

本文最初发表在 Towards Data Science 博客,经原作者 Praveen Mishra 授权,InfoQ 中文站翻译并分享。
去年,Google 研究人员发布了 BERT,事实证明,这是继 RankBrain 之后效率最高、效果最好的算法改进之一。从初步的结果来看,BigBird 也显示出了类似的迹象。
基于 Transformer 的模型概述
在过去的几年中,自然语言处理取得了巨大的进步,基于 Transformer 的模型在其中扮演了重要的角色。尽管如此,仍然还有很多东西有待发掘。
Transformer 是 2017 年推出的一种自然语言处理模型,主要以提高处理和理解顺序数据的效率而闻名,比如文本翻译和摘要等任务。
与递归神经网络在输入结束之前处理输入的开始不同,Transformer 可以做到并行处理输入,因此,计算的复杂性大大降低了。
BERT 是自然语言处理最大的里程碑式的成就之一,是一个基于 Transformer 的开源模型。2018 年 10 月 11 日,Google 研究人员发表了一篇介绍 BERT 的论文,就像 BigBird 一样。
BERT(BidirectionalEncoderRepresentations fromTransformers,代表 Transformer 的双向编码器表示)是一种先进的、基于 Transformer 的模型。它是在大量数据(预训练数据集)上进行预训练的,BERT-Large 训练了超过 25 亿个单词。
话虽如此,但由于 BERT 是开源的,任何人都可以创建自己的问答系统。这也是 BERT 广受欢迎的原因之一。
但 BERT 并不是唯一的上下文预训练模型。然而,与其他模型不同的是,它是深度双向的。这也是其取得成功和多样化应用的原因之一。
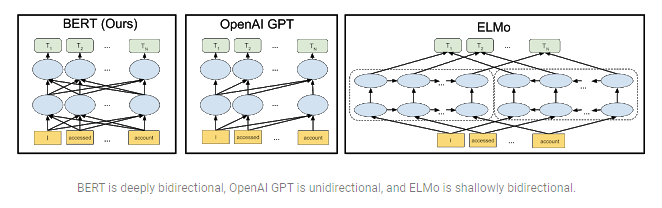
这种预训练模型的结果确实令人印象深刻。它已成功应用于许多基于序列的任务,如摘要、翻译等。甚至连 Google 也采用了 BERT 来理解用户的搜索查询。
但是,就像其他基于 Transformer 的模型一样,BERT 也有它自己的局限性。
以前基于 Transformer 的模型的局限性
虽然基于 Transformer 的模型,特别是 BERT,比起递归神经网络有很大的改进和效率提升,但它们仍然有也有一些局限性。
BERT 工作在一个完全的自注意力机制上。这就导致了每一个新的输入令牌的计算和内存需求的二次方的增长。最大的输入令牌长度一般为 512,这意味着这个模型不能用于更大的输入和大型文档摘要等任务。
这基本上意味着,在将大字符串应用为输入之前,必须将其拆分更小的段。这种内容碎片化也会导致上下文的严重丢失,从而使其应用程序受到限制。
那么,什么是 BigBird?它与 BERT 或其他基于 Transformer 的自然语言处理模型有什么不同呢?
BigBird 简介:用于更长序列的 Transformer
如前所述,BERT 和其他基于 Transformer 的自然语言处理模型的主要局限性之一是,它们运行在一个完全的自注意力机制上。
当 Google 研究人员在 arXiv 上发表了一篇题为《BigBird:用于更长序列的 Transformer》(Big Bird: Transformers for Longer Sequences)的论文后,情况发生了变化。
BigBird 是运行在稀疏注意力机制上的,允许它克服 BERT 的二次依赖性,同时又保持了完全注意力模型的属性。研究人员还提供了 BigBird 支持的网络模型如何超越以前的自然语言处理模型以及基因组学任务的性能水平的实例。
在我们开始讨论 BigBird 的可能应用之前,先看看 BigBird 的主要亮点。
BigBird 的主要亮点
以下是 BigBird 的一些特性,这些特性使它比以前基于 Transformer 的模型更好。
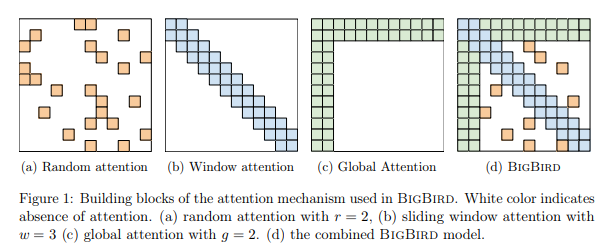
稀疏注意力机制
假设给你一张图片,并要求你为这张图片创建一个相关的标题。你将从识别图片中的关键对象开始,比如说,一个人在扔一个“球”。
对于我们人类来说,识别这个主要对象很容易,但是为计算机系统简化这一过程在自然语言处理中却是一件大事。注意力机制的引入降低了整个过程的复杂性。
BigBird 使用稀疏注意力机制,使其能够处理序列的长度比 BERT 可能的长度多 8 倍。请记住,使用与 BERT 相同的硬件配置就可以实现这一结果。
在 BigBird 的那篇论文中,研究人员展示了 BigBird 中使用的稀疏注意力机制是如何与完全自注意力机制(用于 BERT)一样强大的。除此之外,他们还展示了“稀疏编码器是如何做到图灵完备的”。
简单地说,BigBird 使用稀疏注意力机制,这意味着注意力机制是逐个令牌应用的,而不是像 BERT 那样,注意力机制只对整个输入进行一次应用!
可以处理多达 8 倍长的输入序列
BigBird 的主要特点之一是它能够处理比以前长 8 倍的序列。
研究小组设计 BigBird 是为了满足像 BERT 这样的全 Transformer 的所有要求。
利用 BigBird 及其稀疏注意力机制,研究小组将 BERT 的复杂度 降到 。这意味着原来限制为 512 个令牌的输入序列,现在可以增加到 4096 个令牌(8*512)。
BigBird 的研究人员之一 Philip Pham 在一次Hacker News 讨论中表示:“在我们大部分论文中,我们使用的是 4096,但我们可以使用更大的 16K 以上。”
针对大数据集进行预训练
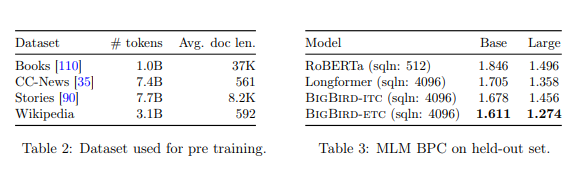
Google 研究人员在 BigBird 的预训练中使用了 4 种不同的数据集:Natural Questions、Trivia-QA、HotpotQA-distractor、WikiHop。
虽然 BigBird 的预训练集远不如 GPT-3(训练参数为 1750 亿个参数)大,但研究论文中的表 3 显示,它比 RoBERTa 和 Longformer 的性能更好。RoBERTa 是一种稳健优化的 BERT 预训练方法,Longformer 是一种用于长文档的类 BERT 模型。
当一位用户请求 Philip Pham将 GPT-3 与 BigBird 进行比较时,他说:“GPT-3 只是用了 2048 的序列长度。BigBird 只是一种注意力机制,实际上可能是对 GPT-3 的补充。”
BigBird 的潜在应用
最近,介绍 BigBird 的论文于 2020 年 7 月 28 日才发表,因此,BigBird 的全部潜力还有待确定。
但这里有几个潜在应用的领域。BigBird 的作者在原始研究论文中也提出了其中的一些应用。
基因组学处理
深度学习在基因组学数据处理中的应用越来越多。编码器将 DNA 序列的片段作为输入,用于诸如甲基化分析、预测非编码变体的功能效应等任务。
BigBird 的作者称:“我们引入了一种基于注意力的模型的新应用,在这种模型中,长下文是有益的:提取基因组序列(如 DNA)的上下文表示。”
在使用 BigBird 进行启动子区域预测(Promoter Region Prediction)后,论文声称最终结果的正确率提高了 5%!
长文档摘要与问答系统
由于 BigBird 现在可以处理多大 8 倍长的序列长度,它可以用于自然语言处理任务,如更长的文档格式的摘要和问答系统。在创建 BigBird 的过程中,研究人员还测试了它在这些任务中的性能,并见证了“最先进的结果”。
BigBird 用于 Google Search
Google 从 2019 年 10 月开始利用 BERT来理解搜索查询,并为用户显示更多的相关结果。Google 更新搜索算法的最终目的是比以前更好地理解搜索查询。
由于 BigBird 在自然语言处理方面的表现优于 BERT,所以使用这个新建立的、更有效的模型来优化 Google 的搜索结果查询是有意义的。
Web 和移动应用程序开发
自然语言处理在过去十年中取得了长足的进步。有了一个 GPT-3 驱动的平台,你可以将简单语句转化为可运行的 Web 应用程序(连同代码),人工智能开发者可以真正改变你开发 Web 和 Web 应用程序的方式。
由于 BigBird 可以处理比 GPT-3 更长的输入序列,它可以与 GPT-3 一起使用,为你的企业高效、快速地创建Web 和移动应用程序。
结语
尽管 BigBird 还有很多有待探索的地方,但它绝对具有彻底改革自然语言处理的能力。你对 BigBird 及其对自然语言处理的未来的贡献有什么看法?
参考文献:
【1】 《BigBird:用于更长序列的 Transformer》(Big Bird: Transformers for Longer Sequences),Manzil Zaheer 及其团队,2020 年,arXiv。
【2】 《BERT:用于语言理解的深度双向 Transformer 的预训练》(BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding),Jacob Devlin、Ming-Wei Chang、Kenton Lee、Kristina Toutanova,arXiv。
作者介绍:
Praveen Mishra,技术爱好者,具有创造内容的天赋。热衷帮助企业实现目标。
原文链接:
https://towardsdatascience.com/understanding-bigbird-is-it-another-big-milestone-in-nlp-e7546b2c9643

InfoQ高级技术编辑

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论