
本文根据京东商城交易平台的杨超在“第一期蝴蝶沙龙:揭秘 618 电商大促背后的高并发架构”会议上的演讲整理而成。
大家好!我是来自京东商城交易平台的杨超,今天特别高兴能够来给大家做这个分享。我是 2011 年加入京东,5 年中我经历了不少技术架构的演进,也看到了不少变化。这次分享首先介绍京东商城的服务、京东交易结构,然后介绍针对 618 备战,我们做的一些事情,以及从 2011 年到现在,京东交易平台经历的变化。
商城服务
(点击放大图像)

如图所示是京东交易平台的一张大的渔网图。从主页面网站开始,到后面提交订单、购物车、结算页、订单中心等的整个生产过程,大体可分为三个部分。第一部分是订单提交前,就是俗称的购物车,结算页。第二部分是订单预处理部分,生成订单之后、到物流之前,还会有一些预处理过程,比如生鲜、大家电、奢侈品、易碎品等商品。第三部分是订单履约部分。今天我讲的主要内容是,交易平台的提交以前和预处理部分。
(点击放大图像)

京东交易平台,包括单品页的价格、库存,购物车、促销,结算页的下单,再到订单中心线。
如下图所示,2011 年京东的订单量是30 万,2015 年订单量就已经到了3000 多万,京东的流量每年不断地翻倍。订单从30 万到100 万是三倍增长,实际上访问流量的翻番,可能是10 倍、50 倍,甚至上百倍。比如,用户购买东西从单品页进入,然后查询很多信息,包括价格、评价。商品加入购物车后,用户会不停地比对各类商品。刷新购物车,从前端到后端所有的服务基本上都会刷新。那么,当你刷新一次,调动服务就会承受一次动态的调用。当订单量翻三倍的时候,实际服务访问量最少是要翻20 倍。
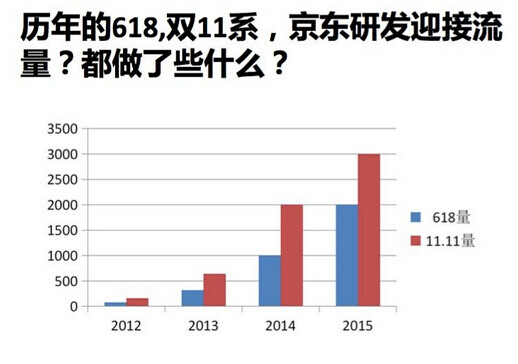
我见过的京东目前最大的前端流量是,一分钟几千万,一个正常前端服务访问量是在几千万,几亿、几十亿,一天的PV。
那为了应对如此大的调动量,每年的618、双11,京东都做了什么?
下面我会详细讲618、双11 备战后面,每一年所做的不同改变。这是一个整体的大概分析,我们从哪些方面做优化,去提高系统的容灾性,提高系统应对峰值流量的能力。

实际上每年京东内部的正常情况是,领导层会给出一个大概的预期值,就是希望当年的大促中,需要达到几百亿,或者几十亿的预期销售额。那么,根据这个销售额,根据客单价(电商的订单的平均价格,称为客单价)换算成订单量。另外在以往的618、双11 中,我们都会统计出订单量和调用量,即前端价格需要访问多少次,购物车需要访问多少次,促销引擎需要访问多少次,整个流程需要多大的量。有了大概的方向之后,就会把具体系统的量换算出来。第一轮会做压测,压测分为线上压测和线下压测两部分。这些都是准备工作,根据一些指标往年的增长量估算出一个预期值。
压测
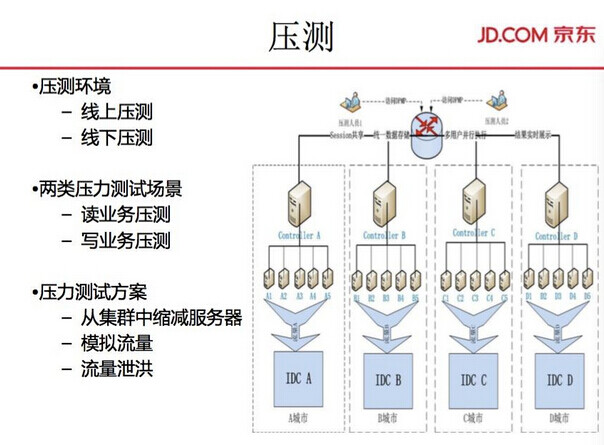
这是真正进入第一波。首先,每年的大促前,都会经历半年业务迭代期,整个系统会有很多变更。我们会进行第一轮的压测系统,压测之后会知道当前线上真正能够承载的访问量有多大,距离预期有多远。压测分为线上压测跟线下压测。压测场景分为读业务和写业务,压测方案有集群缩减服务、模拟流量、流量泄洪。
讲到压测,先说说压测的来历吧。2011 年时候没有线上压测,线下压测也不是很全。真正引入线上压测是在2014 年,订单量已经接近2000 万。之前的大促备战,是通过组织架构师、优秀的管理人员,优秀的技术人员,一起去评估优化系统,因为在迭代代码的同时,我们会知道系统哪里容易出现问题,然后对数据库、Web 或者业务服务做一堆优化。
在2014 年,订单量到了上千万,换算成为访问量,每天的PV 大涨,集群也更大偏大,如果还是只依靠技术人员去优化,可能会不足。于是就衍生出压测,我们想知道系统的极限值。这样,当系统承受不住访问请求的时候,我们就会知道哪里出现瓶颈,比如,服务器的CPU、内存、连接速度等。我们通过第一轮压测找到第一波的优化点,开始了线上的压测。
当时第一波做线上压测是在凌晨一两点,把整个线上的流量剥离小部分机器上。把集群剥离出来,然后再做压测。所有的服务器、所有的配置就是用线上完全真实的场景去做压测,就能够得到线上服务器在真实情况,再优化。
曾经做redis 压测,把进程绑定到单核CPU,redis 是单进程程序,当时集群的性能就提升了5%。因为机器的每次CPU 切换,都需要损耗资源,当时把进程直接绑定到固定的CPU 上,让它高压下不频繁地切换CPU 进程。就这样一个改变,性能提升了5%。当量很大的时候,真正底层细节的小改变,整个性能就会有很大的改进。这是我们从2014 年引进线上压测和线下压测之后的一个真实感受。
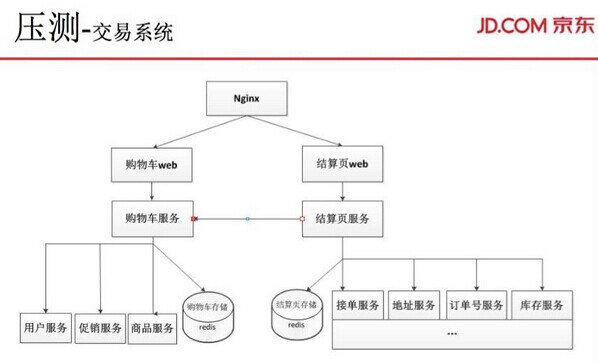
压测完之后得到容量,得到交易系统的购物车、结算页大概承受值,之后会进行一轮优化,包括对NoSQL 缓存的优化。京东在2012 年的时候自建CDN 网络,Nginx 层做了很多模块加Nginx+lua 的改造。应用程序层也会做很多缓存,把数据存在Java 虚拟器里面。数据层的缓存,主要有redis、 NoSQL 的使用,另外会剥离出一些独立的数据存储。
缓存 压缩
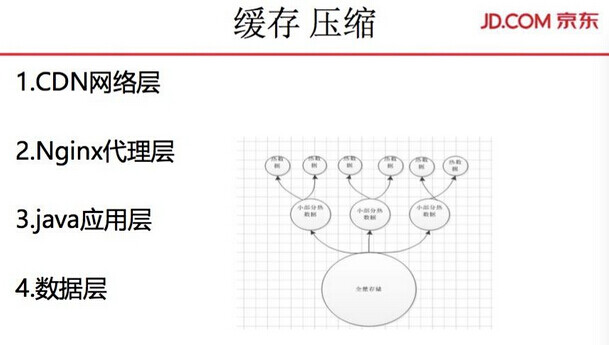
CDN 域名切换的问题,原来外部 CDN 切换 IP,需要 15-20 分钟,整个 CDN 才能生效。我们的运维做了很多的改进,自建了 CDN,内网 VIP 等等进行缓存压缩。Nginx 本身就有介质层的缓存和 GZIP 压缩功能,把静态 js、CSS 文件在 Nginx 层直接拦掉返回,这样就节省了后面服务的服务器资源。GZIP 压缩能压缩传输的文件以及数据,节省了网络资源的开销(GZIP 压缩主力损耗 CPU,机器内部资源的平衡)。前面就直接压缩返回图片、文件系统等静态资源。流量到部署集群系统时,只需要处理动态资源的计算,这样就将动态静态分离集中处理这些专向优化。
真正的计算逻辑,服务自身的组装、如购物车的促销商品、服务用户,基本上所有资源都耗费在此。比如,连接数都会耗费在跟促销,商品,用户服务之间调用,这是真实的数据服务。如果不分离,你用 DOS 攻击直接访问 JS,然后传一个大的包,就会完全占用带宽,连接和访问速度就会非常慢。这也是一种防护措施,在大促中会做很多缓存、压缩这些防护。
(点击放大图像)

购物车从2010 年就开始Java 改造,整体结构的划分主体有,促销引擎、商品、用户。系统结构在2012 年已经成型。到13 年,加入了购物车服务的存储。原来购物车存储的商品是在浏览器端的Cookie 里的,用户更换一台设备,之前加入的商品就会丢失掉。为了解决这个需求,我们做了购物车服务端存储,只要登录,购物车存储就会从服务端拿取。然后通过购车服务端存储打通了手机端与PC 端等的存储结构,让用户在A 设备加入商品,在另外一个设备也能结算,提高用户体验。
异步 异构

2013 年之后,接入了很多其他业务,如跟腾讯合作,有微信渠道,我们会把存储分为几份,容量就会逐步地放大。这是异步的存储,手机端会部署一套服务,PC 端会部署一套服务,微信端会部署一套服务。就会隔离开来,互不影响。
购物车就是这么做的。购物车整个数据异步写的时候都是全量写的。上一次操作可能异步没写成功,下一次操作就会传导都写成功了。不会写丢,但是可能会有一下延时,这些数据还是会同步过来。比如,从 PC 端加入商品之后没有立即同步到移动端,再勾选下购物车,购物车的存储又会发生变更,就会直接把全部数据同步到移动端。这样,我们的数据很少会出现丢失的情况。
异步写的数据是进行了很多的压缩的。第一层压缩从前端开始,整个前端是一个接口串,到后面购物车服务,先把它压缩为单个字母的接口串,后面又会压缩成字节码,使字节流真正存储到 redis 层里面。当存储压缩得很小的时候,性能也会提高。
缓存压缩只是为提升纵向性能做的改进。后面还会进行横向异步异构的改进,购物车把移动端存储剥离出去,移动端的存储在一组 redis 上,PC 端的存储在另外一组上。PC 端和移动端是异步去写,这样相互不影响,虽然它们的数据是同步的。这是针对多中心用户所做的一些改进。
外层的异步,是做一些不重要的服务的异步,就从购物车前端看到的地址服务、库存状态服务。库存状态服务在购物车只是一些展示,它不会影响主流层、用户下单。真正到用户提交的时候,库存数据才是最准确的。这样,我们会优先保证下单流程。
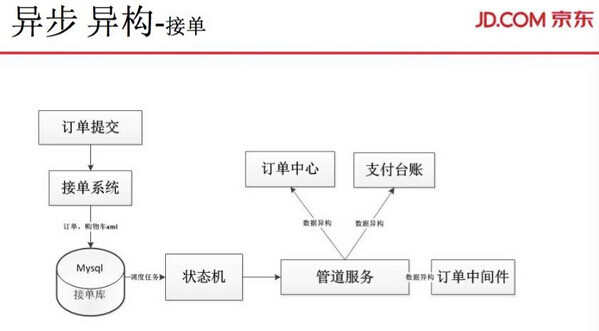
接下来讲讲接单的异步。提交订单,提交一次订单原来需要写 10 多张表。当订单量提高到一分钟 10 万的时候,系统就无法承受。我们就把整个提交订单转成 XML,这样只写一张表,后面再去做异步。接单的第一步,先是把整个订单所有信息存储下来,然后再通过状态机异步写原来的 10 多张表数据。
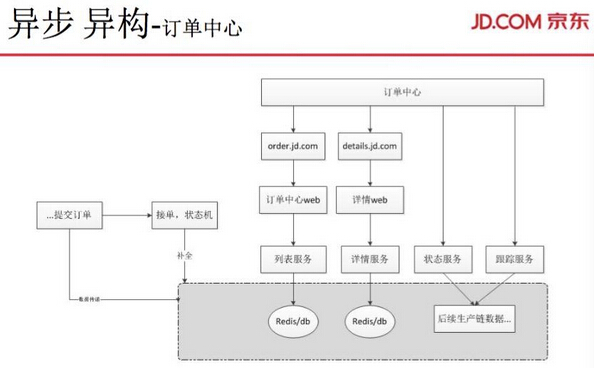
关于订单中心的异步异构,订单中心原来都是从订单表直接调出的。随着体量增大,系统无法承载访问,我们异构出订单中心的存储,支付台帐存储等。 异构出来数据都具有业务针对性存储。数据体量会变小,这样对整体的优化提升提供很好的基础。
这样的存储隔离,对订单状态更新压力也会减小,对支付的台帐、对外部展示的性能也会提升。大家会疑问,这些数据可能会写丢。我们从第一项提交开始,直接异步写到订单中心存储,到后面订单状态机会补全。如果拆分不出来,后面就生产不了。也就是说,到不了订单中心,数据生产不了,一些异步没成功的数据就会在这个环节补全。
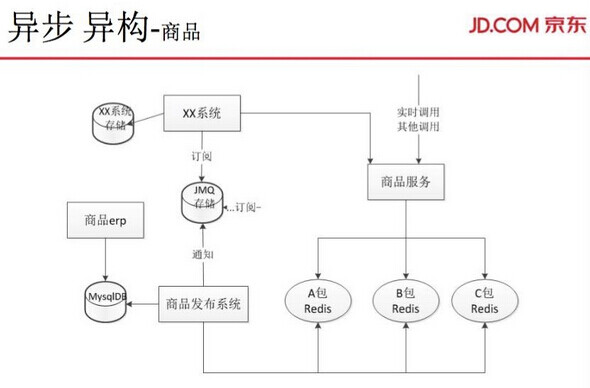
然后是商品的异步异构。2013 年,商品团队面临的访问量,已经是几十亿。如何去应对这个情况呢?很多商品数据贯穿了整个交易,包括交易的分析、各个订单的系统都会调商品系统。我们会针对系统优化。比如,针对促销系统调用,促销系统主要调用特殊属性,我们把这些属性存到促销系统的特有存储。库存系统也类推。调用的特殊属性的方法也不一样。譬如大家电的长宽高这些特有属性,不像前端商品页里只是基本属性。这样就把所有的属性异构处理,针对商品纬度、商品 ID 等所有数据会异构一份到库存、促销、单品页,后面进行改造的时候,又将数据分 A 包、B 包、C 包。京东的业务很复杂,有自营,又有平台数据,A 包可能是基础数据,B 包可能是扩展数据,C 包可能是更加偏的扩展数据。这样,促销系统可能调用的是 B 包的扩展属性,也有可能调用的是 A 包的基础属性。单品页访问 A 包、B 包,调的集群是不一样的。这样存储的容量就可以提高两倍,系统的容灾承载力也会提高。
商品原来是一个单表,后来慢慢发展成为了一个全量的商品系统,包括前端、后端整个一套的流程。异步异构完了之后,系统可进行各方面的优化,这样系统的容量也会慢慢接近预期值。然后找到系统容量的最大值,如果超过这个值,整个系统就会宕机。那么,我们会做分流和限流,来保证系统的可用性。否则,这种大流量系统一旦倒下去,需要很长的时间才能恢复正常,会带来很大的损失。
分流限流
在 618、双 11 时候,手机、笔记本会有很大力度的促销,很多人都会去抢去刷。有很多商贩利用系统去刷,系统流量就不像用户一秒钟点三四次,而是一分钟可以刷到一两百万。怎样预防这部分流量?我们会优先限掉系统刷的流量。
-
Nginx 层: 通过用户 IP、Pin,等一下随机的 key 进行防刷。
-
Web 层: 第一层,Java 应用实列中单个实列每分钟,每秒只能访问多少次;第二层 ,业务规则防刷,每秒单用户只能提交多少次,促销规则令牌防刷。
从 Nginx,到 Web 层、业务逻辑层、数据逻辑层,就会分流限流,真正落到实际上的流量是很小的,这样就会起到保护作用,不会让后端的存储出现崩溃。从前面开始,可能访问价格或者购物车的时间是 10 毫秒,保证 20 台的机器一分钟的流量是一百万、两百万。如果是 40 台机器的话,承载能力会很强,会透过 Java 的服务,压倒存储,这样会引发更大的问题,庞大存储一旦出现问题很难一下恢复。如果从前面开始一层一层往下限,就可以起到保护底层的作用。中间层出问题比较容易处理,如 Web 层,限流会消耗很多 CPU,会一步步加入更多机器,这样就能够解决这个问题。
我们需要降级分流限流。
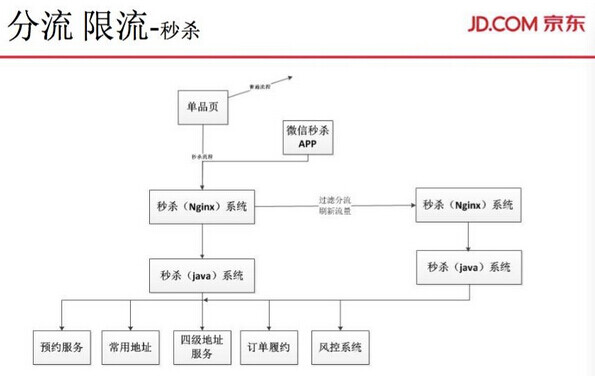
下面结合秒杀系统来讲讲如何限流分流。2014 年才产生秒杀系统。当时,在同一时刻可能有 1500 万人预约抢一件商品,抢到系统不能访问。后端服务都没有出现这些问题,有的服务费不能正常展现。后来就专为抢购设计了一个秒杀系统。正常情况下,有大批量用户需要在同一时间访问系统,那么就从系统结构上分出去这些流量。秒杀系统尽量不影响主流层的入口,这样就分离出来一部分数据。
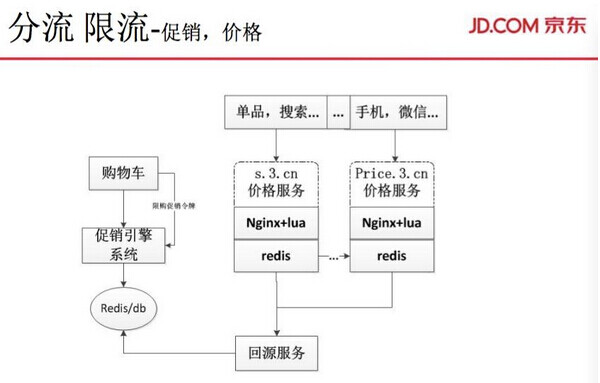
接下来讲讲促销和价格。主力调用价格的服务主要在促销引擎,限流主要是通过购物车服务,购物车到促销引擎又会限流,促销引擎里面会有令牌。比如,有 5000 个库存,发 50 万个令牌到前端去,肯定这 5000 个库存会被抢完,不可能再把其他服务的量打到后面,这样会保护促销引擎,这是一种总令牌模式的保护。后面的分流性能,会分集群式、重要程度去做。另外,一些广告的价格服务,我们会优先降级,如果出问题的话会限制。另外,有一部分刷引擎刷价格服务的数据,正常情况下是保证它正常使用,但是一旦出现问题,我们会直接把它降级,这样就保护了真实用户的最好体验,而不是直接清除程序的应用。
容灾降级

每次双 11 活动,我们会做很多的容灾和降级,有多中心交易、机房容灾、业务容灾等各种纬度的容灾。大概统计了一下做过的一些容灾方案。
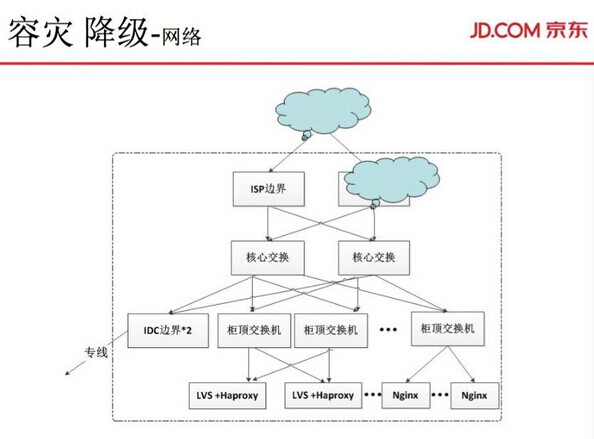
首先是网络容灾。前面说到 SB 中间件、域名解析,我们运维自己会做了核心交换机两层专线。这是我们运维部做的一些网络架构图,两边相互容灾的一个结构。有 LVS、HA、域名及解析,只是单服务挂了,通过交换机,我们可以从一个机房切换到另一个机房,因为会做一些域名的解析和切换。
(点击放大图像)

应用系统相互调用容灾和降级:结算的容灾和降级。应用系统大部分能够降,比如库存状态。如果像优惠券这些不重要的服务,备注信息,可直接降级服务,不用去访问它,直接提交就行。在提交订单时候,首先我们会保证必要服务,这些服务都会有很多的保护措施。每个应用里面,应用级别、服务级别的容灾,比如地址服务、库存状态容灾可以直接先降级。到提交的时候,我们直接对库存做限制。
(点击放大图像)

应用内部的容灾。库存就是结算前面的系统应用的服务,再到细一层的我们的库存服务,这是每一个服务的容灾降级。从库存状态这边的话,从网络设备内层,有网络容灾降级。应用内部有对于预算服务的降级,预算服务会有预算库存,原来是写MySQL 数据库。正常情况下,预算库存是写MASIC 预算库,当出现问题的时候,我们会异步堆列到本地机器,装一个程序去承载这个异步MySQL 数据的落地,然后再通过Work 把它写到MySQL 服务里面。正常情况下,是双写MySQL、redis,当MySQL 承载不住的时候,我们会把MySQL 异步写到里面。
这里面都会有开关系统去控制。当提交订单产生变更的时候,才会把库存状态从这边推到这个库存状态这边,因为库存状态的调用量跟价格一样很大。今年我们看到的最大调用量是一分钟2600 万。这样不可能让它直接回原到MySQL,跟直接库存的现实存储里面。通过预算系统把这个状态从左边算好,直接在推送过到真正的存储,这样就把这个存储剥离出来,这也算一种异步异构,这样我们会提升它的容量。
这是原来的结构,就是redis 直接同步,然后直接访问。现在把它改成是,直接让左边的预算服务去推送到状态服务里面。
监控

最后主要就是监控系统,我们运维提供了网络监控、机器监控。
网络监控包括我们看到的SBR,以及一些专线网络监控,如交换机、柜顶交换机、核心交换机的监控。
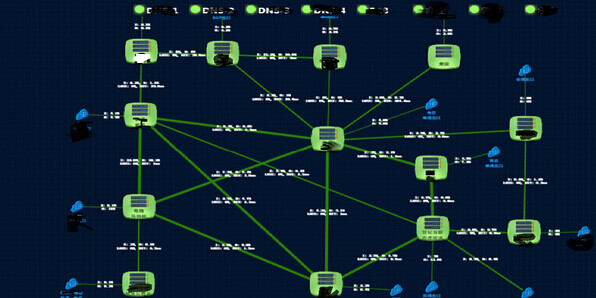
接下来是应用的系统监控。机器监控有CPU、磁盘、网络、IO 等各方面系统的监控。业务纬度的监控,有订单量、登陆量、注册量等的监控。京东机房微屏专线的一个网络平台的监控,里面有很多专线,它们相互之间的流量是怎么样?图中是我们监控系统,是机器之间的监控,包括机器直接对应的交换机、前面的柜机交换机等的网络监控等。
这是应用系统里面的方法监控,后面是业务级别的监控。订单级别的包括注册量、库存、域站,或者区域的订单、金额、调用量的监控都会在这里体现。真正到大促的时候,不可能经常去操作我们的系统,去修改它的配置。正常情况下都是去查看这些监控系统。2012 年之后,监控系统一点一点积累起来。当量越来越大,机器资源越来越多之后,这些监控都会直接影响正常服务,服务用户的质量会下降,可能20 台机器宕了一台机器,不会影响全部效果。所以,监控的精准性是一步步慢慢提高的。
(点击放大图像)

谢谢大家!
感谢陈兴璐对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论