
Kimi发布了 K2,这是一个混合专家型大语言模型,拥有 320 亿个激活参数和 1.04 万亿个总参数,基于 15.5 万亿个 token 训练。这次发布引入了 MuonClip,这是一种新的优化器,它在 Muon 优化器的基础上增加了 QK-clip 技术,旨在解决训练不稳定性问题,团队报告称在预训练期间实现了“零损失峰值”。该模型有两种变体:基础版本和 K2 Thinking,后者在测试推理、编码和代理能力的基准测试中声称达到了最先进的结果,包括在 Humanity's Last Exam(HLE)中使用工具时获得 44.9%,在 BrowseComp 中的 60.2%,以及在 SWE-Bench Verified 中的 71.3%。这次发布意味着 K2 成为开源模型领域的有力竞争者,特别是在软件工程和代理任务中,其中模型展示了强大的泛化能力。
团队通过一系列扩展实验验证了 MuonClip。他们首先使用标准 Muon 优化器训练了一个中等规模的模型,该模型拥有 90 亿个激活参数和 530 亿个总参数。然后研究人员测试了 QK-Clip 是否影响模型性能,发现 MuonClip 保持了 Muon 的优化特性,而没有对损失轨迹产生负面影响。对于全规模的 Kimi K2 模型,团队应用了τ值为 100 的 MuonClip,并在训练过程中跟踪了最大注意力逻辑值。最大逻辑值在训练过程中逐渐降低到正常操作范围,无需手动调整,团队将此作为优化器稳定性改进的证据。
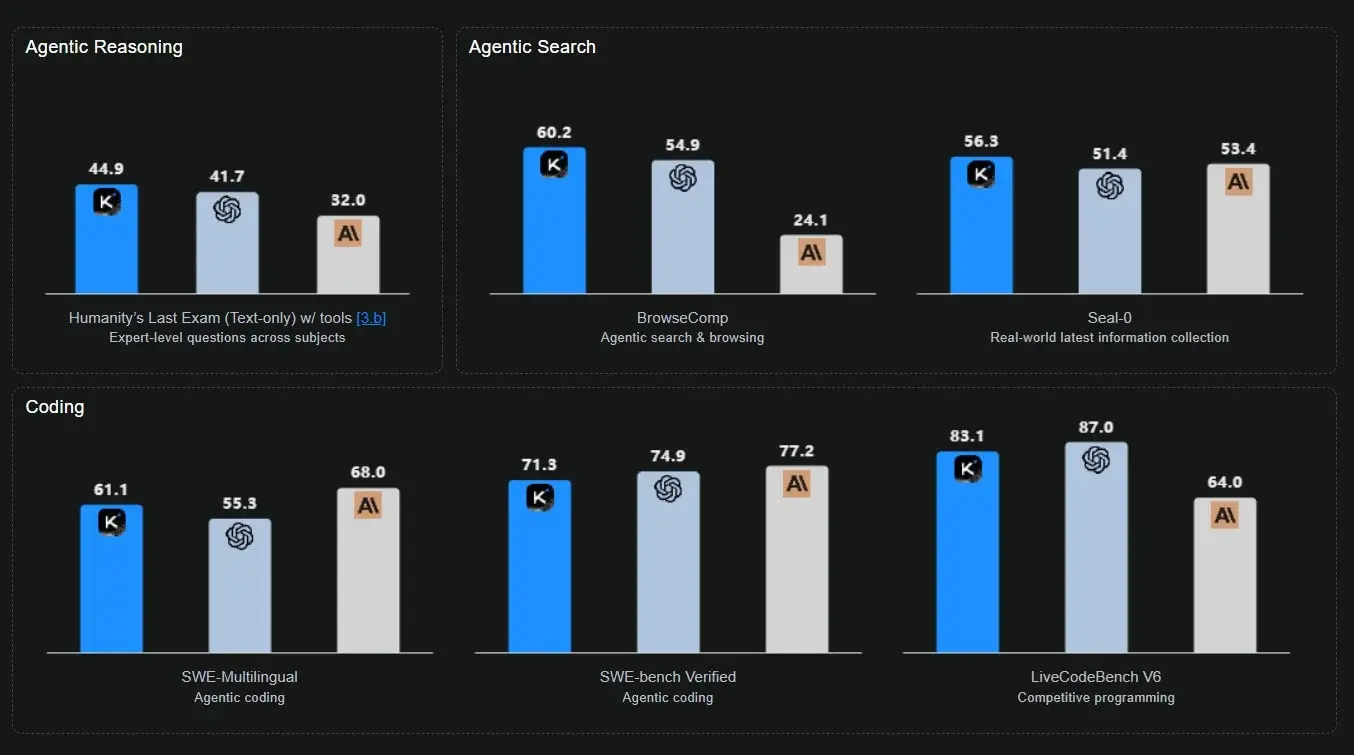
来源:Kimi K2 基准测试结果
Kimi 在 NVIDIA H800 GPU 集群上训练了 K2,每个节点包含 2TB 的 RAM 和通过 NVLink 和 NVSwitch 连接的 8 个 GPU。集群使用 8×400 Gbps RoCE 互连进行节点间通信。团队设计了一种灵活的并行策略,允许在任何 32 的倍数节点上进行训练,解决了他们在大型语言模型训练期间所描述的动态资源可用性问题。
为了管理内存使用,团队对特定操作应用了选择性重计算,包括 LayerNorm、SwiGLU 和多头潜在注意力(MLA)上投影,选择了他们认为是成本低廉但占用空间大的阶段。训练过程还重新计算了 MoE 下投影,以进一步减少激活内存需求。
该模型可以执行 200 到 300 个由长期规划和自适应推理驱动的顺序工具调用。K2 Thinking 执行的周期遵循思考→搜索→浏览器使用→思考→编码的模式,生成和完善假设,同时验证证据和构建答案。这种方法允许模型将模糊、开放式问题分解为可操作的子任务。
对于部署,团队解决了思考模型特有的推理效率挑战。虽然低比特量化降低了推理延迟和 GPU 内存使用,但思考模型生成的长输出序列通常在量化时会导致性能下降。Kimi 在后训练阶段应用了量化感知训练(QAT),在 MoE 组件上使用 INT4 仅权重量化。这种实现使 K2 Thinking 能够以大约 2 倍的生成速度提升运行原生 INT4 推理。
Kimi K2许可证包括了一个商业使用要求。使用模型或其衍生产品用于商业产品或服务的组织,如果超过 1 亿月活跃用户或每月收入超过 2000 万美元,必须在这些产品或服务的用户界面上显著标明“Kimi K2”。这种归属要求将 K2 的许可证与通常不强制要求高规模商业部署的用户明确标注的标准开源许可证区分开来。
Awni Hannun 在 Apple Silicon 上测试了 K2 Thinking,报告的性能结果展示了模型在数据中心基础设施之外的可访问性。Hannun 表示:
新的 1 万亿参数 Kimi K2 Thinking 模型在 2 个 M3 Ultra 上以其原生格式运行良好 - 没有质量损失!该模型在 int4 上进行了量化感知训练(qat)。在这里,它使用 mlx-lm 中的流水线并行处理生成了大约 3500 个 token,速度为每秒 15 个 token。
提供 AI 模型独立分析的 Artificial Analysis 表示:
Kimi K2 Thinking 是新的领先开放权重模型:它在 Agent 环境中表现出特别的强度,但非常啰嗦,生成的 token 数量是完成我们的智能指数评估的模型中最多的。
Hacker News 上的一位评论者指出:
模型之间的终极竞争最终将成为能源竞争。中国的开源模型在能源消耗方面具有主要优势,中国本身在能源资源方面也具有巨大优势。它们可能不一定能超越美国,但它们可能也不会落后太多。
Kimi K2 进入了一个竞争激烈的开源模型领域,其中包括 DeepSeek-R1——它也专注于扩展推理,阿里巴巴的 Qwen 模型(包括用于推理任务的QwQ),Mistral 的 Mixtral MoE 系列,以及 Meta 的 Llama 3 家族。
K2 Thinking 变体可以在 kimi.com 上找到,并通过 Moonshot API 平台提供。团队已在 Hugging Face 上发布了模型权重,那里可以访问技术细节和实现指导。Moonshot平台上提供了完整的 API 文档,为希望将 K2 集成到他们应用中的开发人员提供了集成规范。
原文链接:Kimi's K2 Opensource Language Model Supports Dynamic Resource Availability and New Optimizer




