
最近读了本好书-《深度学习推荐系统》,读完不觉全身通畅,于是就有了写这篇文章的想法,把自己的理解和总结分享给大家。
本文将按照从算法到工程的顺序,先介绍一下推荐系统整体架构;再聊聊算法模型的演化;然后是推荐系统的一些设计关键点;最后,结合自身经验和业界最新进展,讨论一下系统的工程化实践。
一、推荐系统整体架构
说到推荐系统,大家应该都不陌生,它几乎已经是任何一个互联网系统的标配。在如今信息爆炸的场景下,如何根据每个人的喜好,快速的把用户“需要”的信息呈现出来,不仅是提高客户体验的需要,也是保证客户留存率,保证下单率的灵药。
推荐的呈现形式可能有多种多样,拿同程艺龙小程序来说,当用户搜索酒店时,酒店列表的顺序就是推荐的体现。推荐的顺序,融合了用户的地理位置、历史消费习惯、品牌偏好等多种信息,把最具“价值”的酒店摆在靠前的位置。
下图展现了一个典型的推荐系统的整体架构,也涵盖了全书所围绕介绍的主要关键点。
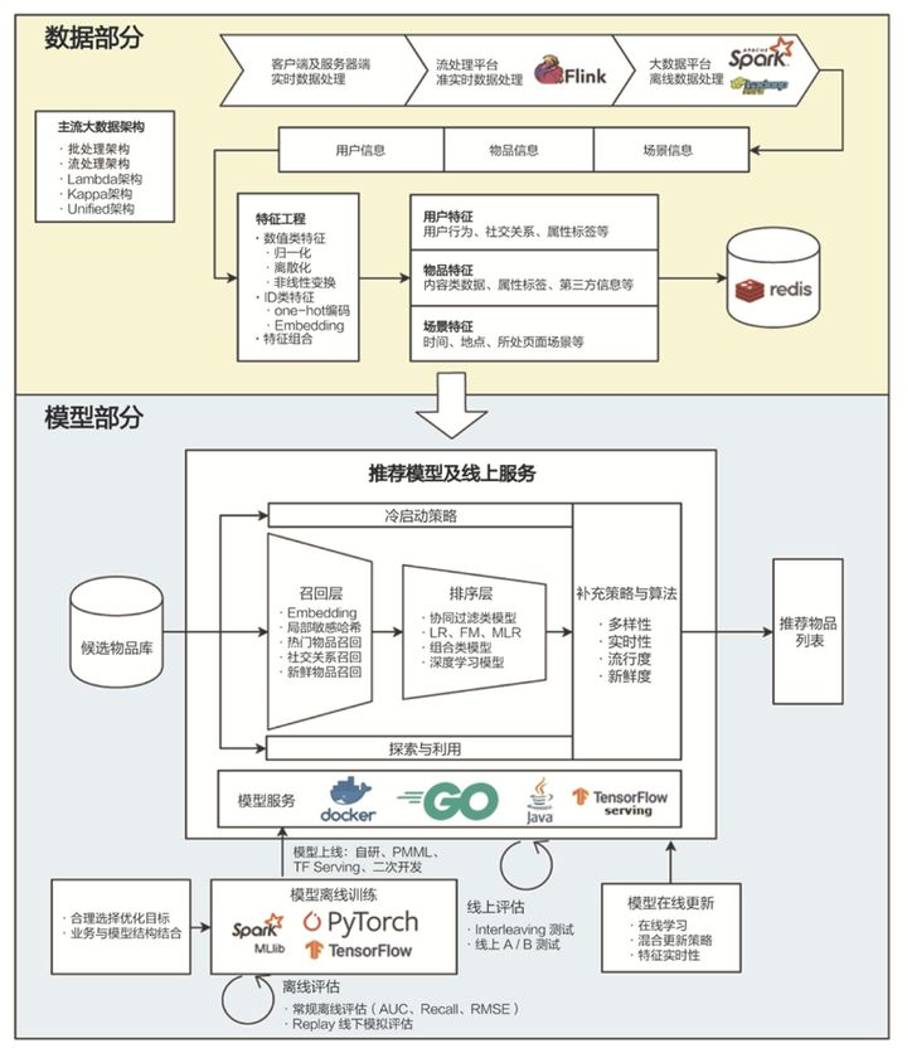
图中将系统整体架构分成“数据部分”和“模型部分”,数据部分的箭头代表了数据加工处理的过程,从数据收集开始,到数据汇总、加工、预处理、到最后数据落地,通过特征工程形成特征数据,供算法模型使用。数据的内容,对于推荐系统来说,一般可以概括为三部分:用户信息、物品信息、场景信息。
目前业界的大数据处理框架很多,从最早一代的 Hadoop 技术体系,到后来的实时流处理框架 Storm,再到后来的流批一体化框架,如 Spark、Flink 等,都是在朝“更大吞吐量”、“更高实时性”、“一体化”方向演进。所谓大数据架构模式:lambda 也好、kappa 也罢,其实主要是解决如何更好的将流、批两种处理模式整合在一起,平衡系统的实时性和吞吐量。
模型部分主要讲了三件事:
1、 推荐模型的演化及特点;
2、 模型的离线训练;
3、 模型的在线部署。
其中,关于模型演化及介绍,书中花了两章的篇幅进行了详细介绍,从机器学习时代到深度学习时代,是本书的精髓。
模型的离线训练即包含了训练框架的选择,也介绍了模型分布式训练的原理,还有些训练方式的奇技淫巧。
模型的在线部署是工业界讨论最多的部分,如何把离线训练的模型引入系统,使其发挥效能,有很多“关键设计”。其中“召回”和“排序”是典型的设计,此外还有冷启动方案、平衡探索利用等很多注意点。
其实近几年,模型推理任务还有一些最新的优化技术,如“模型量化”、“计算图优化”、“知识蒸馏”等,书中讨论的并不是很多,我们将在最后介绍。
接下来,将按照上面的顺序,逐一展开讨论;让我们先进入模型的世界吧。
二、传统推荐模型的演化
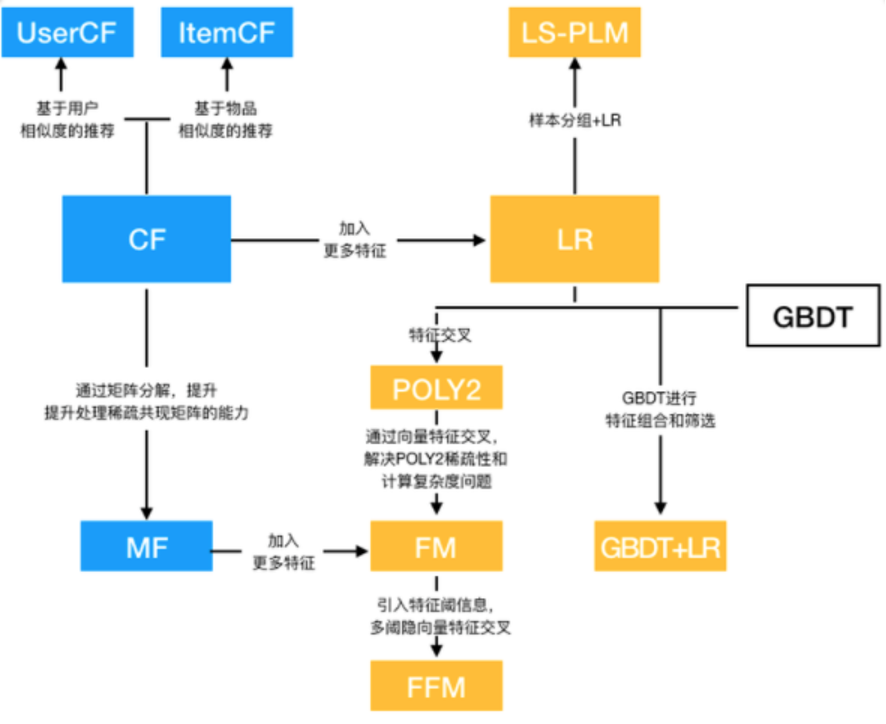
上图已经将前机器学习时代的主要模型概括的很清楚了,书中将这些模型分为 4 类:协同过滤算法族、LR 算法族、因子分解机算法族、组合模型。
协同过滤(CF)可以说是推荐系统算法的鼻祖了,它从用户购买物品的行为中寻找相似性,构建算法模型。所以它又分两种:ItemCF 和 UserCF。购买相似的物品的用户视为“相似”,从而推荐“相似用户”购买而自己又没购买的物品,就是 User Based CF;而反之,被多个相似用户购买的物品视为“相似”,从而推荐“相似物品”给用户自己的就是 Item Based CF。这两种方式没有优劣,视场景而用。UserCF 适用于热点发现以及跟踪热点趋势。而 ItemCF 更适用于兴趣变化较为稳定的应用。
协同过滤历史悠久,可解释性很强,但它也有天然缺陷,如 ItemCF 的热门物品具有很强的头部效应,它能与很多物品产生相似性,从而被推荐,这就使得推荐物品缺乏变化。而且,CF 算法仅仅使用了用户和物品购买信息,无法引入其他特征,使得很多有效信息被遗漏。虽然后续又衍生出矩阵分解(MF)算法,来解决模型的泛化能力,但始终无法引入其他特征。
逻辑回归(LR)是经典的推荐模型,它着眼于用户物品购买矩阵,但又不局限于其中,通过引入用户信息、物品信息及上下文信息,对稀疏矩阵进行预测。其 xw+b ->sigmoid 的数学形式,不仅使其具有可解释性强,又是后来深度学习模型神经元的典型构成。因此,很长一段时间内,LR 都在工业界占据主导地位。
但它的局限性也很明显:表达能力有限,无法进行自动特征交叉。所有的交叉特征提取,完全看算法工程师的“想象力”和“对业务的理解力”。所以其表现也很不稳定。
因此,很快 FM 的时代来了。FM 为每个特征单独引入了隐向量,用向量积代表特征组合后的权重。
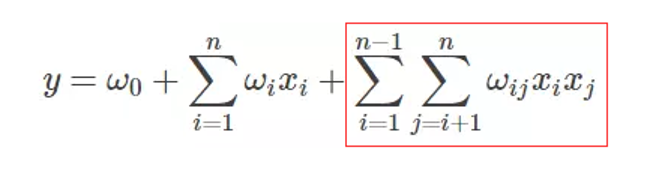
从 FM 的表达式也可以看出,相比 LR,其只是在线性部分后加了两两特征交叉项,如果交叉特征的隐向量维度为 k,n 为特征数量,其额外增加的计算复杂度为 nk。作为 LR 的改进,FM 不仅继承了 LR 的所有优点,还用“不大”的额外开销,解决了特征交叉问题。同时 FM 还没有深度学习模型的复杂性,使其在工程上十分利于部署。
目前,同程艺龙酒店的推荐,很大一部分通道仍然使用的是 FM 模型。轻量、可解释性强、易于部署,同时还能通过不断引入新的特征提高其准确性。这些优点都使这个奋战了多年的“老兵”,在深度学习大行其道的今天,仍然有用武之地。
终于说到“上分神器”——GBDT 了。这个神奇的模型通过将一棵棵简单树进行组合,通过对“残差”进行拟合,使其具有非常好的预测准确性和泛化能力。同时它也能对特征进行自动的筛选和组合。
其优良的性能使其在前几年的机器学习比赛中,几乎是必选的模型。通过不断的调参和模型融合,就能不断在比赛中提高分数,拿到不错成绩。XGBoost 和 LightGBM 是实现了 GBDT 模型的两个经典框架。
但如此优秀的模型也有其局限性。首先高复杂度必然造成上线的困难和可解释性的消解。另外,残差树的形式,也使得其只能串行化训练和预测。因此,工业界在线上实际使用 GBDT 模型进行预测的并不多,而是利用它特征筛选和交叉能力,和其他模型进行组合。
GBDT+LR 就是一个生动的例子,利用 GBDT 特征组合能力,形成多阶特征交叉,然后把产生的每棵子树命中的叶子节点,形成的 one-hot 向量,作为新的特征,送入到 LR 中。这种组合最妙的地方还在于,两个模型可以分开训练,独立升级演化。
GBDT 作为机器学习时代“最后的倔强”,将“简单模型”的各项指标都推向了顶峰,特征交叉的方案也基本挖掘到了极致。但互联网仍在产出海量的数据并对模型提出更高的要求。与此同时,随着算力的提升和数据的积累,深度学习模型也在悄然的崛起。
三、深度学习推荐模型的演化
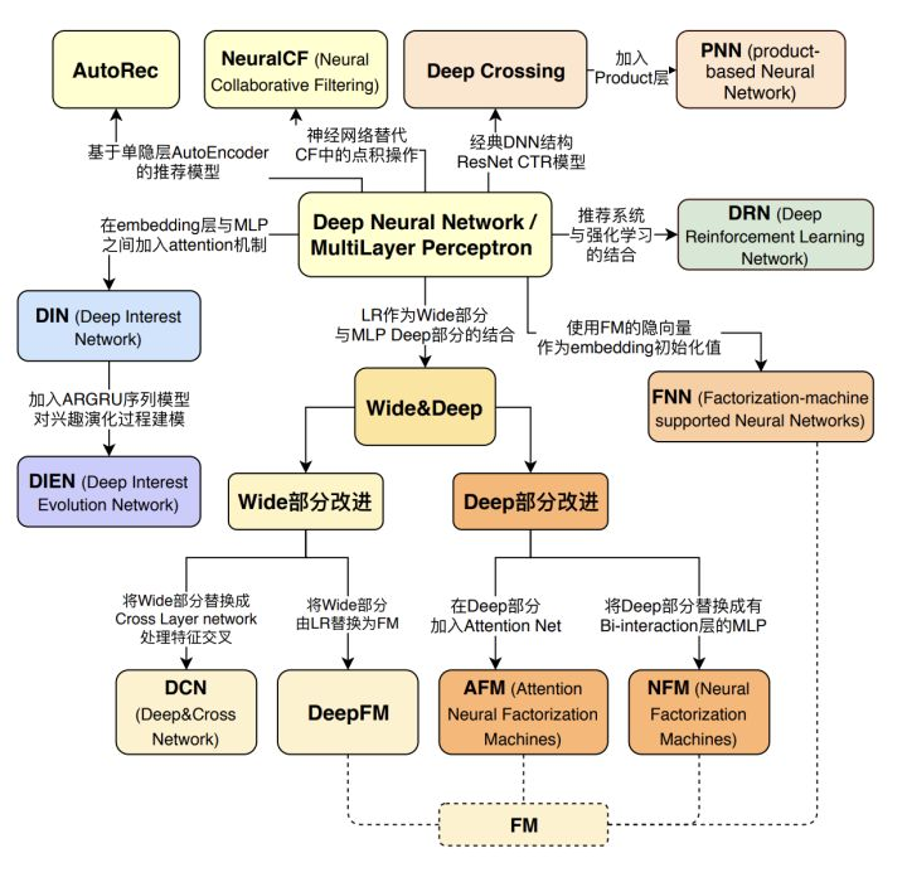
与传统的机器学习相比,深度学习模型一般有更复杂的网络结构,更强的表达能力,能够拟合更复杂的数据模式。
书中的这幅图揭示了推荐领域的深度学习模型演化关系。深度学习模型以多层感知机(MLP)为基础开始各自的演化。MLP 是典型的神经网络结构,多层的结构很好的解决了特征交叉问题。其实在机器学习时代就有 MLP,但由于其相比 LR、FM 等模型,参数量更大;在没有更多数据量的情况下,效果反而不如 LR 和 FM 模型,所以,在实际中,往往应用的不多。但这仍然不能掩盖其在深度学习中的核心地位。
深度学习最开始的实际应用应该说还是 Deep Crossing 和 PNN 系列。Deep Crossing 在实际中大量使用了 Embedding 结构,并使用 stacking 的方式将不同特征拼接起来。而在具体的网络结构中,使用了经典的残差结构,如下图:
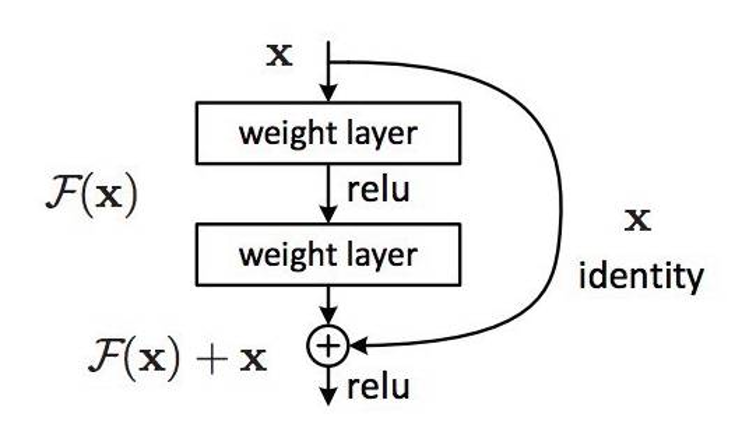
残差结构加了一条跳过网络的路径,使 X 直接加到网络后的输出上,残差结构很好的解决了随着模型加深,训练时梯度消失问题,拟合残差使得模型的拟合能力更强,训练难度更低。最经典的残差结构的提出还是微软的 ResNet,GBDT 某种意义上来说也是针对残差建模。
介绍深度学习模型,不能不提大名鼎鼎的 Wide&Deep,由谷歌于 2016 年提出。
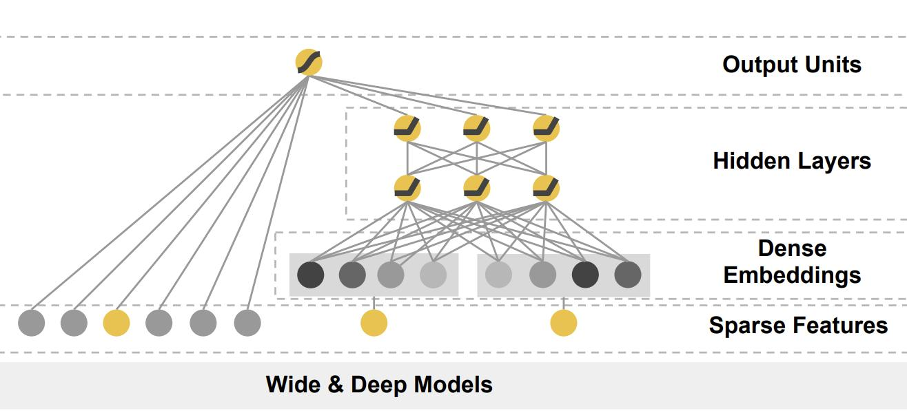
浅层模型具有较强的记忆能力,训练速度快,可解释性强的优点;深度模型是处理特征交叉的好手、具有较强的模型容量和泛化能力。那能不能将二者的优势结合起来呢?Wide&Deep 就是这样一个模型,它包括一个浅层模块和一个深度神经网络模块。谷歌团队最初将其应用在 google 商店 app 推荐中。
但哪些特征需要放在 Deep 端、哪些特征需要放在 Wide 端,需要对业务场景有深刻的理解。
“记忆”和“泛化”在机器学习领域是一对儿相反的词,“记忆”代表对训练数据中共现关系的直接运用;“泛化”则代表模型挖掘特征和最终结果的潜在模式的能力。一般来说模型的“记忆能力”是我们机器学习训练过程中,想极力避免的,“泛化能力”才是我们追求的模型目标。想象一下,一个考生如果只死记硬背,记住了几道题,练习时可能会得高分,但在考试时遇到自己没见过的题就懵了,这是我们不希望看到的。但在 Wide&Deep 中,这两种能力却得到了综合运用。“泛化能力”由 Deep 部分承担,Wide 部分承担“需要死记硬背”的部分。这就好像,考试前,我们既学会了一些解题模式,又要死记硬背一些典型热点题目一样。
谷歌团队将“已安装应用”,作为 Wide 部分的特征,Deep 部分输入则为“全特征”。最后将二者组合起来,形成统一的模型。同程的酒店推荐也有使用 Wide&Deep 模型,目前更多是侧重 Deep 部分的特征挖掘。在实际线上生产环境中,取得了不错的业务效果。
Wide&Deep 模型的提出,打开了不同网络结构融合的新思路。以致后来很多模型都是对 Wide&Deep 模型的 Wide 部分或 Deep 部分进行改造而来。
对 Wide 部分的改进就有 DCN 和 DeepFM,前者是把 Wide 部分换成了交叉网络,而后者则是使用 FM 来代替原有的 LR 部分。
对 Deep 部分的改进则既有结构上的,也有通过引入新的机制的方式。
注意力机制是一次有意义的突破,DIN、AFM 都是这其中有效的尝试。注意力机制模拟了人类认识事务的注意力机制,在图像、语音和推荐领域的呈现形式不尽相同。从数学形式上看,注意力机制只是将过去的向量加和换成了加权后加和,而且其训练难度上,也是多了一层注意力的权重,但其意义却是更符合人类实际的思考模式的。拿 AFM 来说,其 Attention Net 的数学形式如下:
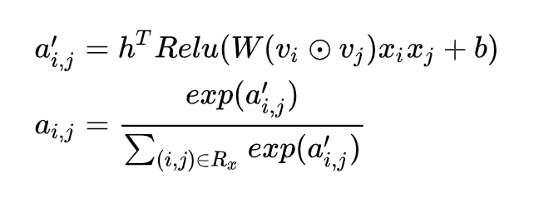
本质上就是一个单层神经网络 + softmax,最终输出的 ai,j 就是 FM 各交叉项的权重。这也是符合我们的直觉的:即任意两个二阶交叉项,其重要性也不应该是一样的。最终效果也证明了这点:引入了 Attention 机制的 AFM,效果大幅提升。
四、推荐系统的一些设计关键
聊完模型演化,再聊聊模型相关的设计与选型。推荐系统作为一个复杂系统,并不只是模型就够了。有关模型,还有很多设计关键点需要关注。
新建一个模型时,需要考虑模型的目标是什么?模型的目标一般由商业目标和应用场景决定。而模型目标又最终确定了损失函数和训练方法。
首先我们需要将大的商业目标拆解,同时考虑技术架构。比如将系统拆分成“召回”和“排序”两个阶段就是技术上典型的平衡“性能和业务”的方案。召回阶段考虑快速过滤掉大部分不相关商品,同时保留多样性。有时为了多样性,还会采取“多路召回”的方式。即通过不同的策略、规则分别召回一部分候选集,然后把候选集合并混合在一起供后续使用。召回阶段的特点决定了它往往采用简单的模型、规则、或 Embedding 技术,以此来保证召回“效率”。而 CTR、CVR 则是进一步对“排序”阶段目标的业务拆分。拿酒店推荐场景来说,用户必须先点进酒店详情页,才有可能进一步到下单页形成转化率。因此,CTR、CVR 就是我们模型优化的目标,而实现推荐的形式,就是通过列表页展现的顺序来影响用户的选择。这种排序推荐的方式,让我们的训练方法,不仅可以使用 pointwise 的训练方法,对单个酒店打分;还可以使用 pairwise 等 LTR 方法,对酒店的顺序进行建模训练。
完成了整体的模型拆解,就开始着眼到单个模型上来。模型的特征挖掘充分吗?是否需要多模态特征?像酒店推荐一般会包含“用户特征”、“酒店特征”、“上下文特征”等。每个特征的选取和处理都是经过大量的打磨和 A/B-Test 实验的结果。
如何解决冷启动问题?模型的初始化有时是在系统上线前,这时已经积累了一定量的数据,可以充分建模;但有时缺乏的却是输入的特征。如新建用户、新商品。这时有些策略可以帮助我们跨过这个阶段。如基于规则的推荐、或通过“主动学习”主动获取数据等。
推荐的实时性包含模型的实时性和特征的实时性。模型的更新频率和更新范围是影响模型实时性的关键。更新频率一般从一周到一天,甚至是在线学习,这些都需要数据收集和流处理框架的支持,同时结合好全量和增量更新。更新范围既可以全部,也可以是模型和 Embedding 向量分开更新。
五、模型的离线训练与在线部署
1、离线训练
在目前互联网数据规模越来越大的情况下,模型的训练场景从单机单卡发展到单机多卡,再到多机多卡,分布式训练逐渐成为一个逃不开的选项。目前主流的分布式训练框架包括 Spark MLlib、Parameter Server、Tensorflow 等。
从并行方式上看,可以分为数据并行和模型并行。数据并行又可以分为同步并行和异步并行。
Spark MLlib 是典型的同步数据并行方式。它通过广播的方式同步梯度到各个计算节点,然后每个节点都拉取一部分训练数据,在本地完成一轮梯度计算,再通过 treeAggregate 汇总各个梯度加和求平均,最后同步最新梯度到各节点完成一轮梯度更新。
可以看出这种并行训练方式虽然清晰,但训练过程却是低效的。每轮迭代先要广播所有参数,极其耗费带宽资源;另外,在生成汇总梯度时,都要等待所有节点完成,训练速度由最慢的节点决定。因此,Spark MLlib 并不适合深度学习时代,大规模神经网络的分布式训练。
因此,Parameter Server 应运而生,那么 Parameter Server 是怎么解决上述两个问题的呢?下图展示了 Ps 的整体架构:
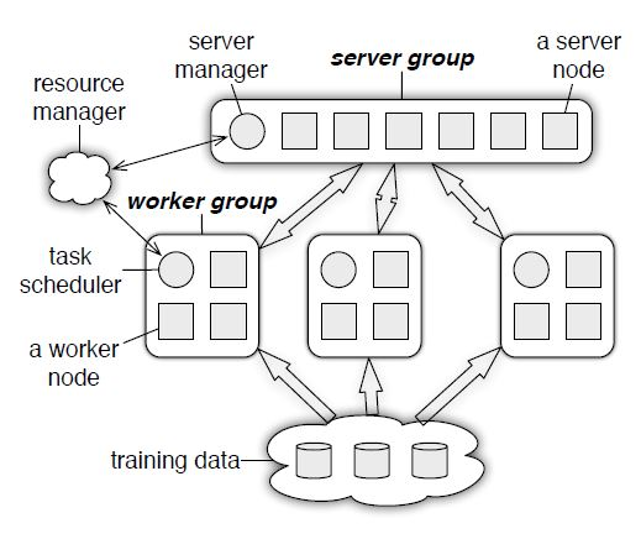
Ps 整体上由 Server Group 和 Worker Group 构成,Worker 负责拉取部分数据,计算局部梯度,并上报 Server;Server 负责维护汇总梯度,计算全局梯度,并更新 Worker。可以看到,Server Group 内多 Server 的结构,每个 Server 通过一致性 hash,维护一定范围内的参数,避免了单节点的带宽瓶颈,也保证了节点删扩容的灵活性。而在更新梯度时,不再采取“同步阻塞”的并行方式,而是采取了“异步并行”。即 Worker 在计算完局部梯度并上报更新后,不再等待其他计算节点,而是继续拉取数据,开始下一轮迭代。当然,速度上的提升,带来的是模型一致性的丧失,也就是收敛结果的不确定性。这就需要设计者根据实际模型情况做好平衡。另外,也可以采取“有界延迟”的方式,作为折衷方案。
Tensorflow 采用了多种并行策略。其由 OP 组成的计算关系图,类似于 Spark 的 DAG(有向无环图);有依赖关系的 OP 必须串行执行,无依赖关系的 OP,可以分配到多卡上并行执行。其分布式策略默认采取了类似 Ps 的数据并行的方式,不再赘述。Ring-All Reduce 作为另外一种并行策略,相对 Ps 可以达到更高的带宽利用率。
2、在线部署
模型的在线部署需要面临的则是另外一番完全不同的场景了。与离线训练最大的不同是对推理性能的极致追求,面临的问题和困难也有很多。
首先,在线部署有可能和离线使用的是不同的框架,甚至是不同的语言。那怎么把模型“提交”给在线推理模块,就有很多考量。PMML 协议在机器学习时代是几乎是模型交换的标准。PMML 文件中包含了模型的结构定义和模型参数,像 sklearn 等很多框架都支持直接将模型导出为 PMML 格式。而在部署端,如果编程语言是 Java,则使用 JPMML 则很容易将模型装载、还原。但到了深度学习时代,模型参数动辄上百万,再使用像 PMML 这种以 XML 为组织形式的协议就不合适了。
如果推理平台是自研,可以使用自定义导出模型参数的方式。模型参数本质上就是大量的 key-value 集合,导出后,可以以任意格式存储。同程的酒店推荐模型就是采用这种方式,离线训练端把模型参数以 key-value 的形式导出后,推送到共享的文件系统中;模型推理平台自动检查更新,构建模型并装载最新的参数,简单、高效而灵活。
ONNX(Open Neural Network Exchange,开放神经网络交换)格式,是由微软开源,一套新的用于表示深度学习模型的标准,近几年逐渐火热起来,并逐渐被 TensorFlow、PyTorch、Caffe2 等各大框架支持。它定义了可扩展的计算图模型,以及内置运算符和标准数据类型的定义;本质上是以 PB 格式为组织形式的文件,因此更加节省空间。
然后是线上部署框架的选择。
Tensorflow Serving 是一个谷歌开源的用于模型推理的高性能库,可同时提供 RESTful 和 gRPC 接口,用于线上模型推断。统一的离线框架和在线框架是这种方案的最大优点,只需将 Tensorflow 的模型导出为 PB 文件,然后即可导入 Tensorflow Serving 使用。与 TF 良好的兼容性大大简化了上线步骤;此外,它还提供了模型版本控制和热更新等功能。Tensorflow Serving 最大的硬伤在于其默认情况下的性能。Python 环境下程序运行本来的性能就不高,再加上特征预处理过程,如果再不针对硬件进行优化,那这种方式上线的模型推断接口,性能是堪忧的。必须针对性的进行代码和硬件优化。此外,如果训练环境不是 Tensorflow,那用 TF-Serving 做线上部署也是比较麻烦的。
自研框架当然也是个不错的选择。TE 的酒店推荐框架就是采用自研的方式。当然需要考虑的问题也不少,包括:
1、 与各种离线训练框架交换模型的格式;
2、 模型的加载与热更新及版本控制;
3、 如何解构各种模型,并进行高性能的推断,提供高吞吐量的对外接口;
4、 如何组织、复用大量的特征处理代码;
5、分布式模型装载、硬件优化等等。
总之自研框架的成本是比较高的,所以一般也只有大型互联网公司才会选择自研。但好处也是明显的,整个过程更加可控,不必再局限于各种开源框架的限制。百度的 Paddle、腾讯的 TNN 都是业内比较有名的自研框架。
近几年,一系列专注于硬件优化的模型推理框架也逐渐崛起。Nvidia 推出的 TensorRT 便是其中的典型。根据其官方文档介绍,TensorRT 可以针对 GPU 模式,达到 10X 以上的加速。那它是怎么做加速的呢?主要有两种方式:一种是通用类的模型加速,这个我们后面一起讨论;另一种是针对硬件指令级的加速。比如图像识别中,经常使用的一个卷积层 + 一个偏置层 + Relu 激活,本来是三条 cuda 指令,但在特定的显卡下,TensorRT 可以将其合并成 CBR 层,一条 cuda 指令,从而实现网络结构简化和推理加速。
最后,我们来说说通用的模型加速技术,包括:数学公式优化、模型剪枝、模型量化、权值共享和知识蒸馏。
数学公式优化:这类最好理解,就是对模型原有计算形式,做数学公式上的推导变形,使其更符合 CPU 的计算模式。比如 FM 的交叉项计算公式:
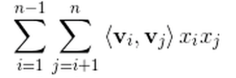
乍一看其计算复杂度为
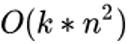
但可以进行如下变换:
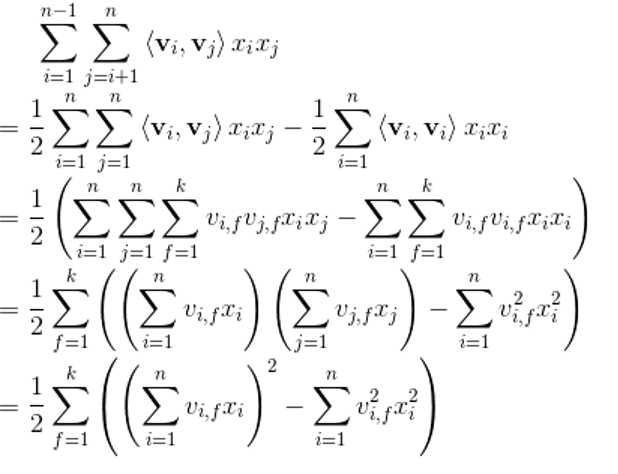
复杂度就变成了
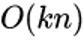
其主要就是利用公式:
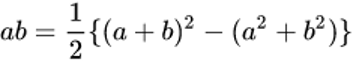
实现化简。
另一个例子是在卷积运算中,Winograd 算法大量被使用。它来自于 CVPR 2016 的一篇 paper:
模型剪枝:在 2016 ICLR 的 best paper
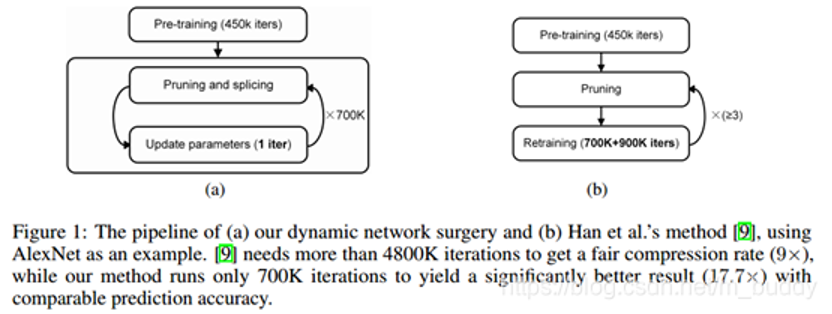
也就是增加了“修补”操作,来恢复被误删掉的重要连接。从最终效果看,模型剪枝和精度下降都得到了有效控制。
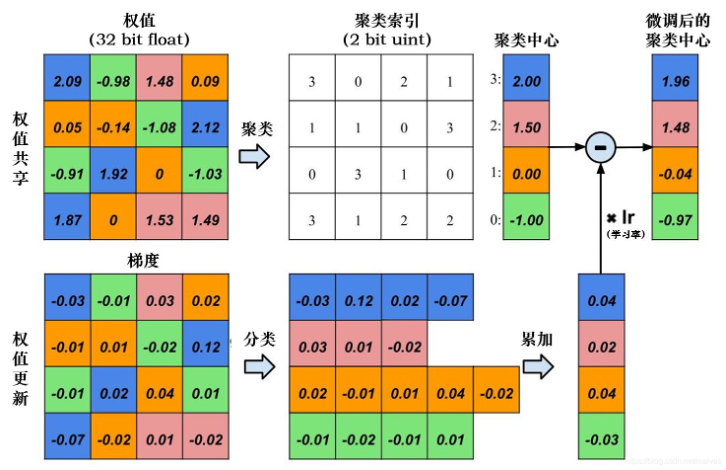
权值共享:卷积网络中的卷积核最早引用了“权值共享”和“局部感受野”这俩概念。而如果把这种思想引入到模型压缩领域中是否可行呢?Han 在其论文中就验证了这一方案:使用 k-means 方法对模型的权值进行聚类,然后使用中心点代替原有权值,以后梯度更新时,就以类别为粒度进行更新。下图描述了这一方法的过程。
模型量化:模型量化是近两年较为火热的一种模型压缩方式。一般情况下,神经网络中的数据是以精度为 32 位的浮点型(FLOAT32)进行表示的,存储和计算的开销都很大。模型量化则是研究以更低的精度表示模型,同时控制模型效果损失。目前半精度、INT8、二值化都是流行的方式。量化时,也有仅量化权值和特征、权值都量化两种方案。
通常来说,INT8 量化用的最多,Tensorflow、TensorRT 等很多框架也都内置支持。原理其实并不复杂,关键是如何将 Float32 的值域映射到 INT8 的区间(-127~127),见下图:
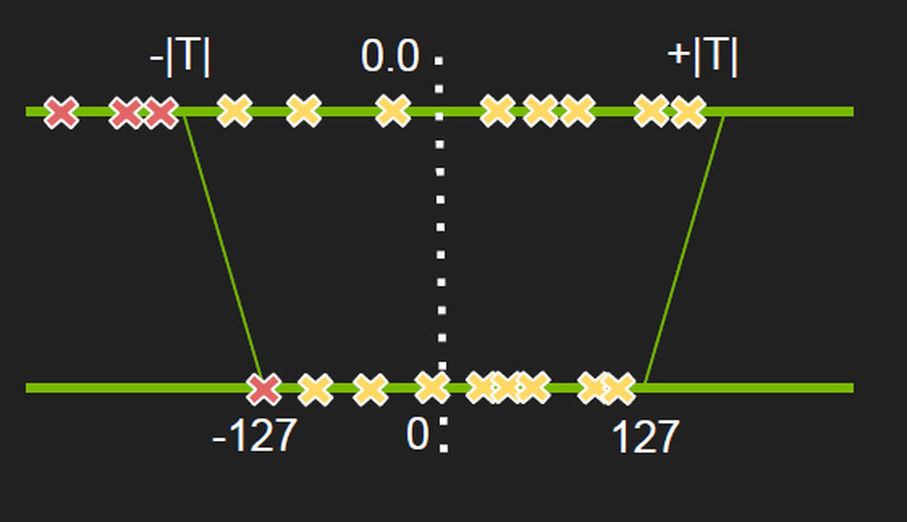
但浮点型的范围是很大的,个别的离群点可能会导致 INT8 映射时,将大部分数据集中映射在几个值,从而腾出更大的空间给离群点,这就得不偿失了。所以需要控制 FLOAT32 映射的边界值 T,也就是映射范围,舍弃掉部分离群点。那如何衡量舍弃哪些以及映射的好坏呢?TensorRT 使用的是 KL 散度,也就是相对熵。相对熵是用来衡量两个分布的差异的,因此原问题就变成了如何把 FLOAT32 映射到 INT8 的区域,同时使两个分布的 KL 散度最小化。
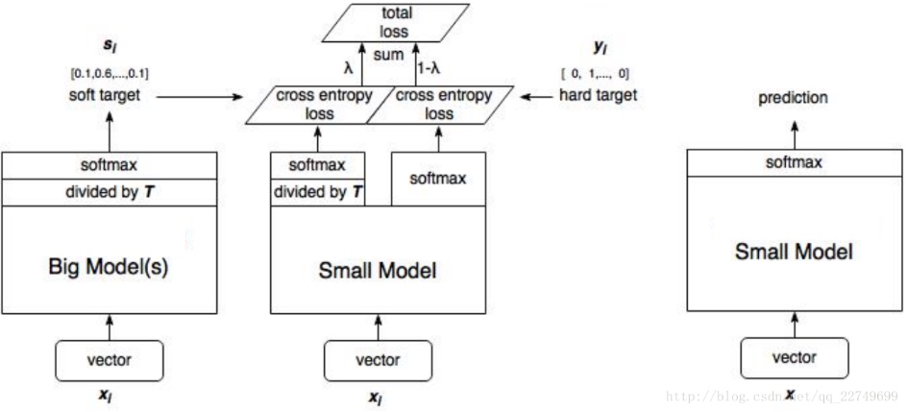
知识蒸馏:知识蒸馏最早要追述到 Hinton 的这篇论文《Distilling the Knowledge in a Neural Network》。知识蒸馏是要用一个训练好的复杂度较高的 Teacher 网络,去协助训练一个复杂度低的 Student 网络。一个模型容量更大的 Teacher 网络,虽然其表达能力很强,但同时也意味着它可能会存在很多冗余,我们要的是模型泛化能力本身,而非模型的参数结构。所以就需要把 Teacher 模型的预测能力通过“蒸馏”的方式,迁移到一个轻量简化的 Student 网络。
这其中的关键是软化后的 Softmax。拿 MINST 手写数字识别来说,我们知道输入到模型中的目标是经过 One-hot 的,也就是 0 1 0 0 0 0...这种形式。目的是告诉模型哪个结果是对的,我们希望它概率最大化,从而实现训练;而其实这种方式丢掉了很多信息,比如数字 2 和 3 很像,我们怎么把这种信息告诉模型,从而让它在训练过程中少走弯路呢?答案就是 Teacher 网络。作为一个“过来人”,Teacher 网络通过推断,当然可以知道 2 和 3 很相似这种信息,然后把结果“软化”(使 One-hot 结果更加平滑),也一起输入到 Student 网络的训练过程中。这样,Student 网络就可以更快的、以更小更简洁的结构学到老师的精髓。下图就描述了这一过程:
不知不觉中已经写了这么多,这才发现推荐领域涉及到的知识点是那么多,而很多内容还没有展开讲。有些是书中提到,有些是自己实际工作中的总结,希望对大家有所帮助。路漫漫其修远兮,吾将上下而求索。
作者介绍:
房磊,2014 年加入同程艺龙,任架构师,技术委员会委员;先后负责 MAPI 手机网关平台建设、同程艺龙开放平台建设、数据平台建设等。擅分布式系统架构设计和 AI 系统设计。20 年参加 Top100 案例北京峰会,获人工智能专场最佳讲师。欢迎关注我的个人微信公众号:architectAI,进一步交流、私信我~。




