

ModelArts 实现了更少资源、更低成本、更快速度、更极致的体验。128 块 GPU,ImageNet 训练时间从 18 分钟降至 10 分钟!ModelArts 已开放免费体验,欢迎试用!
深度学习已广泛应用 模型增大、数据增长 深度学习训练加速的需求日益剧增
近年来,深度学习已经广泛应用于计算机视觉、语音识别、自然语言处理、视频分析等领域,可服务于视频监控、自动驾驶、搜索推荐、对话机器人等场景,具有广阔的商业价值。作为人工智能最重要的基础技术之一,深度学习也逐步延伸到更多的应用场景,如智能制造、智慧交通等。
但是,为了达到更高的精度,通常深度学习所需数据量和模型都很大,训练非常耗时。例如,在计算机视觉中,如果我们在 ImageNet[1]数据集上用 1 块 V100 GPU 训练一个 ResNet-50 模型, 则需要耗时将近数日。这严重阻碍了深度学习应用的开发进度。因此,深度学习训练加速一直是学术界和工业界所关注的重要问题,也是深度学习应主要用的痛点。
Jeremy Howard 等几位教授领衔的 fast.ai 当前专注于深度学习加速,在 ImageNet 数据集上用 128 块 V100 GPU 训练 ResNet-50 模型的最短时间为 18 分钟。
然而,最近 BigGAN、NASNet、BERT 等模型的出现,预示着训练更好精度的模型需要更强大的计算资源。可以预见,在未来随着模型的增大、数据量的增加,深度学习训练加速将变得会更加重要。只有拥有端到端全栈的优化能力,才能使得深度学习的训练性能做到极致。
[1] 文中所指的 ImageNet 数据集包含 1000 类个类别,共 128 万张图片,是最常用、最经典的图像分类数据集,是原始的 ImageNet 数据的一个子集。
华为云 ModelArts 创造新记录,“极致”的训练速度
华为云 ModelArts 是一站式的 AI 开发平台,已经服务于华为公司内部各大产品线的 AI 模型开发,几年下来已经积累了跨场景、软硬协同、端云一体等多方位的优化经验。ModelArts 提供了自动学习、数据管理、开发管理、训练管理、模型管理、推理服务管理、市场等多个模块化的服务,使得不同层级的用户都能够很快地开发出自己的 AI 模型。
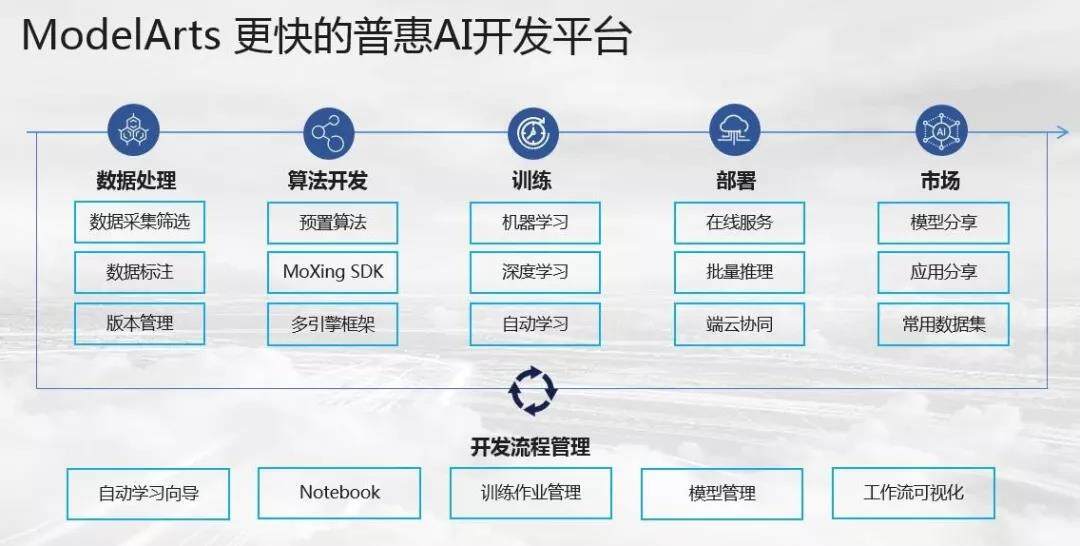
华为云 ModelArts 功能视图
在模型训练部分,ModelArts 通过硬件、软件和算法协同优化来实现训练加速。尤其在深度学习模型训练方面,我们将分布式加速层抽象出来,形成一套通用框架——MoXing(“模型”的拼音,意味着一切优化都围绕模型展开)。采用与 fast.ai 一样的硬件、模型和训练数据,ModelArts 可将训练时长可缩短到 10 分钟,创造了新的记录,为用户节省 44%的成本。
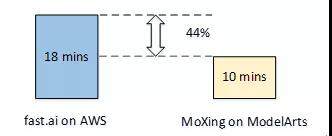
基于 MoXing 和 ModelArts 的训练速度提升
分布式加速框架 MoXing
MoXing 是华为云 ModelArts 团队自研的分布式训练加速框架,它构建于开源的深度学习引擎 TensorFlow、MXNet、PyTorch、Keras 之上,使得这些计算引擎分布式性能更高,同时易用性更好。
高性能
MoXing 内置了多种模型参数切分和聚合策略、分布式 SGD 优化算法、级联式混合并行技术、超参数自动调优算法,并且在分布式训练数据切分策略、数据读取和预处理、分布式通信等多个方面做了优化,结合华为云 Atlas 高性能服务器,实现了硬件、软件和算法协同优化的分布式深度学习加速。
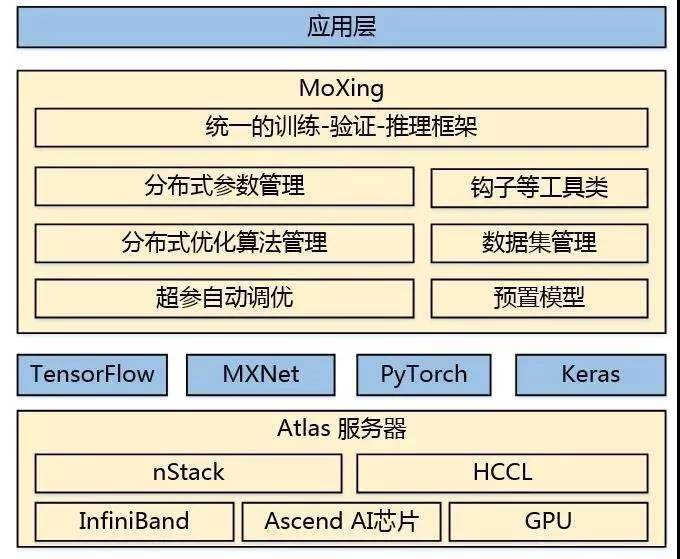
华为云 MoXing 架构图
易用:让开发者聚焦业务模型,无忧其他
在易用性方面,上层开发者仅需关注业务模型,无需关注下层分布式相关的 API,仅需根据实际业务定义输入数据、模型以及相应的优化器即可,训练脚本与运行环境(单机或者分布式)无关,上层业务代码和分布式训练引擎可以做到完全解耦。
从两大指标看 MoXing 分布式加速关键技术
在衡量分布式深度学习的加速性能时,主要有如下 2 个重要指标:
1.吞吐量,即单位时间内处理的数据量;
2.收敛时间,即达到一定的收敛精度所需的时间。
吞吐量一般取决于服务器硬件(如更多、更大 FLOPS 处理能力的 AI 加速芯片,更大的通信带宽等)、数据读取和缓存、数据预处理、模型计算(如卷积算法选择等)、通信拓扑等方面的优化,除了低 bit 计算和梯度(或参数)压缩等,大部分技术在提升吞吐量的同时,不会造成对模型精度的影响。为了达到最短的收敛时间,需要在优化吞吐量的同时,在调参方面也做调优。如果调参调的不好,那么吞吐量有时也很难优化上去,例如 batch size 这个超参不足够大时,模型训练的并行度就会较差,吞吐量难以通过增加计算节点个数而提升。
对用户而言,最终关心的指标是收敛时间,因此 MoXing 和 ModelArts 实现了全栈优化,极大缩短了训练收敛时间。在数据读取和预处理方面,MoXing 通过利用多级并发输入流水线使得数据 IO 不会成为瓶颈;在模型计算方面,MoXing 对上层模型提供半精度和单精度组成的混合精度计算,通过自适应的尺度缩放减小由于精度计算带来的损失;在超参调优方面,采用动态超参策略(如 momentum、batch size 等)使得模型收敛所需 epoch 个数降到最低;在底层优化方面,MoXing 与底层华为自研服务器和通信计算库相结合,使得分布式加速进一步提升。
测试结果对比,用数据说话
一般在 ImageNet 数据集上训练 ResNet-50 模型,当 Top-5 精度≥93%或者 Top-1 精度≥75%时即可认为模型收敛。
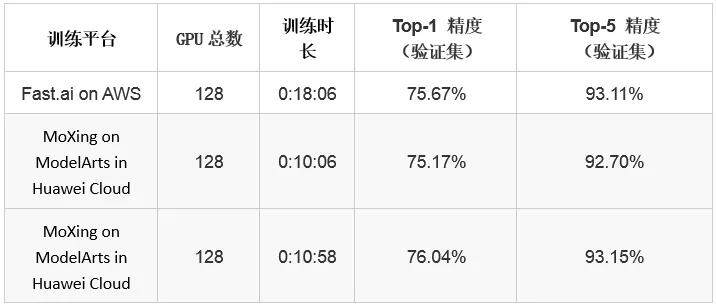
我们测试的模型训练收敛曲线如下图所示。此处 Top-1 和 Top-5 精度为训练集上的精度,为了达到极致的训练速度,训练过程中采用了额外进程对模型进行验证,最终验证精度如下表所示(包含与 fast.ai 的对比)。图(a)所对应的模型在验证集上 Top-1 精度≥75%,训练耗时为 10 分 06 秒;图(b)所对应的模型在验证集上 Top-5 精度≥93%,训练耗时为 10 分 58 秒。
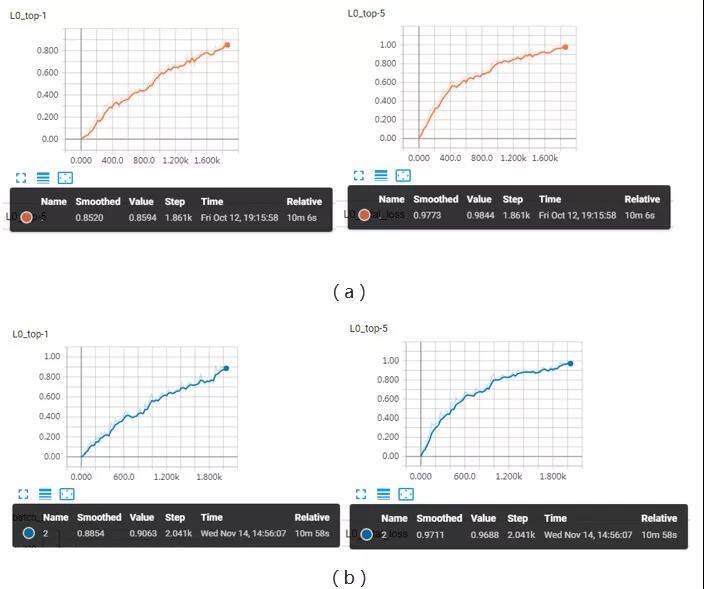
MoXing 与 fast.ai 的训练结果对比
未来展望–更快的、更普惠的 AI 开发平台
华为云 ModelArts 致力于为用户提供更快的普惠 AI 开发体验,尤其在模型训练这方面,内置的 MoXing 框架使得深度学习模型训练速度有了很大的提升。正如前所述,深度学习加速属于一个从底层硬件到上层计算引擎、再到更上层的分布式训练框架及其优化算法多方面协同优化的结果,具备全栈优化能力才能将用户训练成本降到最低。
后续,华为云 ModelArts 将进一步整合软硬一体化的优势,提供从芯片(Ascend)、服务器(Atlas Server)、计算通信库(CANN)到深度学习引擎(MindSpore)和分布式优化框架(MoXing)全栈优化的深度学习训练平台。并且,ModelArts 会逐步集成更多的数据标注工具,扩大应用范围,将继续服务于智慧城市、智能制造、自动驾驶及其它新兴业务场景,在公有云上为用户提供更普惠的 AI 服务。
本文转载自华为云产品与解决方案公众号。
原文链接:https://mp.weixin.qq.com/s/lNCIIG9fPQPFEEJqe_xXvQ

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论