上一篇文章讨论了Redis 的常用数据类型与存储机制,本文会讨论一下Redis 的复制功能以及Redis 复制机制本身的优缺点以及集群搭建问题。
Redis 复制流程概述
Redis 的复制功能是完全建立在之前我们讨论过的基于内存快照的持久化策略基础上的,也就是说无论你的持久化策略选择的是什么,只要用到了 Redis 的复制功能,就一定会有内存快照发生,那么首先要注意你的系统内存容量规划,原因可以参考我上一篇文章中提到的 Redis 磁盘 IO 问题。
Redis 复制流程在 Slave 和 Master 端各自是一套状态机流转,涉及的状态信息是:
Slave 端:
REDIS_REPL_NONE
REDIS_REPL_CONNECT
REDIS_REPL_CONNECTED
Master 端:
REDIS_REPL_WAIT_BGSAVE_START
REDIS_REPL_WAIT_BGSAVE_END
REDIS_REPL_SEND_BULK
REDIS_REPL_ONLINE
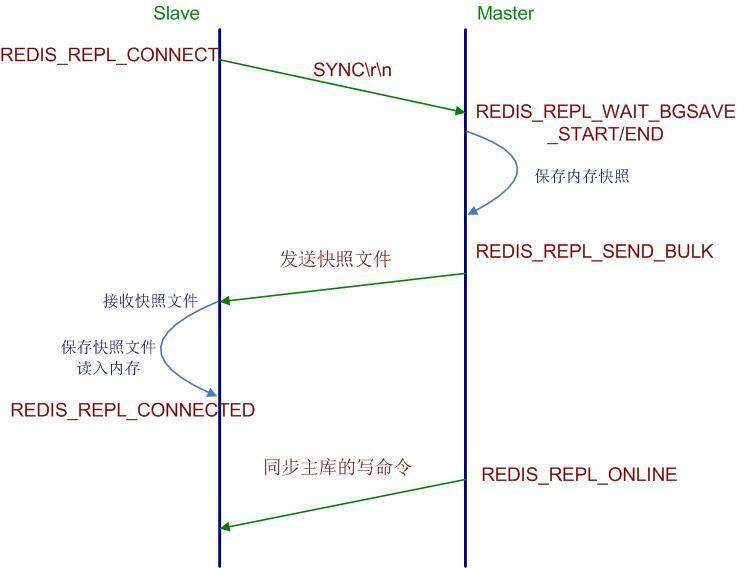
整个状态机流程过程如下:
- Slave 端在配置文件中添加了 slave of 指令,于是 Slave 启动时读取配置文件,初始状态为 REDIS_REPL_CONNECT。
- Slave 端在定时任务 serverCron(Redis 内部的定时器触发事件) 中连接 Master,发送 sync 命令,然后阻塞等待 master 发送回其内存快照文件 (最新版的 Redis 已经不需要让 Slave 阻塞)。
- Master 端收到 sync 命令简单判断是否有正在进行的内存快照子进程,没有则立即开始内存快照,有则等待其结束,当快照完成后会将该文件发送给 Slave 端。
- Slave 端接收 Master 发来的内存快照文件,保存到本地,待接收完成后,清空内存表,重新读取 Master 发来的内存快照文件,重建整个内存表数据结构,并最终状态置位为 REDIS_REPL_CONNECTED 状态,Slave 状态机流转完成。
- Master 端在发送快照文件过程中,接收的任何会改变数据集的命令都会暂时先保存在 Slave 网络连接的发送缓存队列里(list 数据结构),待快照完成后,依次发给 Slave, 之后收到的命令相同处理,并将状态置位为 REDIS_REPL_ONLINE。
整个复制过程完成,流程如下图所示:
Redis 复制机制的缺陷
从上面的流程可以看出,Slave 从库在连接 Master 主库时,Master 会进行内存快照,然后把整个快照文件发给 Slave,也就是没有象 MySQL 那样有复制位置的概念,即无增量复制,这会给整个集群搭建带来非常多的问题。
比如一台线上正在运行的 Master 主库配置了一台从库进行简单读写分离,这时 Slave 由于网络或者其它原因与 Master 断开了连接,那么当 Slave 进行重新连接时,需要重新获取整个 Master 的内存快照,Slave 所有数据跟着全部清除,然后重新建立整个内存表,一方面 Slave 恢复的时间会非常慢,另一方面也会给主库带来压力。
所以基于上述原因,如果你的 Redis 集群需要主从复制,那么最好事先配置好所有的从库,避免中途再去增加从库。
Cache 还是 Storage
在我们分析过了 Redis 的复制与持久化功能后,我们不难得出一个结论,实际上 Redis 目前发布的版本还都是一个单机版的思路,主要的问题集中在,持久化方式不够成熟,复制机制存在比较大的缺陷,这时我们又开始重新思考 Redis 的定位:Cache 还是 Storage?
如果作为 Cache 的话,似乎除了有些非常特殊的业务场景,必须要使用 Redis 的某种数据结构之外,我们使用 Memcached 可能更合适,毕竟 Memcached 无论客户端包和服务器本身更久经考验。
如果是作为存储 Storage 的话,我们面临的最大的问题是无论是持久化还是复制都没有办法解决 Redis 单点问题,即一台 Redis 挂掉了,没有太好的办法能够快速的恢复,通常几十 G 的持久化数据,Redis 重启加载需要几个小时的时间,而复制又有缺陷,如何解决呢?
Redis 可扩展集群搭建
1. 主动复制避开 Redis 复制缺陷。
既然 Redis 的复制功能有缺陷,那么我们不妨放弃 Redis 本身提供的复制功能,我们可以采用主动复制的方式来搭建我们的集群环境。
所谓主动复制是指由业务端或者通过代理中间件对 Redis 存储的数据进行双写或多写,通过数据的多份存储来达到与复制相同的目的,主动复制不仅限于用在 Redis 集群上,目前很多公司采用主动复制的技术来解决 MySQL 主从之间复制的延迟问题,比如 Twitter 还专门开发了用于复制和分区的中间件 gizzard( https://github.com/twitter/gizzard ) 。
主动复制虽然解决了被动复制的延迟问题,但也带来了新的问题,就是数据的一致性问题,数据写 2 次或多次,如何保证多份数据的一致性呢?如果你的应用对数据一致性要求不高,允许最终一致性的话,那么通常简单的解决方案是可以通过时间戳或者 vector clock 等方式,让客户端同时取到多份数据并进行校验,如果你的应用对数据一致性要求非常高,那么就需要引入一些复杂的一致性算法比如 Paxos 来保证数据的一致性,但是写入性能也会相应下降很多。
通过主动复制,数据多份存储我们也就不再担心 Redis 单点故障的问题了,如果一组 Redis 集群挂掉,我们可以让业务快速切换到另一组 Redis 上,降低业务风险。
2. 通过 presharding 进行 Redis 在线扩容。
通过主动复制我们解决了 Redis 单点故障问题,那么还有一个重要的问题需要解决:容量规划与在线扩容问题。
我们前面分析过 Redis 的适用场景是全部数据存储在内存中,而内存容量有限,那么首先需要根据业务数据量进行初步的容量规划,比如你的业务数据需要 100G 存储空间,假设服务器内存是 48G,那么根据上一篇我们讨论的 Redis 磁盘 IO 的问题,我们大约需要 3~4 台服务器来存储。这个实际是对现有业务情况所做的一个容量规划,假如业务增长很快,很快就会发现当前的容量已经不够了,Redis 里面存储的数据很快就会超过物理内存大小,那么如何进行 Redis 的在线扩容呢?
Redis 的作者提出了一种叫做 presharding 的方案来解决动态扩容和数据分区的问题,实际就是在同一台机器上部署多个 Redis 实例的方式,当容量不够时将多个实例拆分到不同的机器上,这样实际就达到了扩容的效果。
拆分过程如下:
- 在新机器上启动好对应端口的 Redis 实例。
- 配置新端口为待迁移端口的从库。
- 待复制完成,与主库完成同步后,切换所有客户端配置到新的从库的端口。
- 配置从库为新的主库。
- 移除老的端口实例。
- 重复上述过程迁移好所有的端口到指定服务器上。
以上拆分流程是 Redis 作者提出的一个平滑迁移的过程,不过该拆分方法还是很依赖 Redis 本身的复制功能的,如果主库快照数据文件过大,这个复制的过程也会很久,同时会给主库带来压力。所以做这个拆分的过程最好选择为业务访问低峰时段进行。
Redis 复制的改进思路
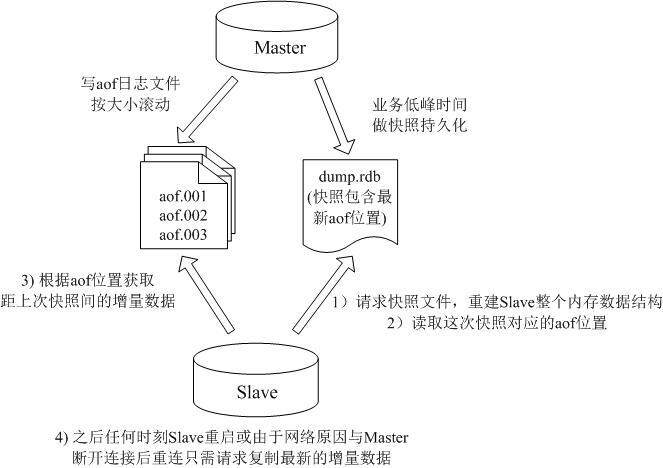
我们线上的系统使用了我们自己改进版的 Redis, 主要解决了 Redis 没有增量复制的缺陷,能够完成类似 Mysql Binlog 那样可以通过从库请求日志位置进行增量复制。
我们的持久化方案是首先写 Redis 的 AOF 文件,并对这个 AOF 文件按文件大小进行自动分割滚动,同时关闭 Redis 的 Rewrite 命令,然后会在业务低峰时间进行内存快照存储,并把当前的 AOF 文件位置一起写入到快照文件中,这样我们可以使快照文件与 AOF 文件的位置保持一致性,这样我们得到了系统某一时刻的内存快照,并且同时也能知道这一时刻对应的 AOF 文件的位置,那么当从库发送同步命令时,我们首先会把快照文件发送给从库,然后从库会取出该快照文件中存储的 AOF 文件位置,并将该位置发给主库,主库会随后发送该位置之后的所有命令,以后的复制就都是这个位置之后的增量信息了。
Redis 与 MySQL 的结合
目前大部分互联网公司使用 MySQL 作为数据的主要持久化存储,那么如何让 Redis 与 MySQL 很好的结合在一起呢?我们主要使用了一种基于 MySQL 作为主库,Redis 作为高速数据查询从库的异构读写分离的方案。
为此我们专门开发了自己的 MySQL 复制工具,可以方便的实时同步 MySQL 中的数据到 Redis 上。
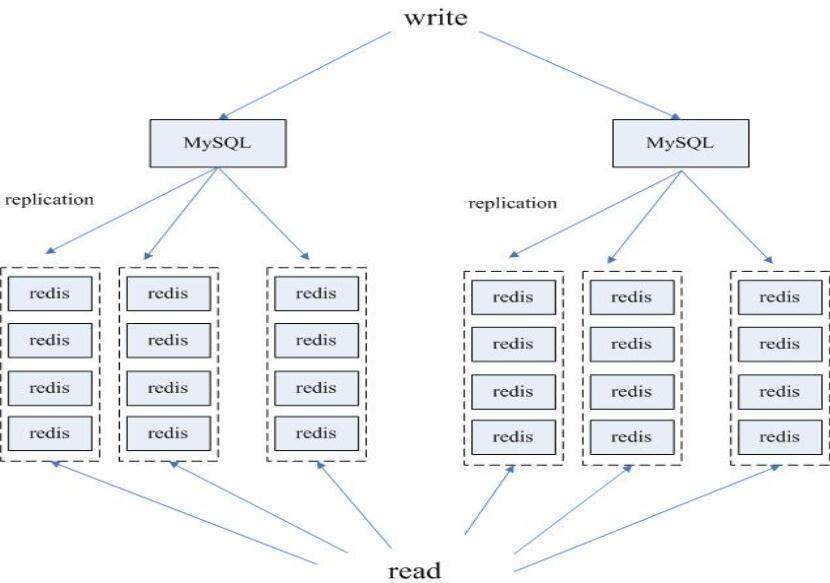
(MySQL-Redis 异构读写分离)
总结:
- Redis 的复制功能没有增量复制,每次重连都会把主库整个内存快照发给从库,所以需要避免向在线服务的压力较大的主库上增加从库。
- Redis 的复制由于会使用快照持久化方式,所以如果你的 Redis 持久化方式选择的是日志追加方式 (aof), 那么系统有可能在同一时刻既做 aof 日志文件的同步刷写磁盘,又做快照写磁盘操作,这个时候 Redis 的响应能力会受到影响。所以如果选用 aof 持久化,则加从库需要更加谨慎。
- 可以使用主动复制和 presharding 方法进行 Redis 集群搭建与在线扩容。
本文加上之前的 2 篇文章基本将 Redis 的最常用功能和使用场景与优化进行了分析和讨论,实际 Redis 还有很多其它辅助的一些功能,Redis 的作者也在不断尝试新的思路,这里就不一一列举了,有兴趣的朋友可以研究下,也很欢迎一起讨论,我的微博 ( http://weibo.com/bachmozart ) @摇摆巴赫。
感谢张凯峰对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家加入到 InfoQ 中文站用户讨论组中与我们的编辑和其他读者朋友交流。




