

一、背景渊源
1、摩尔定律
提到多线程好多书上都会提到摩尔定律,它是由英特尔创始人之一 Gordon Moore 提出来的。其内容为:当价格不变时,集成电路上可容纳的元器件的数目,约每隔 18-24 个月便会增加一倍,性能也将提升一倍。换言之,每一美元所能买到的电脑性能,将每隔 18-24 个月翻一倍以上。这一定律揭示了信息技术进步的速度。
可是从 2003 年开始 CPU 主频已经不再翻倍,而是采用多核,而不是更快的主频。摩尔定律失效。那主频不再提高,核数增加的情况下要想让程序更快就要用到并行或并发编程。
2、并行与并发
如果 CPU 主频增加程序不用做任何改动就能变快。但核多的话程序不做改动,不一定会变快。
CPU 厂商生产更多的核的 CPU 是可以的,一百多核也是没有问题的,但是软件还没有准备好,不能更好的利用,所以没有生产太多核的 CPU。随着多核时代的来临,软件开发越来越关注并行编程的领域。但要写一个真正并行的程序并不容易。
并行和并发的目标都是最大化 CPU 的使用率,并发可以认为是一种程序的逻辑结构的设计模式。可以用并发的设计方式去设计模型,然后运行在一个单核的系统上。可以将这种模型不加修改的运行在多核系统上,实现真正的并行,并行是程序执行的一种属性真正的同时执行,其重点的是充分利用 CPU 的多个核心。
多线程开发的时候会有一些问题,比如安全性问题,一致性问题等,重排序问题,因为这些问题大家在写代码的时候会加锁等等。这些基础概念大家都懂,本文不再描述。 本文主要分享造成这些问题的原因和 Java 解决这些问题的底层逻辑。
二、多线程
2.1 计算机存储体系
要想明白数据一致性问题,要先捋下计算机存储结构,从本地磁盘到主存到 CPU 缓存,也就是从硬盘到内存,到 CPU。一般对应的程序的操作就是从数据库查数据到内存然后到 CPU 进行计算。这个描述有点粗,下边画个图。
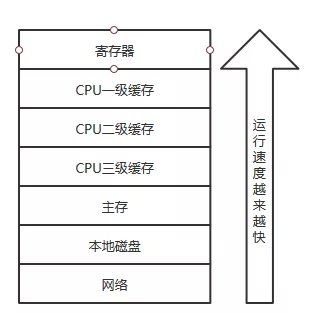
业内画这个图一般都是画的金字塔型状,为了证明是我自己画的我画个长方型的(其实我不会画金字塔)。
CPU 多个核心和内存之间为了保证内部数据一致性还有一个缓存一致性协议(MESI),MESI 其实就是指令状态中的首字母。M(Modified)修改,E(Exclusive)独享、互斥,S(Shared)共享,I(Invalid)无效。然后再看下边这个图。
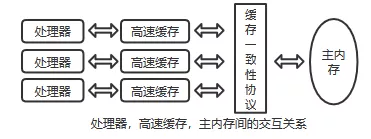
太细的状态流转就不作描述了,扯这么多主要是为了说明白为什么会有数据一致性问题,就是因为有这么多级的缓存,CPU 的运行并不是直接操作内存而是先把内存里边的数据读到缓存,而内存的读和写操作的时候就会造成不一致的问题。解决一致性问题怎么办呢,两个思路:
锁住总线,操作时锁住总线,这样效率非常低,所以考虑第二个思路。
缓存一致性,每操作一次通知(一致性协议 MESI) (但多线程的时候还是会有问题,后文讲)
2.1 Java 内存模型
上边稍微扯了一下存储体系是为了在这里写一下 Java 内存模型。
Java 虚拟机规范中试图定义一种 Java 内存模型(Java Memory Model) 来屏蔽掉各种硬件和操作系统的内存访问差异,以实现 让 Java 程序在各种平台下都能达到一致的内存访问效果。J
内存模型是内存和线程之间的交互、规则。与编译器有关,有并发有关,与处理器有关。
Java 内存模型的主要目标是定义程序中各个变量的访问规则,即在虚拟机中将变量存储到内存和从内存中取出变量这样的底层细节。 此处的变量与 Java 编程中所说的变量有所区别, 它包括了实例字段、静态字段和构成数组对象的元素,但 不包括局部变量与方法参数,因为后者是线程私有的,不会被共享,自然就不会存在竞争问题。为了获得较好的执行效能,Java 内存模型并没有限制执行引擎使用处理器特定寄存器或缓存来和主内存进行交互,也没有限制即时编译器进行调整代码执行顺序这类优化措施。
Java 内存模型规定了所有的变量都存储在主内存中。每条线程还有自己的工作内存,线程的工作内存中保存了该线程使用到的变量的主内存副本拷贝,线程对变量的所有操作(读取,赋值等 )都必需在工作内存中进行,而不能直接读写主内存中的变量。不同的线程之间也无法直接访问对方工作内存中的变量,线程间变量值的传递均需要通过主内存来完成。
这里所说的主内存、工作内存和 Java 内存区域中的 Java 堆、栈、方法区等并不是同一个层次的内存划分,这两者基本上是没有关系的。 如果两者一定要勉强对应起来,那从变量、主内存、工作内存的定义来看,主内存对应 Java 堆中的对象实例数据部分 ,而工作内存则对应于虚拟机栈中的部分区域。从更底层次上说,主内存就是直接对应于物理硬件的内存,而为了获取更好的运行速度,虚拟机可能会让工作内存优先存储于寄存器和高速缓存中,因为程序运行时主要访问读写的是工作内存。
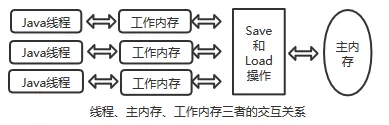
前边说的都是和内存有关的内容,其实多线程有关系的还有指令重排序,指令重排序也会造成在多线程访问下结束和想的不一样的情况。大段的介绍就不写了要不篇幅太长了(JVM 那里书里边有)。主要就是 在 CPU 执行指令的时候会进行执行顺序的优化。画个图看一下吧。

具体理论后文再写先来点干货,直接上代码,一看就明白。
猜猜有可能输出什么?多选
A:a=0,b=1
B:a=1,b=0
C:a=0,b=0
D:a=1,b=1
上边这段代码不太好调,然后我稍微改造了一下。
这段代码,a 和 b 初始值为 0,然后两个线程同时启动分别设置 a=1,x=b 和 b=1,y=a。这个代码里边的 starta 和 startb 线程完全是为了让 threada 和 threadb 两个线程尽量同时启动而加的,里边只是分别调用了 threada 和 threadb 两个线程。然后无限循环只要 x 和 y 不同时等于 0 就初始化所有值继续循环,直到 x 和 y 都是 0 的时候 break。你猜猜会不会 break。
结果看截图:
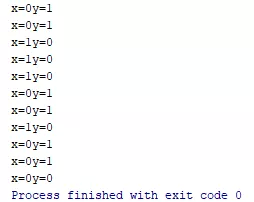
因为我没有记录循环次数,不知道循环了几次,然后触发了条件 break 了。从代码上看,在输出 A 之前必然会把 B 设置成 1,在输出 B 之前必然会把 A 设置为 1。那为什么会出现同时是零的情况呢。这就很有可能是指令被重排序了。
指令重排序简单了说是就两行以上不相干的代码在执行的时候有可能先执行的不是第一条。也就是执行顺序会被优化。
如何判断你写的代码执行顺序会不会被优化?要看代码之间有没有 Happens-before 关系。Happens-before 就是不无需任何干涉就可以保证有有序执行,由于篇幅限制 Happens-before 就不在这里多做介绍。
下面简单介绍一下 Java 里边的一个关键字 volatile。volatile 简单来说就是来解决重排序问题的。对一个 volatile 变量的写,一定 happen-before 后续对 J 它的读。也就是你在写代码的时候不希望你的代码被重排序就使用 volatile 关键字。volatile 还解决了内存可见性问题,在执行执行的时候一共有 8 条指令 lock(锁定)、read(读取)、load(载入)、use(使用)、assign(赋值)、store(存储)、write(写入)、unlock(解锁)(篇幅限制具体指令内容自行查询,看下图大概有个了解)。
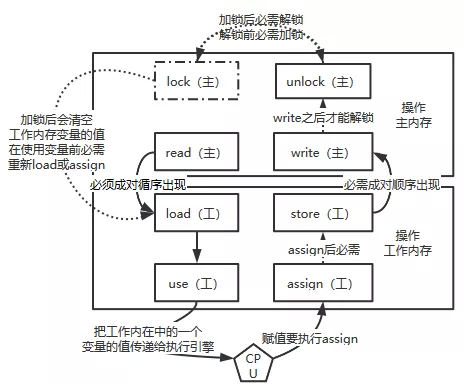
volatile 主要是对其中 4 条指令做了处理。如下图
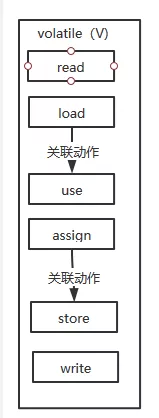
也就是把 load 和 use 关联执行,把 assign 和 store 关联执行。众所周知有 load 必需有 read 现在 load 又和 use 关联也就是要在缓存中要 use 的时候就必须要 load 要 load 就必需要 read。通俗讲就是要 use(使用)一个变量的时候必需 load(载入),要载入的时候必需从主内存 read(读取)这样就解决了读的可见性。下面看写操作它是把 assign 和 store 做了关联,也就是在 assign(赋值)后必需 store(存储)。store(存储)后 write(写入)。也就是做到了给一个变量赋值的时候一串关联指令直接把变量值写到主内存。就这样 通过用的时候直接从主内存取,在赋值到直接写回主内存做到了内存可见性。
2.3 无锁编程
我在网上看到大部分写多线程的时候都会写到锁,AQS 和线程池。由于网文太多本文就不多做介绍。下面简单写一写 CAS。
CAS 是一个比较魔性的操作,用的好可以让你的代码更优雅更高效。它就是无锁编程的核心。
CAS 书上是这么介绍的: “CAS 即 Compare and Swap,是 JDK 提供的非阻塞原子性操作,它通过硬件保证了比较-更新的原子性” 。他是非阻塞的还是原子性,也就是说这玩意 J 效率更高。还是通过硬件保证的说明这玩意更可靠。
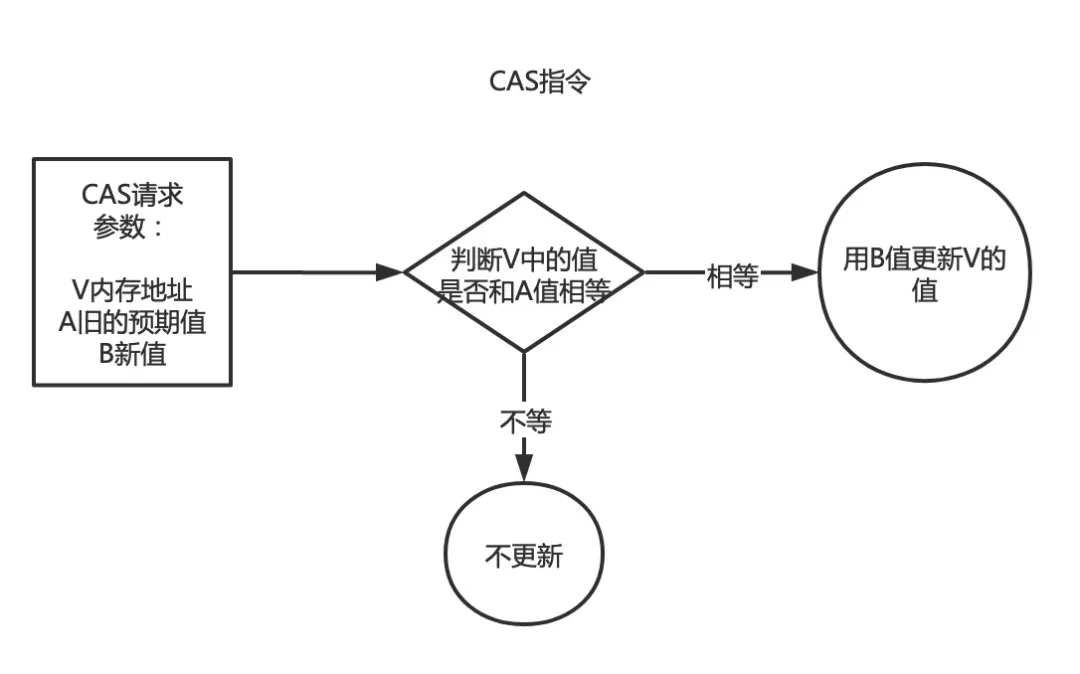
从上图可以看出,在 cas 指令修改变量值的时候,先要进行值的判断,如果值和原来的值相等说明还没有被其它线程改过,则执行修改,如果被改过了,则不修改。在 Java 里边 java.util.concurrent.atomic 包下边的类都使用了 CAS 操作。最常用的方法就是 compareAndSet。其底层是调用的 Unsafe 类的 compareAndSwap 方法。
本文转载自公众号宜信技术学院(ID:CE_TECH)。
原文链接:
https://mp.weixin.qq.com/s/vBwUPH1kSy-hF8wuZ2XD8g

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论