来加速计算的优势。
第一篇文章:《英伟达是如何做 GPU 编程的(一)》
第二篇文章:《英伟达是如何做 GPU 编程的(二)》
争取最佳性能
CPU 到 GPU 移植的性能可能会低于专用的 HPC 代码的性能,这似乎是很自然的。毕竟,受限于软件体系结构和已创建的 API,并且需要考虑用户群所期望的额外复杂特性。不仅如此,与 CUDA 等专用语言相比,C++标准并行的简单编程模型允许更少的手工微调。
实际上,通常可以将这种性能损失控制并限制到可以忽略不计的程度。关键是分析各个代码部分的性能指标,并消除不能反映软件框架实际需求的性能瓶颈。
一个好的做法是为数值算法的核心组件维护一份单独的原理论证(proof-of-principle)代码。与完整、复杂的软件框架(如 Palabos 中的STLBM库)相比,这种方法的性能可以更自由地优化。此外,像 nvprof 这样支持 GPU 的分析器可以有效地用亮色突出性能瓶颈的根源。
以下建议重点介绍了典型的性能问题及其解决方案:
请勿触摸 CPU 上的数据
了解你的算法
建立性能模型
请勿触摸 CPU 上的数据
性能损失的一个常见源头是 CPU 和 GPU 内存之间的隐藏数据传输,这可能会非常缓慢。在 CUDA 统一内存模型中,只要你从 CPU 中访问 GPU 数据,这种类型的传输就会发生。触摸单个字节的数据可能会导致灾难性的性能损失,因为即使是一次传输,传输的也是整个内存页。
一个显而易见的解决方案是尽可能只在 GPU 上操作数据。这需要仔细搜索代码,查找所有对数据的访问,然后将它们包装成并行算法调用。虽然这相当鲁棒,但即使是最简单的操作也需要进行这个流程。
显然,需要查找的地方是数据统计的后置处理(post-processing)操作或中间评估。另一个经典的性能瓶颈是在 MPI 通信层,因为需要在 GPU 上进行数据打包和解包操作。
在 GPU 上表达算法说起来容易做起来难,因为 for_each 和 transform_reduce 的形式最适合于均匀结构化的内存访问。
在数据结构不规则的情况下,使用这两种算法来避免竞争条件并保证合并内存访问是很痛苦的。在这种情况下,你应该遵循下一个建议,并熟悉 C++ STL 中提供的并行算法家族。
了解你的算法
到目前为止,并行 STL 似乎只不过是一种用花哨的函数式语法来表达并行 for 循环的方法。实际上,STL 提供了大量的算法,除了 for_each 和 transform_reduce 之外,这些算法对表达数值方法非常有用,包括排序和搜索算法。
exclusive_scan 算法计算累积和,特别值得一提是,它对于非结构化数据的重建索引操作非常有用。例如,考虑一种用于 MPI 通信的打包算法,其中每个网格节点贡献给通信缓冲区的变量数量是预先未知的。在这种情况下,需要线程之间的全局通信来确定每个网格节点写入缓冲区的索引。
下面的代码示例展示了如何使用并行算法在 GPU 上以良好的并行效率来解决此类问题:
//步骤1:计算每个节点贡献的变量个数。int* numValuesPtr = allocateMemory(numberOfCells);for_each(execution::par_unseq, numValuesPtr, numValuesPtrl + numberOfCells, [=](int& numValues){ int i = &numValues - numValuesPtr; // 计算当前节点提供的变量个数。 numValues = computeNumValues(i);} );// 2. Compute the buffer index for every node.int* indexPtr = allocateMemory(numberOfCells);exclusive_scan(execution::par_unseq, numValuesPtr, numValuesPtr + numberOfCells, indexPtr, 0);// 3. Pack the data into the buffer.for_each(execution::par_unseq, indexPtr, indexPtr + numberOfCells, [=](int& index){ int i = &index - indexPtr; packCellData(i, index);} );这个示例让你享受到了基于算法的 GPU 编程方式的强大表现力:代码不需要同步指令或任何其他低级构造。
建立性能模型
性能模型通过瓶颈分析创建算法性能的上限。它通常将峰值处理器性能(以 FLOPS(“每秒峰值速度”)度量)和峰值内存带宽视为限制硬件特性的主要因素。
正如上一篇文章中的“示例:格子玻尔兹曼软件和 Palabos”部分所述,LBM 代码的计算与内存访问比率较低,并且在现代 GPU 上完全受限制于内存。也就是说,如果你使用的是单精度运算或一个为双精度运算优化的 GPU,至少是这样。
峰值性能简单地表示为 GPU 的内存带宽与代码中执行的内存访问次数之间的比率。直接的结果是,将 LBM 代码从双精度运算转换为单精度运算将使性能加倍。
图 1 显示了在 NVIDIA A100(40 GB)GPU 上,Palabos GPU 移植在单精度和双精度浮点运算上的性能。

所执行的测试用例是湍流状态下盖驱动腔(lid-driven cavity)中的流动,具有简单的立方几何结构。然而,这种情况包括边界条件,并表现出复杂的流动模式。性能以每秒百万次晶格节点更新(MLUPS,越多越好)来衡量,并与 GPU 内存在峰值容量下被利用的理论峰值进行比较。
该代码在双精度下的峰值性能达到 73%,在单精度下达到 74%。这样的性能指标在最先进的 LB 模型实现中很常见,与所使用的语言或库无关。
尽管有些实现可能会增加几个百分点,达到接近 80%的值,但很明显,我们正在接近性能模型所隐含的硬限制。从大局的角度来看,代码的单个 GPU 性能已经很好了。
重用现有的 MPI 后端以获得多 GPU 代码
当 C++并行算法无缝地集成到现有的软件项目中以加速关键代码部分时,没有什么能阻止你重用项目的通信后端以达到多 GPU 的性能。但是,你需要密切关注通信缓冲区,并确保它不会在 CPU 内存中绕道,否则会导致代价高昂的页面错误。
我们第一次尝试在多个 GPU 上运行 GPU 移植版本的 Palabos,虽然在技术上产生的结果是正确的,但性能并没有达到可接受的水平。从一个 GPU 切换到两个 GPU 并没有加速,速度反而下降了一个数量级。这个问题可以追溯到通信数据的打包和解包。在最初的后端中,这是在 CPU 上执行的,并在 CPU 内存中执行了其他的不必要数据访问,比如调整通信缓冲区的大小。
这些问题可以在分析器的帮助下被发现。分析器会突出显示统一内存中出现的所有页面错误,并通过将相应的代码部分移动到并行算法中来进行修复。“了解你的算法”部分解释了对遵循不规则模式的数据是如何打包和解包通信缓冲区的。
此时,使用除了 MPI 之外没有任何扩展的标准 C++,你可以获得一个混合 CPU/GPU 软件项目,它在单 GPU 上拥有最先进的性能,在多 GPU 上也拥有稳定的并行性能。
不幸的是,由于受当前语言规范和相应 GPU 实现的限制,多 GPU 的性能仍然低于预期。在对 C++标准并行这一相当年轻的技术进行改进之前,我们将在本文中基于 C++标准之外的技术提供一些解决方案。
协调多 CPU 和多 GPU 代码执行
虽然本文主要关注的是 CPU 和 GPU 的混合编程,但我们无法避免在某些时候需要解决 CPU 处理中的混合并行(MPI 或多线程)问题。
例如,Palabos 的原始版本是非混合的,它使用 MPI 通信层在 CPU 内核之间以及整个网络中分配工作。移植到 GPU 后,生成的多 CPU 和多 GPU 代码会在每个 MPI 任务中自发地将单个 CPU 内核与一个完整的 GPU 组合在一起,从而使 CPU 的性能变得相对不足了。
每当需要或方便将计算密集型任务保留在 CPU 上时,就会导致性能瓶颈。在流体动力学中,在预处理阶段(如几何体处理或网格生成)通常会出现这种情况。
一个显而易见的解决方案是使用多线程从 MPI 任务中访问多个 CPU 内核。这些线程的共享内存空间可以通过 CUDA 统一内存形式直接与 GPU 共享。
然而,C++并行算法不能同时用于 GPU 和多核 CPU 执行。这是因为 C++不允许从语言内选择并行算法的目标平台。
虽然 C++线程确实提供了一种原生地解决这个问题的方法,但我们发现 OpenMP 提供了最便利和最不受干扰的解决方案。在这种情况下,for 循环的 OpenMP 注解足以将分配给当前 MPI 任务的网格部分分发到多个线程上。
通过固定内存进行通信
在当前版本的 HPC SDK 中,CUDA 统一内存模型在与 MPI 的结合中表现出了另一个性能问题。
由于 MPI 通信层期望数据具有固定的硬件地址(所谓的固定内存:pinned memory),因此驻留在托管内存区域中的任何缓冲区都会首先被隐式地复制到主机 CPU 上的固定内存缓冲区中。由于 GPU 和 CPU 之间的传输,该操作最终可能会非常昂贵。
因此,通信缓冲区应该显式地固定到一个 GPU 内存地址上。对于 nvc++ 编译器,这是通过使用 cudaMalloc 分配通信缓冲区来实现的:
// 分配通信缓冲区// vector<double> buffer(N);// double* buffer = buffer.data();double* buffer; cudaMalloc((void**)&buffer, N * sizeof(double));for_each(buffer, buffer + N, … // 进行数据打包另一种解决方案是用 Thrust 库中的 thrust::device_vector 替换 STL 向量,默认情况下,该库使用固定的 GPU 内存。
在不久的将来,HPC SDK 将会支持用户更高效、更自动地处理这些情况。这样他们就不必使用 cudaMalloc 或 thrust::device_vector 了。所以,敬请期待!
经过本文列出的各种改进后,Palabos 库在一个带有 4 个 GPU 的 DGX A100(40-GB)工作站上进行了测试,同样以盖驱动腔案例作为基准。获得的性能如图 2 所示,并与在 48 核 Xeon Gold 6240R CPU 上获得的性能进行了对比:
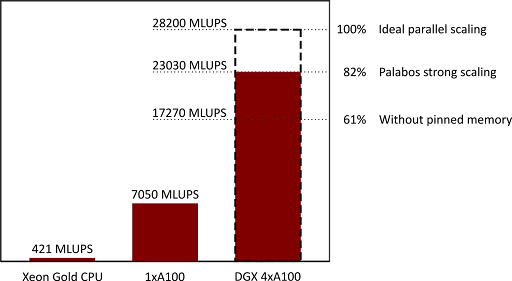
对于 Xeon Gold,Palabos 的原始实现被证明更高效,可用于 48 个 MPI 任务,而单 GPU 和 4-GPU 执行则使用并行算法后端,它是使用 nvc++ 编译的。
性能数据显示,与单 GPU 相比,4-GPU 的执行速度提高了 3.27 倍。在强扩展机制下,
并行效率这个数值达到了令人非常满意的 82%,在两次执行中,总域大小相同。在弱扩展机制下,使用 4-GPU 执行 4 倍大的问题规模,加速比提高到 3.72(效率为 93%)。
图 2 还显示了当使用未固定(unpinned)的通信缓冲区时,例如当 MPI 通信缓冲区未分配 cudaMalloc 时,并行效率从 82%下降到 61%。
最终,4-GPU DGX 工作站的运行速度比 Xeon Gold CPU 快 55 倍。虽然由于两台机器的作用域不同,直接比较可能不公平,但它提供了通过将代码移植到 GPU 所获得的加速度感。DGX 是一个连接到公共电源插头的台式工作站,但它提供的性能在 CPU 集群上只有通过数千个 CPU 内核才能获得。
结论
你已经看到 C++标准语言并行可用于将像 Palabos 这样的库移植到 GPU 上,从而极大地提高了代码的性能。
对于 Palabos 库的最终用户来说,只需进行单行更改,将 CPU 切换到 GPU 后端即可获得这种性能提升。
对于 Palabos 库的开发人员来说,需要做一些工作来开发相应的 GPU 后端。然而,这项工作不需要学习新的特定领域语言,也不依赖于对 GPU 架构的详细了解。
这篇由两部分组成的文章希望能为你提供了一些指导,你可以应用这些指导来使用自己的代码实现类似的结果。 更多相关信息,我们鼓励你查阅以下资源:
在HPC SDK页面上了解更多关于编译器支持的信息。
免费下载HPC SDK
通过阅读二维热导方程(2D heat equation)的代码,学习结合使用 MPI 与 C++标准并行。
通过一个简单的、自包含的示例或下载完整的STLBM库,学习如何在 GPU 上实现 LBM。
访问Palabos GPU移植的项目页面
下载Palabos
原文链接:
https://developer.nvidia.com/blog/multi-gpu-programming-with-standard-parallel-c-part-2




