
本文最初发表于scaleyourapp.com网站,经原作者Shivang Sarawagi授权由 InfoQ 中文站翻译分享。
YouTube 是仅次于谷歌的第二大热门网站。在 2019 年 5 月,每分钟会有超过 500 小时的视频内容上传到该平台。
该视频共享平台有超过 20 亿的用户,每天有超过10亿小时的视频被播放,产生数十亿的浏览量。这些都是令人难以置信的数字。
本文会对 YouTube 使用的数据库和后端数据基础设施进行深入讲解,它们使得该视频平台能够存储如此巨量的数据,并能扩展至数十亿的用户。
那我们就开始吧。
1.引言
YouTube 的旅程开始于 2005 年。随着这家由风险资本资助的技术初创公司不断取得成功,它于 2006 年 11 月被谷歌以 16.5 亿美元收购。
在被谷歌收购之前,它们的团队由以下人员组成:
两名系统管理员
两名可扩展性软件架构师
两名特性开发人员
两名网络工程师
一名 DBA
2.后端基础设施
YouTube 的后端微服务是由Python、数据库、硬件、Java(使用了Guice框架)和 Go 编写的。用户界面是使用JavaScript编写的。
主要的数据库是由 Vitess 支撑的 MySQL,Vitess是一个数据库集群系统,用于 MySQL 的水平扩展。另外,使用 Memcache 实现缓存并使用 Zookeeper 进行节点的协调。
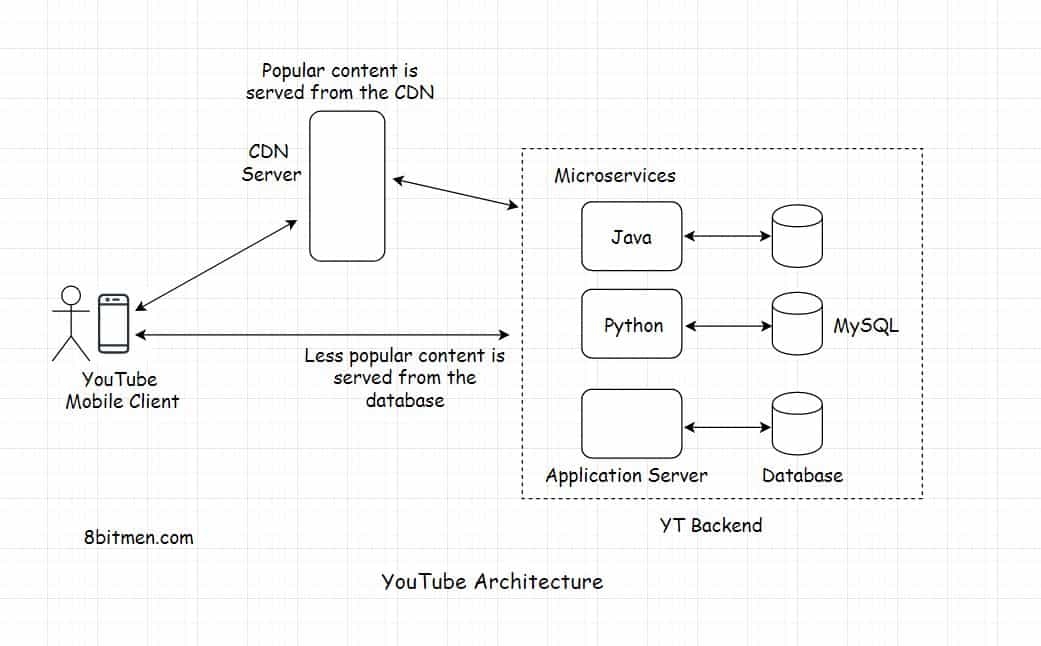
流行的视频通过 CDN 来提供,而一般的、较少播放的视频则从数据库中获取。
每个视频在上传的时候,都会赋予一个唯一的标识符并且会由一个批处理 job 进行处理,该 job 会运行多个自动化的过程,比如生成缩略图、元数据、视频脚本、编码、设置货币化状态等。
VP9 & H.264/MPEG-4 AVC 高级视频编码(Advanced Video Coding codecs)会用于视频压缩,它能够使用其他编码器一半的带宽来编码 HD 和 4K 质量的视频。
视频流则是使用基于HTTP协议的动态自适应流(Dynamic Adaptive Streaming),这是一种自适应比特率的流媒体技术,能够从传统的 HTTP Web 服务器上实现高质量的视频流。通过这种技术,内容可以按照不同的比特率提供给观众。YouTube 客户端会根据观看者的互联网连接速度自动适应视频渲染,从而尽可能减少缓冲时间。
我曾经在一篇专门的文章中讨论过 YouTube 的视频转码过程,参见“YouTube是如何以低延迟提供高质量视频的”。
所以,这里对平台的后端技术有一个快速的介绍。YouTube 主要使用的数据库是 MySQL。现在,我们了解一下 YouTube 的工程团队为什么觉得有必要编写 Vitess?他们在最初的 MySQL 环境中面临的问题是什么,使他们在此基础上实现了一个额外的框架?
3.为何需要 Vitess
网站最初只有一个数据库实例。随着网站的发展,为了满足日益增长的 QPS(每秒查询次数)需求,开发人员不得不对数据库进行水平扩展。
3.1 主-从副本
副本会添加到主数据库实例中。读取请求会被路由到主数据库和副本上,以减少主数据库的负载。添加副本有助于缓解瓶颈,增加读取的吞吐量,并增加系统的持久性。
主节点处理写入的流量,主节点和副本节点同时处理读取流量。
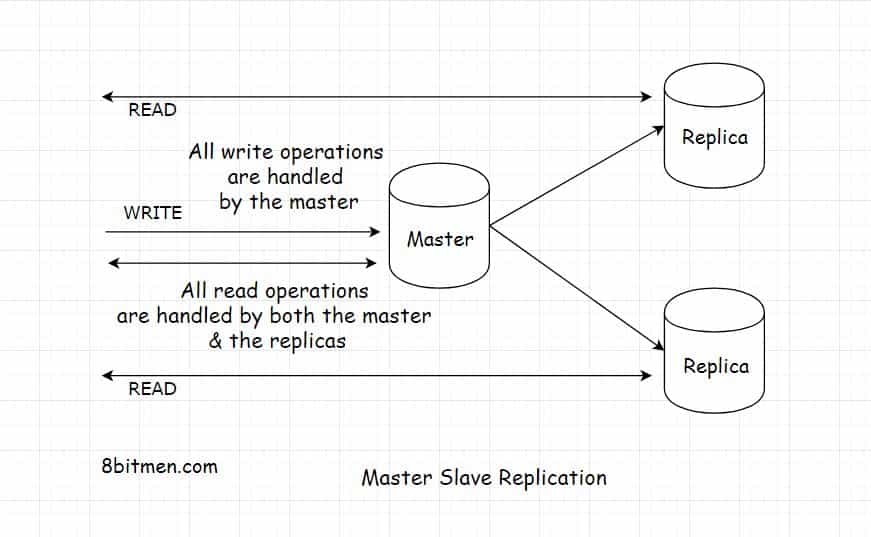
但是,在这种场景中,有可能会从副本中读取到陈旧的数据。如果在主节点将信息更新到副本之前,一个请求读取了副本的数据,那么观看者就会得到陈旧的数据。
此时,主节点和副本节点的数据是不一致的。在这种情况下,不一致的数据是主节点和副本节点上特定视频的观看次数。
其实,这完全没有问题。观众不会介意观看次数上略微有点不一致,对吧?更重要的是,视频能够在他们的浏览器中渲染出来。
主节点和副本节点之间的数据最终会是一致的。
因此,工程师们觉得非常开心,观众们也非常开心。随着副本的引入,事情进展顺利。
网站继续受到欢迎,QPS 继续上升。主-从副本策略现在很难跟上网站流量的增长了。
那现在该怎么办?
3.2 分片
下一个策略就是对数据库进行分片(shard)。分片是除了主-从副本、主-主副本、联盟和反范式化(de-normalization) 之外,扩展关系型数据库的方式之一。
数据库分片并不是一个简单的过程。它大大增加了系统的复杂性,并使得管理更加困难。
但是,数据库必须要进行分片,以满足 QPS 的增长。在开发人员将数据库分片后,数据会被分散到多台机器上。这增加了系统写入的吞吐量。现在,不再是只有一个主实例处理写入,写入操作可以在多台分片的机器上进行。
同时,每台机器都创建了单独的副本,以实现冗余和吞吐。
该平台的受欢迎程度持续上升,大量的数据被内容创作者不断添加到数据库中。
为了防止机器故障或者外部未知事件造成的数据丢失或服务不可用,此时需要在系统中添加灾难管理的功能了。
3.3 灾难管理
灾难管理指的是在面临停电和自然灾害(如地震、火灾)时的应急措施。它需要进行冗余,并将用户数据备份到世界不同地理区域的数据中心。丢失用户数据或服务不可用是不允许的。
在世界范围内拥有多个数据中心也有助于 YouTube 减少系统延迟,因为用户请求会被路由到最近的数据中心,而不是路由到位于不同大陆的原始服务器。
现在,你可以想象基础设施会变得多复杂。
经常会有未经优化的全表扫描导致整个数据库瘫痪。数据库必须进行保护,防止受到不良查询的影响。所有的服务器都需要被跟踪以确保服务的高效性。
开发人员需要有一个系统来抽象系统的复杂性,能够让他们解决可扩展性的挑战,并以最小的成本管理该系统。这一切促使 YouTube 开发了 Vitess。
4.Vitess:用于水平扩展 MySQL 数据库集群的系统
Vitess是一个运行于 MySQL 之上的数据库集群系统,能够使 MySQL 进行水平扩展。它有内置的分片特性,能够让开发人员扩展数据库,而不必在应用中添加任何的分片逻辑。这类似于 NoSQL 的做法。
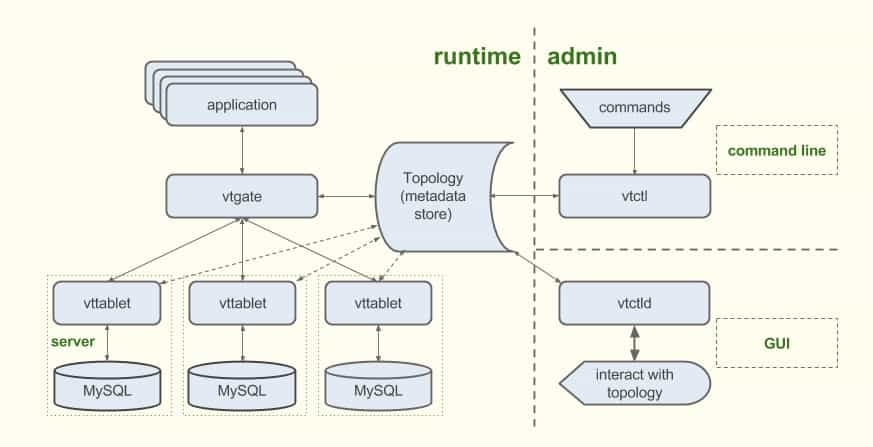
Vitess 架构,图片来源
Vitess 还会自动处理故障转移和备份。它能够管理服务器,通过智能重写资源密集型的查询和实现缓存来提高数据库性能。除了 YouTube,该框架还被业界的其他知名厂商使用,如 GitHub、Slack、Square、New Relic 等。
当你需要 ACID 事务和强一致性的支持,同时又希望像 NoSQL 数据库一样快速扩展关系型数据库时,Vitess 就会大显身手。
在 YouTube,每个 MySQL 连接都有 2MB 的开销。每一个连接都有可计算出来的成本,而且随着连接数量的增加,还必须增加额外的 RAM。
通过基于 Go 编程语言并发支持构建的连接池,Vitess 能够以很低的成本管理这些连接。它使用 Zookeeper 来管理集群,并使其保持最新状态。
5.部署到云中
Vitess 是云原生的,很适合云中部署,因为就像云的模式一样,容量是逐步添加到数据库的。它可以作为一个 Kubernetes 感知(Kubernetes-aware)的云原生分布式数据库运行。
在 YouTube,Vitess 在容器化环境中运行,并使用 Kubernetes 作为容器编排工具。
在如今的计算时代,每个大规模的服务都在分布式环境的云中运行。在云中运行服务有许多好处。
Google Cloud Platform是一套云计算服务,它的基础设施与谷歌内部的终端用户产品(如谷歌搜索和 YouTube)所用的基础设施是相同的。
每个大规模的在线服务都有一个多样化(polyglot)的持久性架构,因为某一种数据模型,无论是关系型还是 NoSQL,都无法处理服务的所有使用场景。
在为本文展开的研究中,我无法找到 YouTube 所使用的具体谷歌云数据库的清单,但我非常肯定它会使用 GCP 的特有产品,如 Google Cloud Spanner、Cloud SQL、Cloud Datastore、Memorystore 等来运行服务的不同特性。
这篇文章详细介绍了其他谷歌服务所使用的数据库,如Google Adwords、Google Finance、Google Trends等。
6.CDN
YouTube 使用谷歌的全球网络进行低延迟、低成本的内容传输。借助全球分布的 POP 边缘点,它能够使客户能够更快地获取数据,而不必从原始服务器获取。
所以,到此为止,我已经谈到了 YouTube 使用的数据库、框架和技术。现在,该谈一谈存储问题了。
YouTube 是如何存储如此巨大的数据量的呢(每分钟上传 500 小时的视频内容)?
7.数据存储:YouTube 是如何存储如此巨大的数据量的呢?
视频会存储在谷歌数据中心的硬盘中。这些数据由 Google File System 和 BigTable 管理。
GFS Google File System是谷歌开发的一个分布式文件系统,用于管理分布式环境中的大规模数据。
BigTable是一个建立在 Google File System 上的低延迟分布式数据存储系统,用于处理分布在成千上万台机器上的 PB 级别的数据。60 多个谷歌产品都使用了它。
因此,视频被存储在硬盘中。关系、元数据、用户偏好、个人资料信息、账户设置、从存储中获取视频所需的相关数据等都存储在 MySQL 中。
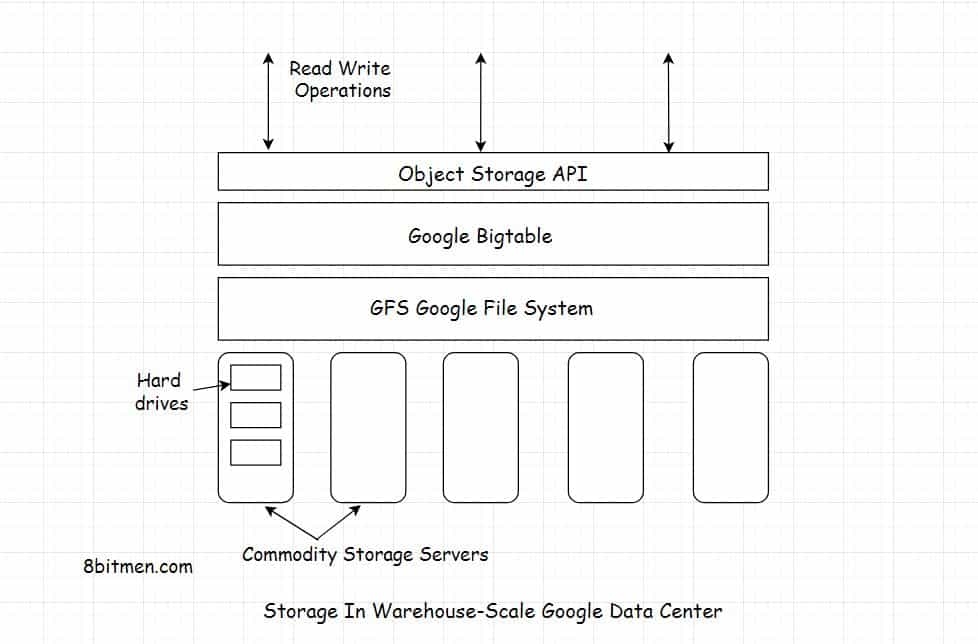
7.1 即插即用的商用服务器
谷歌数据中心拥有同质化的硬件,软件则是内部构建的,管理成千上万的独立服务器集群。
谷歌部署的服务器,能够增强数据中心的存储能力,它们都是商用服务器(commodity server),也被称为商用现成的服务器(commercial off-the-shelf server)。这些服务器价格低廉,可广泛使用和大量购买,并能以最小的成本和代价替换或配置数据中心的相同硬件。
随着对额外存储需求的增加,新的商用服务器会被插入到系统中。
出现问题后,商用服务器通常会被直接替换,而不是进行修理。它们不是定制的,与运行定制的服务器相比,使用它们能够使企业在很大程度上减少基础设施成本。
7.2 为数据中心设计的存储磁盘
YouTube 每天都需要超过一个 PB 的新存储。旋转硬盘驱动器是主要的存储介质,因为其成本低,可靠性高。
SSD 固态硬盘比旋转磁盘具有更高的性能,因为它们是基于半导体的,但大规模使用固态硬盘并不划算。
它们相当昂贵,也容易随着时间的推移逐渐丢失数据。这使得它们不适合用于归档数据的存储。
另外,谷歌正在开发一个适用于大规模数据中心的新磁盘系列。
有五个关键指标可用来判断为数据存储而构建的硬件的质量:
硬件应该有能力支持秒级的高速度输入输出操作。
它应该符合组织规定的安全标准。
与普通存储硬件相比,它应该有更高的存储容量。
硬件采购成本、电力成本和维护费用应该都是可以接受的。
磁盘应该是可靠的,并且延迟是稳定的。




