
对于一个分布式计算引擎(尤其是 7*24 小时不断运行的流处理系统)来说,由于机器故障、数据异常等原因导致作业失败的情况是时常发生的,因此一般的分布式计算引擎如 Hadoop、Spark 都会设计状态容错机制确保作业失败后能够恢复起来继续运行,而新一代的流处理系统 Flink 在这一点上更有着优秀而简约的设计。
每个框架都有与之相关的诸多概念,常常令开发者感到困惑。本文会尽量避免从官方文档的角度进行论述,而是尝试先跳出具体的框架,从原理上分析分布式计算引擎状态容错机制的设计思想。通过对比 Hadoop、Spark、Flink 关于这一点的不同思考,更能了解到批处理系统和流处理系统如何看待状态与容错这件事。
何谓状态?
并不是分布式计算引擎才有状态的概念。从广义上来讲,任何一个程序,在运行时的某一时刻其进程中各个字段、变量在内存中的值,都是状态。
例如,一个程序从一个文件中读取数据,程序在内存中记录下来文件读取到了什么位置,将其保存在某个对象的 offset 字段中,以便接下来从该位置继续读取。这个 offset 字段的值其实就是一个有业务含义的“状态”值。
既然任何程序都有状态,那么对于任何一个分布式计算框架来说,无需任何特殊的设计,“状态”便天然地存在于其运行时的内存中。框架可以对这些状态进行维护(例如将其持久化),实现任何框架想要实现的目的(例如将其用于接下来将要讲到的容错机制中)。
那么这里的问题则是,各个框架是选取哪些字段、变量的值进行管理的呢?这便是理解各个框架状态与容错机制的关键。
何谓容错?
显然,并不是任何程序、框架都必须实现容错机制。在大数据计算领域常常把一个作业分类成流计算或批计算。对于批计算而言,容错并不是一个必不可少的机制,因为大部分批处理任务在时间和计算资源上来说都是可控的。如果作业在中途异常停止,大不了可以重新再运行一次。
然而,对于流处理作业并不是这样。因为从业务上来说,流处理作业会 7*24 地不间断运行。设想如果一个流处理作业运行了一年,突然因为一些异常原因挂掉,或者因为发现了脏数据或逻辑问题而手动停止,如果这时没有容错机制,则需要从一年前的数据开始从头运行。这在时间和计算成本上来说都无法接受。
如果一个作业需要容错,往往指的就是这样一个过程:
程序在运行的过程当中,在某一时刻对其状态进行落盘存储。在未来的某一时刻,程序因为某种原因停止后,可以从之前落盘的数据重启并继续正常稳定地运行。
用通俗的话说就是一个存档、读档的过程。整个过程如下图所示:
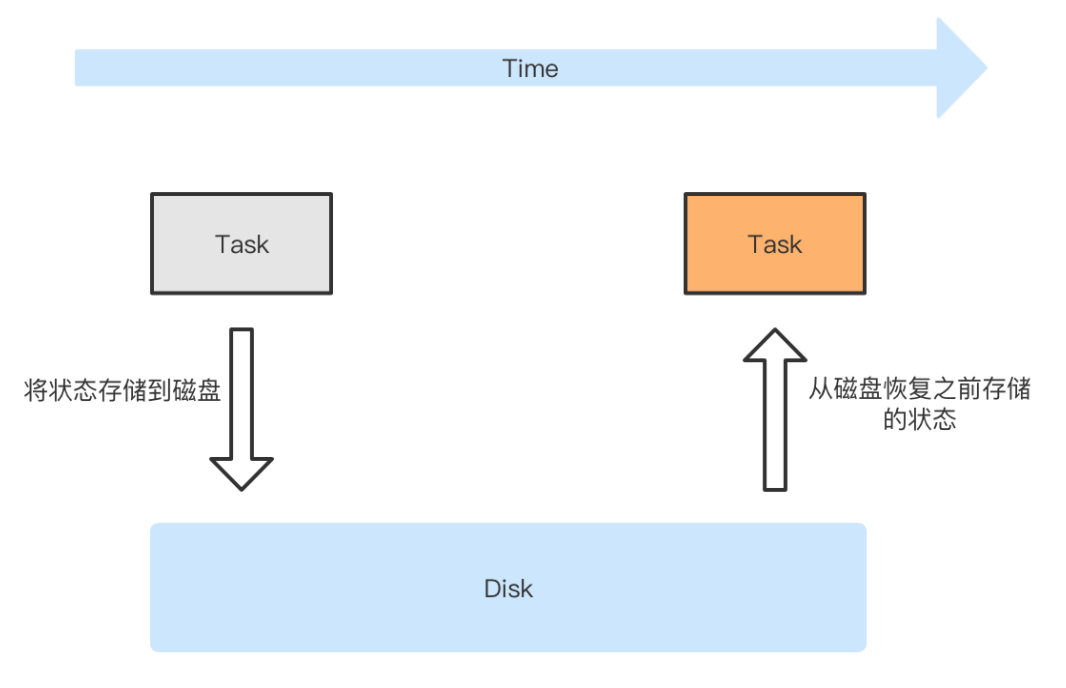
注意:由于这里讨论的是广义上的容错,因此要特意指出,之前存储状态的程序,与后来恢复状态的程序,未必是同一个程序,即程序内部的逻辑是可以完全不同的,只要该程序可以读取磁盘中的状态即可。至于读取以后要怎么利用这些状态,那是业务需要考虑的事情。如果对这一点没有清晰的认识,就会困惑于 Flink、Spark 这些计算引擎是否可以在做了 checkpoint 后修改程序的逻辑,修改过后是否还能正常重启。这里可以非常负责任地讲,即便有些版本的 Flink、Spark 未必支持修改后的程序从之前的检查点恢复,只要我们理解了其内在原理,都可以自己修改源码或通过其他手段使其做到这一点。
状态与容错的关系
综上,状态指的是某一时刻程序中各个字段、变量等在内存中的值,容错指的是对这些状态进行存储落盘、读取恢复的过程。因此,关键之处在于选取哪些值进行存储和恢复,以保证这样的存储和恢复具有业务价值。对这一点的理解与取舍,便是不同框架对状态与容错机制设计的出发点。
本节脱离具体的框架试举几例,大家可以自行对号入座,看这样的设计思路接近于哪个框架。
存储处理数据后的结果:在计算模型中,将数据按条处理。可以在处理数据的算子中定义一个字段,每处理一条数据,就按照业务逻辑对该字段进行更新。在进行状态存储时,仅存储该字段的值。在作业重启时,只需恢复该字段的值。
存储数据本身:在计算模型中,以数据集的方式处理数据。数据集会被多个算子处理,因此可以在它被某个算子处理完后将这个中间结果保存下来。这样在恢复时,就可以从这个完整的中间结果开始继续运行。
存储数据位置:由于计算引擎的数据一定有一个数据源,而某些数据源会为每条数据记录它在数据源中的位置。计算引擎可以将读取到的最新一条数据在数据源的位置记录下来,将其作为状态保存和恢复。
在不同的业务和技术场景下,状态与容错的解决方案理论上有无穷多,与每个计算框架的计算模型紧密相关。此外,一个框架的状态与容错机制能达到什么样的效果,还跟与其对接的组件有关(端到端的数据一致性问题)。比如上述第三例,倘若数据源并没有记录数据的位置信息,那么该容错机制也无法有效运行。
Hadoop 与 Spark 如何设计容错
一般来说,最朴素的想法就是通过下面的步骤实现状态与容错:
暂停所有数据的接收。
每个任务处理当前已经接收的数据。
将此时所有任务的状态进行持久化。
恢复数据的接收和处理。
当作业出现异常时,则可以从之前持久化的地方恢复。Hadoop 与 Spark 的容错机制就是该思想的实现。
Hadoop 的任务可以分为 Map 任务和 Reduce 任务。这是两类分批次执行的任务,后者的输入依赖前者的输出。Hadoop 的设计思想十分简单——当任务出现异常时,重新跑该任务即可。其实,跑成功的任务的输出,就相当于整个作业的中间结果得到了持久化。比如 Reduce 任务异常重跑时,就不必重跑它依赖的 Map 任务。
Spark 的实现也是这一想法的延续。虽然 Spark 不是 Hadoop 那样的批处理,但是它仍然把一个“微批(micro batch)”当作数据处理的最小单元,整个框架实际上延续了不少批处理的思想。Spark 的容错机制相当经典,用到了其 RDD 的血统关系(lineage)。熟悉 Spark 的读者应该了解“宽依赖”、“窄依赖”等概念。当 RDD 中的某个分区出现故障,那么只需要按照这种依赖关系重新计算即可。以复杂一些的宽依赖为例,Spark 会找到其父分区,经过计算重新获取结果。
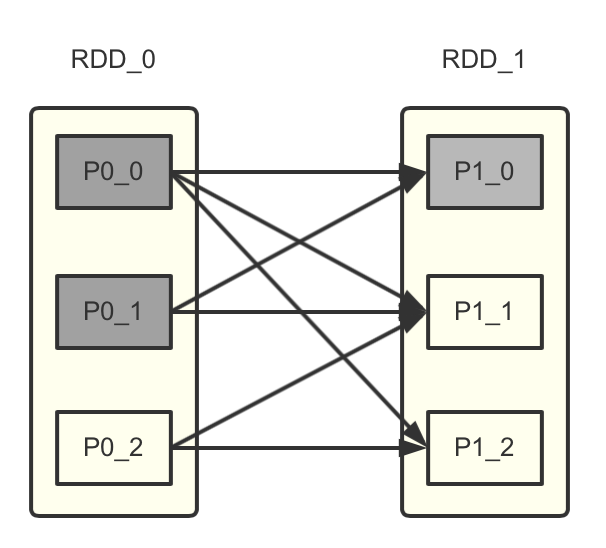
如上图所示,如果 P10 发生故障,则 P00 与 P01 都会重新计算,而计算 P00 和 P01 又会继续找其父分区重新计算。按照这个血缘关系来看,一直向上追溯会付出极大的代价。因此 Spark 提供了将分区计算结果持久化的方法。如果 P00 与 P0_1 的数据进行了持久化,那么就可以利用该结果直接恢复状态。
从以上设计可以感受到,这种实现更适合于批计算的框架中。它相当于将前一个阶段的计算结果“存档”下来,然后在任意时间后将该结果作为输入,运行下一个阶段的任务。这种实现的状态存储过程显然过于繁重,并不太适用于对“低延时”要求极高的流处理引擎。因此,Flink 设计了一套完全不同的分布式轻量级实现方式,并精巧地实现了各种一致性语义。
Flink 的容错机制——通过 Barrier 实现一致性语义
官方文档是这样描述 Flink 的:
Stateful Computations over Data Streams
即,在数据流上的状态计算。可以说,状态计算(包括状态管理、检查点机制等)是它最大的特点之一。
下面介绍 Flink 状态容错机制的设计原理。
从单机程序开始
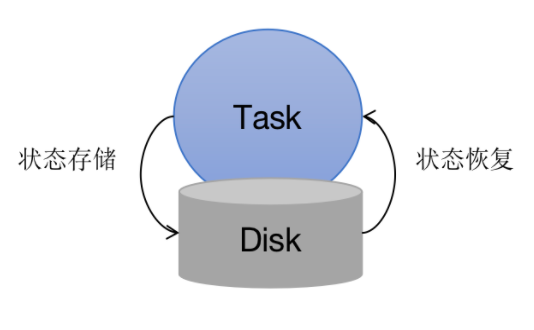
现在跳出 Flink 框架,设想一个运行在单个节点的进程,该如何设计容错机制。
比较容易想到的一个思路是,在主线程外另开启一个线程执行定时任务,定期地将状态数据刷写到磁盘。当作业停止后重启,则可以直接从之前刷写到磁盘的数据恢复。如下图所示:
分布式容错
延续这个思路,是否可以设计一个分布式的容错机制呢?下图是一个多节点 的分布式任务,数据流从左至右。
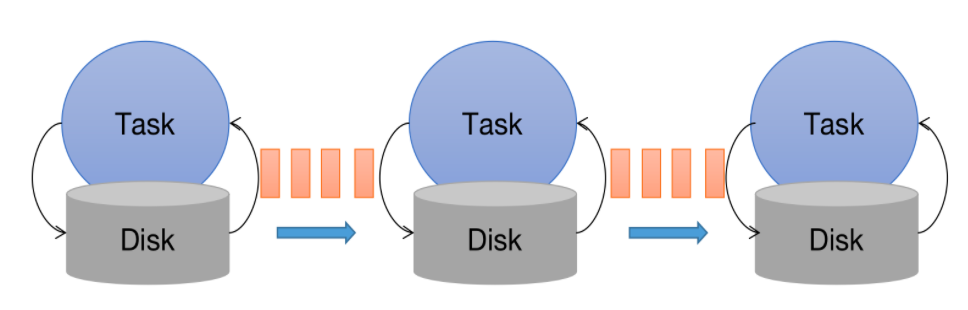
如果给这些 Task 分别开启一个线程运行定时任务,这些分布在不同物理机上的任务的确也可以做到状态的存储和恢复。然而,这种粗暴的处理方式极容易发生业务上的异常。比如,当最左边的 Task 处理完了 a、b、c 这三条数据后,将数据发送至网络,在这三条数据还未到达中间的 Task 时,三个线程同时(假设时间同步非常理想)触发了状态存储的动作。这时左边的 Task 保存的状态是处理完 a、b、c 后的状态,而后两个 Task 保存的是未处理这三条数据时的状态。此时整个集群宕机,三个 Task 恢复后,左边的 Task 将从 a、b、c 这三条数据后的数据开始读取和处理,而后面的 Task 将永远无法接收到这三条数据。这就造成了数据的丢失。如果三个机器线程的触发时间不同步,也可能会造成数据重复处理。
这个问题在流处理中被称为“一致性语义”问题。当一条数据在计算引擎中被处理“至少一次”、“恰好一次”、“最多一次”时,一致性语义分别是“at least once”、“exactly once”、“at most once”。
不同的业务场景对于一致性语义有着不同的要求。举例来说,一个广告投放平台按照用户对广告的点击量进行收费,如果点击量被少算,则对平台方不利,如果点击量被多算,则对广告商不利,无论哪种情况都不利于长期合作。在这种情况下,“exactly once”语义就显得尤为重要。
基于 Flink 的计算模型与数据传输方式的设计,容错机制由 Barrier 来实现。Barrier 可以理解为一条数据,被周期性地插入到数据流当中,跟随数据一起被传输到下游。
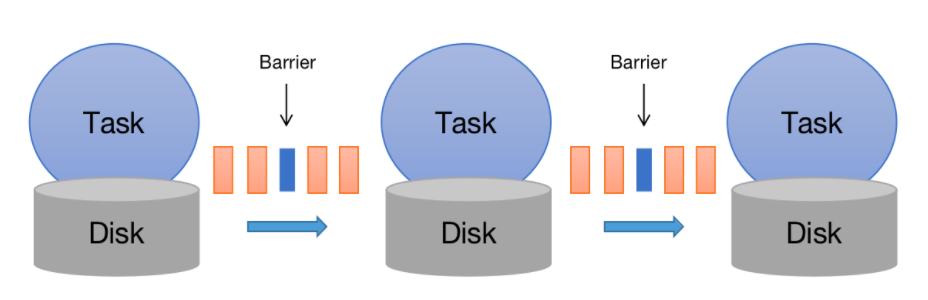
此时,每个任务将不再需要另启一个线程完成定时任务,只需要在接收到 Barrier 时触发存储状态的动作即可。由于数据传输的有序性,这样的机制可以保证“exactly once”语义。
为什么这里说“可以”保证“exactly once”语义,而没有说“必然”保证该语义呢?这是因为作业的拓扑图可能更加复杂,如下图所示:
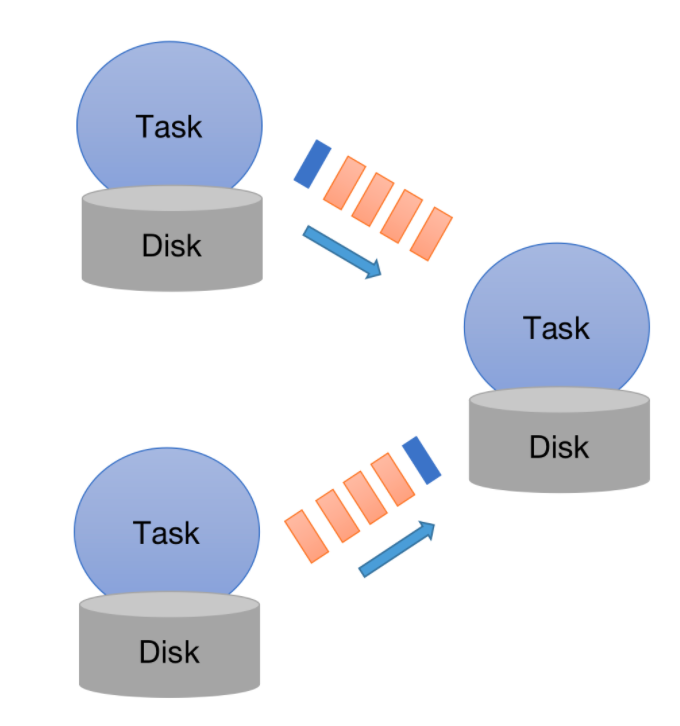
如果一个进程的上游有多条数据流,那么它应该在接受到哪个 Barrier 时触发状态存储操作呢?
以上图为例,当最右边的进程接收到下面的数据流传来的 Barrier 时,它可以先不触发任何操作,该数据流后面的数据也暂时不做处理,而是将这些数据接收到缓存中。上面的数据流照常处理。当接收到了上面的数据流传来的 Barrier 时,再触发状态存储操作。这样仍可以保证“exactly once”语义。
很显然,在了解了这个原理后,就可以在这个过程中可以添加任何自己业务需要的策略。如可以不让 Barrier 对齐就触发操作,或是每条 Barrier 都触发一次操作,甚至可以将部分数据丢弃,等待最后一个 Barrier 到来时触发操作……这些不同的策略对应了不同的一致性语义。Flink 实现了“exactly once”语义和“at least once”语义。
Flink 中的状态存储与恢复
最后,从整体流程上来理解 Flink 的状态存储与恢复。
状态的存储流程大致可以拆分为以下几个部分进行理解:Checkpoint 的触发、Barrier 的传输、状态的更新、状态数据及其元信息的存储。从系统架构上来看,整个流程如下图所示:
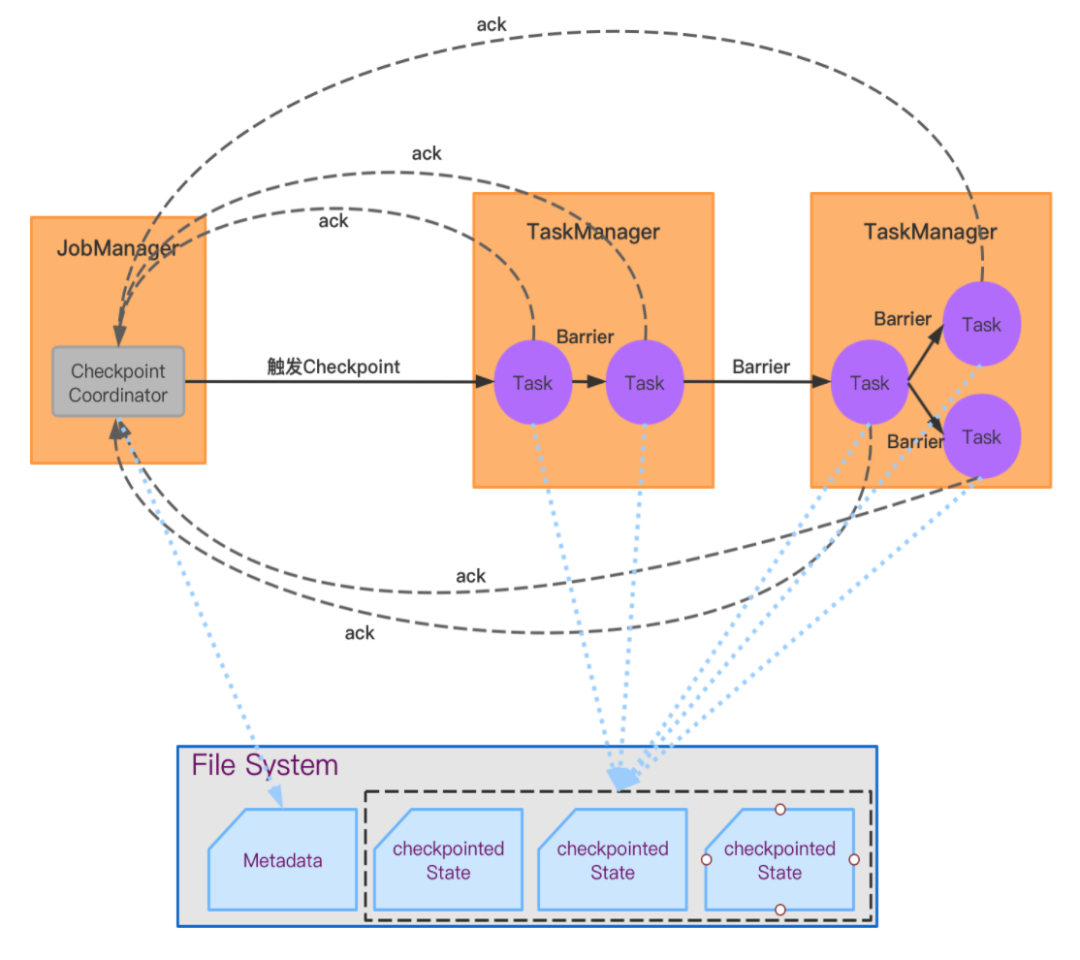
在 JobManager 端有一个组件叫做 CheckpointCoordinator,它是协调整个 Checkpoint 机制的管理器。从上图可以观察到,它会触发 Checkpoint 的流程,并且会发送 Barrier 到 source task。随后,Barrier 在任务间流转,触发每个任务的快照操作。分布式框架中,每个任务独立地完成状态的存储,在这里可以简单理解为生成数据文件。每个 Task 实例将文件信息(如文件位置等信息)传回到 JobManager 端,通知 CheckpointCoordinator 它完成了本次的状态存储。
与 JobManager 端的其他组件有着同样的设计思路,CheckpointCoordinator 知道整个执行图中的所有任务。这样,当每个 Task 各自完成状态存储后通知 JobManager 端,CheckpointCoordinator 就可以知道本次 Checkpoint 是否所有 Task 都完成了状态存储。如果全部完成,则将所有回传的信息汇总成一个元数据文件。
恢复的过程正是存储的逆过程。JobManager 端读取元数据文件,将这些信息封装到执行图各个节点中,部署到 TaskManager 端执行。这样每个 Task 在初始化阶段就知道去哪个文件读取状态数据,进而对其进行恢复。
总结
本文从通用视角介绍了状态与容错的基本概念,以 Hadoop、Spark、Flink 为例分析了具体框架的实现原理。
通过对比可以了解到批处理系统与流处理系统对该机制有着不同的思考。批处理系统的基本思路是,当作业出现失败时,把失败的部分重启即可,甚至可以把整个作业重新运行一遍;流处理系统则需要考虑数据的一致性问题,将其融入到整个状态容错机制当中。
由于框架本身定位的不同,这些状态容错机制并没有明显的优劣之分,但它们在各自的领域几乎都是最优秀的实现,其设计思路都值得学习和反思。
本文转载自:ThoughtWorks 洞见(ID:TW-Insights)
原文链接:分布式计算框架状态与容错的设计




