

Apache Pulsar 是 Yahoo 开源的下一代分布式消息系统,其特有的分层分片的架构,使得 Pulsar 可以完美地匹配和适配大数据计算框架中的批流一体的存储需求。本文整理自 StreamNative 核心工程师翟佳在 QCon全球软件开发大会(北京站)2019 上的演讲,他在分享中介绍了 Pulsar 是怎么跟流处理中的 Spark 和 Flink 以及批处理中的 Presto 和 Hive 结合,提供批流一体的高效的数据存储。点此下载完整版PPT。
非常荣幸有机会和大家分享一下 Apache Pulsar 怎样为批流处理提供融合的存储。希望今天的分享对做大数据处理的同学能有帮助和启发。

这次分享,主要分为四个部分。
介绍与其他消息系统相比, Apache Pulsar 的独特优势。
分析批流处理中的存储需求。
讲述 Apache Pulsar 如何完美匹配批流处理中的存储需求。
介绍怎样使用Apache Pulsar 提供批流融合的存储。
1. Apache Pulsar 简介
Apache Pulsar 是新近开源的一个大规模分布式消息系统,是 Apache 的顶级项目,在 Yahoo 全球数十个机房大规模部署并线上稳定使用了 4 年多。Apache Pulsar 设计中学习和借鉴了其他优秀的分布式系统,在保证一致性和高吞吐的同时,也提供了其他优秀特性,比如支持上百万的 Topic、无缝的多中心互备、灵活的扩展性等。
这里我们简单介绍一下,与其他消息系统相比, Apache Pulsar 拥有的独特优势,大致有以下 3 点:
(1)独特的软件架构(存储和计算分离,分层分片的存储)
(2)灵活的消费模型( Exclusive、Failover、Shared 和 KeyShared)
(3)丰富的企业特性(多租户)
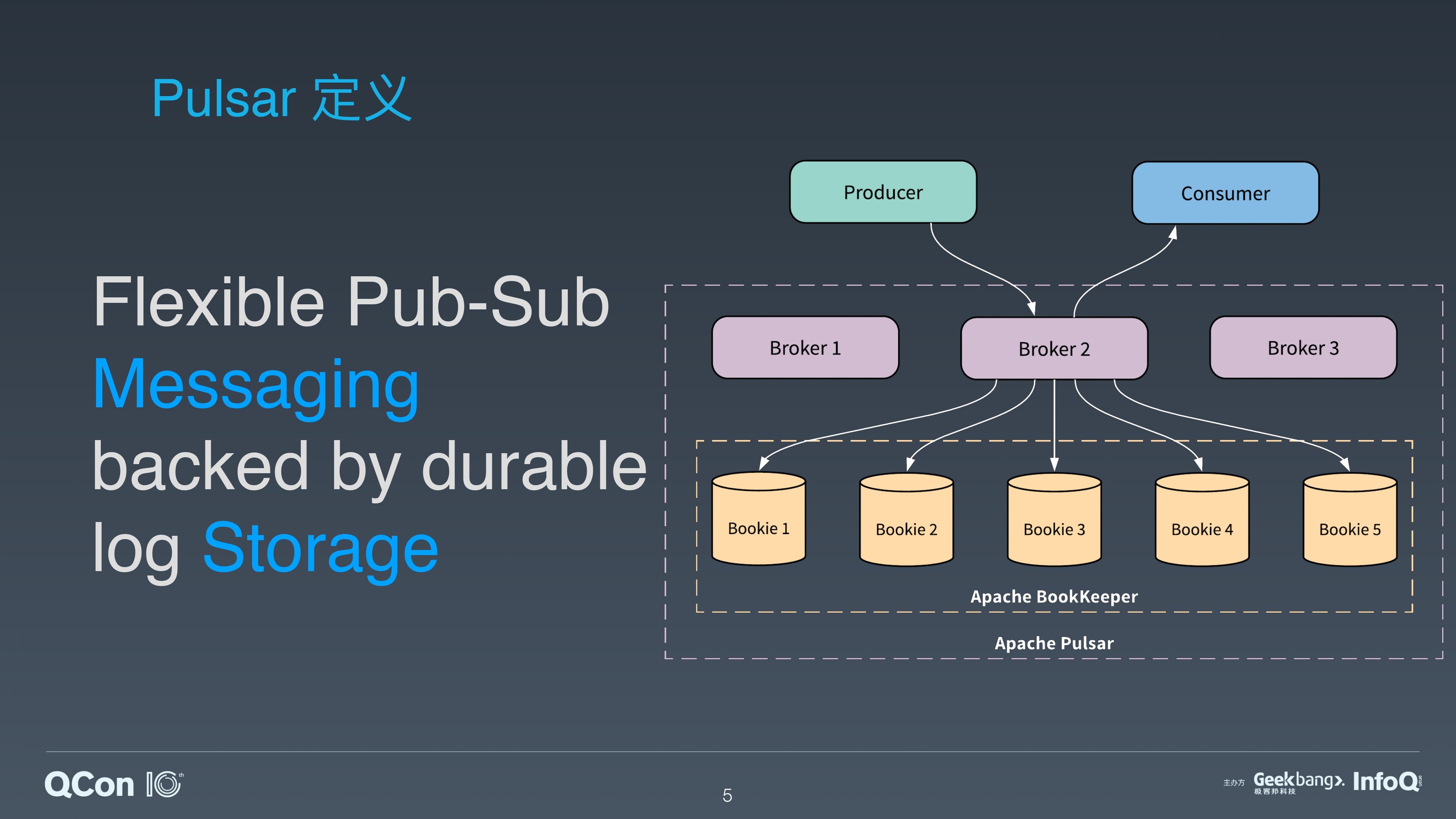
在介绍 Apache Pulsar 时,通常会用这样一句话,“Flexible Pub-Sub Messaging backed by durable log Storage”。这句话表明了 Pulsar 和其他消息系统的根本不同,它采用了存储和计算分离的架构。Pulsar 的服务层使用 Broker,存储层使用 BookKeeper,来提供高效和一致的存储。
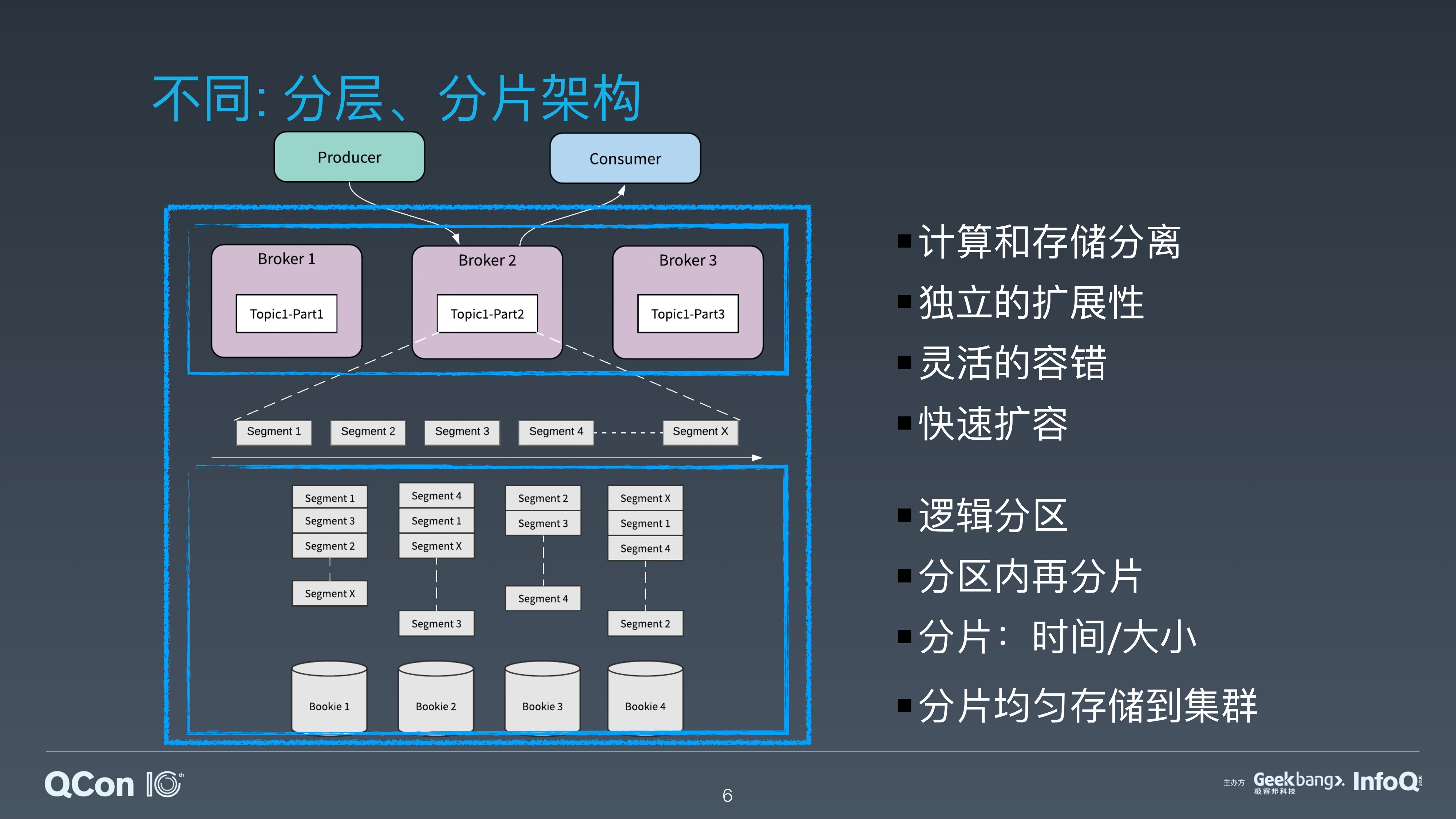
从架构上来说,Apache Pulsar 采用了分层和分片的架构。这是 Pulsar 满足批流处理中存储需求的基础。
在 Apache Pulsar 的分层架构中,服务层 Broker 和存储层 BookKeeper 的每个节点都是对等的。Broker 仅仅负责消息的服务支持,不存储数据。这为服务层和存储层提供了瞬时的节点扩展和无缝的失效恢复。
存储层 BookKeeper 为 WAL(Write Ahead Log)提供了存储,是一个分布式的 Log 存储系统。
WAL 和数据处理中的流有很多相似性,都是数据源源不断地追加,都对顺序和一致性有严格要求。
BookKeeper 通过 Quorum Vote 的方式来实现数据的一致性,跟 Master/Slave 模式不同,BookKeeper 中每个节点也是对等的,对一份数据会并发地同时写入指定数目的存储节点。对等的存储节点,保证了多个备份可以被并发访问;也保证了存储中即使只有一份数据可用,也可以对外提供服务。
Apache Pulsar 通过分层分片的架构,将逻辑的分区转化为分片来作为存储单元。这为数据的并发访问提供了基础。
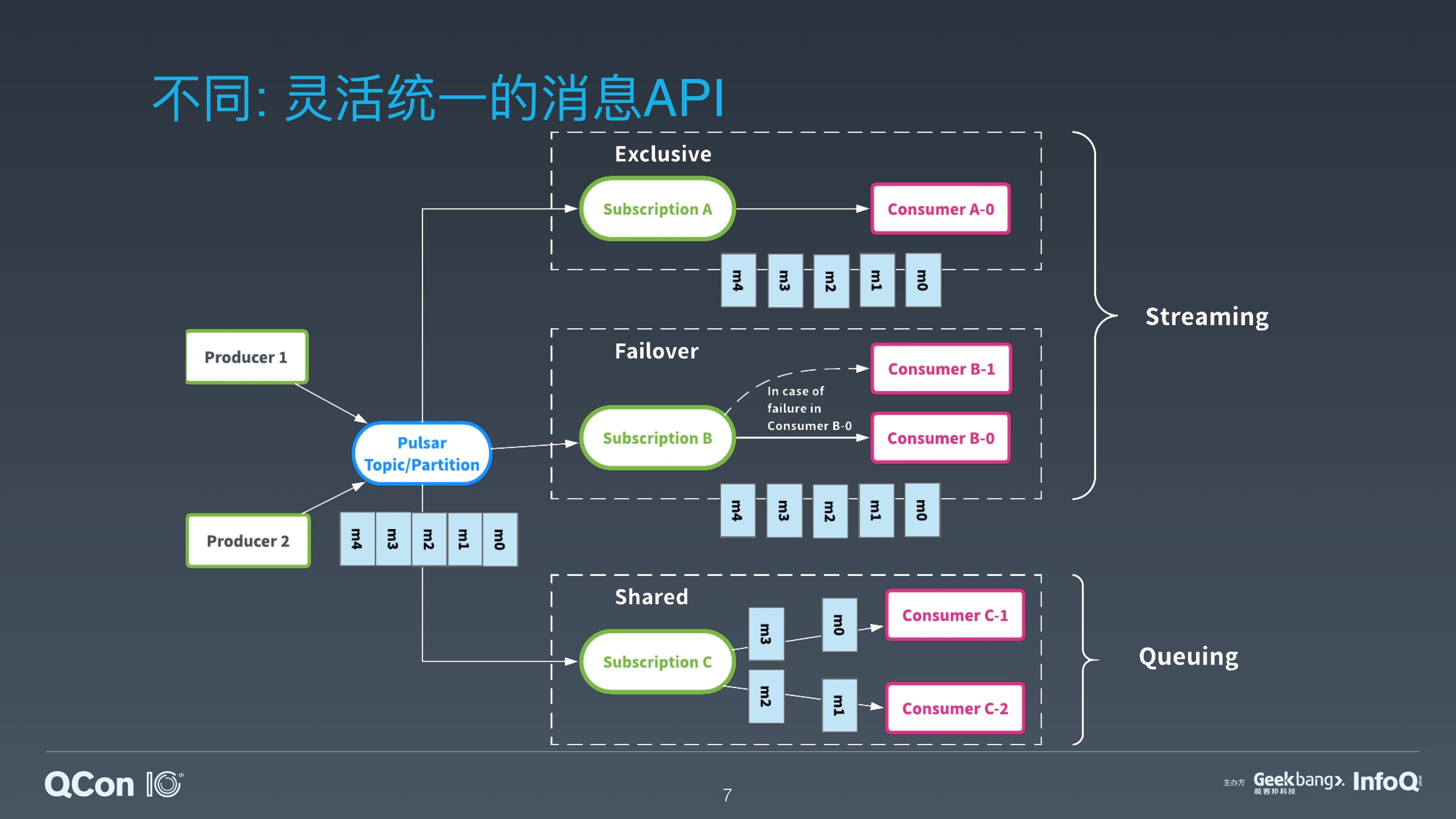
除了架构的不同,从用户接口来说,Apache Pulsar 通过订阅的抽象,提供了灵活的消费模型。每一个订阅类似一个 Consumer Group,接收一个 topic 的所有的消息。用户可以使用不同的订阅类型、以不同的模式来共同消费同一个 Topic 中的消息。
如果对顺序性有要求,可以使用 Exclusive 和 Failover 的订阅模式,这样同一个 Topic 只有一个 Consumer 在消费,可以保证顺序性。
如果使用 Shared 订阅模式,多个 Consumer 可以并发消费同一个 Topic。通过动态增加 Consumer 的数量,可以加速 Topic 的消费,减少消息在服务端的堆积。
Pulsar 即将发布的 2.4.0 版本添加了一种新的订阅模式: KeyShared。KeyShared 模式保证在 Shared 模式下同一个 Key 的消息也会发送到同一个 Consumer,在并发的同时也保证了顺序性。
Apache Pulsar 灵活的消费模型,避免了因为不同的消费场景需要部署多套消息系统的场景,消除了数据生产端的数据分离。
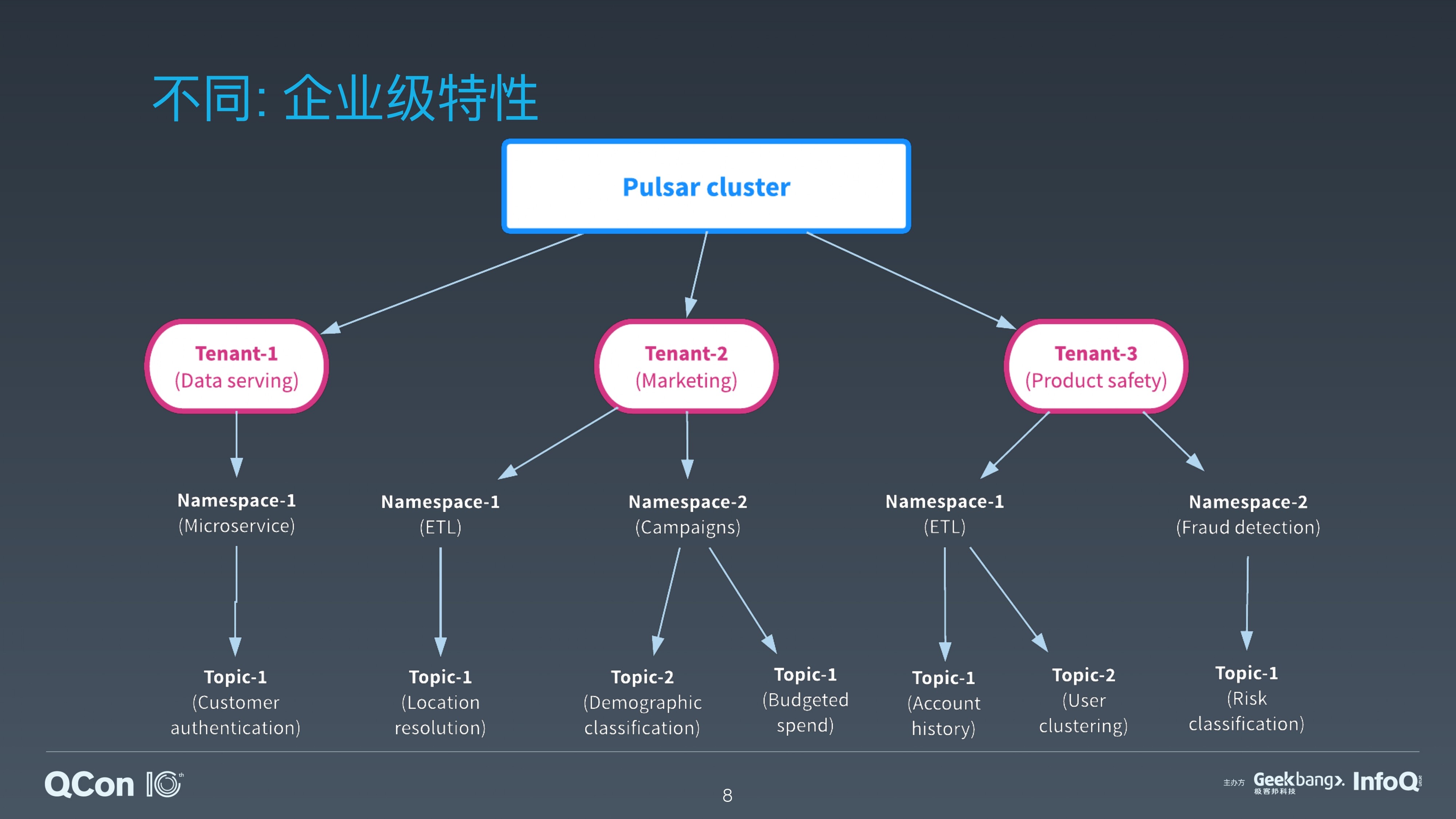
此外,Apache Pulsar 是以多租户为基础的丰富的企业级特性。企业内部可以搭建一套 Pulsar 集群,在集群中给各个部门分配不同的租户,并设置租户的管理权限。租户的管理员再根据部门的不同业务和场景需求,创建不同的 Namespace。在 Namespace 中可以设置管理策略,比如流控,Quota,互备的集群,数据副本数等。这样为 Topic 的管理提供了一个层级的可控的视图。
Apache Pulsar 的企业级特性,为企业搭建统一大集群提供了基础,方便了集群的管理和数据的共享。
以上是关于 Apache Pulsar 的简单介绍,欢迎参阅 Apache Pulsar 的官网了解更多内容。
2. 批流处理中的存储现状
在大数据处理刚刚兴起的时候,一般用户会采用 λ 架构,维护批流两套系统:批系统主要处理历史数据; 流系统处理实时的数据,对批系统的结果进行补充来提高时效。两套系统造成数据冗余,增加维护成本。
在存储层,批处理常使用 HDFS 和网络对象存储等;流处理常使用 Kafka 或其他的消息系统。
为了解决 λ 架构的问题,逐渐演化出 κ 架构,使用一套系统来满足实时数据处理和历史数据处理的需求。
在 κ 架构中,数据的“可重复处理”是关键。一方面要求实时数据能及时获取最新数据,处理完立即导出给其他系统使用;另一方面要满足处理历史数据的需求,需要具备读大量历史数据的能力。实时数据的处理决定了必须使用消息系统,但是消息系统并不能完全满足批处理的并发需求。
在前面的分享中,百度和阿里的专家分享了计算层的批流融合。我们认为批流融合存储层的需求是一个融合的存储表征: 消息系统 + 并发的存储访问。
3. 为什么 Apache Pulsar 能满足批流处理中的存储需求
下面我们从 “Apache Pulsar 提供的存储抽象”、“批流处理中的 IO 模式”和 “Apache Pulsar 提供的无限流存储” 这三个方面来解释为什么 Apache Pulsar 能满足批流融合的存储需求。
3.1. Segmented Stream 存储表征
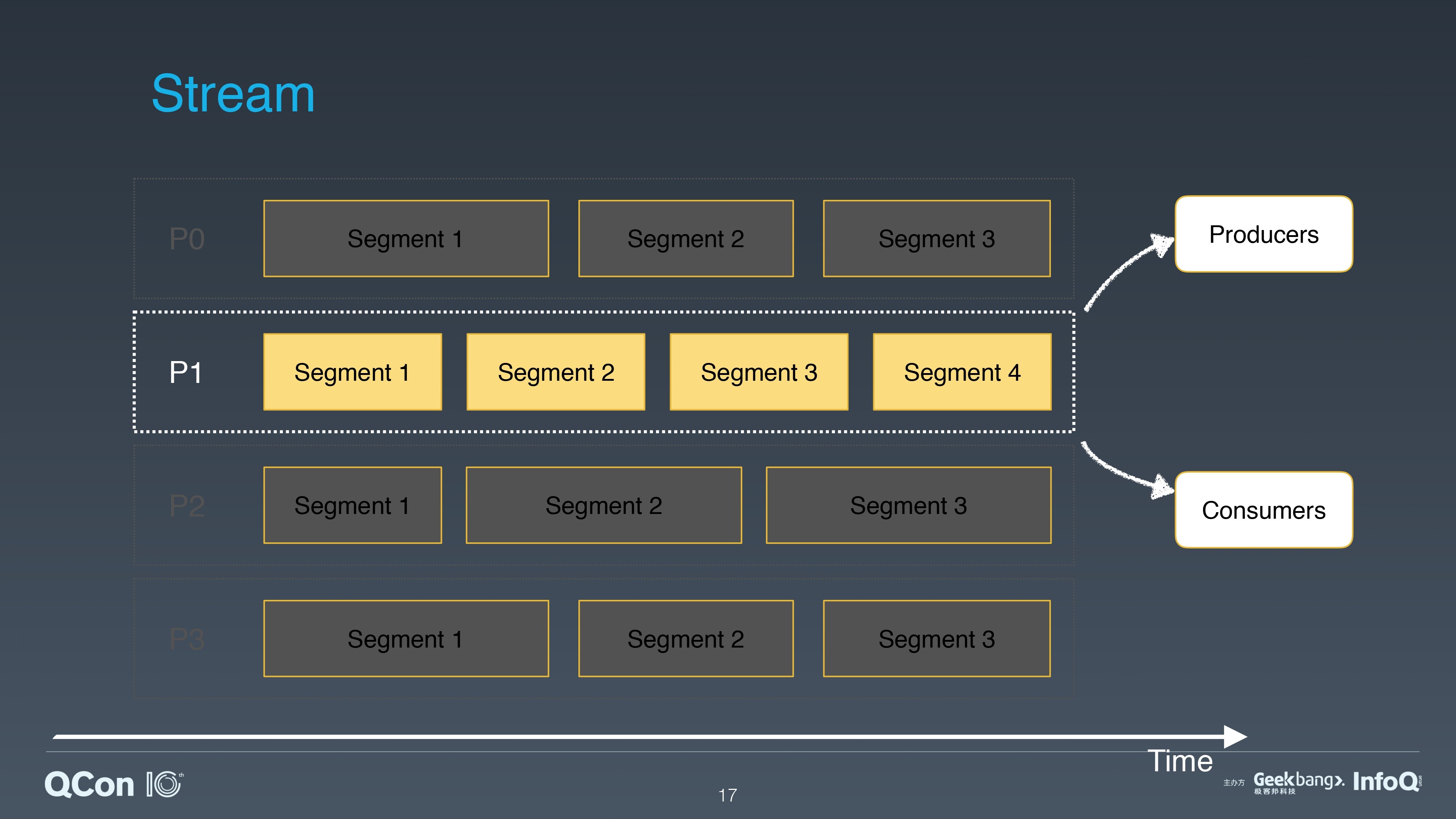
前面我们介绍了 Apache Pulsar 首先是一个消息系统,它和其他消息系统类似,提供了简洁的以 Topic,Producer,Consumer 为基础的 Pub/Sub 模型。
Pulsar 灵活的订阅模式和高带宽、低延迟特性,能够很好的满足流处理的需求。
Apache Pulsar 的 Topic 可以分为不同的分区。和其他消息系统不同的是 Apache Pulsar 利用分片的架构,每个逻辑分区又进行了分片。
在分层分片的架构中,分片是存储的单元,可以类比 HDFS 中的一个文件块,分片被均匀地分布在存储层的 BookKeeper 节点中。
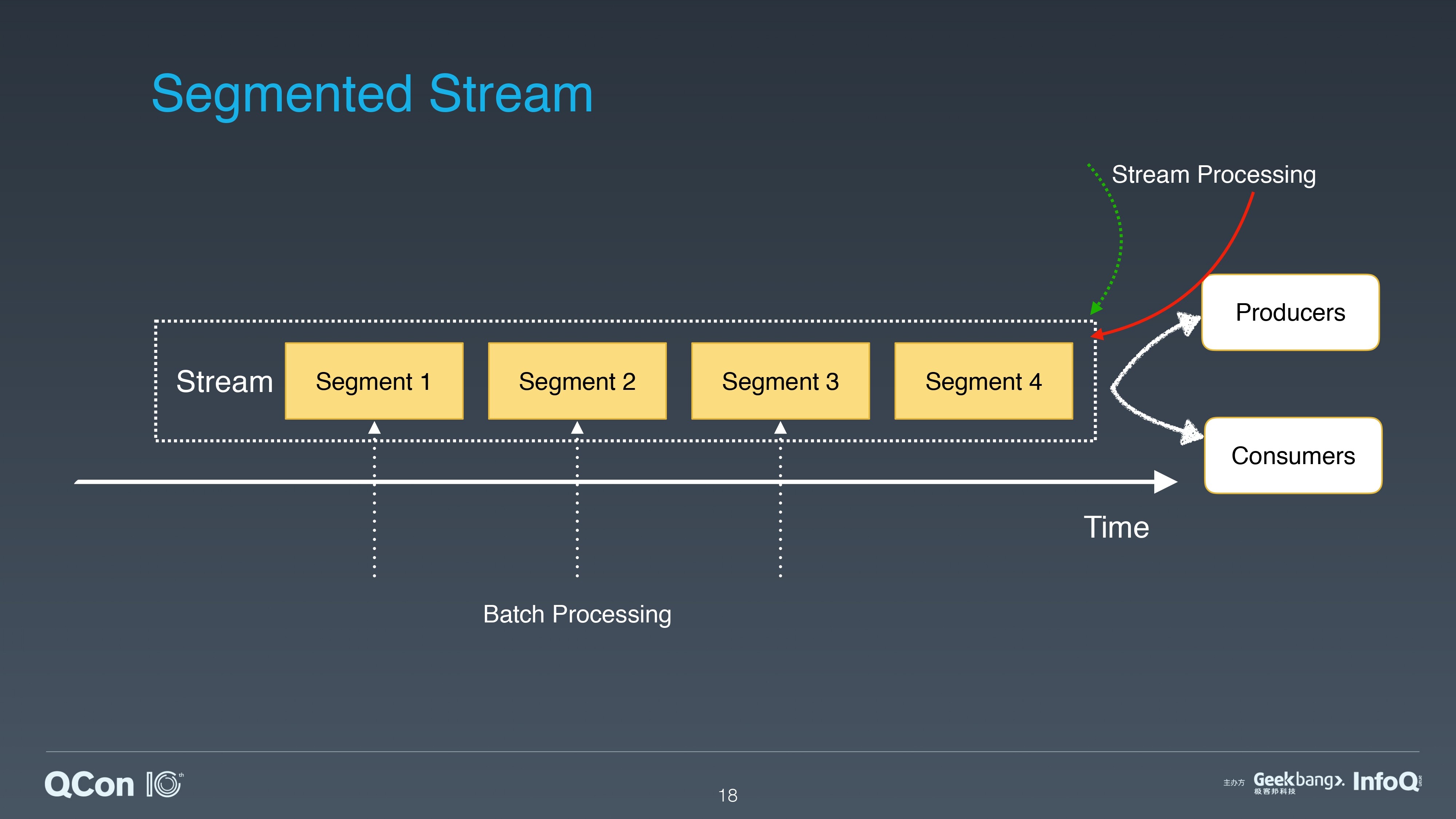
我们再从批流处理的角度来看 Apache Pulsar 的这种分片(Segment)的架构:
对于流处理来说,Apache Pulsar 的每个 Partition 就是流处理的一个流,它通过 Pub/Sub 的接口来给流处理提供数据交互。
对于批处理来说,Apache Pulsar 以分片为粒度,可以为批处理提供数据的并发访问。
一方面,Apache Pulsar 中每个 Partition 都可以看做是源源不断流入数据的载体,借助于分片和二级存储,Apache Pulsar 有能力将 Partition 所有流入的数据都保存下来。这样每个 Partition 都可以看作是 Stream 的存储抽象。
另一方面, Apache Pulsar 的 Partition 是逻辑分区的概念,分区内部又被分成分片,作为存储和 IO 访问的单元。
结合这两个概念,我们把 Apache Pulsar 对每个 Partition 的存储表征称为 Segmented Stream。通过 Pulsar 的 Segmented Stream 抽象,为批流处理提供了一个统一的存储表征。
3.2. 匹配批流处理中的 IO 模式
介绍了 Apache Pulsar 的 Segmented Stream 的存储表征后,下面我们结合批流处理中数据的三种常用的访问模式: Write,Tailing Read 和 Catchup Read,来看看 Apache Pulsar 这种架构的合理性。这里主要会讨论延迟、IO 的并发和隔离,并用大家比较熟悉的 Kafka 系统来对比说明。
Write:往 Stream 中添加新的数据。
Tailing Read:读最新的数据。
Catchup Read:读历史老数据。
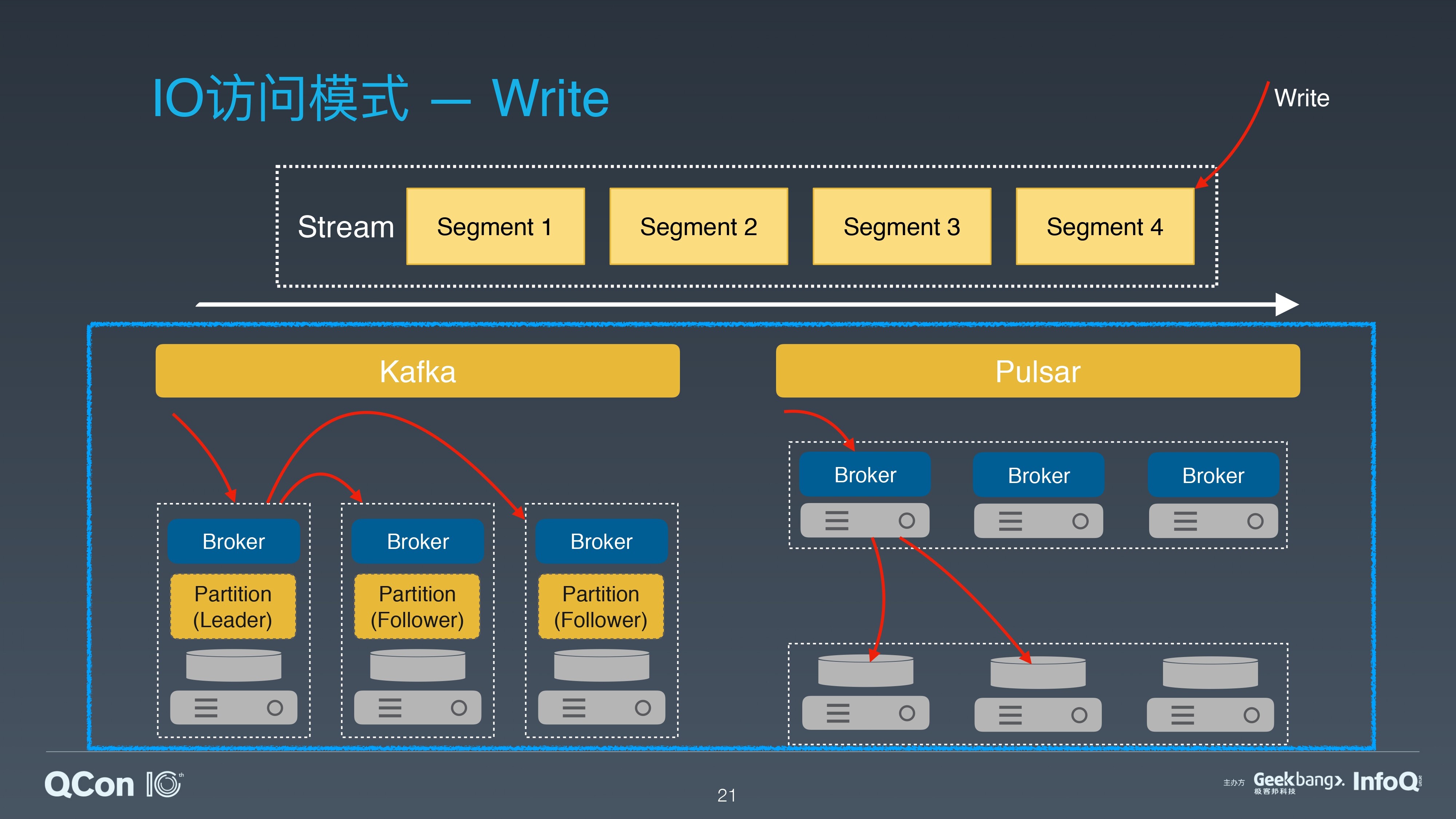
对于 Write 这种模式,所有的写都直接追加在 Stream 的尾部。
对于和 Kafka 类似的 Master/Slave 架构系统来说,数据会先写入 Leader Broker,再发送给其他 Follower Broker。
Apache Pulsar 的写先发送到 broker,然后 broker 作为存储代理,并发将数据发送给存储层的多个 Bookie 节点。
两种架构都会有两次网络跳跃。对于 Write 模式,延迟差别不大。
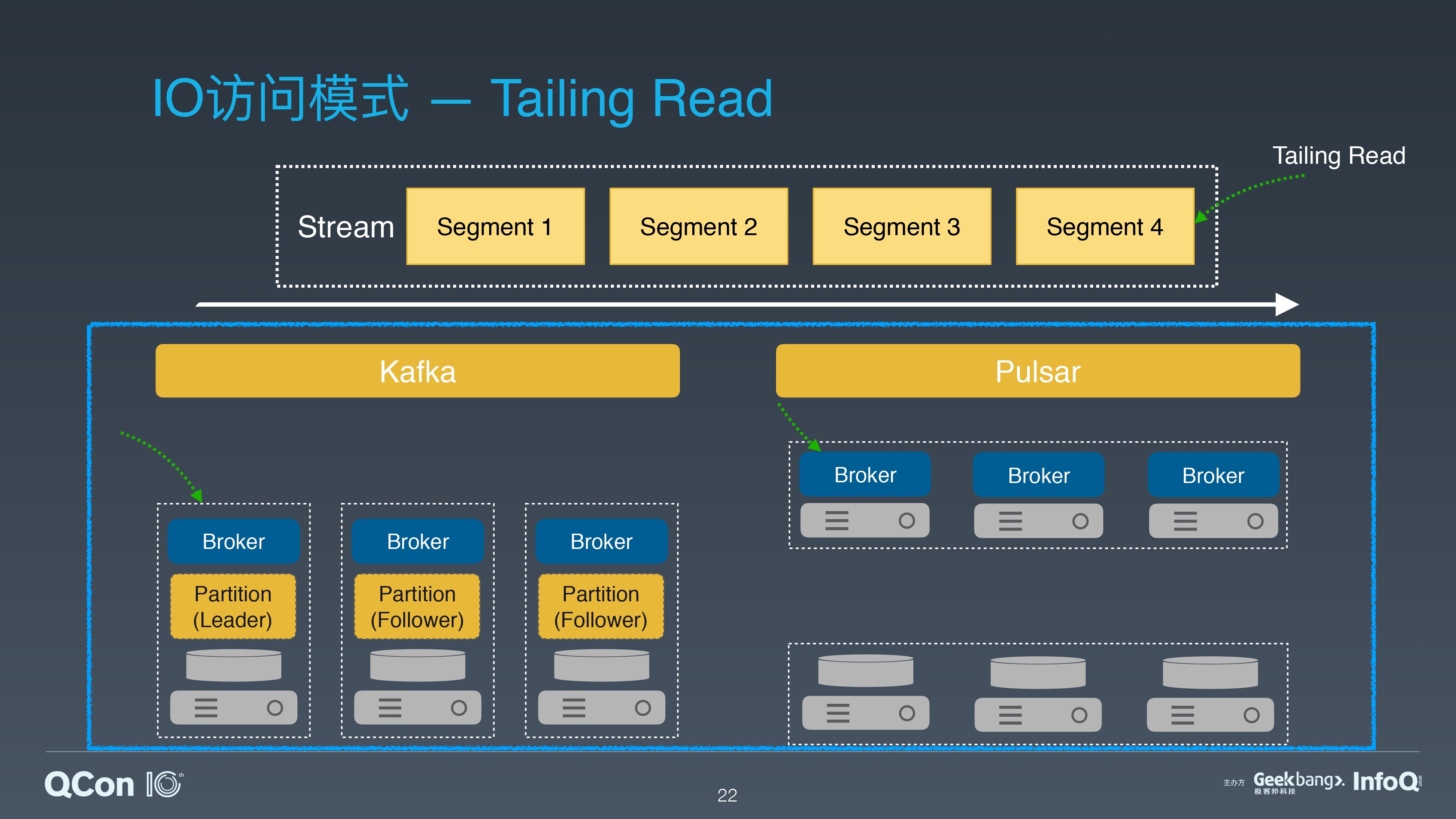
Tailing Read 是流处理中的常用模式。它从 Stream 的尾部读取最新写入的数据。
对于和 Kafka 类似的系统,Tailing Read 会从 Leader Broker 直接读取。
对于 Apache Pulsar,在 Broker 中有一段自维护的 Cache 来缓存刚刚写入的最新数据,Tailing Read 直接从 Broker 获取数据并返回。
两种架构都只有 1 次网络跳跃。对 Tailing Read 模式,延迟差别不大。
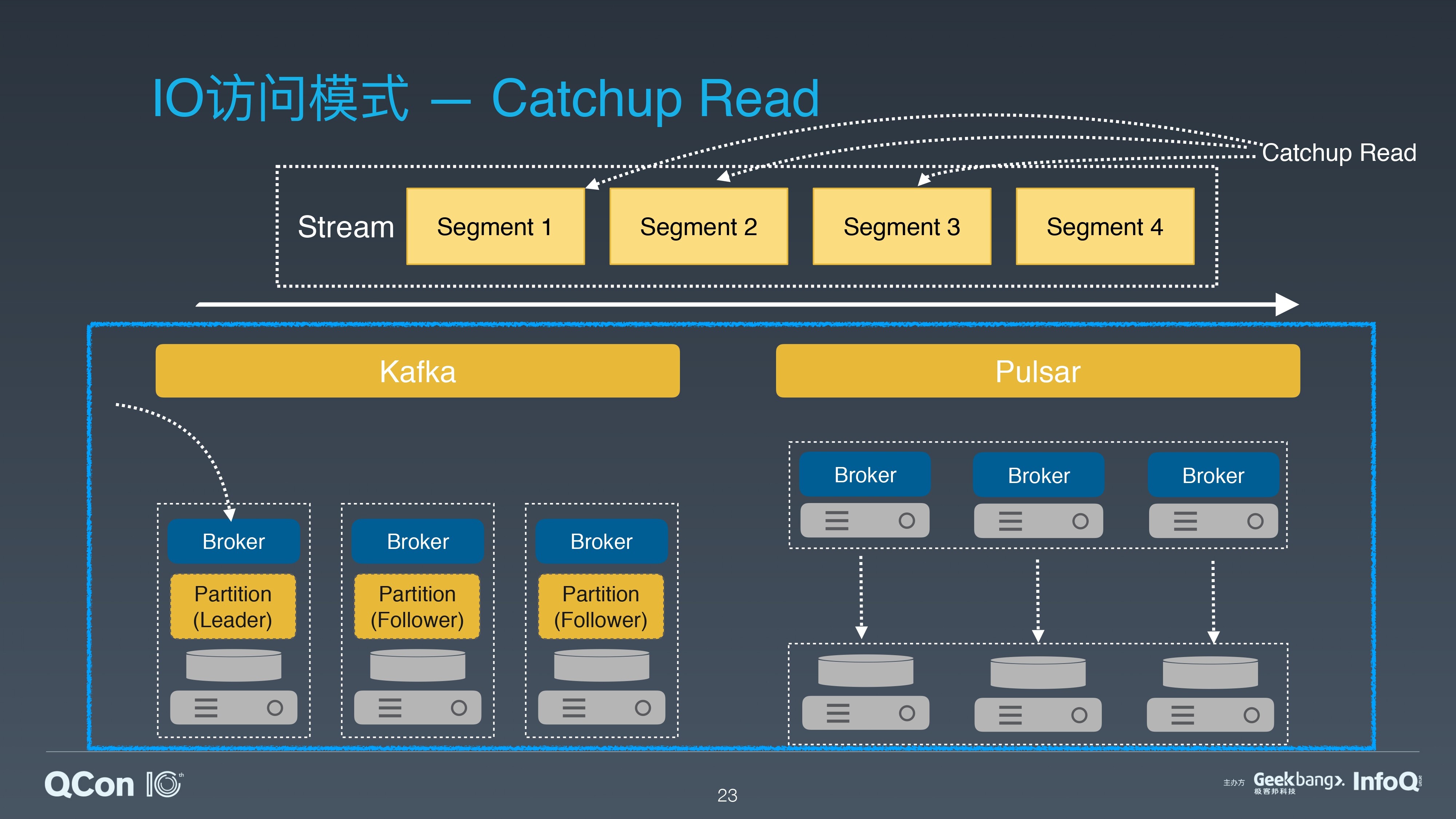
Catchup Read 是批处理中常用的读取模式。它从 Stream 的指定位置,读取一定量的历史数据。这种场景一般对数据的读取量比较大,注重读取的带宽。
对于 Kafka 类似的系统,Catchup Read 一般还是会使用 Pub/Sub 的接口,从 Leader Broker 直接读取。
对于 Apache Pulsar,我们可以从 Broker 中读取元数据,获取 partition 中分片的起始位置和分片在 BookKeeper 中的存储信息,绕过 Pub/Sub 接口,利用 BookKeeper 的 Read 接口,直接从存储层并发访问多个分片。BookKeeper 提供了多副本的高可用,提升了读取历史数据的并发能力。
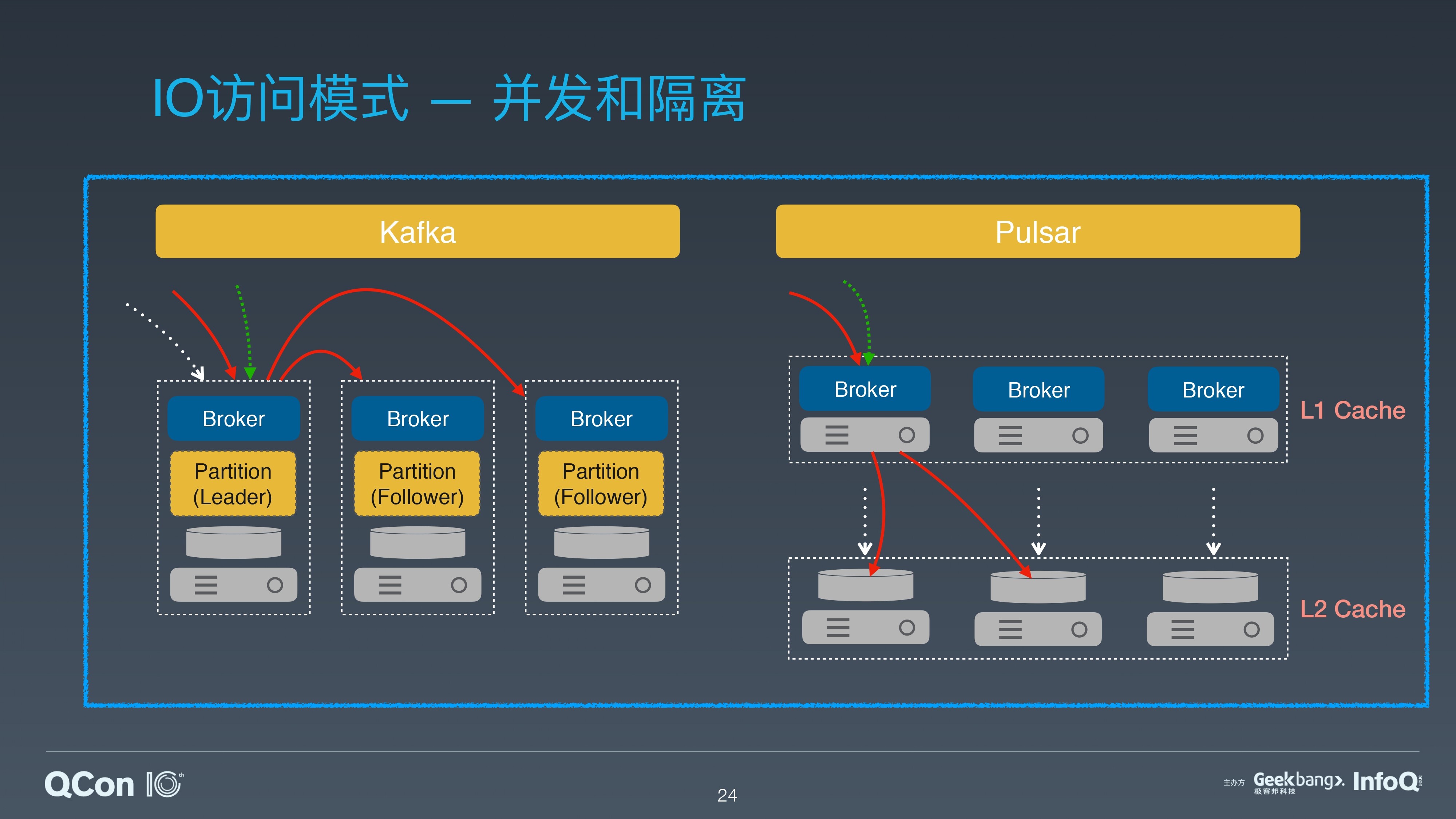
如果我们把这三种 IO 模式放在一起看就更有意思了。 这可以类比用户在某时间段,对 Stream 既有最新数据读写,也有历史数据读写的情形。这是在批流融合中经常遇到的场景。
对和 Kafka 类似的系统,这三种 IO 模式都会发生在 Leader Broker。在 Leader Broker 中,系统的数据都需要通过文件系统的 Pagecache,历史数据和最新的数据会争用 Pagecache 资源,造成读写响应不及时。
如果这时再遇到 Broker 磁盘空间写满,需要扩容的情况,那就需要等待数据的搬移和 rebalance 的操作。这时,IO 的延迟和服务质量很难得到保障。
Apache Pulsar Segmented Stream 的存储表征,结合分层分片的架构,为新数据和历史数据做了天然的隔离。最新的数据 IO 发生在 Broker 层。
对历史数据的并发读写,直接发生在存储节点。冷热数据被天然隔离,用户完全不用担心 IO 的冲突和争用。Apache Pulsar 在节点扩容和错误恢复的过程中,也不会有数据大量拷贝和 rebalance,因此提升了系统的高可用性。
通过这三种 IO 模式的说明和对比,我们发现 Pulsar Segmented Stream 的存储表征,再结合分层分片的架构,可以很好地满足批流处理中对存储系统的需求。
3.3. 无限的流存储支持

Pulsar Segmented Stream 的存储表征,很好地模拟了现实中 Stream 数据。对于流存储的另一个需求是理论上无限的存储空间。这样可以满足对历史数据的存储和访问需求。Apache Pulsar 从两个方面解决了这个问题。
一方面 Pulsar 的存储层中,分片会均衡地分布到所有的存储节点中,这避免了其他系统中单一 broker 存储容量的限制,进而可以利用整个集群的存储空间。
另一方面,Pulsar 的分片架构,为数据的二级存储扩展提供了很好的基础。对于 Segmented Stream,用户可以设置 Segment 在 BookKeeper 中保留的时间或大小。如果超过设定的值,将旧的 Segment 迁移到廉价的二级存储,比如 Aws S3,Google Cloud Storage,或者 HDFS 中。二级存储的带宽一般有保障,可以满足历史数据的批处理模式。 通过二级存储可以减轻无限存储的成本。
3.4. 小结
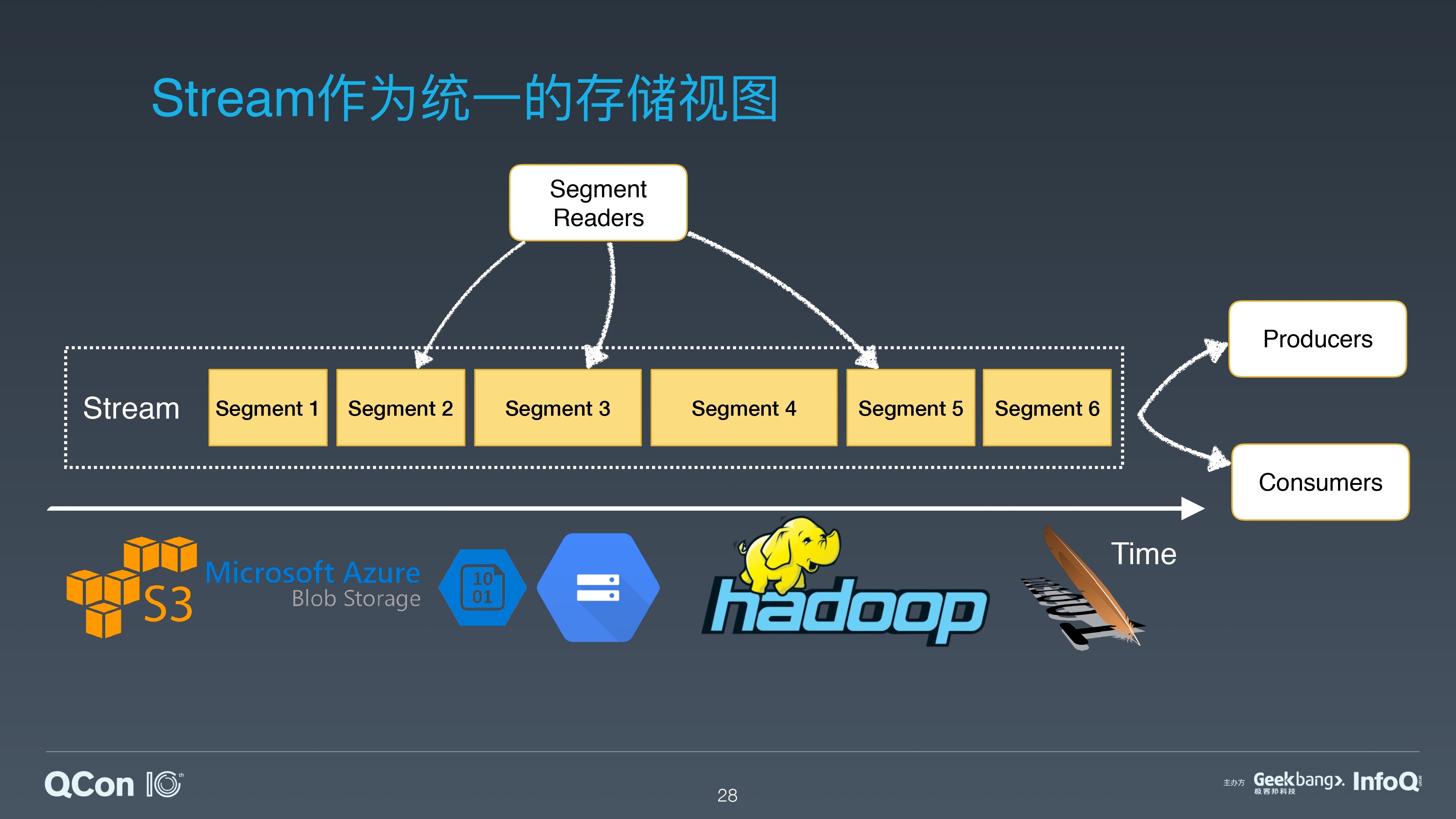
Pulsar 利用自身的分层分片的架构,提供了 Segmented Stream 的存储表征,满足了批流融合的存储需求。
通过 Pulsar Pub/Sub 接口访问 Segmented Stream,可以满足流处理的存储需求;通过 Pulsar 存储层对 segment 的访问接口(Segment Reader),可以满足批处理的并发访问需求。从批流处理的 IO 模式分析中可以发现,Pulsar 的架构可以很好地处理批流处理中的 IO 并发和隔离。并且 Pulsar 提供了理论上无限流存储的能力,能够满足批处理中,对海量历史数据的存储需求。
4. 怎样使用 Pulsar 提供批流融合的存储
前面我们介绍了为什么 Pulsar 的架构能满足批流融合的存储需求。接着我们会介绍 Pulsar 是如何在工程上实现的。
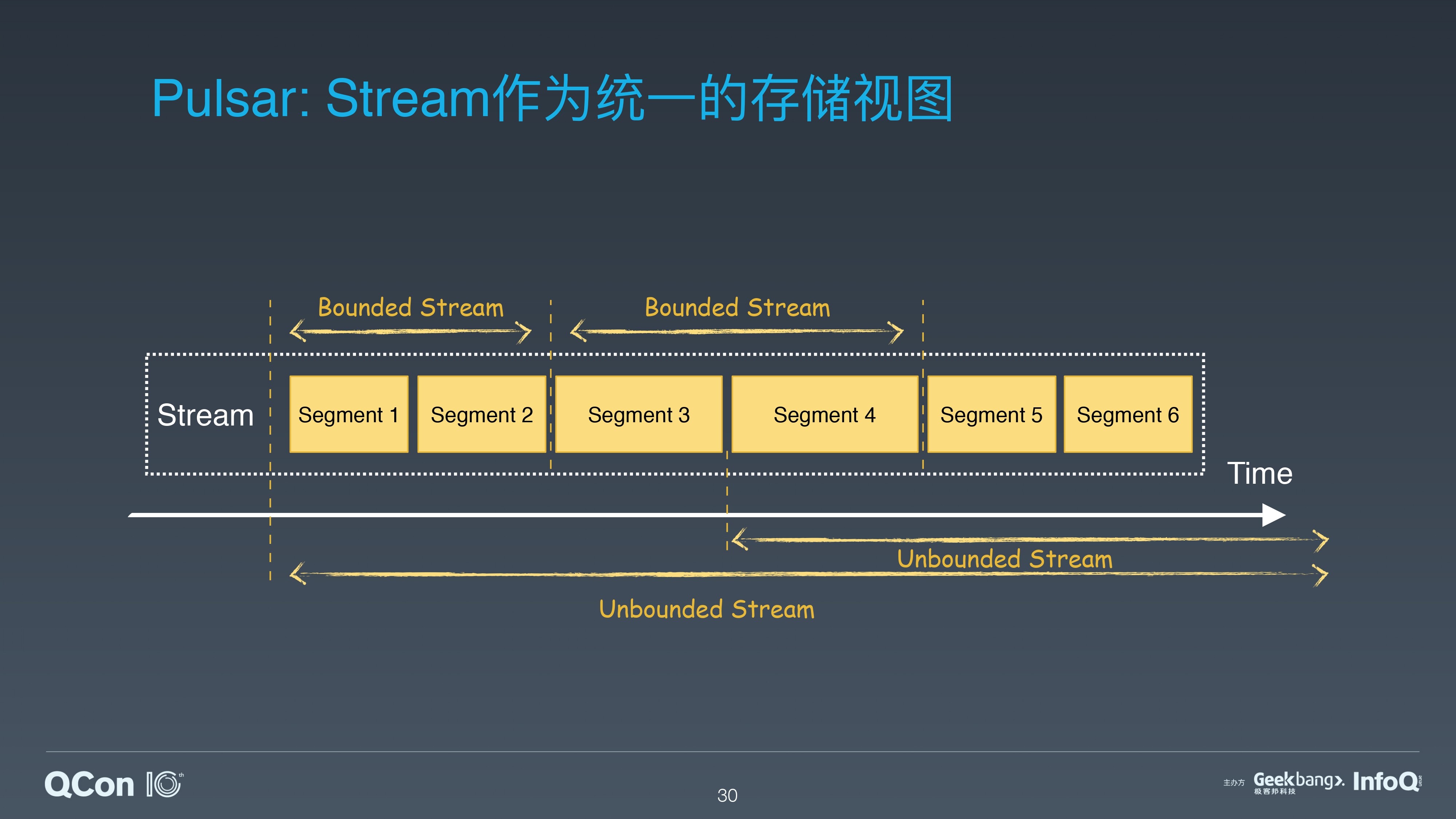
基于 Segmented Stream 存储的表征,我们很容易区分和支持批处理和流处理。批处理所请求的数据可以看做是一个有边界的流(Bounded Stream)。流处理所请求的数据可以看做是一个没有边界的流(UnBounded Stream)。
下面我们看在 Pulsar 内部,批处理和流处理会怎样访问 Segmented Stream。
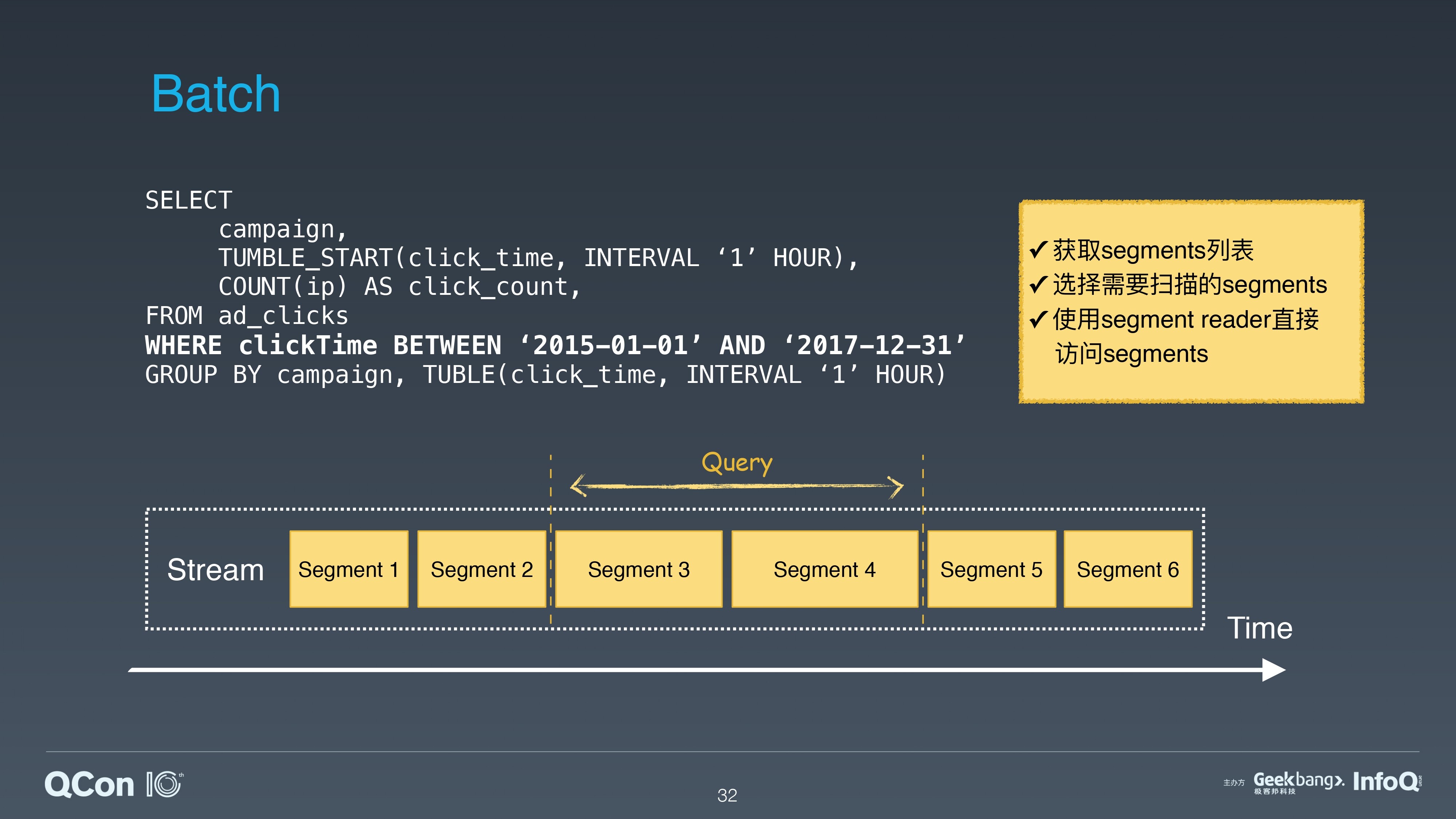
这里的代码是一个计算广告点击率的 SQL 语句。如果用户想要查询某个时间段内的点击率,会提供点击事件的起止时间。起止时间可以确定一个流的起止边界,进而确定一个 Bounded Stream。这是一个典型的批处理场景。
对 Pulsar 的处理来说,首先根据起止时间来确定和获取所需要的 Segments 列表;然后选择这些 Segments,绕过 pub/sub 接口,直接通过 Pulsar 的 Segment Reader 接口,来访问 Pulsar 的存储层。
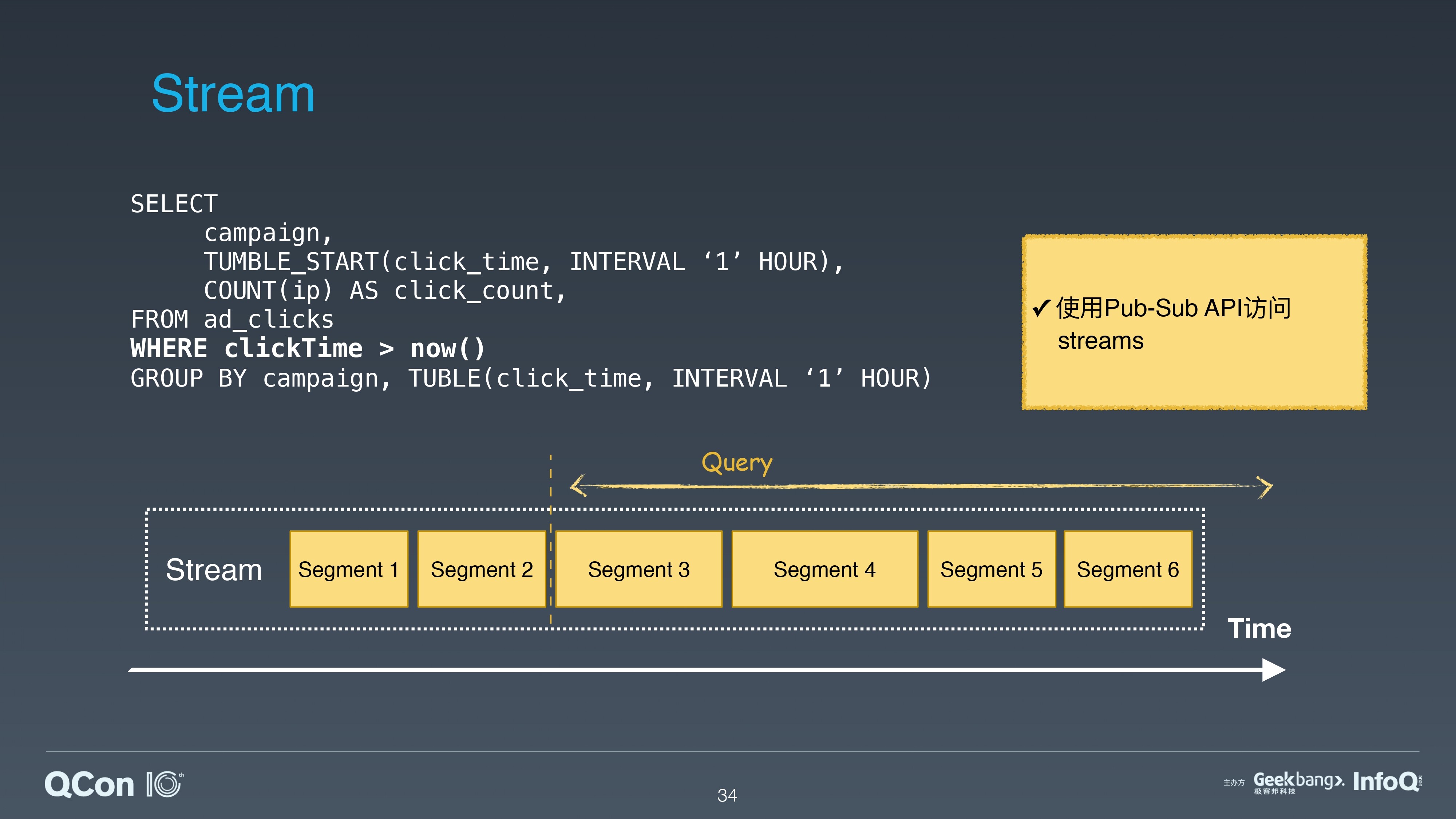
流处理是一系列不会停止的 Windows 访问和查询。与批处理相比,流处理它没有截止的时间点,即使查询到当前时刻,它仍然继续对当前的 window 不断地查询,一个 window 处理结束,接着处理下一个 window。它的 SQL 查询语句不会变化,但是查询 window 中的数据会不断实时更新,它是一个源源不断的、不停处理最新数据的方式。
对于这种访问模式,直接使用 Pulsar 的 pub/sub 接口就可以直接获取最新的消息,满足流处理的需求。
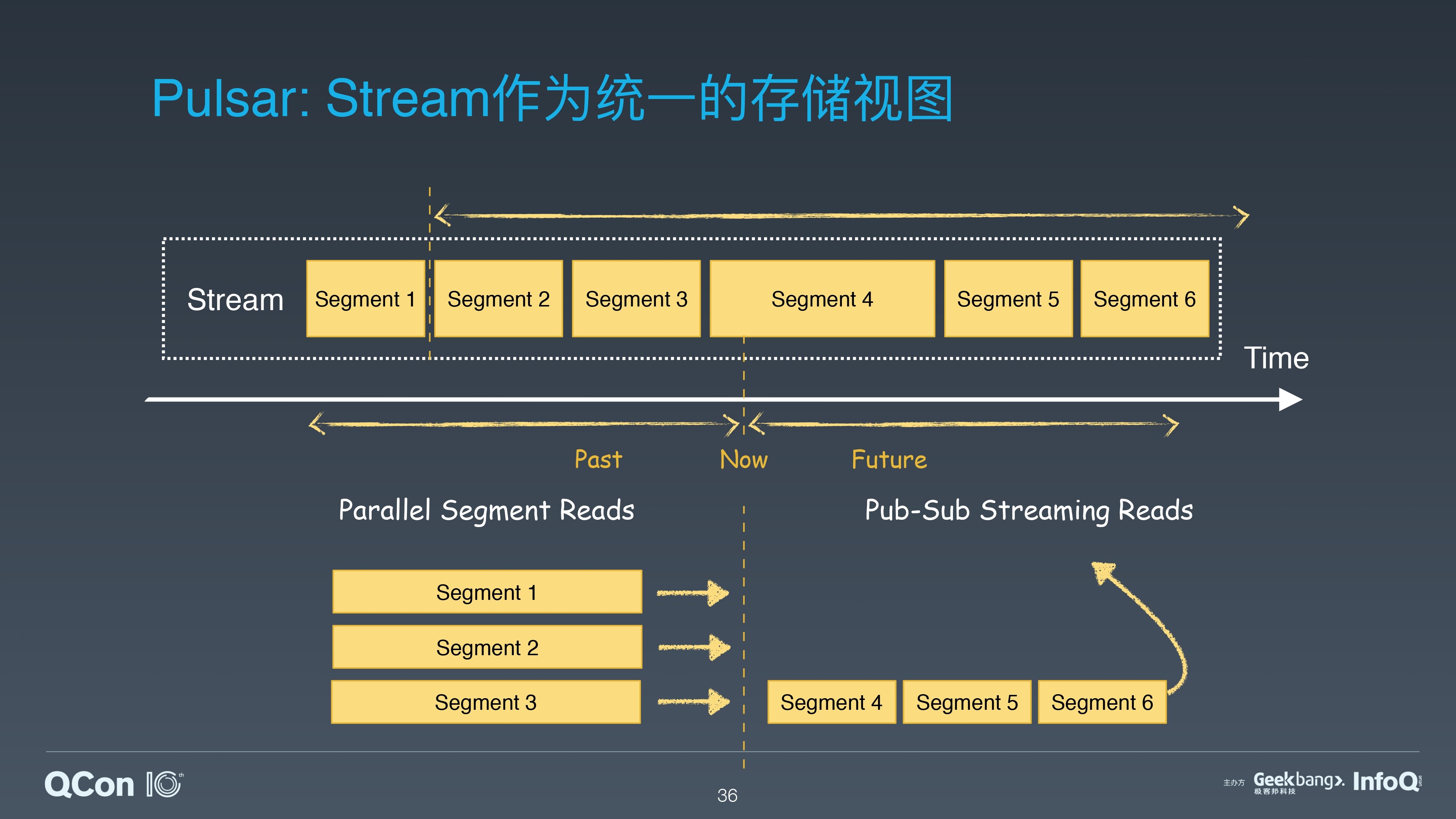
对批流融合,在计算层,更多关注的是批流融合的计算模型、API 和运行时的统一。在存储层,通过 Segmented Stream 的存储表征,为批流数据提供了统一的数据存储和组织方式。
针对批流处理的不同访问模式,Pulsar 提供了两套 API 接口。流处理使用 Pub/Sub 的接口;批处理使用 Parallel Segment Read(PSegment)的接口。
对于批处理的接口,我们在 Pulsar SQL 里面做了一个尝试,Pulsar SQL 借助 Presto,对写入 Pulsar 中的数据进行交互式的查询。
如果你想体验 Pulsar SQL,可以查看 Pulsar 的 SQL手册。
Pub/Sub 的接口已经比较完善,我们最近在丰富和完善 PSegment 接口。


在 PSegment 中,我们的主要工作是集成 Pulsar 和 Flink、Spark、Hive 及 Presto 。这些工作主要集中在 API 的实现和 Schema 的整合。这些工作完成之后,我们会开源这部分的代码。
5. 总结
Pulsar 是下一代云原生的消息和流存储的平台。我们认为消息和流是一份数据的两种不同表征方式。Pulsar 采用了存储计算分离的分层架构和分区内再分片的存储架构,这种架构能够提供基于 Segmented Stream 的存储表征,能为批和流处理提供融合的存储基础。
上图中有 Pulsar 官方的联系方式和讨论途径,包括 Twitter、微信公众号、邮件列表、github 等。Apache Pulsar 是一个年轻的项目,越来越多有意思的 Feature 正在开发和完善中,期待大家关注和加入 Pulsar 社区。在探索 Pulsar 的过程中,有任何问题,欢迎通过 Slack 和微信与我们联系。
QCon 全球软件开发大会(北京站)2019 已经圆满结束,QCon 上海 2019 即将起航,点击此处了解详情。

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论