

小蚂蚁说:
The Web Conference 2018,即前 WWW 大会(International Conference of World Wide Web)于 4 月 23-28 日期间在法国里昂举行。蚂蚁金服的小伙伴也正位于法国前线参加本次活动。在此次大会上,蚂蚁金服也有相关论文入选。本文即蚂蚁金服人工智能团队被录用于 WWW BIG Web track(录取率 17%)的论文——Anomaly Detection with Partially Observed Anomalies 的相关分享。

异常检测是一类应用极为广泛的技术,在大量的应用实践中有着切实的需求。例如,仅就电商交易的场景而言,就存在诸如异常交易挖掘、异常用户发现等诸多问题中需要用到异常检测的相关技术。在传统的研究中,主要存在两种典型的问题情景:其一是基于完全无监督数据的异常检测;其二则是基于有监督数据的异常检测。除此之外,也存在其他的一些问题情景,例如在仅有正常样本数据情况下的异常检测问题。区别于以上种种,本文关注的是这样一种异常检测问题:在只有极少量的已知异常样本和大量的无标记数据的情况下,来进行的异常检测问题。这一场景在诸如 URL 异常检测,异常交易挖掘等问题中均可遇到,因而对于这一问题的研究处理有着切实的应用需求。
在本文,将对我们录用于 WWW BIG Web track 的论文 Anomaly Detection with Partially Observed Anomalies(作者:张雅淋,李龙飞,周俊,李小龙,周志华)进行简要说明。
问题说明
在我们的问题场景中,我们能够获得极少数的已知异常样本以及大量的无标记样本。形式化地,给定包含 m 个样本的数据集
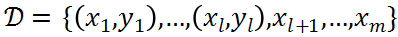
其中前 I 个样本构成的集合
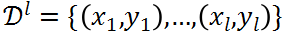
是已知的异常样本集合(本文用 y=1 来表示异常样本,y=-1 表示正常样本),而剩余的 m-I 个样本构成的集合
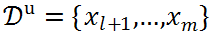
为无标记样本集合。通常情况下,I 远小于 m,即观察到的已知异常的数目是极少的。我们期望基于现有的数据学习得到模型,在未来的数据上具有着比较好的异常检测的效果。
问题分析
我们面对的问题场景与传统的基于无监督学习和监督学习的场景有着明显的差别,若简单的形式化为无监督学习而丢弃已有的部分标记信息则会带来信息的极大损失,且效果不理想;若将无标记的数据完全当作正常样本来采用监督学习的模型来处理,则会因为引入的大量噪音导致效果欠佳;若将已知异常看作是正样本,则我们面对的是基于少量正样本和大量无标记样本构建的学习模型,表面上看,这与 PU(Positive and Unlabeled)Learning 有一定的相似性,然而 PU Learning 中的正样本大多有着较高的相似性,而异常检测中的异常样本往往千差万别,这使得 PU Learning 的应用大大受限。
本文针对于这一问题提出一种“两阶段”的方法。在只有极少数目的异常样本情况下构建模型是困难的,因而本文首先试图从大量的无标记样本中挖掘潜在异常样本(potential anomalies)以及可靠正常样本(reliable normal samples);另一方面,由于异常样本之间往往具有较大的多样性,因而本文试图通过聚类将异常样本划分为不同的簇而非简单的当做一个大类来看待。下文将对方法细节进行简述。
方法介绍
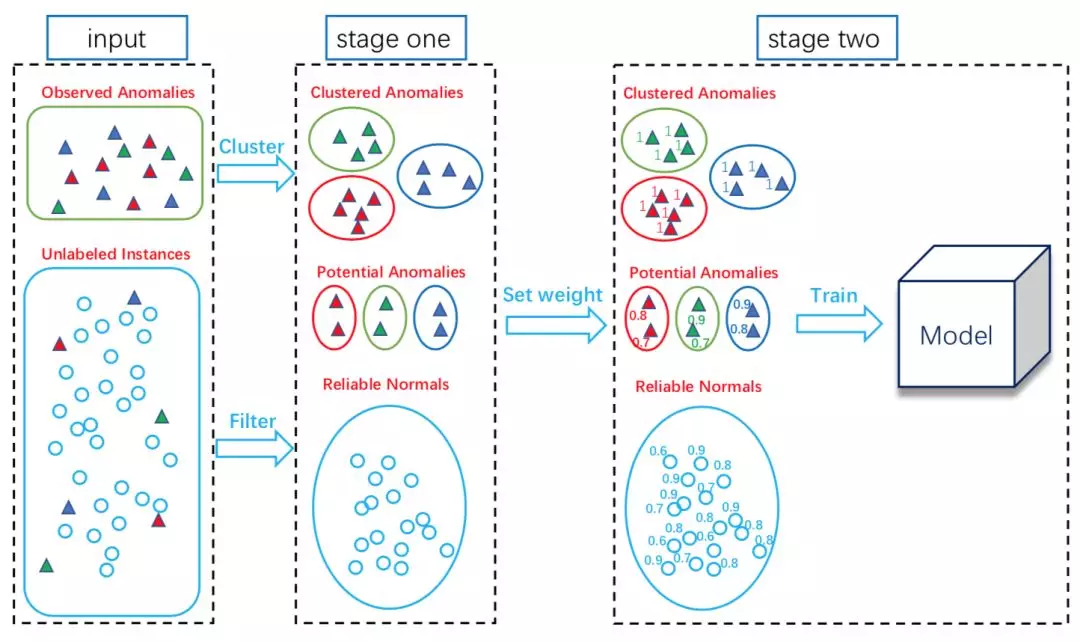
如图所示,该方法主要包括两个阶段。在第一阶段,对已知异常样本进行聚类,并从未标记样本中挖掘潜在异常样本以及可靠正常样本;第二阶段,基于以上的样本,构建带权重的多分类模型。
阶段一:
对于已知的异常样本(Observed Anomalies),因其之间可能具有较大的多样性,我们对其聚类,使得聚类后的每一簇之间具有较高的相似性,这里可以采用不同的聚类算法,本文基于广泛使用的 k-means 聚类算法来实现。
对于无标记的样本(Unlabeled Instances),我们试图从中过滤出潜在异常样本(Potential Anomalies)以及可靠正常样本(Reliable Normals)。对于异常样本而言,一方面,它有着容易被隔离(Isolation)的特点,另一方面,它往往与某些已知的异常样本有着较高的相似性。因而我们分别计算无标记样本的隔离得分(Isolation Score)和其与异常样本簇的相似得分(Similarity Score),综合二者,来得到一个样本的异常程度总体得分。具体地,我们基于著名的异常检测算法 Isolation Forest 的方法计算样本的隔离得分 IS(x):
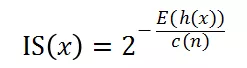
其中,c(n) = 2H(n)-(2(n-1)/n),H(n)为 harmonic number,h(x)为样本 x 在构建的完全随机树中经历的路径的长度,E(h(x))为平均长度。IS(x),意味着 x 的隔离程度越高,是异常样本的可能性越大。
为计算样本与已知异常的相似性得分 SS(x),我们首先计算得到已知异常样本聚类后的各个簇中心μi,则
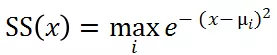
综合隔离得分 IS(x)和相似性得分 SS(x),得到每个样本的总体得分
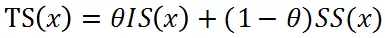
其中参数用于调节二者的影响程度。我们分别选择和的样本作为潜在异常样本(Potential Anomalies)以及可靠正常样本(Reliable Normals),其中作为参数控制过滤的严格程度,筛选出的潜在异常样本归于其最近的异常样本中心所属的类别。
如此,我们除了拥有已知的异常样本(Observed Anomalies),还过滤得到了潜在异常样本(Potential Anomalies)以及可靠正常样本(Reliable Normals)。
阶段二:
在本阶段,我们基于以上的样本构建加权多分类模型来区分不同的异常样本和正常样本。具体地,我们依据标记的置信程度进行权重的设置:令所有已知的异常样本权重为 1,对于潜在异常样本,其 TS(x)越高,则其作为异常样本的置信度越高,权重越大,即
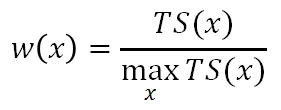
对于可靠正常样本,其 TS(x)越低,则其作为正常样本的置信度越高,权重越大,即
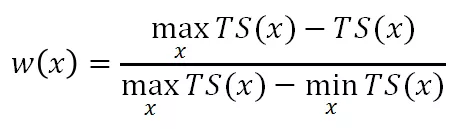
如此,我们训练一个加权的多分类模型来优化一下目标:
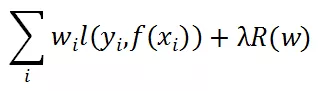
对于未来的待预测样本,通过该多分类模型预测其所属类别,若样本被分类到任何异常类,则将其视为异常样本,否则,视为正常样本。
实验结果
我们在大量数据集上进行了实验验证,并综合对比了基于无监督学习的算法、基于监督学习的算法以及基于 PU Learning 的算法来验证以上算法在我们的场景中的性能。
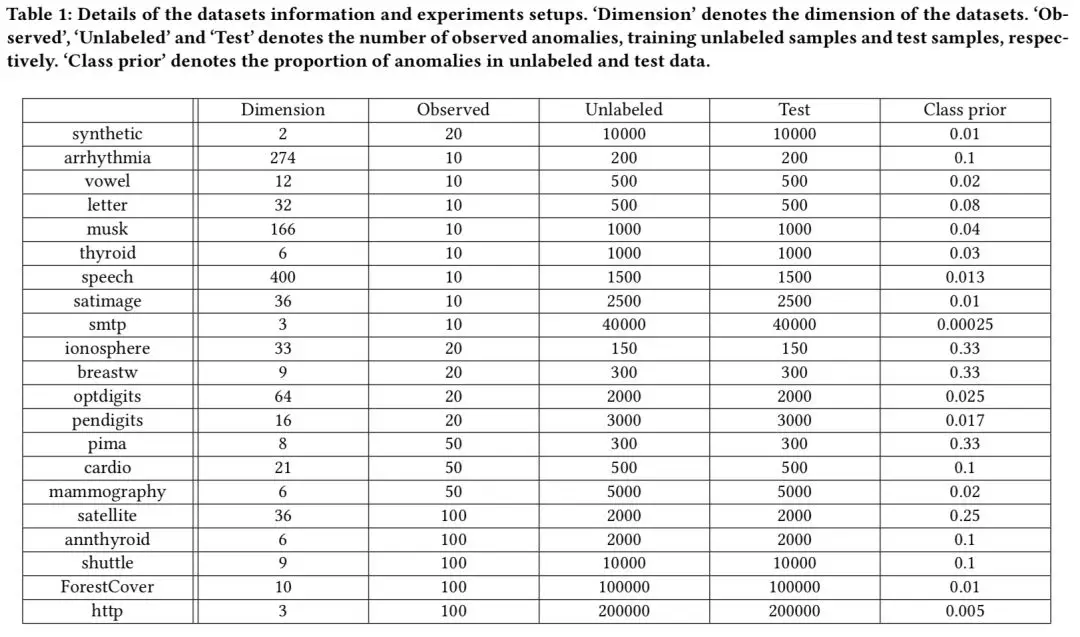
数据信息如下表所示,值得注意的是,我们的实验数据具有着较大的多样性,而数据中已知的异常样本数据是极少的。
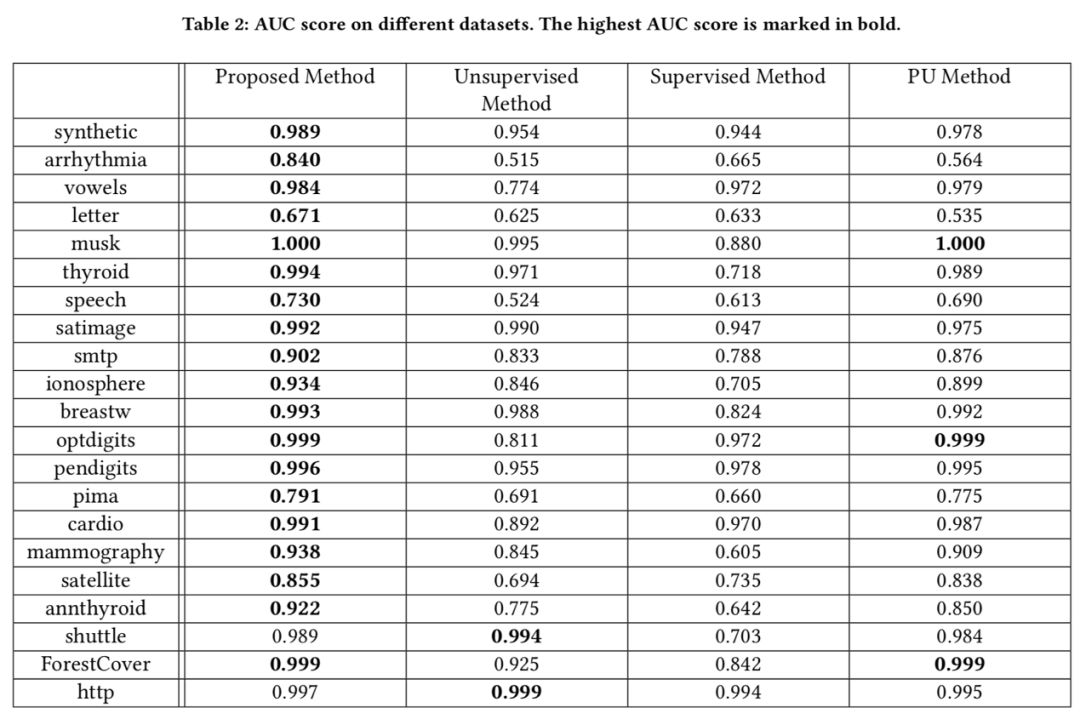
实验结果如下表所示,我们可以看到,无论是无监督还是监督学习的算法,效果都是不理想的。基于 PU Learning 的算法在某些数据上表现尚可,而在某些数据上的表现则较差。我们的方法在各个数据上均有着比较好的性能表现。
业务应用
我们将这一算法应用到 URL 攻击检测的真实应用中。对于 URL 攻击而言,常常存在诸如 XXE (XML External Entity Injection), XSS (Cross SiteScript) 以及 SQL injection 等各种不同的攻击类型,作为异常访问,其相互之间具有一定的差异,若统一对待,则可能带来不理想的效果。除此之外,我们面对的数据是大量的未标记 URL 以及少量已经检测出来的 URL 攻击,这与本文所描述的问题场景完全吻合。
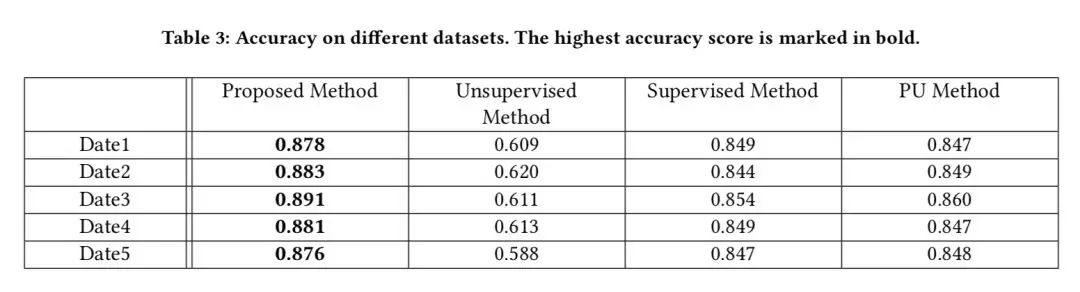
为验证不同算法的效果,我们选取了几天的 URL 访问数据来进行检测,并对打分最高的 1000 样本进行人为的判定,结果如下表所示,我们可以发现,在真实的业务场景中,这一算法同样体现出了性能上的优势,从而验证了这一算法的可靠性。
总结
本文介绍了我们针对于一种特定异常检测场景的算法,在该场景下,我们只有极少量的已打标异常样本和大量的无标记样本。我们提出的方法充分考虑了异常样本具有多样性的特点,综合兼顾样本本身的隔离性以及其与已知异常样本的相似性来进行样本的筛选,并进一步构建了加权多分类模型来对未知样本进行预测,实验结果表明我们的方法相比其他方法具有显著的性能优势。这一问题设定在很多的业务场景中均有可能遇到,因而具有切实的应用价值。
本文转载自公众号蚂蚁金服科技(ID:Ant-Techfin)。
原文链接:
https://mp.weixin.qq.com/s/b1zSonaFy7-dKoFXw9i0SQ

暂无签名

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论