

人工智能是当下金融产业转型的重要助力,本文主要介绍 51 信用卡管家在这方面如何搭建模型体系,如何发掘数据价值,如何成立自己私有的扫码平台或个性化体系。
51 信用卡管家最开始以账单管理业务为主,国内比较早的用于管理信用卡账单的 APP,目前公司的业务领域涉及负债管理、金融、技术服务等。
目前 51 信用卡管家在运营增长面临的问题: “推荐”或“搜索”主要应用在电商行业里面,电商里面推荐系统重召回,包括“粗排”和“精排”,在金融领域产品少,为何要做复杂的召回呢?其实,金融里面我们重“排序”,举例说明,比如今天客户来 51 的目的可能是为了办卡,结果没有选到合适的卡,那么这个时候应该怎么办呢?由于金融客户价值非常大,我们不想失去任何机会,因此就给客户推荐其它业务。
下面介绍一下“推荐”在我们金融领域会遇到什么样的问题:
1. 51 的运营增长痛点
金融领域 APP 属于偏向投资和工具类的,跟电商 APP 相比属于低频率的,客户打开的频率比较低,所以我们的运营能力非常关键,在运营过程中我们遇到哪些困难呢?
(1) 随着业务不断扩张,如何有效识别用户差异化需求?由于我们的流量平台主要来自于广告投放,不同广告商带来用户的体制、分类等不同,办卡类、理财等带来的客户各有差异。
(2) 新用户成本高,怎样第一时间做精准分发?金融类用户相比电商类来说成本高很多,由于价值高所以要更加珍惜。
(3) Push 等渠道转化率低,如何提升?由于客户打开频率低的特点,Push 是重要的手段。
2. 技术上的难点
(1) 金融用户的行为较少,怎样有效挖掘用户标签?标签的挖掘对于我们来说是重中之重。在电商 APP 中,如果用户家里有小孩,母婴类产品会点击比较多,会产生大量的数据,电商根据这些数据可简单准确分析用户的需求。对于金融类用户来说,行为数据也非常重要,但比较少,这就要求我们挖掘其它类数据来补充。
(2) 如何构建一套实时预测用户偏好并线上应用的模型架构?在电商中实时推荐系统、在线测试、在线规则引擎比较多,成熟案例也多,而在金融里面相关资料和成熟案例相对较少,金融类用户偏好有一定的深度,重要的一点在于如何在第一时间捕捉到用户金融类的偏好,因此构建一套成熟的体系架构是非常困难的。
(3) 如何体系化帮助渠道有效增长?在广告投放时,如果反向的用户价值观念比较大,比如 ROI 特别高的情况下,那么渠道投放信心也是倍增的,对于广告平台的也非常有价值。渠道有效增长对站内和站外影响都比较大。

下面介绍一下系统的架构平台相关内容,金融业务如何基于账单和 APP 构建用户标签?金融业务中数据来源第一个是账单,数据量较大,用户的很多账单需要管理和分析,提供很多定制化服务,比如推线下的很多活动等,这个对用户来说意义比较大,这里的账单主要是消费类的数据。第二类数据是 APP 数据,经过很多分析表明这类数据重要性比较高,在后面将结合具体算法介绍基于 APP 构建用户标签。
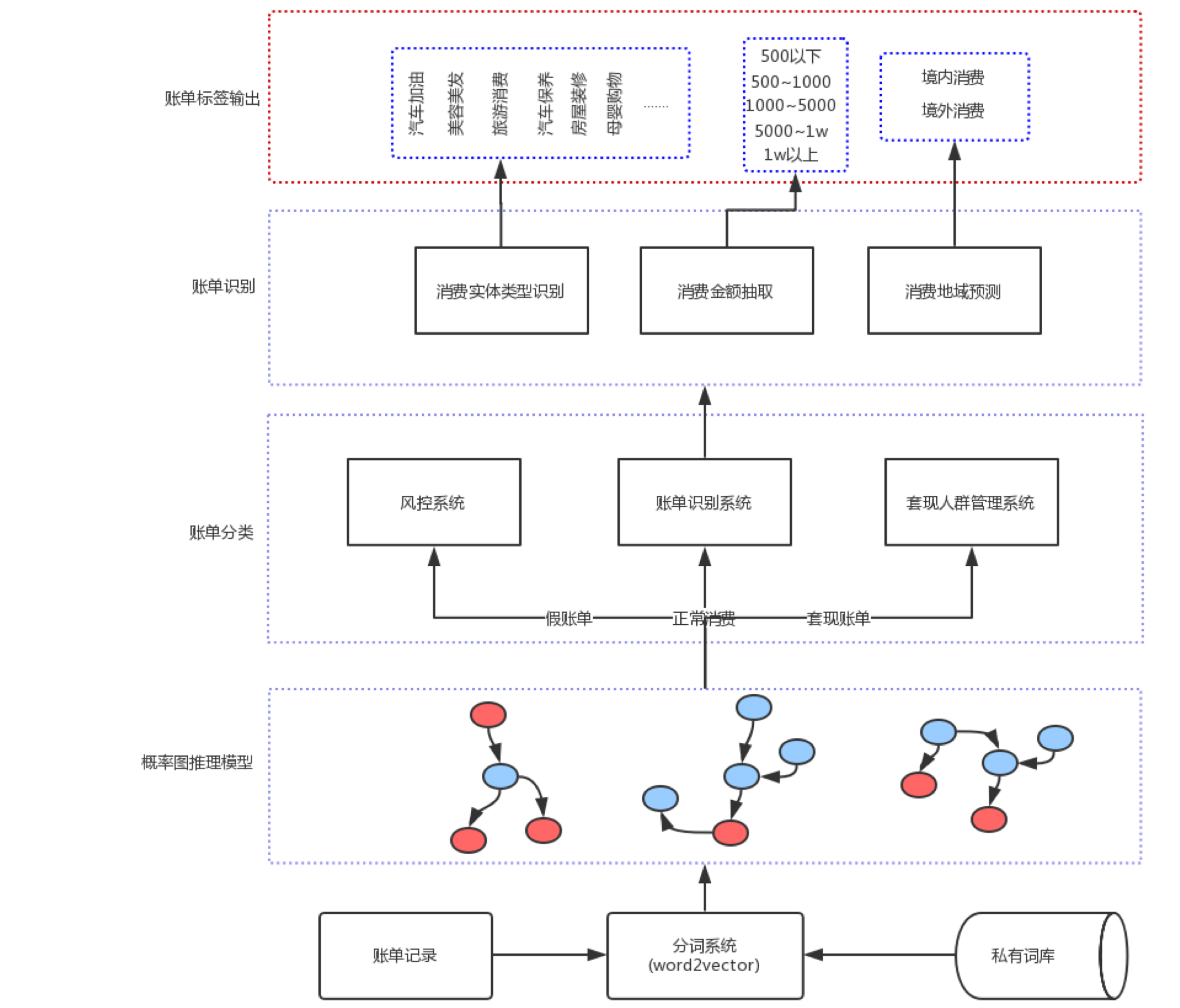
举例说明基于账单构建用户标签。假如今天在杨国福麻辣烫消费了一笔账单,账单里面可能会形成“支付宝消费—杨国福麻辣烫—**金额”等没有语法结构的短文本,我们需要挖掘有用信息,经过很长时间的探索,我们发现这些短文本基本都有一个核心短语,将这些核心短语分类列出来对我们帮助非常大。下图是我们设计的分词系统,大概有三层体系,第一个是主向量化,有字级别向量以及词级别向量化,词向量化也需要很多算法;再往上一层是合并规则,如果名词之间相关性比较大时合并起来就是短语,此外我们也有自有词库;再往下一层就是概率图推理模型,简单介绍一下这层的作用,对于账单来说有几大问题,假如有一笔套现账单,这种账单在这情况下意义不大,但对于判断风险评估来说比较有用,比如判断用户偏好,这样的账单记录会影响系统分词效果。再比如有一笔信贷业务的账单,我们要判断用户是否具有还款或负债能力,此时具有欺诈性质的假账单影响比较大,需要筛选出来。总体原则是避免有问题账单进入系统而影响结果。
以“支付宝消费—杨国福麻辣烫—“金额”为例继续介绍,如下图所示,先将账单记录分为两大类,关键词还是实体名,将“杨国福麻辣烫”提取出来,其它部分作为 other 部分。像“支付宝消费”这样的词在分词系统里面 other 部分一步步分离,最终进入系统概率图部分。概率图有什么作用呢?将训练过程历史记录中出现词的贡献概率或联合概率识别出来,即图中边与边之间的关系。假如进入这个概率图后形成四个短语,在四个图中各出现一次,其他图都没有出现的话,这种意味着这四个短语在图之间的关系在历史训练中比较弱,独立性比较强,那么我们看一下这四个图各处在什么位置,与库里面其他词概率关系是怎么样的,然后构建模型。此外,我们也可以通过人工系统进行审核。下图右侧账单算法分词案例,首先将账单所有短语列出来,大的地区通过将中国的地理位置排列识别,小的地方通过其他解决办法也可识别。还有一个问题,商家都有明显的酒店短语,为何还要做呢?大多数账单能够识别出有多少是住宿类别,但有些时候识别不出怎么办呢,比如“香米拉客家商务酒店”,那么需要通过其它方式提供有效信息再进行分类。以上内容是基于账单体系架构构建用户标签的过程。
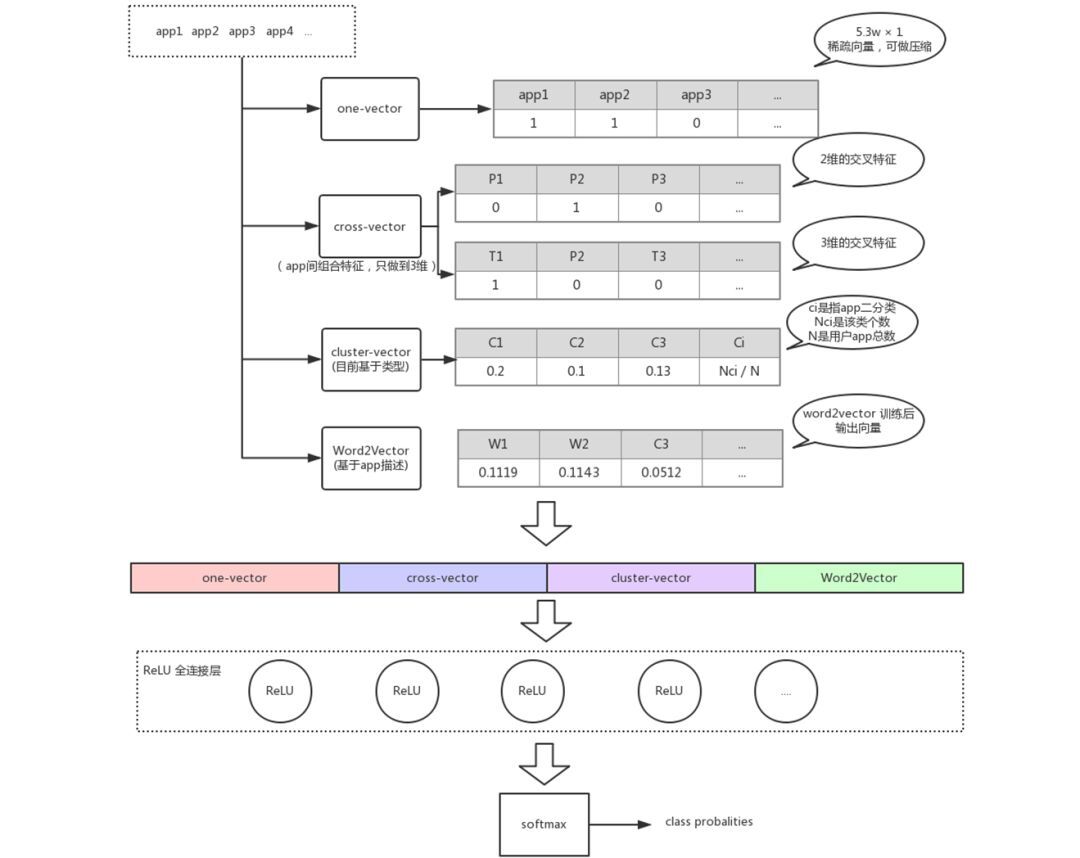
基于 APP 构建用户标签。我们在实际中,不只把 APP 词用一次,甚至把描述词也用到了。单点类 APP 通过 one-vector 一维方式提取,通过矩阵或者一维向量表示,第 2 个是交叉类 cross-vector 二维或三维方式。先简单介绍一下 cross-vector,比如我们在制作 APP 时会给它一个类别,很多 APP 不仅有一级 name 还有 double 级 name,我们有一个二次 name 的预测过程,比如 51 信用管家被很多人作为简单的管理信用类工具,事实上还有理财与借贷类,如果只注意到某一个类别,容易忽略 APP 的价值挖掘,我们可以将 APP 里面两个类进行简单加和等组合,也可以以人工方式进行组合,3 维的交叉则是在 2 维基础上扩充类。此外,APP 里面描述要不要采用呢?我们认为一定要用,因为每个 APP 开发完后在上传的时候一定要有标识类代表性的转账信息,这些描述信息非常有用。这样就能得到足够的数据拟合场景了,那么这种体系我们可以适用于哪些地方呢?比如可以用于判断用户的性别和年龄,也可以用于判断用户理财价值比较大还是旅游比较多类别。
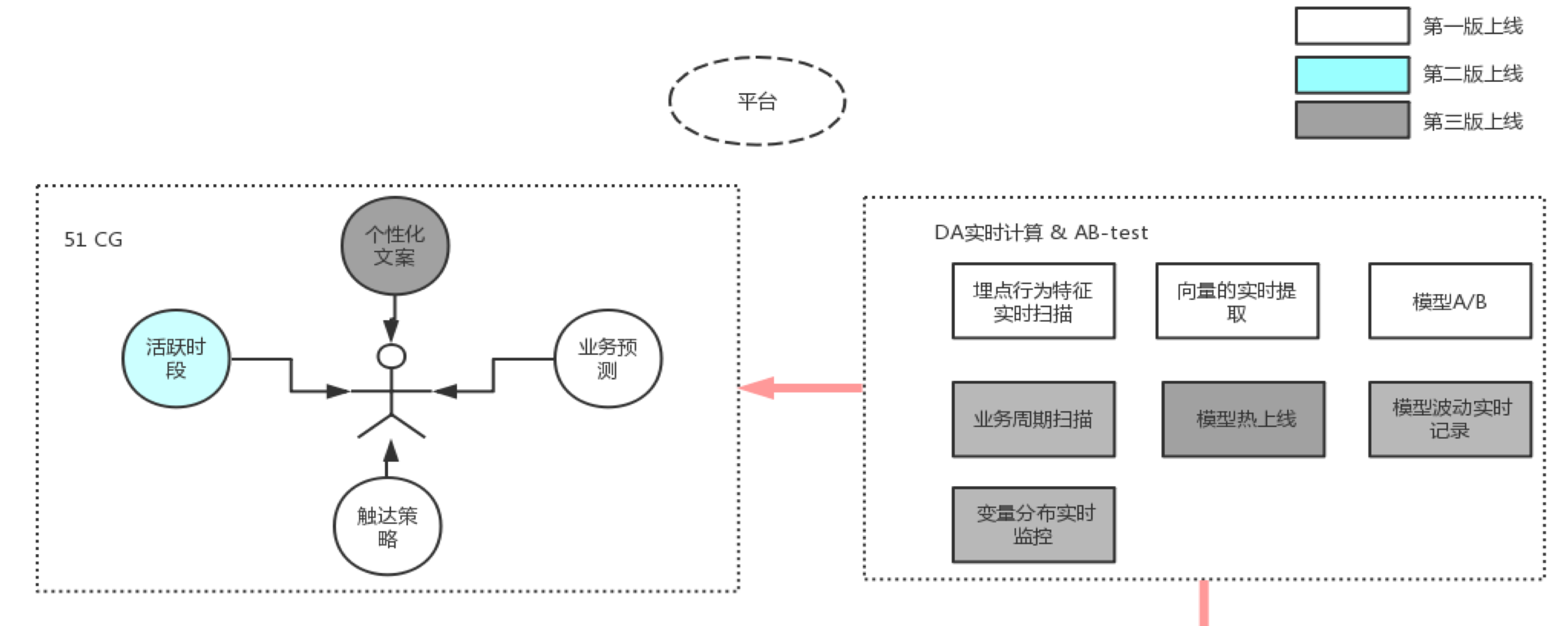
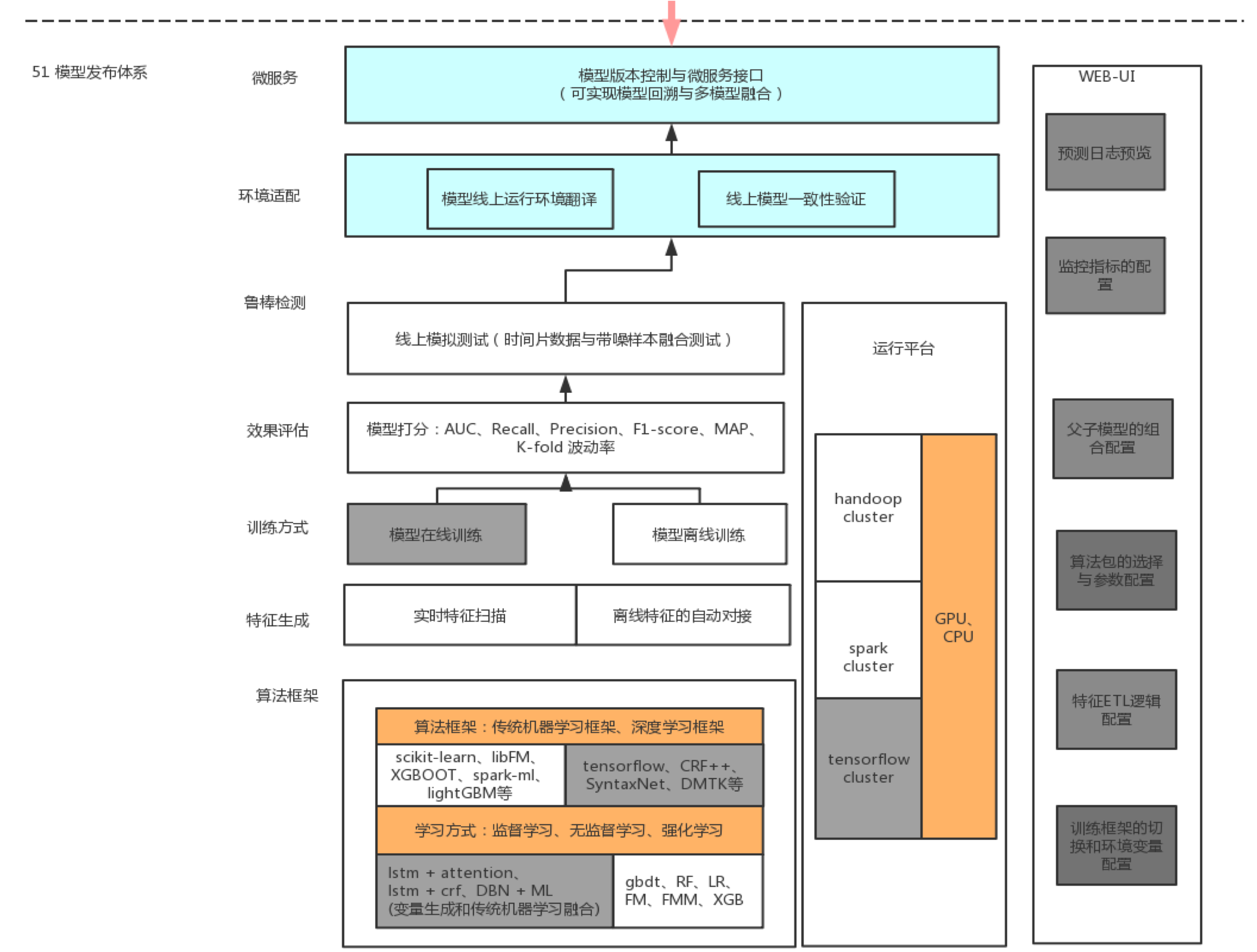
接下来介绍如何将这些模型高效利用,各个业务线如何打通呢,建模人员如何高效利用起来呢?在金融领域这类介绍的比较少,接下来简单介绍一下我们的算法框架。我们算法上线时候,有一个统一的自动化翻译过程,不管是 Python、C++还是 R 语言写的算法统统被屏蔽掉,因为我们要求线上环境必须是稳定的,此外产品上线情况下还需要做移植性校验,将翻译过程的错误进行封装。流程再往上走,51 作为一个个性化通用平台,特征生成包括实时特征扫描、离线特征自动对接以及多元特征融合,训练方式包括模型在线训练、模型离线训练,效果评估包括模型打分指标:AUC、Recall、Precision、F1-score、MAP、K-fold 波动率等,鲁棒性检测包括线上模拟测试(时间片数据与带噪样本融合测试)。再往上走就是环境适配,包括模型线上运行环境翻译与线上模型一致性验证。再往上就是 51CG 运营管理平台,实现了全自动化,因此我们模型上线速度特别快,只要配置好信息随时能够上线对接。
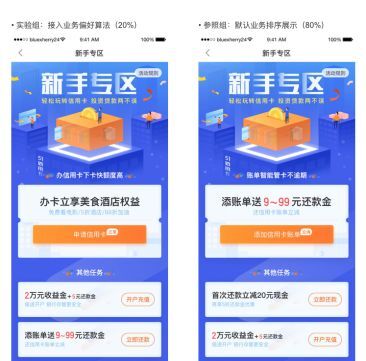
增长的案例 1:新手专区个性化 AB。51 管家最大的功能点就是管理账单,如下图所示针对多种类型新用户(导单、还款、理财、办卡贷款、征信)实现 T+0(实时毫秒级)个性化新手专区 AB 测试新手专区转化率较默认业务排序提升 7-14%。
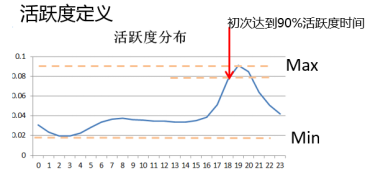
第 2 个案例就是前面提到的 51 管家重推送(Push),首先简单说明 Push 优化五个关键问题: 合适的时间、以合适的文案、给合适的人、推送合适的内容、疲劳度控制。什么是合适的时间,建立推送时间优化 AB 迭代机制,这个主要依靠运营或产品脑洞,没有特别好的方法,每个产品有个合适的时间。如下图所示,我们的思路是看平均活跃时间、最活跃时间、最活跃时间提前 1 小时以及活跃次数 90 分位数的最早时间等,这样就可以划分活动分布。
理财文案比较多,我们通过 MAB 算法来选择最佳文案,简单介绍一下我们如何应用的?MAB 是一个算法模型,我们采用 UCB 算法(置信区间上界)来计算每一个文案下收益,置信区间上下限宽度需要注意一下,如果置信区间上下限很宽的话是存在风险的,由于实验不够可能每次都定位同一个位置,这个时候如何校验需要一定的拆分实验功底。

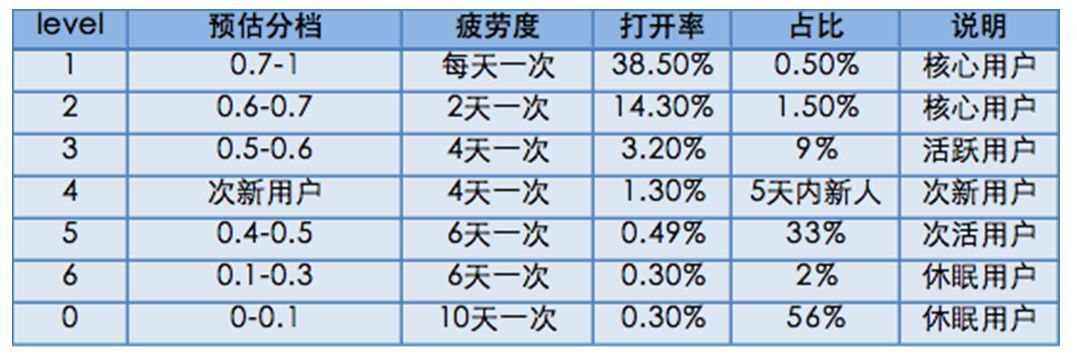
如何通过数据驱动设计疲劳度控制?通过预测加分档方式进行调整。这里打开率预估是 Push 里面最基础的模型,需要持续迭代优化,通过 MVP(Minimum Viable Produc)最小化产品可行来驱动,预估分档为规则(最近 N 天打开 Push)-LR 模型(纯打开率)-融合(转化率)+校准(calibration),有些情况下打开次数频繁,此时需要进行一定限制。
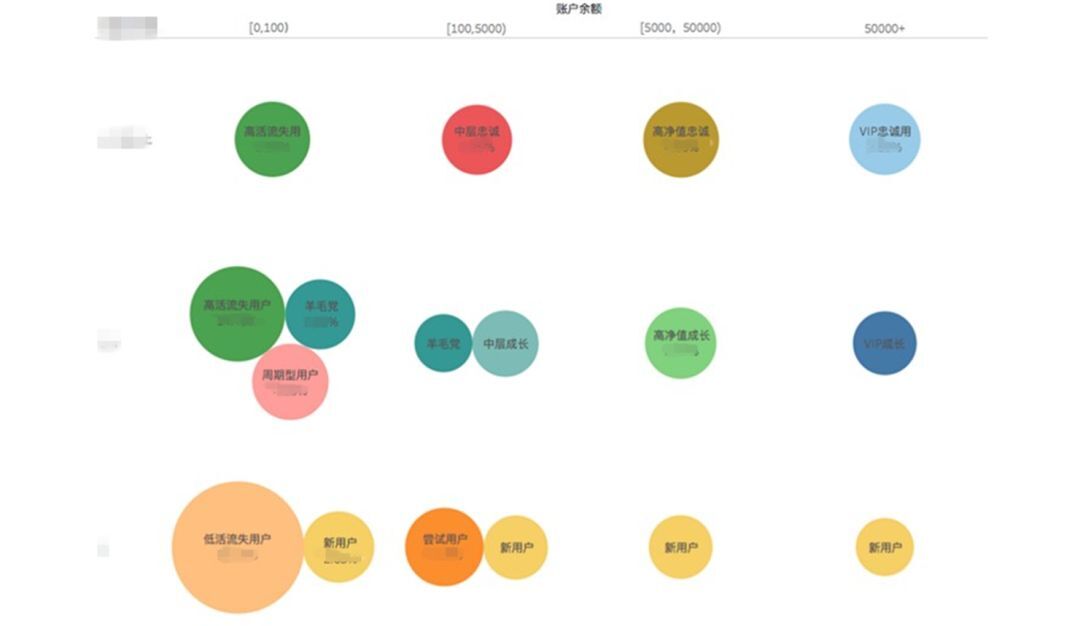
增长案例 2:基于用户标签对理财用户进行细分预测。我们对用户定义分群非常清楚,比如低活流失用户、高活流失用户、周期型用户、尝试型用户等,包括前面提到的 Push 在增加用户活跃量的条件下,用户打开 APP 时基本就是活跃的,那么这些是基于我们数据的积累。
下图所示,基于 push 渠道精细化运营的结果。针对 6 种细分人群做差异化运营策略跟踪一个月时间,最终 AB 实验,六个人群较未提供策略都有比较显著的 ROI 净值提升。
作者介绍:
陈兵强, 现担任 51 信用卡管家资深算法专家,曾担任美国 nanjee 公司算法研发总监、国内领先大数据公司的 ID-Graph 团队负责人,长期从事金融领域的 ML、DL 等相关算法研究和落地解决方案。
本文来自陈兵强在 DataFun 社区的演讲,由 DataFun 编辑整理。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论