

列表页推荐

这是印度语版的推荐列表页,左边跟常见 feed 推荐的产品形态是非常类似的,有不同的异构的卡片:
新闻聚合页,点开以后就是一个聚合页。
视频,点开是一个沉浸式播放的聚合页。
普通的图文,点开是一个落地页、详情页。
Memes,印度市场特有的内容 Memes。这种内容主要是一张图片(或者动图),这种内容比较特殊,可以直接在列表页消费,直接看了就曝光、阅读完成,就结束了,如果点开的话就是 Memes 的沉浸式页面。
总结起来,内容消费的路径有:
一种是,列表页里直接消费的内容,如 Memes。
一种是,落地页中消费的内容。
还有就是通过聚合页再次跳到落地页消费的内容。
1. 目标确定
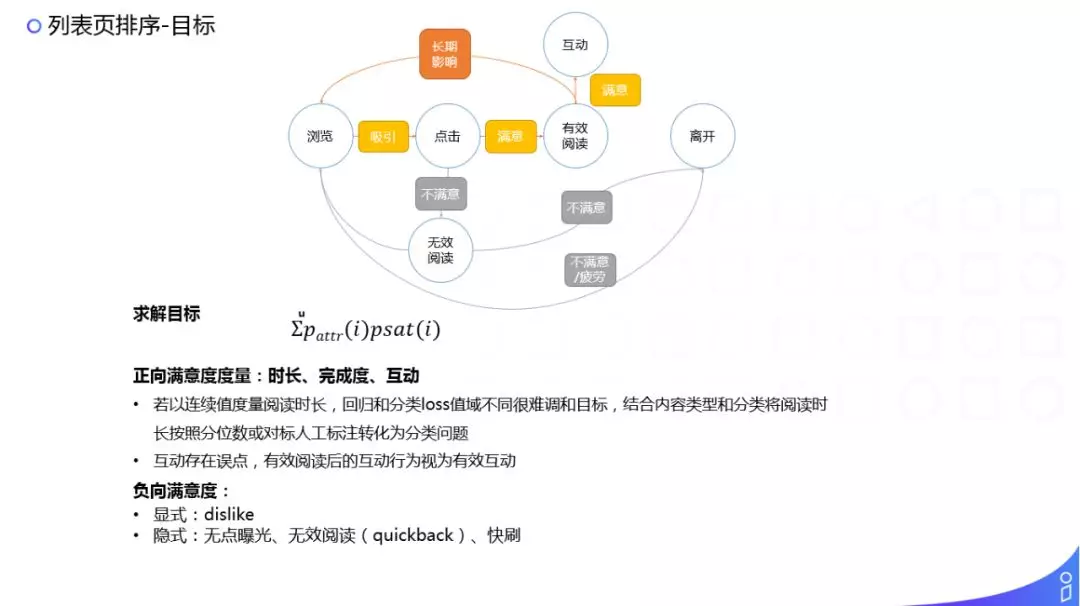
接下来讲下如何确定目标。对于推荐系统来说,最核心的就是如何确定目标,如果目标定不好,可能就会出现标题党的问题。在解释最终求解目标之前,先看下用户的行为路径:
图中圆圈表示的是用户的一种行为,方框表示用户发生这种行为的心里活动。
比如用户看到一篇内容之后,如果这个内容有吸引用户的点,也就是产生了吸引,会发生一次点击,在点击看到详情页的内容之后,如果对这个内容比较满意,用户可能会形成一次有效的阅读,有一次有效阅读之后,如果用户还是觉得这个内容非常好、非常满意,用户可能会有一些互动的行为,比如分享、点赞、评论等。
当然还有种可能:用户在列表页里看到一篇内容之后,用户不是很感兴趣,直接就跳走了或者快速的划过;再就是用户点开了一篇类似标题党的内容,但是内容完全不是用户想要的,这其实是一个强烈的不满意会,一个无效的阅读,然后用户就离开了。如果把所有不满意的行为看作是一种负向的满意度,我们建模的核心目标应该是一个用户累计的所有满意的行为,使满意行为累积量最大化。
这里所有标黄色的路径其实是一个偏正向的路径,标灰色的路径是个偏负向的路径,我们的目标是使正向的路径逐渐的累积,对用户逐渐的产生一个比较正向的影响。
所以求解目标是:
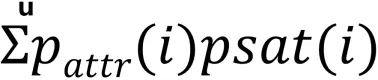
左边为吸引的概率,右边是满意的概率,然后所有看过的内容满意度最大化。
如何衡量有效的阅读?一个传统的方法是用阅读时长来衡量是不是一个满意的阅读,但实际上用户满意的心理和时长不是一个完全线性的关系。比如有一类行为是用户阅读了 5s 或者 10s 以下快速离开(quickback),这种无效阅读,无论是 3s、5s 还是 7s、8s,效果都是用户对内容完全不满意,应该快速离开的。再有,当用户读一篇长文时,大家可能都有这样的体会,长文阅读可能会有一个瓶颈,就是大家花了很长时间在一篇文章阅读上,但是读到一定程度的时候,可能再也读不下去了,能花的时间就存在一个极限了,所以最后满意度和时长关系是类似 sigmoid 的函数关系。因此,我们在对满意度建模时,其实是把回归问题变成了一个分类/二分类/多分类的问题。这里可能会涉及怎么做时长回归的问题(由于不同类型、分类、主题的内容以及内容信息量的不同,其阅读时长总量是会变化的),一种简单的方法是用这些维度,对内容进行统计分析求出分布,然后用分位数来截断,通过人工来排出几个档,也可以做一些人工标注来拟合这样的分类。结合 UC 国际信息流,稍微特殊的一点是列表页有 Memes 这样的图片内容。这种内容由于强调的是互动性(一般承载的是一些高分享类的内容,如早安、节日问候、搞笑的图片等),在产品设计时,会把这种交互行为做前置,在列表页就放出来,这样就可能存在误点,用户还没看到或看完这篇内容,就产生了点击,需要做一些过滤。
负向满意度,分为:
显式:很多产品在设计时,都会在内容边上有个 XX,也就是 dislike,比较直白的显示了负向满意度。
隐式:无点的曝光、无效阅读 ( quickback )、快刷等动作。
说完了总的求解目标之后,这里列举的吸引和满意,满意还可以拆解成更多的步骤,比如刚才说的有效阅读和互动行为,可以再做分解,但无论如何都是一个多目标的任务,针对这样的多目标任务该如何建模呢?
2. 多目标点估计
这里列举了一些方法,都是阿里巴巴集团内部在各个业务线上的一些沉淀:
① ESMM:
这是阿里妈妈团队在解决多目标问题的一种解决方案。ESMM 可以解决我们在对多目标问题进行求解时,比如左边是转化率的目标,右边点击率目标,往往是独立进行求解的。使用样本时,该如何表达上文说到的转移概率?常规做法用到的样本,如转化率使用的样本是所有的有点样本,由于在训练时,使用的样本是部分样本,在预测目标时,使用的是全样本,导致样本分布会存在一定的偏差。ESMM 是把样本空间放到全空间,在定义目标,计算 loss 时,计算的都是全样本空间的 loss,一个是点击率,再有一个是把 CVR 作为一个中间节点,最后求解的 loss 目标是 CTR * CVR,然后底层网络参数共享。
② DBMTL:
DBMTL 模型是淘宝推荐团队对 ESMM 模型进行的改进。主要的改进点:左边这部分就相当于 ESMM 那张图横过来了,是共享参数层;specific layer 是走的不同目标的分支;最重要的是右边 bayesian layer,表达了概率图中目标之间的贝叶斯转移概率的因果关系。如果转移概率之间的关系,受其他的一些 feature 和因素的影响,也可以把那些 feature 加到网络中一起训练,所以 DBMTL 建模的时候还建模了几个目标之间的因果关系。
③ MMoE:
MMoE 类似一个专家系统,有多个子网络,每个子网络使用的特征和网络结构可以有差异,在最终确定多目标的时候进行票选,通过 gate 来赋予不同的权重来做票选。
最后,我们的业务在不同场景上都取得了比较正向的收益,如视频频道和 Push 场景。
多目标这儿写了一个点估计,因为主要用在精排的场景,在做每次的预估时,考虑的都还只是某一条内容的满意度效果。
3. 混排
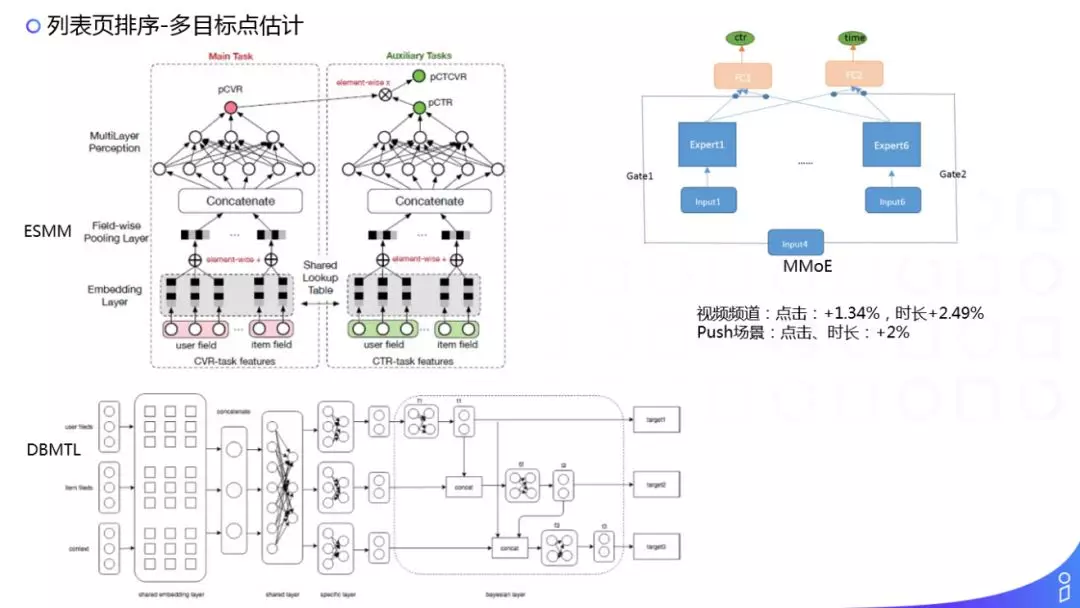
但是在列表页场景,我们要求解的是一个组合最优的效果,也就是说对上面的问题需要做进一步的扩展。在考虑点击率时,还要考虑上下文,我上下文的信息。
然后我们的求解目标也做了一个转换:
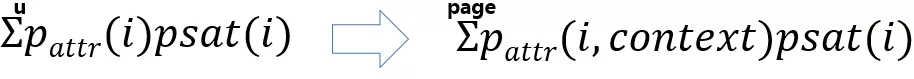
U 转到 page,做了一个独立假设,认为页与页之间是没有关联关系的,但这个假设不一定成立,只是为了把问题简化一下。这样我们的问题就变成了在组合列表页的情况下,如何达到组合最优。比如有 N 条精排的候选集输出,对这 N 条结果输出 M 个槽位的排列,也就是求解排列的最优解。所以搜索空间相当于是 N 的 M 次方,一个非常大的搜索空间,在实际业务中是没法落地的,因为计算复杂度太高了。
所以淘搜这有一个简化版的方法:类似于贪心的一种算法,在每一轮只确定当前这条最优的结果,然后考虑上文,不考虑下文。举个例子,比如现在是第三轮迭代,已经确定了前三个位置的最优组合,现在是求解第四个位置应该选哪一条,预测第四条那个位置最优的一个选项。另外在做贪心搜索时,搜索空间非常受限,受选择顺序的限制。那么 beam search 有一个参数,就是宽度,每次可以把候选集保留 top3,也就是最优组合的 top3 作为候选,再进行下一次的探索,有一定的探索回溯的能力,这样 beamsize 探索的最优空间的大小,可以用来 balance 性能和效果。
还有一点是对上文的建模,怎么表达上文的排列信息,也就是上文内容之间的位置相对关系的信息。这里有一个比较巧妙的方法:用 RNN 的网络结构来表达他们之间的相互关系,然后在计算的过程中(因为是一个贪婪式的计算,每一轮只计算一步),只计算 RNN 的一个 STEP 可以了,所以在时间复杂度上也是可以接受的,这样存储一个 RNN 中间的隐变量就可以了,这就是混排的做法。
内容冷启
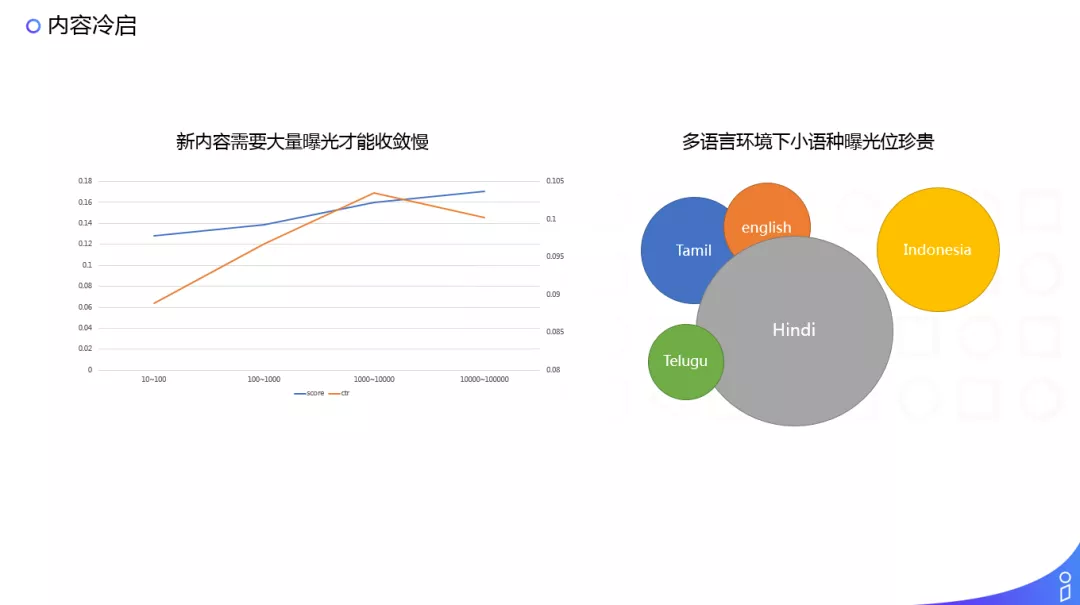
内容冷启问题,有朋友问,如果一个推荐系统完全不做内容理解,是不是也是可行的?这里从其中一个角度说下。
左图是我们现在只用 ID 作为 feature,也就是说核心 feature 是内容的 ID,相当于没有内容理解,这是一个新内容收敛的效果,下边横轴是下发的 PV,可以看到点击率的收敛,要基本上要到千次左右的下发才能达到一个接近收敛的程度,而且起步阶段和后面其实 gap 还是非常大的,用 ID 做推荐就会遇到这样冷启的问题,特别是我们的业务场景又涉及到小语种。因此,对于场景,无论是 item 还是流量都做了很多的细分,所以冷启的问题会尤其的严重一些。
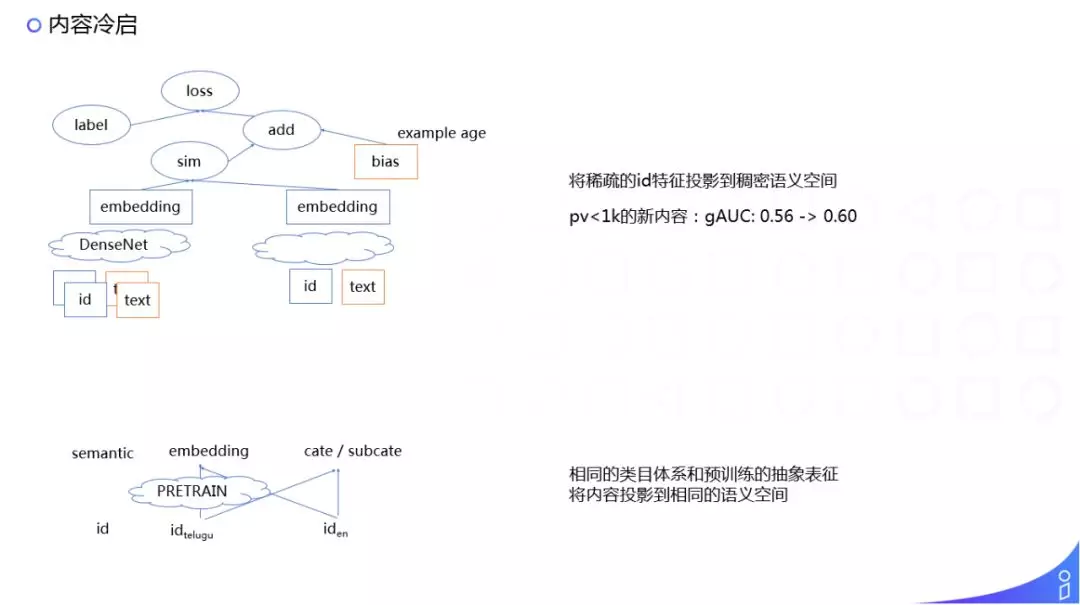
解法其实还是内容理解,我们把 ID 的特征映射到文本域。这里有一个 YouTube 15 年做的一个工作,怎么去掉时间的 bias,就是 Example age,其含义是在采用这条样本时,这个时间点距离这条内容发布的时间点之间的 time diff 时间差是什么样的。加上 bias 的 feature 之后,对时间敏感的内容在下发时就会考虑到下发时间差,相当于提高了时效性。
我们在召回侧 DM match,把 ID 特征加上文本特征之后,冷启(1000 条以下的曝光)内容 AUC 有了不错的提升。
另外,在多语言的体系下,如果能把文本域的表征对齐投影到同一个空间,对冷启应该能起到更好的效果。
总结
简单总结下,结合大家常见的一些问题,本次分享主要介绍了排序中如何确定目标,如何做多目标的点估计以及混排的组合优化,还简单介绍了内容冷启的一些解决思路,主要是特征泛化和语义对齐。本次分享就到这里,谢谢大家。
作者介绍:
杰雄,阿里高级算法专家
本文来自 DataFun 社区
原文链接:

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论