

本文最初发表于 Towards Data Science 博客,经原作者 Ajit Rajasekharan 授权,InfoQ 中文站翻译并分享。
本文阐述了一种评估预训练 BERT 模型以提高性能的方法。
摘要
事实证明,在领域特定语料库(如生物医学领域)上从头开始训练 BERT 模型,并使用特定于该空间的自定义词汇表,对于最大限度地提高模型在生物医学领域的性能至关重要。这在很大程度上是因为生物医学领域独有的语言特征,而这些特征在 Google 发布的原始预训练模型中并没有得到充分的体现(BERT 模型的自我监督训练通常被称为预训练)。这些领域特定的语言特征如下:
生物医学领域具有许多该领域特有的术语或短语,例如药物、疾病、基因等名称。这些术语,或者广义地说,生物医学领域语料库对疾病、药物、基因等的实体偏见,在原始预训练模型中,从最大化模型性能的角度来看,没有足够的代表性。最初的 BERT 模型(BERT-BASE/Large-Cased/Uncased,或 tiny BERT 版本)预训练了一个实体偏见的词汇表,这些词汇[主要偏向于人员、地点、组织等」(https://towardsdatascience.com/unsupervised-ner-using-bert-2d7af5f90b8a)。
生物医学领域特有的句子片段 / 结构示例有:(1)“《疾病名称》继发于 《药物名称》……”,(2)“《疾病名称》对于之前的两种治疗方法难以治愈,患者需接受《治疗名称》治疗”。
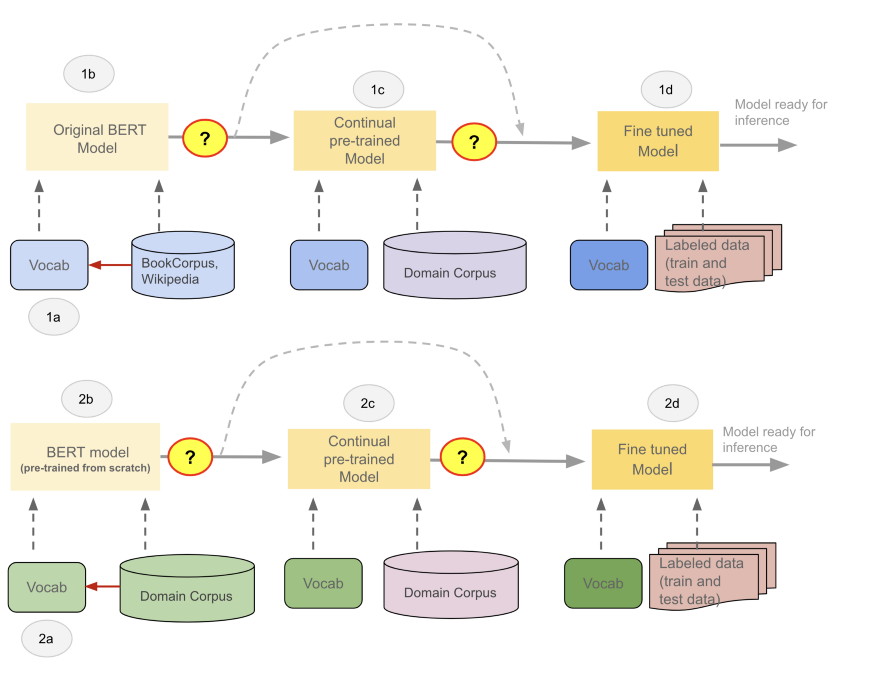
在保留原有词汇的领域特定语料库上进一步训练原有的 BERT 模型,通常称为持续预训练,然后在监督任务上进一步微调模型,已经证明可以提高模型的性能(例如,图 1 的 BioBERT 路径 1A→1B→1C→1D)。然而,这样的模型的性能仍然落后于具有领域特定词汇的特定语料上从头开始预训练的模型(例如,图 1 中的SciBERT路径 2A→2B→2D)。
鉴于 BERT 模型的典型应用是利用现有预训练模型,并在任务上对其进行微调(图 1 中的路径 1A→1B→1D),因此在实践中,经常做出一个隐含的假设,即原有预训练模型训练得“很好”,并且能充分发挥作用。只有经过微调的模型才会被评估——预训练模型的质量被认为是理所当然的。
然而,当我们使用自定义词汇表从头开始预训练 BERT 模型以最大化性能时,我们需要一种方法来评估预训练模型的质量。BERT 的预训练模型在掩蔽语言目标(预测句子中被掩蔽或损坏的标记)或下一句目标上的损失,可能在实践中并不够。
下面列出的性能检查对于检查预训练模型可能很有价值。
上下文无关的向量性能。检查构成 BERT 词汇的训练后的上下文无关向量。具体来说,它们的聚类特征以及所有向量与词汇表中其他向量的聚集分布。在进行该测试时,训练不足 / 训练不当的模型往往具有不同于训练良好的模型的特征。
上下文有关的向量性能。检查上述上下文无关向量在通过训练好的模型时转换成上下文有关的向量之后的质量。这些转换后的向量显示了模型在掩蔽词预测中的性能。虽然这本质上是掩蔽语言模型损失值在训练过程中所捕捉到的内容,但对于几个大类掩蔽语言任务的模型性能进行细粒度的检查(如下所述),可能比代表模型损失的单一数字更能揭示模型的性能。假设测试是全面的,即包括针对领域特定的实体类型的测试,并且具有领域特定的句子结构,那么在此度量中表现不佳的模型就表示模型训练不足。
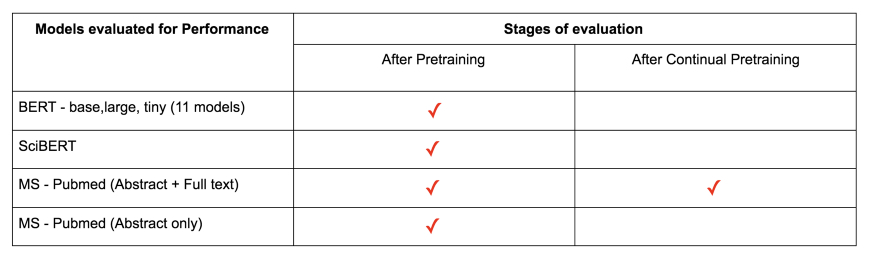
下面将使用这两种性能指标来检查一些公开发布的 BERT 预训练模型的质量。
下面讨论的这个练习的结果,强调了评估预训练模型以最大化模型性能的重要性。它还可以帮助我们确定是否需要对一个公开发布的模型进行进一步的预训练,即使它是在我们感兴趣的领域中进行预训练,然后再针对领域特定的任务对其进行微调。
快速回顾 NLP 任务的 BERT 模型用例
BERT 中的自监督学习是通过掩蔽和破坏句子中的少数词来完成的,并使模型通过预测这些词来进行学习。尽管这种形式的学习(自编码器模型)限制了模型生成新句子的能力,与 GPT-2 等自回归模型相比,预训练 BERT 模型可以原样用于无监督的 NER、句子表示等。在不需要标记任何数据的情况下,利用构成 BERT 词汇表的学习向量(上下文无关向量)和模型的 MLM(掩蔽语言模型)能力——即 BERT 使用上下文有关向量(出现用于掩蔽位置的模型的向量)的“填空”能力:在原始词汇表中与这些向量相邻的向量是填空的候选者。
然而,预训练 BERT 模型的流行和典型用法是针对下游监督任务对其进行微调。在某些情况下,为了提高模型性能,在微调之前可能需要持续的预训练。(图 2)
任何形式的模型训练、预训练、持续预训练或微调,都会修改模型权重和词汇向量:在训练阶段中,从左到右的同色模型(米色)以及词汇表(蓝色)的不同颜色说明了这一事实,如图 1 和图 2。
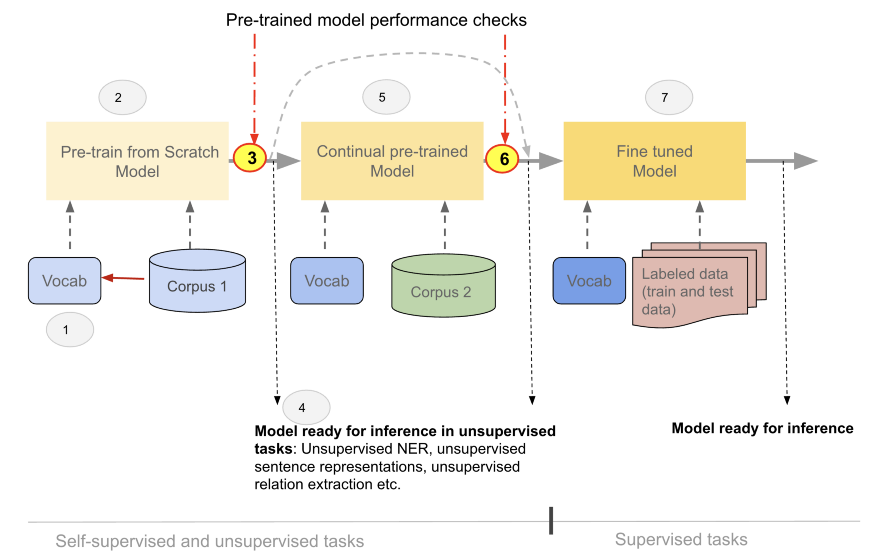
通过研究以下模型的证据表明,无论使用何种训练路径(图 1 中的 1A-1D 或 2A-2D),对预训练模型性能的评估(图 2 中的步骤 3 或 6),可能是下游任务中最大化模型性能的关键。
上下文有关向量的评估(MLM 检查)
三大类的“填空”测试(掩蔽语言模型预测)被用来评估模型性能。这些测试基本上都是带掩蔽的句子。掩蔽位置的模型预测分数(在整个词汇表中)用于评估模型性能。
词汇测试:一个模型如何使用领域预料库所特有的术语。这个测试类别包含词汇中出现的具有完整术语的句子(没有分解成子词的词汇),以及由来自词语表的子词组成的术语。
领域特定实体和句子结构测试:测试模型预测句子中的领域特定实体和领域特定结构的能力。
基本语言句子结构测试:该测试模型预测感兴趣的主要语言的基本句子结构的能力(对于多语言语料库,这需要按比例表示主要语言)。
词汇测试样本

图 4a:词汇测试样本:对空白位置的 5 个模型的前 10 个预测。尽管词汇表不存在伊马替尼(imatinib,瑞士诺华公司研发的癌症靶向药)这一术语,但 BERT base uncased 预测还是捕捉到了伊马替尼是一种化学物质的概念。相比之下,SciBERT 并没有捕捉到这一点,尽管它的词汇表中存有完整的单词。这在一定程度上可能是因为 SciBERT 是在一个科学预料库而不是专门的生物医学预料库上训练的。这两个 Microsoft 预训练模型表现都不佳,但其中一个(MS-Abs+Full)在临床试验中持续预训练时,在所有 5 个模型中表现最好。
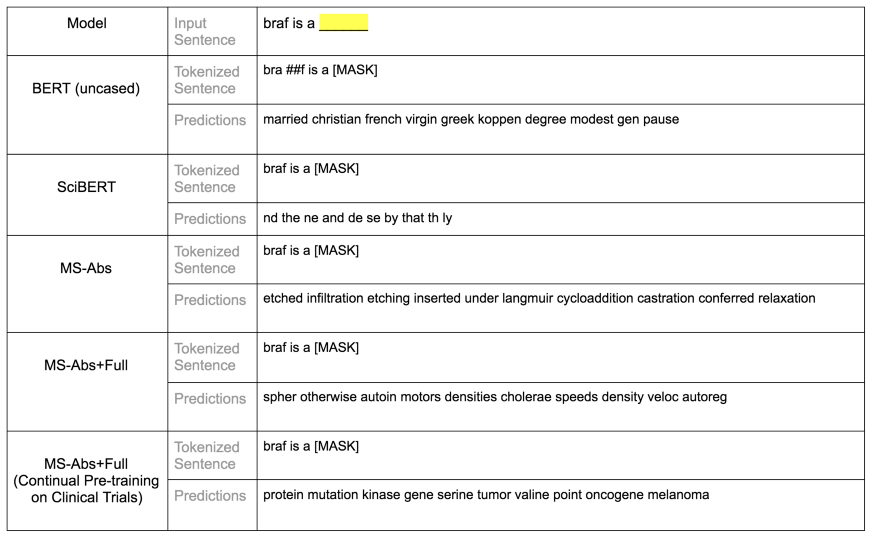
图 4b:词汇测试样本:对空白位置的 5 个模型的前 10 个预测。BERT base uncased 预测未能捕捉到 braf 是一个基因这一事实。SciBERT 也没有捕捉到它,尽管在它的词汇表中有完整的单词 braf。这在一定程度上可能是因为 SciBERT 是一个科学预料库而不是专门的生物医学预料库上进行训练的。这两种 Microsoft 预训练模型表现都不佳,但其中一种(MS Abs+Full)在临床试验中持续预训练时,在所有 5 个模型中表现最好。
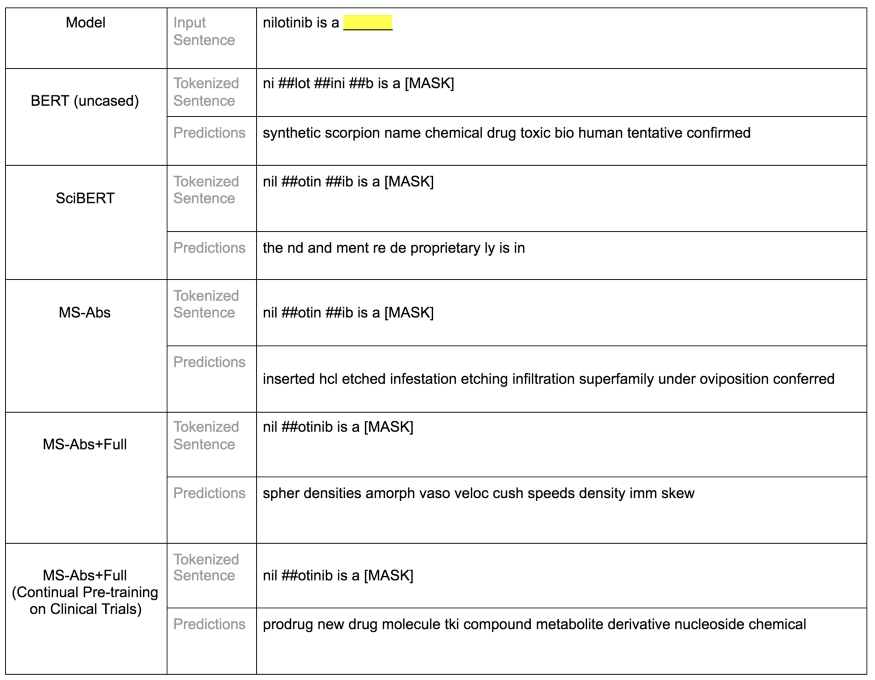
图 4c:词汇测试样本:对空白位置的 5 个模型的前 10 个预测。BERT base uncased 预测捕捉了尼洛替尼(nilotinib,是一种酪氨酸激酶抑制剂)是一种化学物质的概念,尽管尼洛替尼这一术语在词汇表中并不存在。相比之下,SciBERT 没有捕捉到这一点,尽管在它的词汇表中有完整的单词。两种 Microsoft 预训练模型表现都不佳,但其中一种(MS-Abs+Full)在临床试验中持续预训练时,在所有 5 个模型中表现最好。在这个情况中,Microsoft 模型将术语尼洛替尼分解成几个子词。
领域特定实体和句子结构测试样本
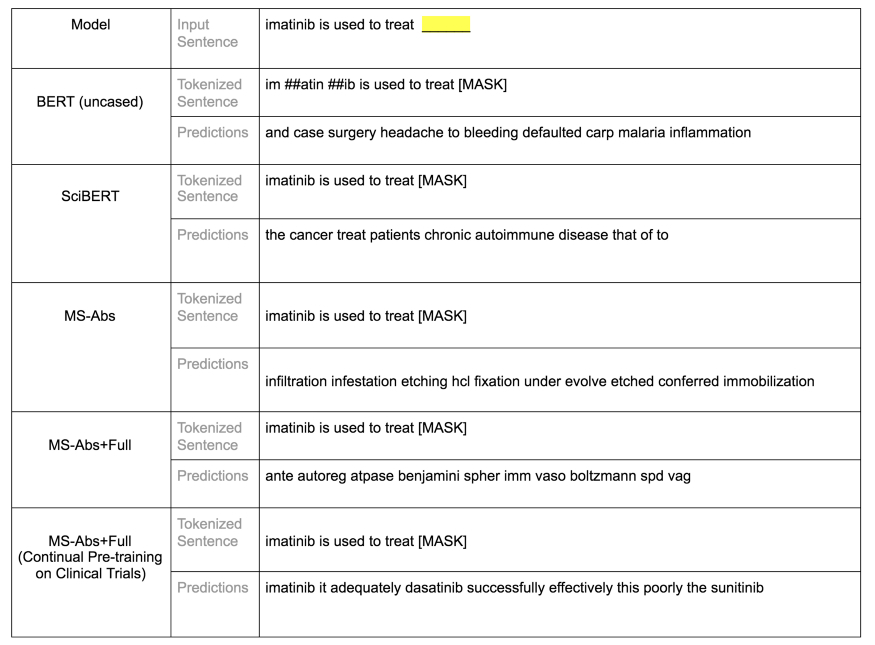
领域特定实体和句子结构测试样本:对空白位置的 5 个模型的前 10 个预测。 BERT base uncased 预测捕捉到了伊马替尼治疗疾病的概念。SciBERT 也捕捉到了这一点。Microsoft 的模型在这些测试中表现很差,即使在使用临床试验语料库进行持续预训练之后也是如此。
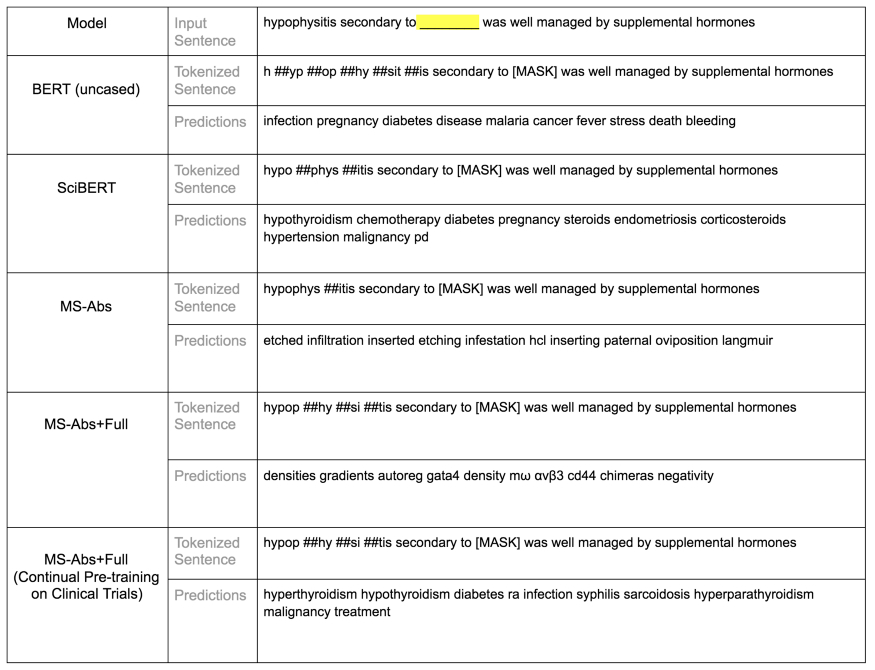
图 4e:领域特定实体和句子结构测试样本:对空白位置的 5 个模型的前 10 个预测。在这个测试中,空白位置具有实体歧义性,可能是一种药物,也可能是一种疾病。 BERT base uncased 捕捉到了疾病的概念,但没有捕捉到药物的概念。SciBERT 同时捕捉到了疾病和治疗的概念。Microsoft 模型经过持续预训练之后,也捕捉到了这两个概念。这两个 Microsoft 预训练模型在这次测试中表现都不佳。
基本语言句子结构测试样本
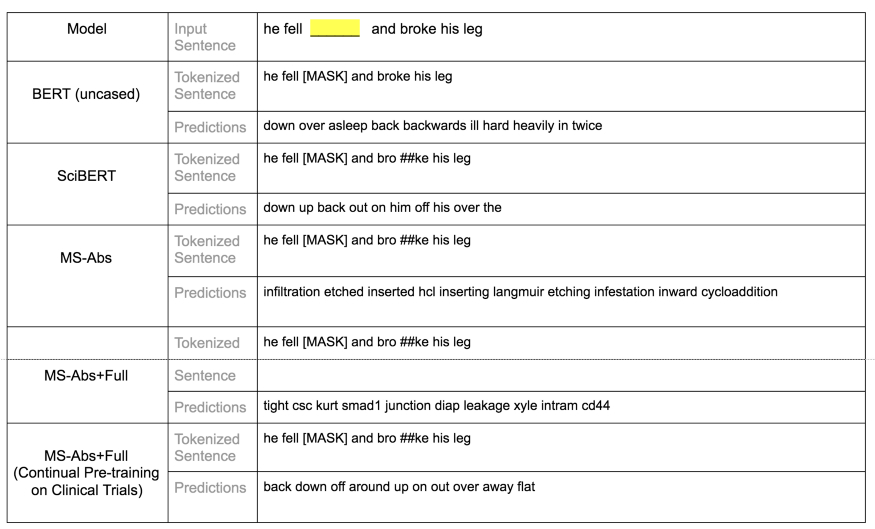
图 4f:基本语言句子测试:对空白位置的 5 个模型的前 10 个预测。鉴于 BERT base uncased 使用的语料库是 Wikiped 和 Bookcorpus,因此它的性能在这次测试中要优于其他模型,这并不奇怪。SciBERT 和 Microsoft 持续预训练模型也表现良好,而两个 Microsoft 预训练模型表现都不佳。
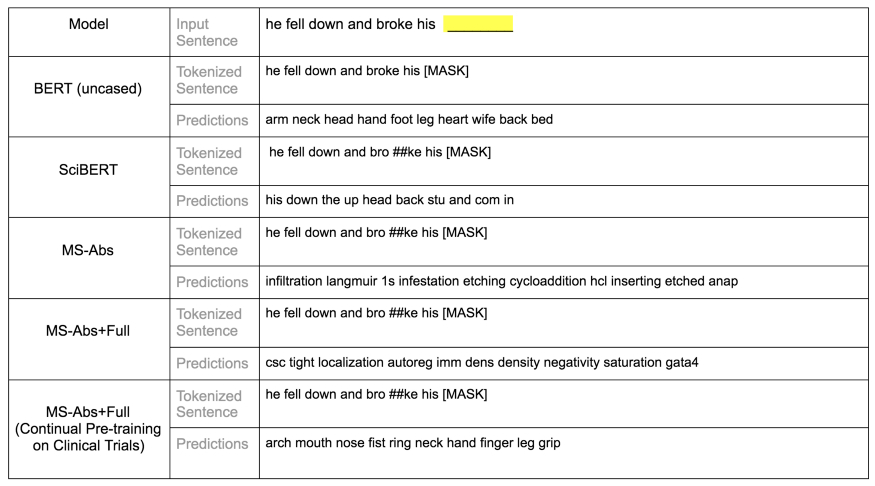
图 4g:基本语言句子测试:对空白位置的 5 个模型的前 10 个预测。在这个测试中, BERT base uncased 的性能也优于其他模型。SciBERT 和 Microsoft 持续预训练模型的性能也不错。而两个 Microsoft 预训练模型性能较差。
以上测试总结
虽然以上测试仅仅是三个大类的说明性样本,但从业者可以使用类似上面的几个定性测试来检测一个模型在训练模型时或之后性能不佳。两个 Microsoft 的两个预训练模型就是这样的例子:它们在所有测试中的性能一直很差。其中一个性能不佳的模型除了不准确的预测外,还表现出其他预训练不足 / 不当的迹象:它们具有相同的特征噪声,比如不同 / 不同输入句子的术语。
然而,为了确定一个模型是否经过预训练以最大化性能,就必须在这些类别中创建足够数量的测试用例,然后基于对空白位置的顶部模型预测对性能进行评分。
总的来说,在上面的测试中:
Microsoft 预训练模型在临床试验中进行持续预训练后(由我进行持续预训练以评估),在生物医学领域测试中性能最好,在基本语言测试中也相当出色。
BERT 虽然没有领域特定词汇表,但在生物医学测试中性能相当不错(除了领域特定术语的预测),这表明它已经经过良好的预训练。
SciBERT 的性能也相当不错。但在生物医学领域和基础语言测试方面都无法出类拔萃。
如上所述,公开发布的 Microsoft 预训练模型(PubMedBERT)性能最差。考虑到持续预训练提高了模型的性能,使其成为本次评估中生物医学领域的最佳模型,它间接地证实了 Microsoft 模型的最新性能(即使上面的样本量太小,无法得出模型性能的结论),当训练时间更长时(Microsoft 尚未发布最新的模型,三个模型中的两个已发布,见本文表 8)。这也强调了在发布模型 / 使用模型用于其他任务之前对其进行评估的重要性,尽管随后对模型进行了微调,而该模型在测试中性能不佳,但仍然可以产生最新的结果(这两个 Microsoft 模型就是证据)。
上下文无关向量的评估(词汇检查)
除了训练模型输出的上下文有关向量显示出训练不足 / 不良的可衡量迹象外,构成 BERT 词汇表的向量还可以揭示关于训练质量的可衡量信息。例如:
直方图是由 BERT 词汇表中的每个词和词汇表中的其他向量的余弦分布构成的。这些直方图可用于识别可能训练不足 / 不当的模型。
对术语的顶级领域进行抽样也有助于揭示训练质量:顶级领域往往是典型的同一实体类型的。
词汇向量聚类。在训练期间或在预训练和持续预训练运行中比较训练过的模型集群,可以深入了解持续训练的效果。
各种模型的余弦分布直方图
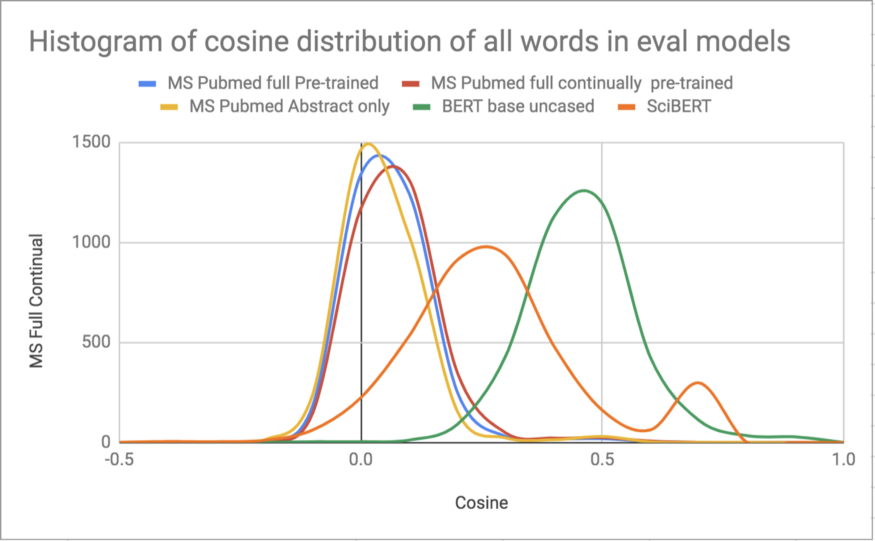
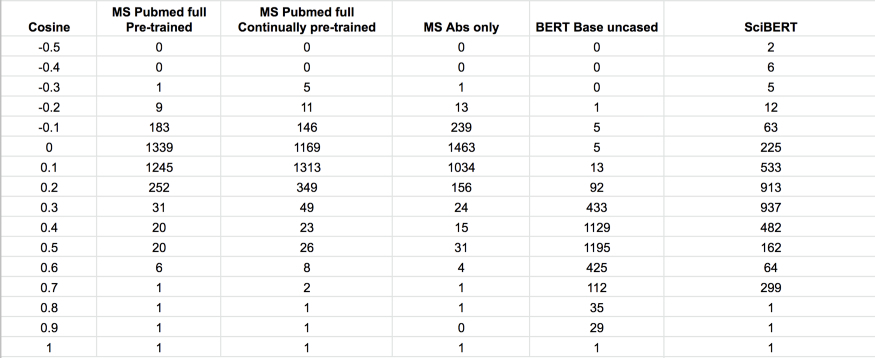
图 5:在 5 个评估模型的词汇中随机抽样约 1000 个单词的余弦分布直方图。Microsoft 的模型,即使经过持续预训练,七分部看起来也更像是一个 BERT 大型模型(见下图)。然而,总的来说,这些数据并没有显示出任何不同寻常的东西,这表明词汇向量是经过充分训练的。经过持续训练后,分布只有轻微的右移,这进一步支持了这一结论。向量集群(如下所述)也为索赔词汇向量的训练提供了充分的证据。这就得出了一个逻辑结论:Microsoft 模型的权重可能没有得到充分的训练。持续预训练解决了这一问题,从而带来了一流的性能。这一结论还得到以下事实的进一步证明:Microsoft 对一个模型进行更长时间的训练,并在所有三个模型中得出了最好的分数(Microsoft 尚未公布三个模型中的最佳模型)。SciBERT 有第二个凸起,与所有被检测的分布相比,它具有截然不同的形状,原因不得而知。一般来说,这些直方图对于检测异常分布是有用的,这些分布可能暗示了一些潜在的现象。
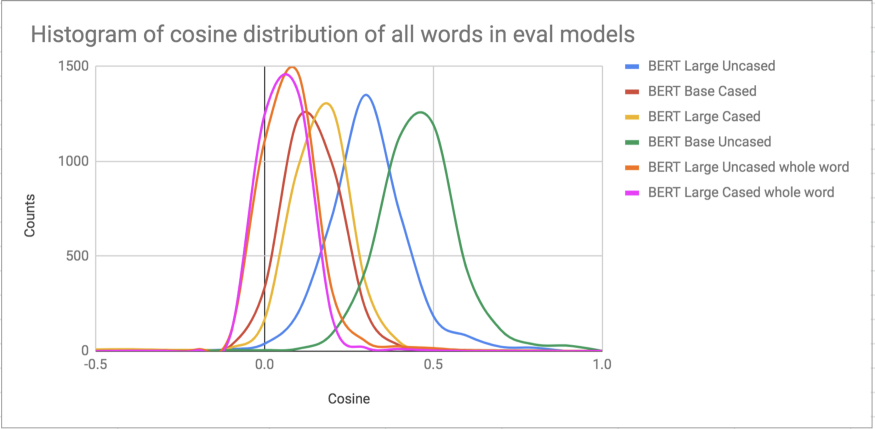
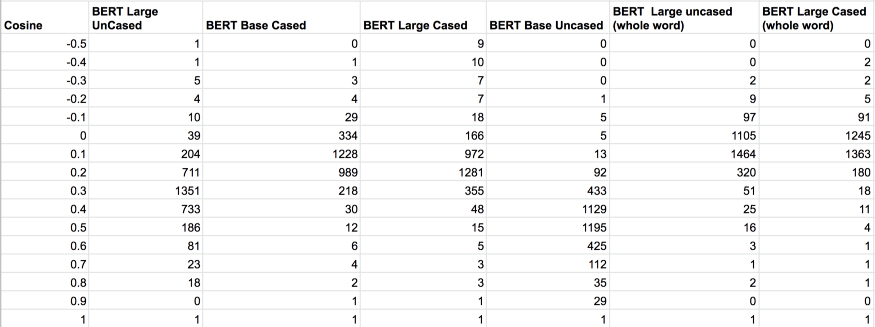
图 6:在词汇表中随机抽样约 1000 个单词的余弦分布直方图。BERT 大型模型(cased 和 uncased,整个单词被掩蔽)往往有较长的尾部。与大型模型相比,模型的分布均值更倾向于向右基模型移动。有趣的是,尽管 Microsoft 模型与 BERT 基本模型(768 dim;12 层)相同,但其分布更像是 BERT 大型模型。
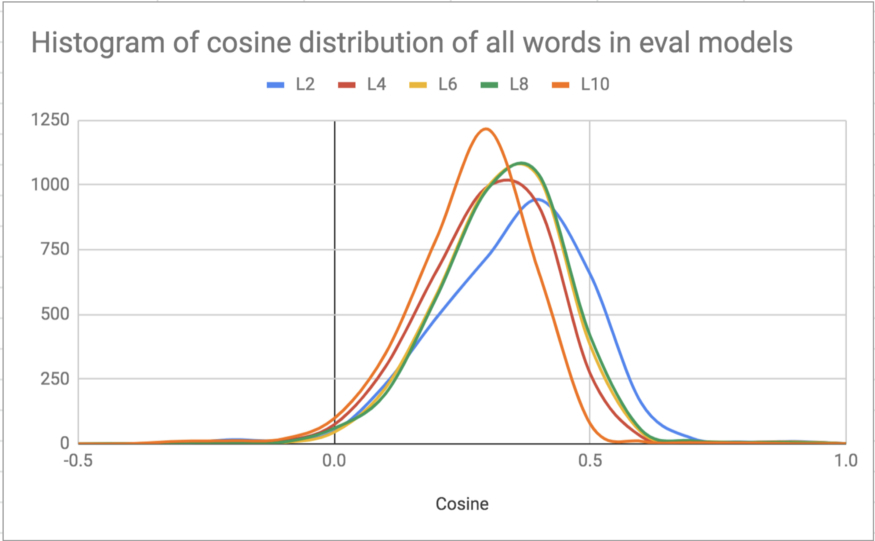
图 7:在词汇表中随机抽样约 1000 个单词的余弦分布直方图。2、4、6、8、10 层 BERT 微模型的分布。随着层数的增加,平均值向左移动,类似于从 BERT 基数(12 层)到 BERT 大模型(24 层)的均值的移动。
上面的数字并没有显示出所有 5 个评估模型的任何异常,这表明,构成 BERT 词汇的向量的训练没有明显的异常。下面针对小样本词的预先距离邻域测试进一步证实了这一点。
前期使用过的几个词汇测试术语的十大邻域
下面这两个术语在除 BERT 之外的所有评估模型的词汇表中都存在,对这两个术语的邻域测试表明,它们的邻域都相当好,即使是两个 Microsoft 预训练模型和 SciBERT。不过这三个模型在包含这些词汇的句子测试中性能不佳,这说明相对于词汇向量本身,模型层的训练不足。


图 8:前期词汇测试中使用的两个术语的前 10 个邻域。对这两个词的测试表明,这两个词都出现在除 BERT 之外的所有被评估模型的词汇表中,它们的邻域都相当不错甚至对于 Microsoft 预训练模型和 SciBERT 也是如此,然而,这三个模型在包含这些词语的句子测试中性能不佳。这说明相对于词汇向量本身,模型层的训练不足。
词汇向量聚类
此外,当检查由 Microsoft 预训练模型(摘要 + 全文)及其持续预训练版本的向量构成的聚类时,其中聚类是用固定阈值(60 degrees—.5 conine)完成的,聚类有 80% 是相同的。这进一步证实了这样一个事实:即使在原始预训练模型中,词汇向量也得到了很好的训练。需要进一步训练的是模型层。
[持续] 预训练的顺序流
下图显示了在训练和持续预训练期间最大化模型性能的顺序流。即使在模型输出一组检查点(而不是最后一个检查点)的情况下,下面的顺序也适用,并且我们评估每个检查点,如流程中所示。然而,在这种情况下,如果一个检查点未通过 MLM 检查,如果选择了较新的检查点作为候选,我们可以将其丢弃。
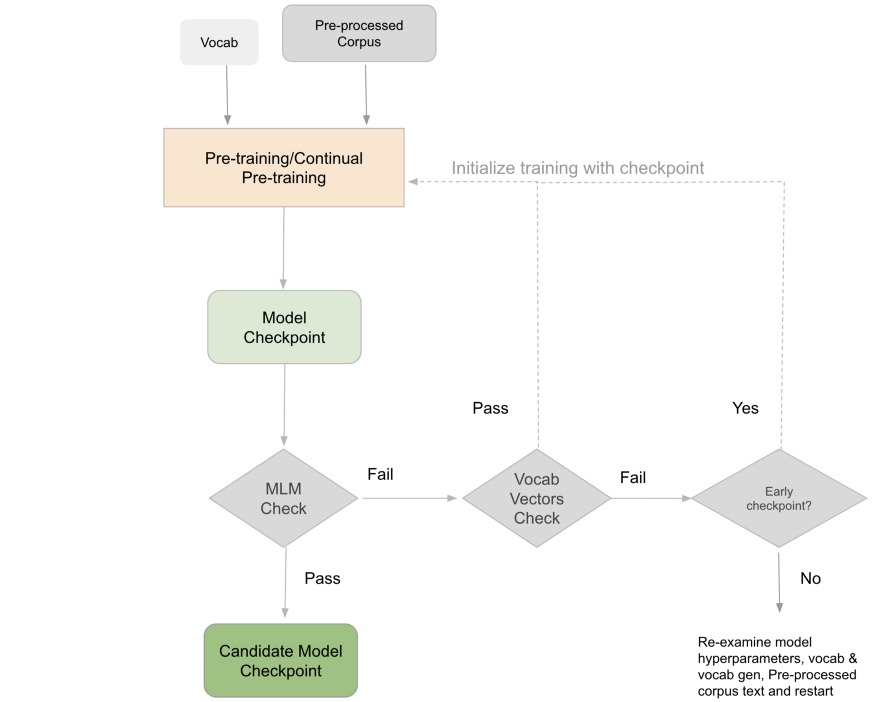
图 9:获取顺序流,以便在训练和持续预训练期间最大化模型性能。
结语
实践证明,对于从业者来说,预训练或持续预训练具有自定义词汇的领域特定语料库是关键,尤其是在使用该模型执行各种下游任务时,无论是监督还是无监督。事实证明,任何没有利用领域特定自定义词汇表的方法都会产生次优的结果,至少在生物医学领域是这样。
从从业者的角度来看,采用“填空”(MLM)的 BERT 学习方法的效用怎么强调也不为过,尽管这种学习方法限制了该模式不能称为像 GPT-2 那样的生成模式。除了有助于评价训练 BERT 模型的质量,如本文所示,当与学习的词汇向量结合使用时,“填空”的能力有助于将传统的有监督的任务转化为无监督的任务(如无监督的 NER)。
实施说明
澄清“微调”这一术语。在本文中,微调仅用于接受预训练或持续预训练的模型,然后在受监督的任务上对其进行训练的任务。
当持续预训练 / 微调 BERT 模型时,可以添加额外的领域特定的标记。这是一个有限的改进,在上面的文章没有提及,因为它没有解决原始词汇表的实体偏见问题。
在BERT 的 GitHub 页面中对推荐进行预处理是实现最大化模型性能的关键。使用HuggingFace进行预训练有一个局限性:它在训练前将整个语料库读入内存(该代码正在快速更改,因此这一问题可能很快就会解决)。这使得在没有大量内存的情况下,在大型语料库上进行预训练是不切实际的。
当使用原始 BERT 发布代码进行 [持续] 预训练时,全字掩蔽已被证明可以提高模型的性能。在创建预训练记录时需要制定此选项,而不是在预训练期间。
当使用原始 BERT 发布代码进行 [持续] 预训练时,用于创建预训练记录的序列长度需要与预训练期间使用的序列长度相同。
当使用原始 BERT 发布代码进行 [持续] 预训练时,批大小可能必须根据我们选择的序列长度来选择,并且还应由可用的 GPU 内存来驱动。
当使用原始 BERT 发布代码进行 [持续] 预训练时,即使在为特定领域进行预训练时,从像Bookcorpus这样的通用语料库添加句子也可能会有所帮助。然而,这个语料库不必是词汇生成的一部分。
当使用原始 BERT 发布代码进行 [持续] 预训练时,自定义词汇文件的生成可能最好在领域语料库的子集上完成,该子集从术语角度来看是具有代表性和清晰的。通过检查词汇向量的集群,可能会发现似乎有噪音的集群。这可能预示着词汇生成过程可能会有所改善。
下图显示了从头开始训练模型的向量分布直方图。正如人们所预料的那样,所有的向量几乎彼此正交:这得益于高维向量的随机初始化。
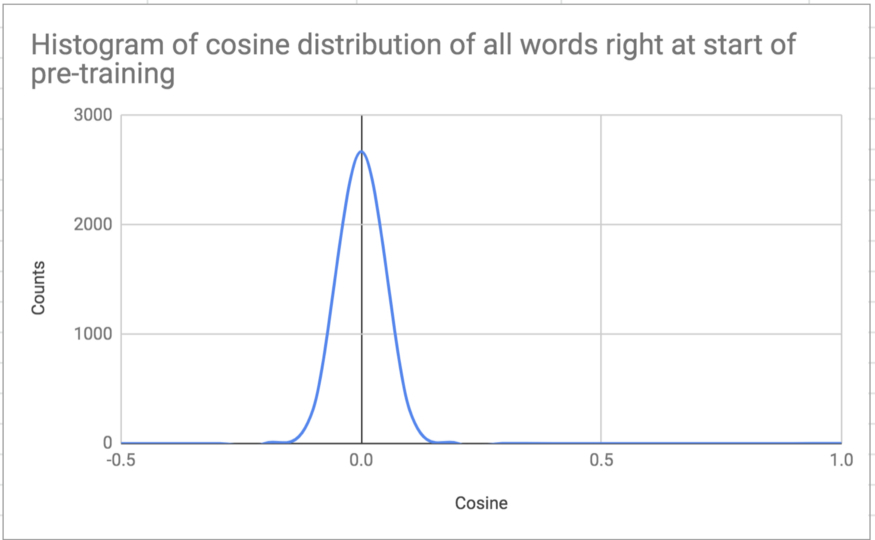
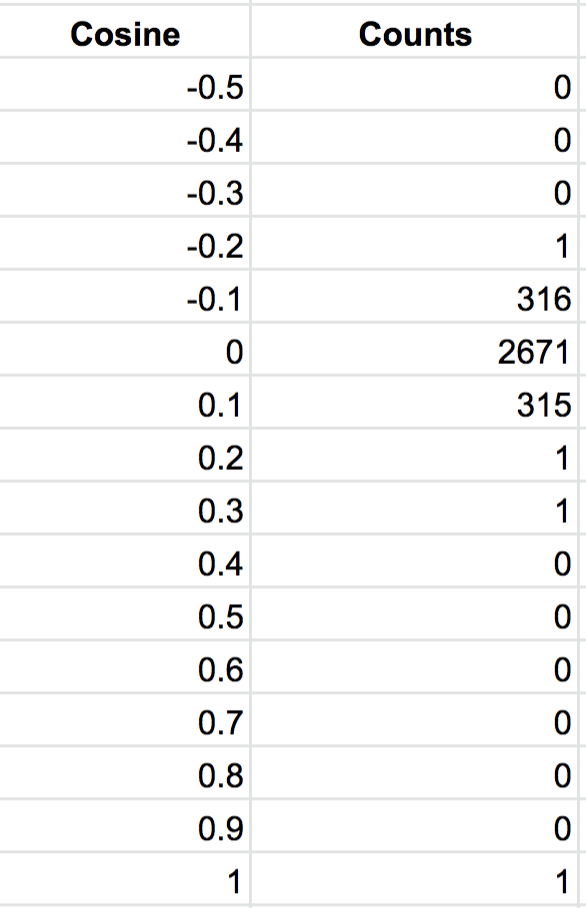
图 10:在词汇表中随机抽样约 1000 个单词的余弦分布直方图。从头开始对模型进行预训练。正如人们所预料的那样,所有向量几乎彼此正交:这得益于高维向量随机初始化。值得注意的是,所有 BERT 发布的预训练模型都有数百个正交向量,除了略高于 1000 个的全字掩蔽模型。Microsoft 预训练模型具有类似的正交向量的高计数,即使在持续预训练之后仍然如此。需要回答的问题是,这些向量在训练期间移动,然后变得接近正交,还是在训练期间根本不移动。如果事实证明它们根本没有移动,那么这可能表明词汇生成并不真正代表领域特定语料库:这个问题可以通过在真正代表整个语料库的语料库子集上重新生成词汇来解决。
作者介绍:
Ajit Rajasekharan, 机器学习从业者。
原文链接:
https://towardsdatascience.com/maximizing-bert-model-performance-539c762132ab

InfoQ高级技术编辑

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论