

大模型是当前通用人工智能产业发展创新的核心技术,目前国内已发布的生成式 AI 模型超过了 100 个。面向以大模型为核心的生成式 AI 开发与应用场景,近日浪潮信息发布了大模型智算软件栈 OGAI(Open GenAI Infra)——“元脑生智”,为大模型业务提供了全栈全流程的智算软件栈,包括 AI 算力系统环境部署、算力调度保障、模型开发管理等。OGAI 软件栈由 5 层架构组成,从 L0 到 L4 分别对应于基础设施层的智算中心 OS 产品、系统环境层的 PODsys 产品、调度平台层的 AIStation 产品、模型工具层的 YLink 产品和多模纳管层的 MModel 产品。
其中 L2 层 AIStation 是面向大模型开发的 AI 算力调度平台,AIStation 针对大模型训练中的资源使用与调度、训练流程与保障、算法与应用管理等方面进行了系统性优化,具备大模型断点续训能力,保证长时间持续训练。AIStation 支撑浪潮信息“源”大模型的训练算力效率达到 44.8%。某大型商业银行基于 AIStation 打造的大规模并行运算集群,帮助其充分发掘计算潜能进行大模型训练,并荣获 2022 IDC“未来数字基础架构领军者”奖项。
本文将重点讨论大模型训练面临的挑战、AIStation 如何提升大模型训练效率,以及取得的效果。
一、大模型训练面临巨大挑战
1.大模型训练巨大算力成本和算力利用难题
大模型训练要面对的首要挑战就是海量数据和计算量,算力开销巨大,如 GPT-3 是在 10000 个 GPU 上训练得到的,“源 1.0”模型是在 2128 个 GPU 上通过 AIStation 平台完成 1800 亿 tokens 的训练,训练一个万亿 token 的 700 亿参数模型将花费上百万美元。但计算平台的性能通常不能随着算力线性增长,而是会出现耗损,因此大模型训练还需要高效的算力调度来发挥算力平台的效能。而这不仅需要依赖算法、框架的优化,还需要借助高效的算力调度平台,以根据算力集群的硬件特点和计算负载特性实现最优化的算力调度,整体提高算力利用率和训练效率。
2.耗时且维护复杂的多种网络兼容适配
大模型训练过程中,成千上万颗 GPU 会在节点内和节点间不断地进行通信。为了获得最优的训练效果,单台 GPU 服务器会搭载多张 InfiniBand、ROCE 等高性能网卡,为节点间通信提供高吞吐、低时延的服务。但不同的网络方案各有优劣,InfiniBand 因性能优异已被公认为大模型训练的首选,但其成本较高;RoCE 虽然成本较低,但在大规模的网络环境下,其性能和稳定性不如 InfiniBand 方案。因此要想满足大模型训练对通信的要求,就要对集群网络中的通信设备适配使用和网络情况进行探索和设计。
3.不稳定的大模型训练和高门槛的系统级别优化
大模型训练过程比传统的分布式训练复杂,训练周期长达数月。集群计算效力低、故障频发且处理复杂,会导致训练中断后不能及时恢复,从而会降低大模型训练的成功概率,也会使得大模型训练成本居高不下。因此,大模型对训练的稳定性、故障检测与训练容错提出了更高的要求。同时简化大模型分布式任务提交、实现智能与自动化的任务资源匹配和训练健壮性也是提升训练效率的重要保证。
Meta 在训练模型体量与 GPT3 规模相当的 Open Pre-trained Transformer (OPT)-175B 时,遇到的一大工程问题就是训练不稳定。如下图所示,可以看到有许多训练停止的时间节点,原因有 GPU 掉卡、GPU 性能异常导致训练意外中断等。训练稳定性和有效的断点续训是目前大模型训练中亟待解决的问题。
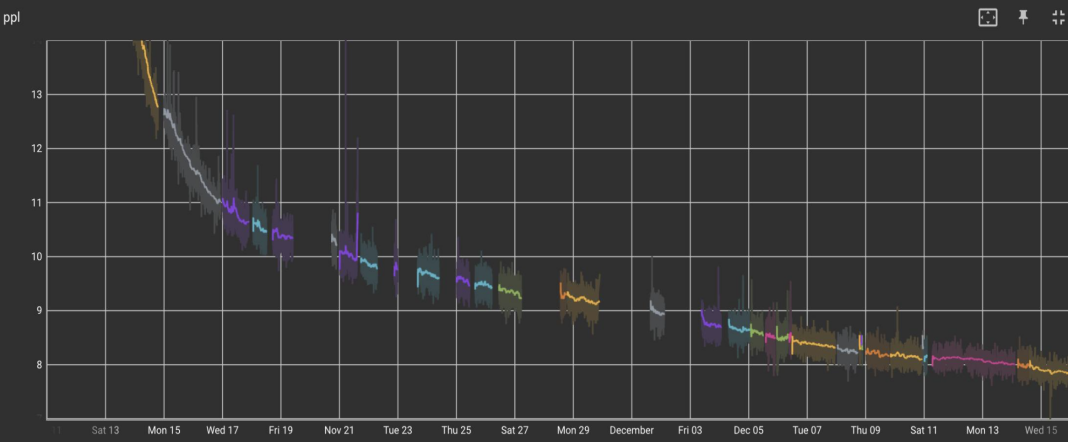
总之,在超大规模分布式环境下开展大模型训练,如果想要缩短训练周期、降低训练成本,就需要解决算力调度、网络通信、训练稳定性等各种挑战。不仅要灵活、充分地利用集群内的所有资源,通过多种手段优化数据使用、通讯,还要及时处理大规模计算集群的异常。
二、AIStation 全流程简化和提速大模型训练
浪潮信息 AIStation 提供了系统性软硬一体优化的平台与软件栈能力,来保障大模型的训练需求。AIStation 平台从资源使用与调度、训练流程与保障、算法与应用等角度进行了系统性的优化,实现了对大模型训练的端到端优化和加速。
1.毫秒级调度,高效使用大规模算力,解决算力利用低难题
AIStation 在大模型训练实践中,针对云原生调度系统性能做了优化,实现了上千 POD 极速启动和环境就绪。如下表所示,AIStation 调度器与原生社区版相比,能大幅提升大规模 POD 任务的调度性能,尤其能保证大模型训练的计算资源的调度使用。
表 1 大规模 POD 调度任务性能对比:
此外,AIStation 平台能够支持大模型特有的开发模式,提供多种尺度作业资源使用方式,包括小尺度资源调度,大尺度资源调度、高性能调度等。算力调度器通过动态、智能地管理和调配集群计算资源,制定合理的作业执行计划,以最大限度地利用资源,满足各类训练任务的时延和吞吐需求,保证作业高效稳定运行,实现算力平台高利用率、强扩展性、高容错性。
通过多种资源高效管理和调度策略,AIStation 能实现毫秒级调度,将整体资源利用率提升到 70%以上,帮助客户更好地利用计算集群算力,充分发挥算力价值。
2.高效网络资源管理,多卡加速比达 90%,极致加速训练过程
AIStation 定义了互相独立的计算高性能网络、存储高性能网络,并且支持交换机级别的资源调度,减少跨交换机流量,同时具备网络故障自动识别和处理功能。针对大模型训练通信要求高的场景,AIStation 提供集群拓扑感知能力,容器网络与集群物理网络一致,保证了容器互联性能,满足训练通信要求。分布式通信优化结合集群的 InfiniBand 或 RoCE 高性能网络和专门优化的通信拓扑,使得 AIStation 在千卡规模集群测试中,多卡加速比达到了 90%。尤其 AIStation 对大规模 RoCE 无损网络下的大模型训练也做了相应优化,实测网络性能稳定性达到了业界较高水平。
借助 AIStation 平台,某大型商业银行实现了主流大模型训练框架,如 DeepSpeed、Megatron-LM 和大语言模型在 RoCE 网络环境的训练,快速实现大模型的落地实践。
3.大规模训练系统级别优化,故障处理时间缩短 90%,最大限度降低实验成本
大模型任务提交时,经常会伴随着大量的环境配置、依赖库适配和超参数调整。AIStation 能够自动化配置计算、存储、网络环境,同时对一些基本的超参数提供自定义修改,方便用户使用,通过几步就能启动大模型分布式训练,目前支持诸多大模型训练框架和开源方案,如 Megatron-LM、DeepSpeed 等。
AIStation 在大规模训练集群上利用自研数据缓存系统,提高了训练前、训练中的数据读取速率,大大减少对存储系统和网络的依赖。配合优化的调度策略,与直接使用存储系统相比,可让模型训练效率获得 200%-300%的提升,硬件性能 100%释放。
健壮性与稳定性是高效完成大模型训练的必要条件。AIStation 针对资源故障等集群突发情况,会自动进行容错处理或者执行弹性扩缩容策略,保证训练任务中断后能以最快速度恢复,为需要长时间训练的大模型提供可靠环境,平均将异常故障处理时间缩短 90%以上。

综上,针对大规模分布式计算,AIStation 内置分布式训练自适应系统,覆盖训练的全生命周期,满足了大模型训练的诸多诉求,提供资源使用视图、计算与网络调度策略、分布式训练加速、训练监控、训练容错与自愈能力,在加速训练的同时,能够自动定位故障和恢复任务,保证了训练的稳定性和效率。某银行客户在 AIStation 智能容错的机制保障下,在极其严苛的业务投产测试中能够实现快速故障排查和恢复,大幅降低业务投产上线时间。
三、AIStation 助力行业提升大模型开发效率
AIStation 平台在 AI 开发、应用部署和大模型工程实践上积累了宝贵的经验和技术,帮助诸多行业客户在资源、开发、部署层面实现降本增效。在垂直行业领域,AIStation 平台帮助头部金融客户、生物制药服务公司快速利用密集数据训练、验证大模型,大大降低大模型业务成本。某大型商业银行基于 AIStation 打造的并行运算集群,凭借领先的大规模分布式训练支撑能力,荣获 2022 IDC“未来数字基础架构领军者”奖项。
浪潮信息 AIStation 在大模型方面已经取得了诸多业界领先的经验和积累,实现了端到端的优化,是更适合大模型时代的人工智能平台。未来 AIStation 将与浪潮信息 OGAI 软件栈一同进化,进一步通过低代码、标准化的大模型开发流程,以及低成本和高效的推理服务部署,帮助客户快速实现大模型开发和落地,抢占先机。
作者介绍
Leon Wang,浪潮信息高级产品经理,山东大学、法国马赛粒子物理中心理学博士,CERN 访问学者,致力于人工智能基础设施与算法的产品设计和生态建设,参与多项相关国家标准制定工作,申请发明专利 10 余项并授权 6 项,发表相关国际国内学术论文 4 篇。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论