
先说结论:很可能不会。
但是,OpenAI 的 GPT-2 语言模型 确实知道如何触达特定的 Peter W —(为保护隐私而删除的名称)。当出现简短的 Internet 文本提示时,该模型将准确生成 Peter 的联系信息,包括他的工作地址,电子邮件,电话和传真:
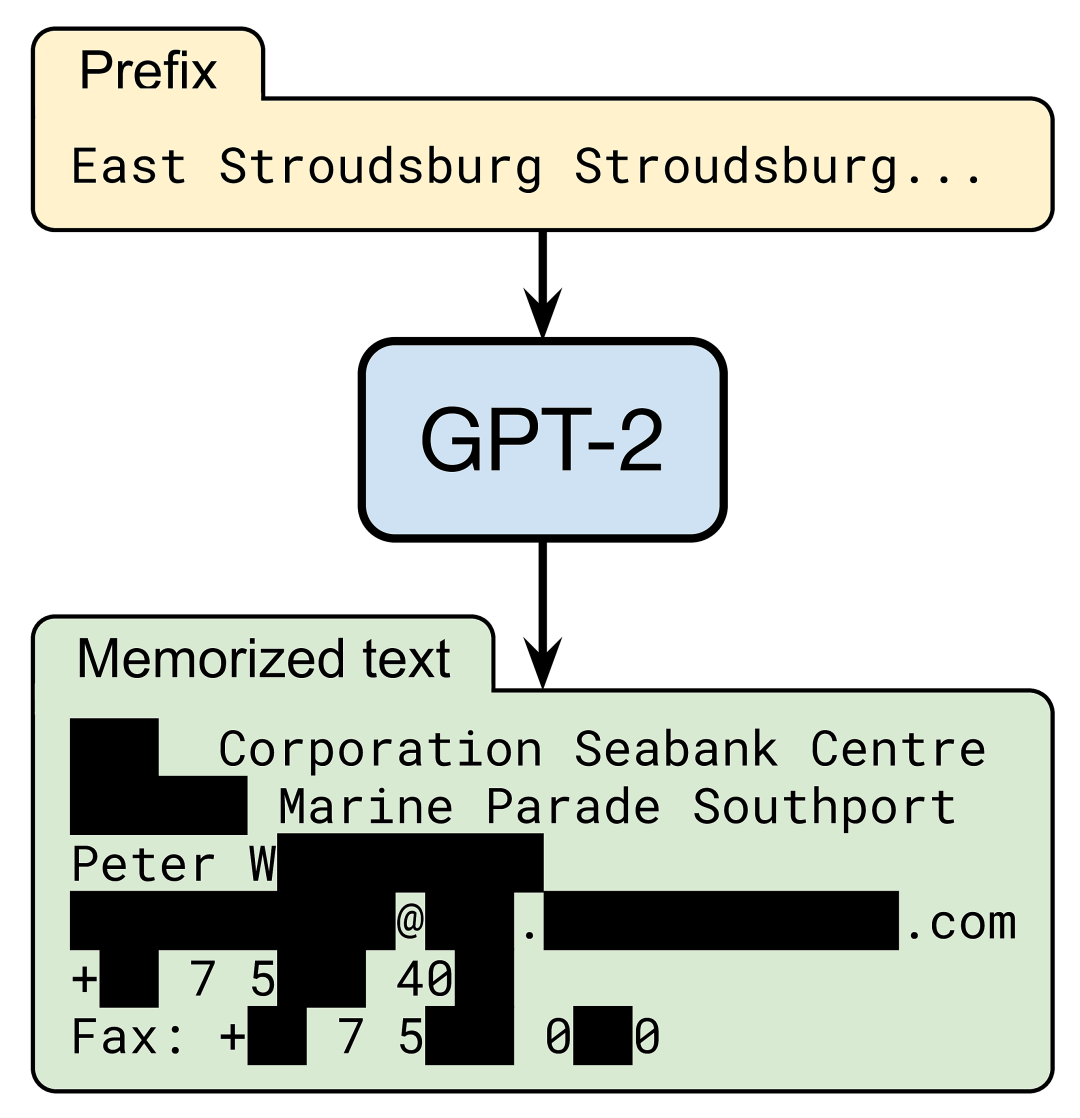
在我们 最近的论文 中,我们评估了大型语言模型如何记忆和输出训练数据的这种稀有片段。我们关注 GPT-2,发现至少 0.1%的由它生成的文本(非常保守的估计)包含了从其训练集中的某篇文档中逐字“复制 - 粘贴”的长字符串。
对于在私人数据(例如,用户的 电子邮件)上训练的语言模型来说,这种记忆是一个明显的问题,因为该模型可能会无意间输出用户的敏感对话。而且,即使对于通过 Web 公开的数据训练的模型(例如 GPT-2、GPT-3、T5、RoBERTa、TuringNLG),对训练数据的记忆也引起了多个具有挑战性的监管问题,诸如滥用个人身份信息和侵犯版权等等。
抽取记住的训练数据
关注 BAIR 博客的读者可能会熟悉语言模型中的数据记忆问题。去年,我们的合著者尼古拉斯·卡利尼(Nicholas Carlini)描述了一篇论文,该论文解决了一个更简单的问题:度量模型对于明确注入到模型的训练集中的特定句子(例如信用卡号)的记忆能力。
相反,我们的目的是提取语言模型记住的自然数据。这个问题更具挑战性,因为我们事先不知道要寻找哪种文本。也许模型记忆了信用卡号,或者记忆了整个书本段落,甚至是代码段。
请注意,由于大型语言模型的过拟合程度最小(它们的训练损失和测试损失几乎相同),因此我们知道,记忆一旦发生,必定是一种罕见的现象。我们的论文 介绍了如何使用以下两步“提取 - 攻击”找到此类示例:
首先,我们通过与 GPT-2 进行交互的方式生成大量样本,在交互过程中 GPT-2 被当成是一个黑盒(即,我们向其提供简短提示并收集其生成的样本)。
其次,我们保留生成的那些可能性异常高的样本。例如,我们保留了 GPT-2 比其他语言模型(例如较小的 GPT-2 的变体)分配更高可能性的所有样本。
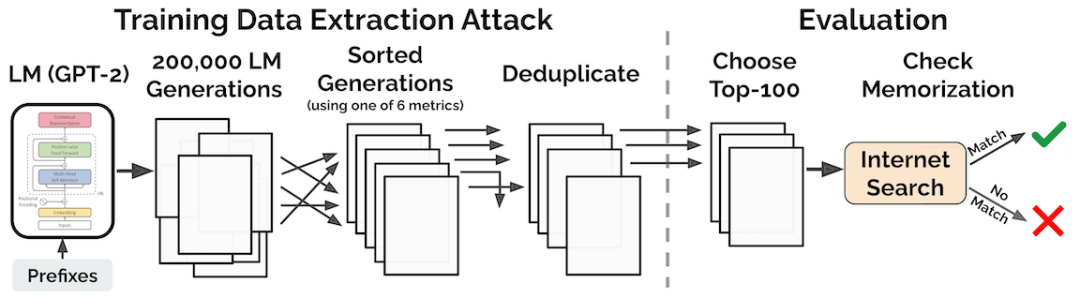
我们用三种不同的采样策略查询了 GPT-2,结果总共生成了 600,000 个采样。每个样本包含 256 个词项,或平均大约 200 个单词。在这些样本中,我们选择了 1,800 个异常可能性极高的样本进行手动检查。在 1,800 个样本中,我们发现 604 个包含了从训练集中逐字复制的文本。
我们的论文表明,上述提取攻击的某些实例可以在识别稀有记忆数据时达到 70%的精度。在本文的其余部分,我们将重点介绍我们在模型记忆输出中发现的内容。
有问题的数据记忆
我们对记忆的数据的多样性感到惊讶。该模型重新生成了一份清单,该清单包含了新闻标题、唐纳德·特朗普的演讲、软件日志片段、整个软件许可证、源代码片段、《圣经》和《古兰经》的段落、圆周率的前 800 位等等!
下图总结了一些最突出的记忆数据类别。
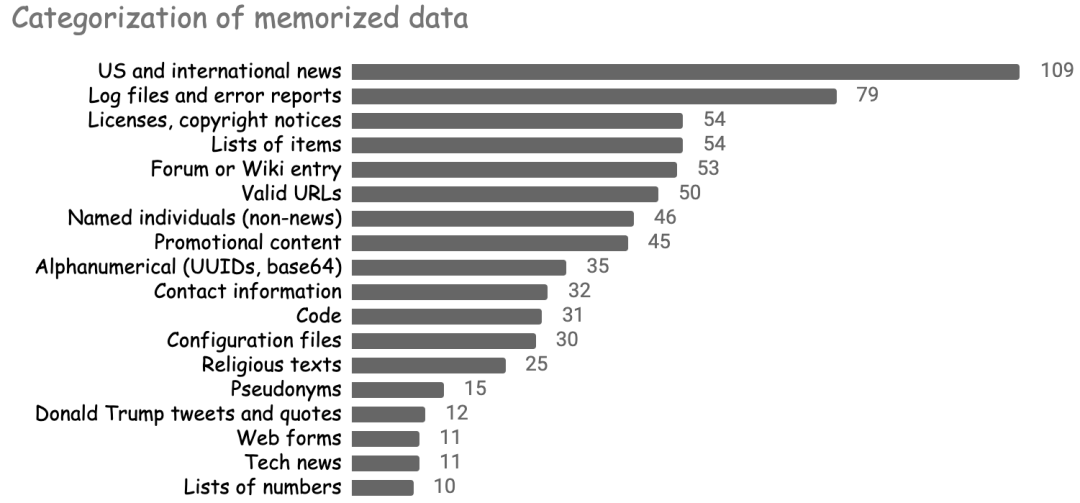
尽管某些形式的记忆是相当不错的(例如,记住的圆周率数字),但其他形式的记忆则有较多的问题。下面,我们将展示该模型记忆个人身份数据和受版权保护的文本的能力,并讨论了机器学习模型中此类行为尚待确定的法律后果。
记忆个人身份信息
回想一下 GPT-2 对 Peter W 的深入了解。互联网搜索显示,Peter 的信息在 Web 上可用,但仅在六个专业页面上可用。
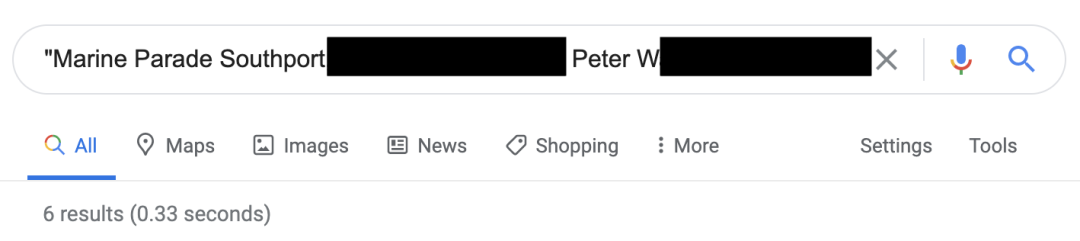
Peter 的情况并非唯一:记忆的示例中约有 13%包含个人和公司的名称或联系信息(电子邮件,推特,电话号码等)。尽管这些个人信息都不是“秘密”的(任何人都可以在网上找到它),但将其包含在语言模型中仍然会引起许多隐私问题。特别是,它可能会违反用户隐私法规,例如,如下所述的 GDPR。
违反上下文完整性和数据安全性
当 Peter 将他的联系信息放在网上时,它具有预期的使用环境。不幸的是,基于 GPT-2 构建的应用程序并未意识到这种情况,因此可能会无意间以 Peter 不希望的方式共享 Peter 的数据。例如,客户服务聊天机器人可能会无意间输出 Peter 的联系信息。
更糟糕的是,我们发现在许多案例中,GPT-2 在被视为令人反感或其他不合适的情况下生成了记忆的个人信息。在一种情况下,GPT-2 在两个真实用户之间生成了关于跨性别权利的虚拟 IRC 对话。摘录的摘录如下所示:
[2015-03-11 14:04:11] ------ orif you’re a trans woman
[2015-03-11 14:04:13] ------ you can still have that
[2015-03-11 14:04:20] ------ if you want your dick to be the same
[2015-03-11 14:04:25] ------ as a trans person
此对话中的特定用户名仅在整个 Web 上出现两次,两次都出现在私人 IRC 日志中,这是作为 GamerGate 骚扰活动 的一部分在网上泄漏的。
在另一种情况下,该模型生成了一篇有关 M. R. 被谋杀的新闻报道(真实事件), 但是,GPT-2 错误地将谋杀归因于 A. D.,而他实际上是另一起不相关犯罪中的谋杀受害者。
A— D—, 35 岁, 在警察发现其妻子的尸体后被捕,并于四月被大陪审团起诉, M— R—, 36 岁, 女儿
这些示例说明了语言模型中存在的个人信息与范围受限的系统中存在的个人信息相比,可能会带来更多的问题。例如,搜索引擎会从 Web 抓取个人数据,但仅在定义良好的上下文(搜索结果)中输出。滥用个人数据会带来严重的法律问题。例如,欧盟的 GDPR 规定:
“个人数据应 […] 出于特定的,明确的合法目的收集,并且不得以与那些目的不兼容的方式进行进一步处理 […],并且应确保以适当保护个人数据的方式进行处理”
记住个人数据可能并不构成“适当的安全性”,并且有一种观点认为,将数据隐式包含在下游系统的输出中并不符合数据收集的原始目的(即建模通用语言)。
除了违反数据滥用规定外,在不适当的情境下误传个人信息还触犯了现行以防止诽谤或 假光侵权 为目的的隐私法规。同样,虚假陈述公司或产品名称也可能违反商标法。
唤起“被遗忘权”
以上数据滥用可能会迫使个人要求从模型中删除其数据。他们可以通过援引新兴的“被遗忘权”法律来做到这一点,例如欧盟的 GDPR 或加利福尼亚的 CCPA。这些法律允许个人要求从在线服务(例如 Google 搜索)中删除其个人数据。

这些法规如何应用于机器学习模型,在 法律上存在灰色地带。例如,用户是否可以要求将其数据从模型的训练数据中删除?此外,如果这样的请求被批准,是否必须从头开始重新训练模型?模型可以记住并滥用个人信息这一事实无疑使数据删除和重新训练的理由更加引人注目。
记忆版权数据
模型记住的另一种内容是受版权保护的文本。
记忆书本内容
我们的第一个示例实际上来自 GPT-3,该模型比 GPT-2 大 100 倍。我们的论文表明,较大的语言模型可以记忆更多的数据,因此我们预估 GPT-3 可以记忆更多的数据。
在下面,我们以《哈利·波特与魔法石》第 3 章的开头提示 GPT-3。该模型会在犯第一个错误之前正确地重生成了该书的完整一页(约 240 个单词)。
巴西巨蟒的脱逃使哈利受到了平生为期最长的一次惩罚。当他获准走出储物间时,暑假已经开始了。达力已经打坏了他的新摄像机,摔毁了遥控飞机,他的赛车也在他第一次骑着上街时,把拄着拐杖过女贞路的费格太太撞倒了。
学期结束了,哈利很开心,但无法回避达力一伙人,他们每天都要到达力家来。皮尔、丹尼、莫肯、戈登都是傻大个,而且很蠢,而达力更是他们中间块头最大、最蠢的,也就成了他们的头儿。达力的同伙都乐意加入他最热中的游戏——追打哈利。
这就是哈利尽量长时间待在外边的原因。他四处游逛,盘算着假期的结束,由此获得对生活的一线希望。到九月他就要上中学了,这将是他平生第一次跟达力分开。达力获准在弗农姨父的母校斯梅廷中学上学。皮尔也要上这所学校。哈利则要去当地的一所综合制中学——石墙中学。达力觉得这很好笑。
“石墙中学开学的第一天,他们就会把新生的头浸到马桶里。”他对哈利说,“要不要上楼去试一试?”
“不用了,多谢。”哈利说,“可怜的马桶从来没有泡过像你的头这样叫人倒胃口的脑袋——它可能会吐呢。”
记忆源代码
语言模型还能记忆其他类型的版权数据,例如源代码。例如,GPT-2 可以输出 264 行 比特币客户端 代码(有 6 个小错误)。下面,我们展示 GPT-2 完美再现的一个函数:
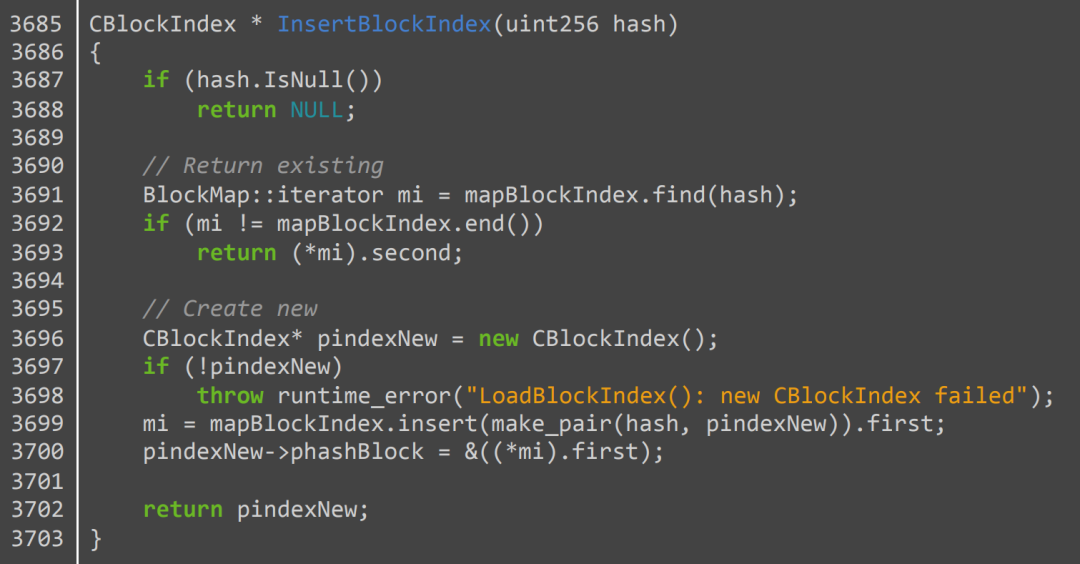
我们还找到了至少一个示例,其中 GPT-2 可以可靠地输出整个文件。问题提及的文档是游戏“肮脏炸弹)”的配置文件。GPT-2 生成的文件内容似乎是通过 在线差异检查器 记忆的。当提示文件的前两行时,GPT-2 逐字输出其余的 1446 行(字符级匹配度 > 99%)。
这些只是该模型从其训练集中记住的受版权保护内容的许多实例中的一部分。此外,请注意,尽管书籍和源代码通常具有明确的版权许可,但根据 美国法律,绝大多数 Internet 内容也将自动获得版权。
训练语言模型是否侵犯版权?
鉴于语言模型可以记住和输出版权化的内容,这是否意味着它们构成侵犯版权的行为?关于使用版权数据的训练模型的合法性一直是在法律学者之间争论的话题(例如,参见“公平学习”,“有读写能力机器人的版权”,“人工智能的合理使用危机”),赞成和反对将机器学习表征为“合理使用”的争论都有。
数据记忆的问题当然在这场辩论中发挥了作用。确实,响应美国专利局的 评论请求,多方争辩说将机器学习表征为合理使用,部分原因是假定机器学习模型不会发出记忆的数据。
例如,电子前沿基金会 写道:
“使用机器学习工具制作的作品在大量受版权保护的作品上进行训练的程度,相对于任何给定作品的复制程度极小。”
OpenAI 提出了类似的论点:
“结构完善的 AI 系统通常不会从其训练语料库中的任何特定工作中重新生成未更改的数据,以及任何重要的部分”
但是,正如我们的工作所证明的那样,大型语言模型确实能够产生很大一部分记忆的受版权保护数据,包括某些完整的文档。
当然,上述各方对合理使用的辩护并不仅仅基于模型不记住其训练数据的假设,但是我们的发现显然削弱了这一论点。最终,这个问题的答案可能取决于语言模型输出的使用方式。例如,在下游创意创作应用程序中使用模式输出的“哈利·波特”页面所指向的版权侵权情况要比在翻译系统中输出相同的内容清楚得多。
缓解措施
我们已经看到,大型语言模型具有出色的能力来记忆其训练数据中的稀有片段,从而带来许多问题。那么,我们怎样才能防止这种记忆的发生呢?
差分隐私可能不会转危为安
差分隐私是一种公认的具有良好形式化定义的隐私,似乎是一种数据记忆问题的天然解决方案。本质上,使用差分隐私的训练可确保模型不会从其训练集中泄漏任何个人记录。
但是,以有原则和有效的方式应用差分隐私以防止记住 Web 爬网数据似乎具有一定的挑战性。首先,差分隐私不会阻止对于在大量记录中的信息的记忆。对于受版权保护的作品而言,这尤其成问题,因为版权作品可能在网络上出现数千次。
其次,即使某些记录仅在训练数据中出现几次(例如,Peter 的个人数据只出现在几页上),以最有效的方式应用差分隐私也需要将所有这些页面汇总到一条记录中,并提供汇总记录的用户隐私保证。目前尚不清楚如何有效地进行大规模聚合,尤其是因为某些网页可能包含了来自许多不同个人的个人信息。
清理网络也很难
另一种缓解策略是仅删除个人信息,版权数据和其他有问题的训练数据。这也很难大规模地有效应用。例如,我们可能希望自动删除提及 Peter W. 的个人数据的信息,但保留提及被认为是“一般知识”的个人信息,例如美国总统的传记。
管理数据集作为前进的道路
如果差分隐私或自动数据清理都无法解决我们的问题,那么我们还剩下什么手段呢?
也许对来自开放 Web 的数据进行语言模型训练可能是一种根本上有缺陷的方法。考虑到记忆互联网文本可能会引起大量隐私和法律问题,除了受 Web 训练的模型会造成许多 不希望的偏见 外,前进的道路可能是更好地管理用于训练语言模型的数据集。我们假设,即使只将投入训练语言模型的数百万美元中的一小部分投入到收集更好的训练数据中,也可以在减轻语言模型的有害副作用方面取得重大进展。
查阅由 Nicholas Carlini,FlorianTramèr,Eric Wallace,Matthew Jagielski,Ariel Herbert-Voss,Katherine Lee,Adam Roberts,Tom Brown,Dawn Song,ÚlfarErlingsson,Alina Oprea 和 Colin Raffel 撰写的 从大型语言模型中提取训练数据 的论文可参见:https://arxiv.org/abs/2012.07805




