
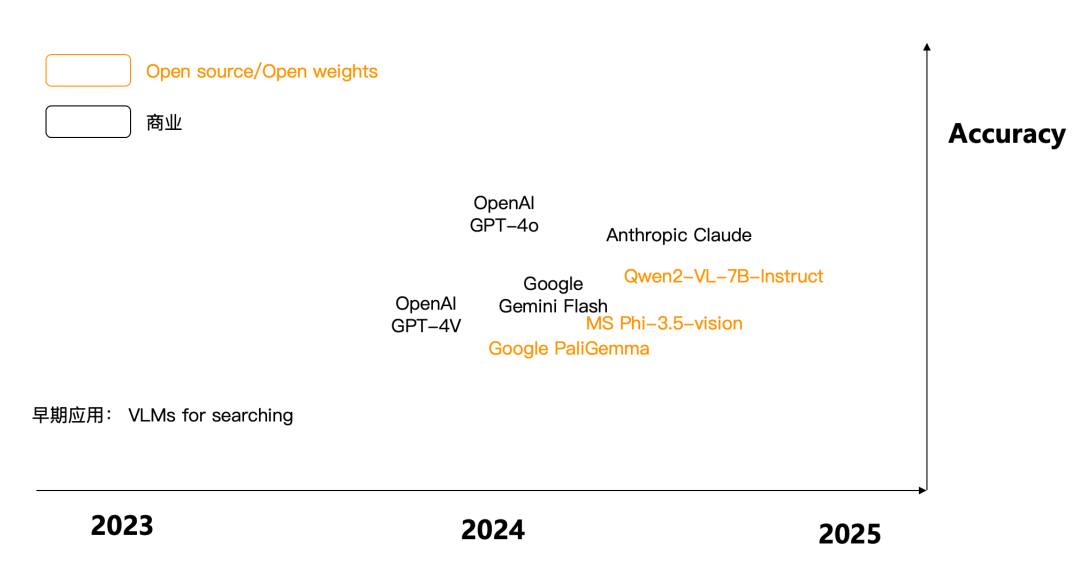
2024 年可以算得上是多模态大模型取得井喷的一年,5 月发布的 GPT-4o,让多模态大模型进一步走进了我们的视野,如果说在 2023 年,多模态的应用还停留在传统的简单图像搜索,到 2024 年,则真正开始了对多模态数据的理解。下图是 24 年涌现的多模态大模型代表,既有商业,也有开源。可以看到,从对图像的理解角度来看,2024 年已经取得了长足进步。
随之而来的,就是多模态 RAG,是否也会开始落地并产生价值?我们先来看看多模态 RAG 的都有哪些使用场景。所谓多模态 RAG 的概念并不稀罕 ,在 2023 年 RAG 概念刚火热起来不久,就有了多模态 RAG 的场景描述,例如针对个人相册,企业宣传素材的搜索需求,然而,这种搜索需求更多是把存在很久的向量搜索的使用场景如图像搜索、以图搜图等安插到了多模态 RAG 之上,并没有真正从业务角度来逐步挖掘多模态 RAG 的场景价值。随着 RAG 技术在 2024 年快速发展,更多的企业,已经把 RAG 看成是大模型在 B 端应用的标准配置。来自于企业内部的文档问答,已经解锁出大量使用需求和场景。在这些文档中,有相当一部分包含各类复杂的图表内容,它们本质上就是各种多模态数据,如何对这些数据进行有效问答,成了挖掘企业内部数据金矿的刚性需求来源之一。
针对这类数据,一种解决方案是采用视觉模型,利用广义上的 OCR 技术,把这些多模态文档的布局首先识别出来,再根据不同语义区块,调用相应的模型来做处理,如下图所示。
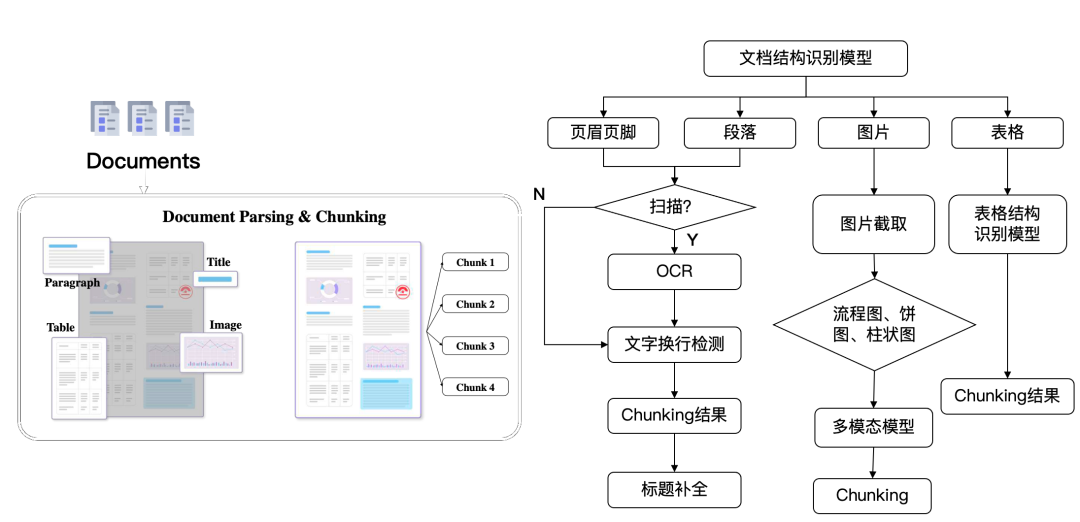
这个流程中,得到的图片和表格,都属于典型的多模态数据,因此,采用相应的模型,将它们转成文本数据,就解决了对多模态数据的理解问题。从原理上来说,这样的技术也分为 2 代:
第一代是采用各类视觉模型,针对不同类型的图表数据分别进行训练,将它们转化为文字。例如针对表格处理的,有表格识别模型,针对流程图,饼图柱状图等企业图表,也需要相应的模型来处理。这些视觉模型,本质上是个分类模型。
第二代则采用生成式模型,不同于流行的 LLM 采用的 Decoder Only 架构,基于 Transformer 的多模态生成式模型,通常采用 Encoder-Decoder 架构,Encoder 的输入端是各种图表,Decoder 的输出就是各类文本。
依托于这种广义的 OCR 技术,可以把一个多模态 RAG 系统变成一个标准的 RAG 系统。在我们的开源和商业版的 RAGFlow 中,分别基于这两类技术提供了相应的实现。
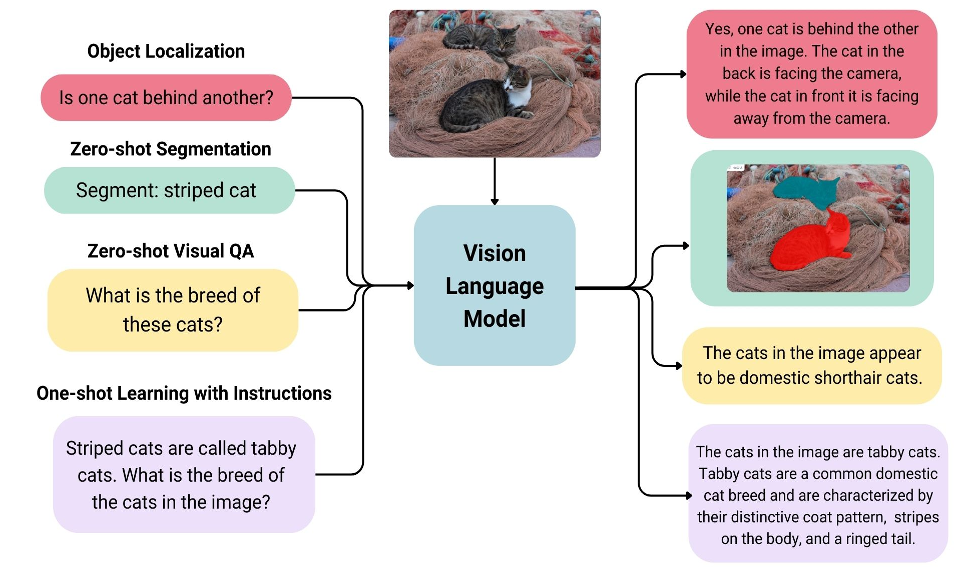
另一种解决方案,则直接依托于多模态模型本身,简称 VLM(Vision Language Model)。输入文字和图像,输出得到基于图像和文字内容理解得到的答案文字。
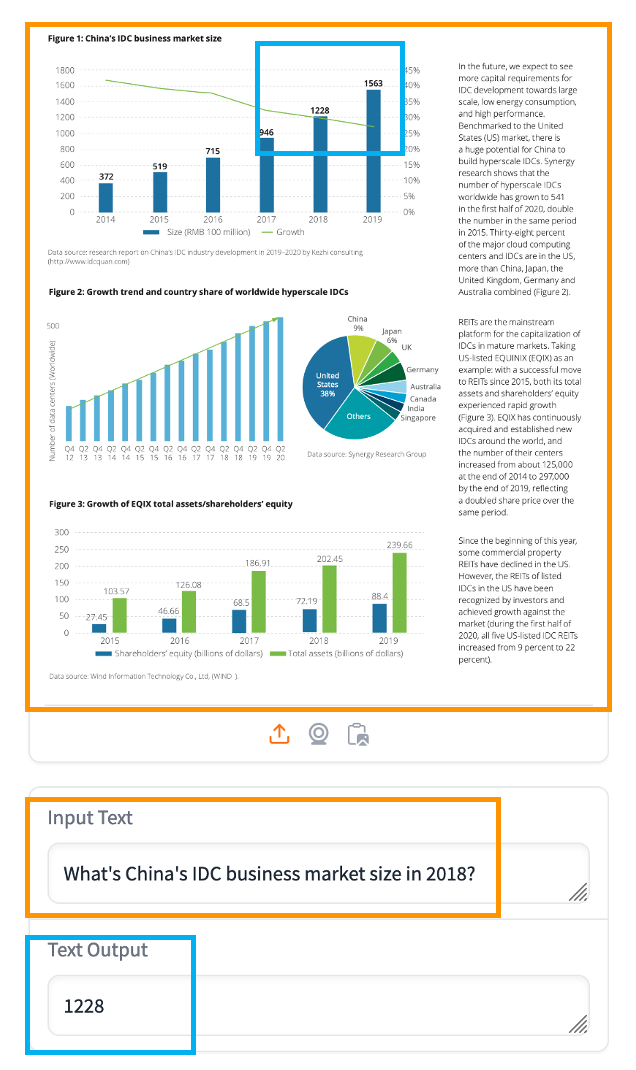
如前文所提到,VLM 在 2024 年取得了显著进展,它们已经大大超越了过去图像搜索这种简单的场景。我们先以 Google 在 7 月开源的 PaliGemma 为例,看看对一个复杂的多模态文档理解的效果【参考资料 1】。上传一张包含柱状图、饼图以及各类文本的复杂 PDF 截图,然后针对图表进行提问,可以看到,PaliGemma 给出了准确的回答。
而近期阿里开源的 Qwen2-VL-7B【参考资料 2】,也在视觉图像理解上达到了更好的效果。如何将这些 VLM 应用于针对大量企业内部 PDF 文档的多模态 RAG,同样是今年 7 月公开的 ColPali【参考资料 3】,则是一个堪称里程碑的工作。ColPali,全称叫 Contextualized Late Interaction over PaliGemma,是一个基于 PaliGemma 的延迟交互模型。PaliGemma 是一个结合了视觉和语言模型的混合模型,它使用 SigLIP 视觉编码器生成的图像块 (Image Patch) Embedding,并将这些 Embedding 输入到 Gemma 文本语言模型中,以获得上下文化的语言模型输出 Embedding。
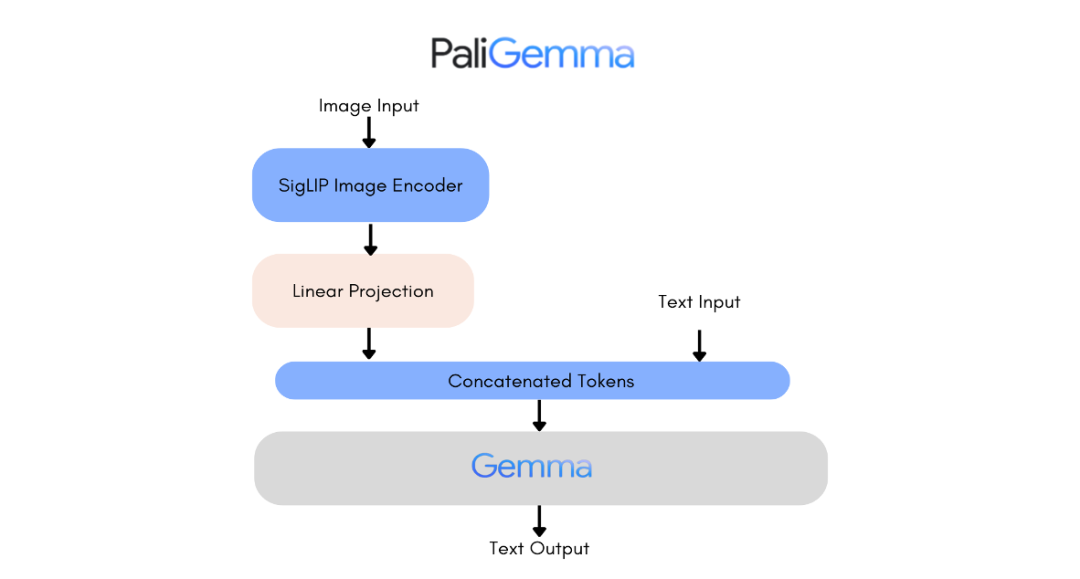
而 ColPali 则在 PaliGemma 基础上添加了一个 Col Adaptor,它负责将 PaliGemma 的 Embedding 输出映射到一个更低维度(128 维)的向量空间,并采用延迟交互模型来计算文本和文档之间的相似度。所谓 ColPali 的"Col",跟最知名的用于文本排序的延迟交互模型 ColBERT,是一个含义,它是用来在 RAG 系统中解决文档排序的一种标准方法的总称。也就是说,我们可以在任何模型基础之上来新增一个 Col Adaptor,同时辅之以训练的正负样本对数据,就可以得到各种 ColXX 模型,它们都是采用延迟交互模型,可以用来捕获查询和文档之间的上下文相似度。
在 RAG 常用的排序模型中,主要有 3 类架构:
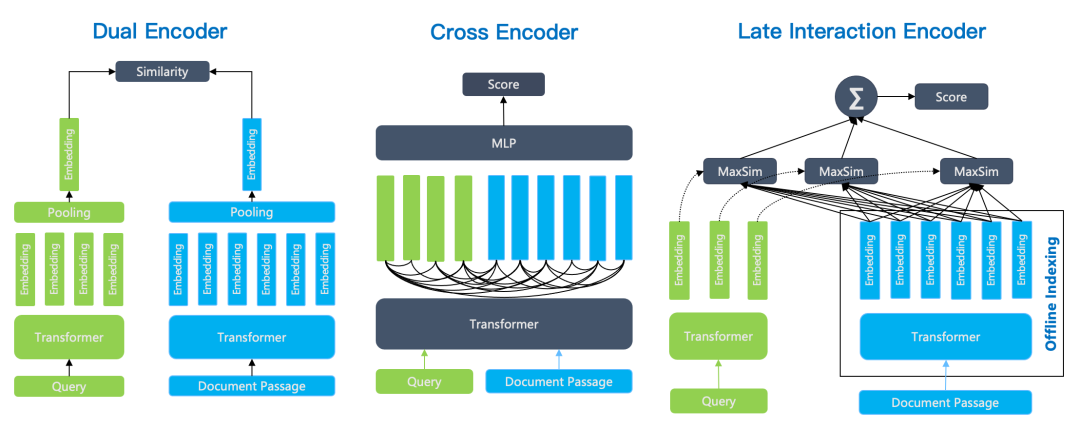
双编码器(Dual Encoder)。以 BERT 模型为例,它针对查询和文档分别编码,最后再经过一个 Pooling 层,使得输出仅包含一个向量。在排序阶段,只需要计算两个向量相似度即可。由于双编码器针对查询和文档分别编码,因此无法捕获查询和文档的 Token 之间的复杂交互关系,在语义上会有很多损耗。
交叉编码器(Cross Encoder)。Cross-Encoder 使用单编码器模型来同时编码查询和文档,它能够捕捉查询和文档之间的复杂交互关系,因此能够提供更精准的搜索排序结果。Cross-Encoder 并不输出查询和文档的 Token 所对应的向量,而是再添加一个分类器直接输出查询和文档的相似度得分。它的缺点在于,由于需要在查询时对每个文档和查询共同编码,这使得排序的速度非常慢,因此 Cross-Encoder 只能用于最终结果的重排序。例如针对初筛结果的 Top 10 做重排序,仍然需要耗时秒级才可以完成。
延迟交互编码器(Late Interaction Encoder)。以 ColBERT 为例,相比于交叉编码器,ColBERT 仍采用双编码器策略,将查询和文档分别采用独立的编码器编码,因此查询的 Token 和文档的 Token 在编码时互不影响,这种分离使得文档编码可以离线处理,查询时仅针对 Query 编码,因此处理的速度大大高于交叉编码器,这样带来的好处就是延迟交互编码,可以放到数据库内部执行,不仅可以大大降低成本,更重要在于它可以针对更多的文档排序(例如 Top 100 甚至 Top 1000),从而大大提升最终的查询精度;相比于双编码器,ColBERT 输出的是多向量而非单向量,这是从 Transformer 的最后输出层直接获得的,而双编码器则通过一个 Pooling 层把多个向量转成一个向量输出,因此丢失了部分语义。
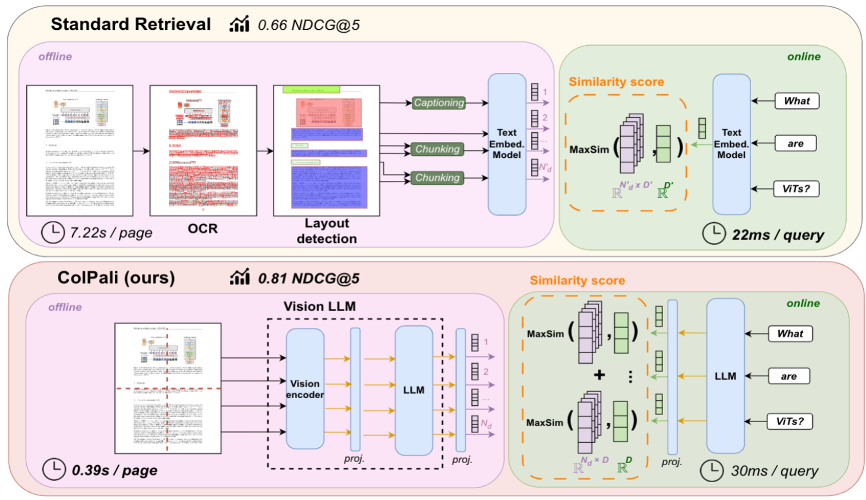
延迟交互编码器,是面向未来的 RAG 排序模型,它既有交叉编码器的排序质量,又具备较高的性能,解决了 RAG 检索过程中语义损耗的问题。正因为此,ColPali 算是延迟交互编码器在多模态 RAG 检索的应用,它的出现,对于提升多模态 RAG 的检索精度,具有显著的价值。下图是 ColPali 在文章中对比采用传统视觉模型的广义 OCR 实现的多模态 RAG,可以看到在查询精度上,领先优势很大。甚至在整体的数据写入速度上,也大大领先。
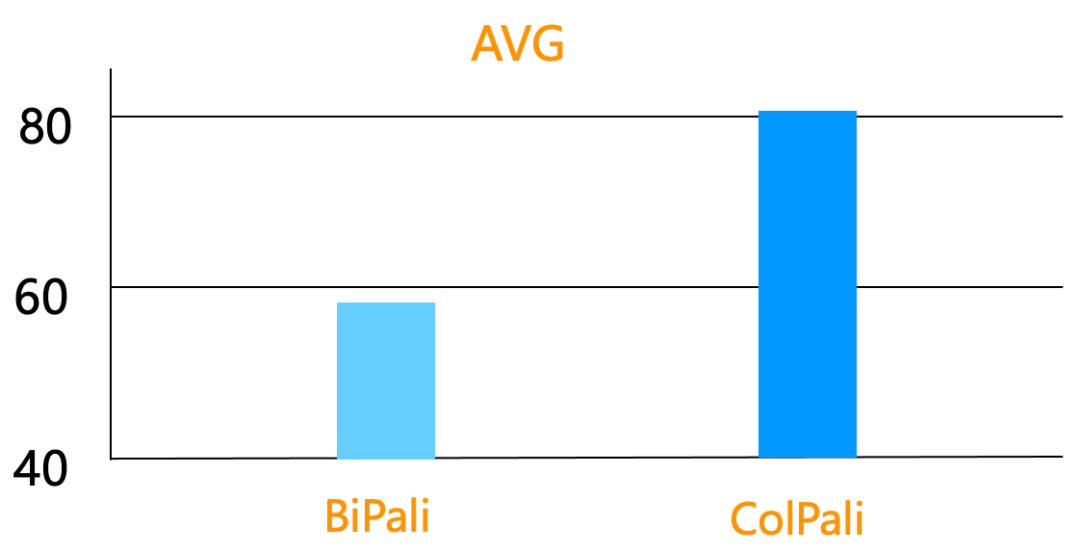
下图是 ColPali,对比不采用延迟交互模型的 BiPali(就是采用双编码器的 PaliGemma,对查询和文档分别用 PaliGemma 编码),在查询精度上的领先优势:平均 nDCG 从 50 多到 80 多,这在产品上几乎就是可用和不可用之间的差异。
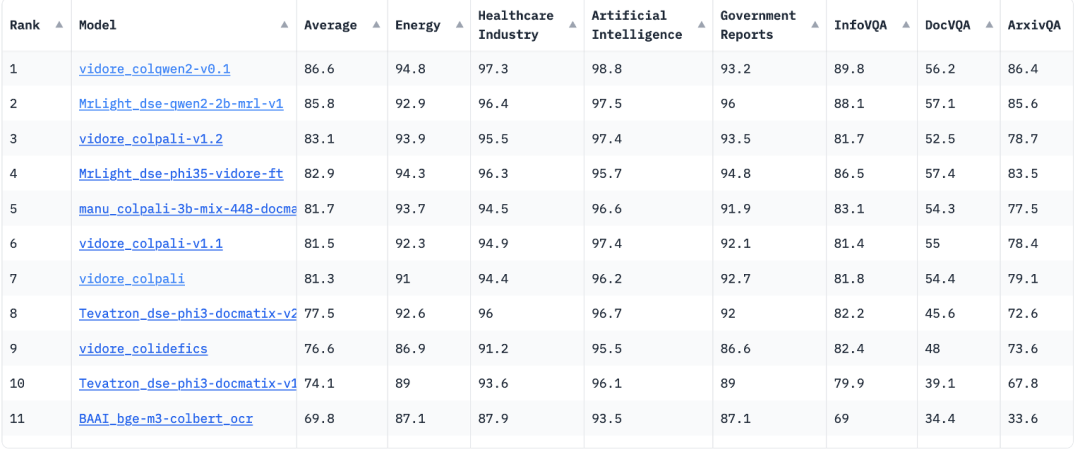
随着 ColPali 的出现,更多的将延迟交互模型用于多模态 RAG 检索的模型也出现了,例如将 Col Adaptor 用于 Qwen2-VL-2B 的 ColQwen2,在 ViDoRe Benchmark 榜单上,近期已经跑到了第一名,它的平均 nDCG 指标,比 ColPali 还领先了 5 个百分点。ViDoRe,全称是 Visual Document Retrieval Benchmark,类似适用于标准 RAG 的 MTEB Benchmark,ViDoRe 可看作是多模态 RAG 的 MTEB。下图是 ViDoRe 的典型评测样本:

并且可以看到,在 ViDoRe Benchmark 上,排名前列的模型,全都是延迟交互模型:
那么如何将 ColPali,应用到企业级的多模态文档知识库系统中呢?我们先来看 ColPali 模型,它会把每张图片,具体来说,就是 PDF 的某一页,看作是 32*32=1024 个 Image Patches,每个 Patch 都会生成 128 维向量。因此,一页图片,就可以用这 1024 个向量来表示。在查询的时候,查询的每个 Token,也都会生成一个 128 维向量,根据 ColPali 模型,查询和一页图片的相似度,是查询每个 Token 的每个向量,跟所有 Patch 的向量之间内积之和的叠加,这就是 MaxSim。因此可以看到,我们需要这样的基础组件,来完成基于 ColPali 搜索的产品化:
需要有 Tensor 类型,就是多向量,来表示一页。
需要有效的支撑 MaxSim 算法。MaxSim 的计算并不是难事,但由于 Tensor 类型的引入,它带来 2 个问题:其一是 MaxSim 的查询复杂度较高;其二是 Tensor 的空间复杂度很高。一页 PDF 的 Tensor 需要 1024*128 = 128KB,对于大量的 PDF 来说,这是很高的空间开销。
在实际使用中,我们发现,单纯采用 ColPali,确实可以解读图表,但对于一些文本内容,仍然无法有效召回。因此,标准 RAG 所必备的能力:全文搜索和多路召回,仍然不可或缺。
在我们的开源 AI 原生数据库 Infinity 中,就已经提供了以上支持,针对第二点,主要优化在于:
我们首先试验了 Tensor Index 的必要性。在实现了 SOTA 的 Tensor Index 后,我们在文本排序上做了对比,发现 Tensor 类型,MaxSim 计算仅放在 Reranker 即可。下图是在一个基于文本的排序评测上,分别对比了采用 Tensor Index,普通搜索 +Tensor Reranker,以及基于 Tensor 的暴搜,可以看到,基于 Tensor Reranker 的结果,甚至高于采用 Tensor Index。
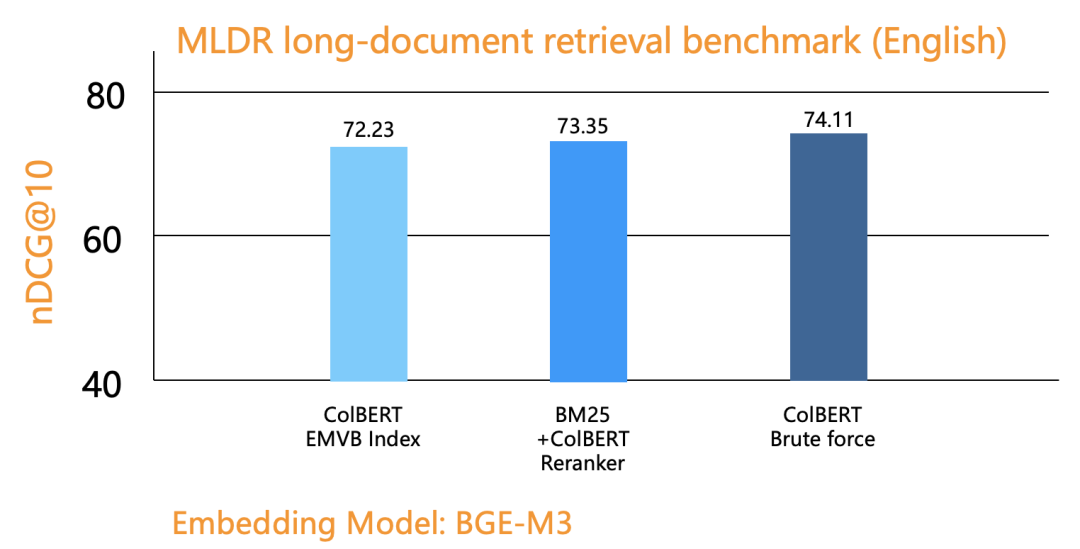
基于以上结论,采用 Tensor Reranker 即可达到效果,而 Tensor Reranker 可以采用更多的优化空间,例如采用二值量化,也就是把向量的每个维度的浮点数,用一个 bit 来表示,这样存储空间可以降低为原来的 1/32,同时计算复杂度也大大降低。
基于以上结论,采用 Tensor Reranker 来实现 MaxSim,那我们在前边的粗筛,同样离不开向量搜索。只是不同之处在于,我们需要这种向量搜索,也具备多向量的能力,意思是,向量搜索是以 Patch Embedding 为单元,但我们期望返回的结果,是以 PDF Page 为单元。

因此,采用 Infinity 数据库,将可以很好的支持多模态 RAG。
以上我们提到了 2 种技术路线,一个是基于广义 OCR,另一个是基于 VLM,分别用于实现多模态 RAG。那么这两种技术路线,哪种更有前景呢?在 ColPali 的论文中,已经给出了针对前者的比较,只是这种比较,主要是针对采用简易的 OCR 技术。在【参考资料 4】中,也针对这两种方法进行了对比,结论如下图所示:
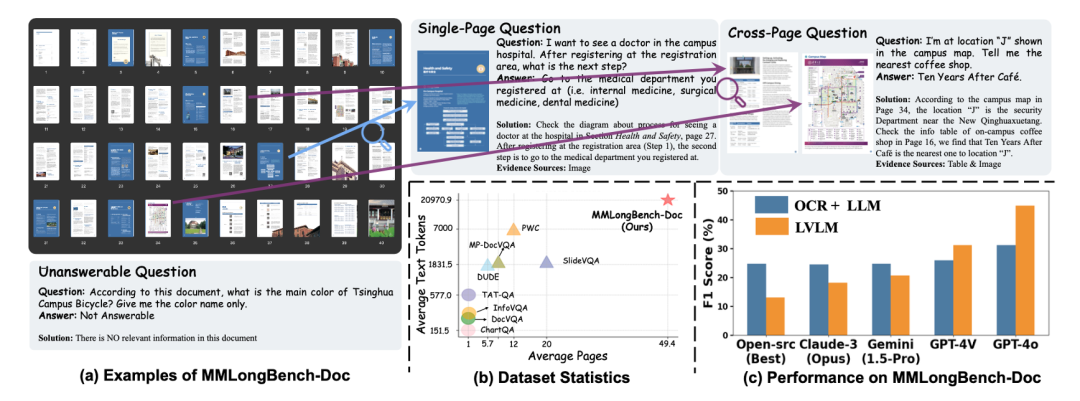
看起来似乎采用 ColPali 这样的延迟交互模型,已经具备足够的领先优势。然而,在前文已经提到,即使是广义的 OCR,也已经演进到了下一代基于 Transformer 的生成式模型架构,这在本质上跟 VLM 没有区别,所不同的是,前者直接输出文字,后者则输出 Embedding,而对于网络结构来说,都是 Encoder-Decoder 架构。面对企业级的多样化需求,在查全和查准都要兼顾的前提下,我们很难说哪种一定会占据优势,因此,最佳的选择是,两者都要有:
在文字更容易表达,或者精确处理更加重要的场景,例如表格,我们可以采用更加准确的图像直接生成文字的做法,把整个表格精准的还原,然后让大模型准确回答问题。
在文字表达不容易,如其他图表类场景,我们交给 VLM 来处理,这样效率更高。
多模态 RAG 系统,需要考虑各种情况,需要有个统一的任务管理模块,来针对用户数据的不同类型,分别调用相应的模块来进行处理。
随着 Encoder-Decoder 架构在工程上的渐趋成熟,Image Patch 的语义表达更加精细,多模态模型已经不再是未来,而是当下,以它为基础的多模态 RAG,也早已摆脱了图片搜索等上一代 AI,它们已经或者即将解锁企业内部的大量非结构化文档数据的深度理解,这将大大扩充 RAG 的使用场景,也大大增加大模型在企业端的应用价值。作为同时开发端到端 RAG 产品和下一代 RAG 配套数据库的我们,也在密切跟进相关领域的发展,不论是产品侧,还是模型以及 Infra 侧。欢迎大家关注我们的端到端开源 RAG 产品 RAGFlow(https://github.com/infiniflow/ragflow),也欢迎关注我们面向未来 RAG 需求的开源数据库产品 Infinity(https://github.com/infiniflow/infinity)
参考资料
1. https://huggingface.co/spaces/big-vision/paligemma-hf
2. https://huggingface.co/spaces/GanymedeNil/Qwen2-VL-7B
3. ColPali: Efficient Document Retrieval with Vision Language Models. https://arxiv.org/abs/2407.01449
4. MMLongBench-Doc: Benchmarking Long-context Document Understanding with Visualizations. https://arxiv.org/abs/2407.01523
今日好文推荐
字节澄清大模型遭攻击,实习生嫁祸背刺同事?IBM老员工被无端解雇后举报董事长;年薪40万美元因滥用25美元餐补被裁!| Q资讯
国产编程语言MoonBit发布原生后端,比Java快15倍,拥抱 RISC-V




