Nginx (读作 Engine-X)是现在最流行的负载均衡和反向代理服务器之一。如果你是一名中小微型网站的开发运维人员,很可能像我们一样,仅 Nginx 每天就会产生上百 M 甚至数以十 G 的日志文件。如果没有出什么错误,在被 logrotate 定期分割并滚动删除以前,这些日志文件可能都不会被看上一眼。
实际上,Nginx 日志文件可以记录的信息相当丰富,而且格式可以定制,考虑到 $time\_local请求时间字段几乎必有,这是一个典型的基于文件的时间序列数据库。Nginx 日志被删除以前,或许我们可以想想,其中是否蕴含着未知的金矿等待挖掘?
请求访问分析
Nginx 中的每条记录是一个单独的请求,可能是某个页面或静态资源的访问,也可能是某个 API 的调用。通过几条简单的命令,了解一下系统的访问压力:
// 请求总数
less main.log | wc -l
1080577
// 平均每秒的请求数
less main.log | awk '{sec=substr($4,2,20);reqs++;reqsBySec[sec]++;} END{print reqs/length(reqsBySec)}'
14.0963
// 峰值每秒请求数
less main.log | awk '{sec=substr($4,2,20);requests[sec]++;} END{for(s in requests){printf("%s %s\n", requests[s],s)}}' | sort -nr | head -n 3
Page Visits Response Size Time Spent/req Moment
182 10/Apr/2016:12:53:20
161 10/Apr/2016:12:54:53
160 10/Apr/2016:10:47:23
请求总数、平均每秒请求数、峰值请求数,可以大体了解系统压力,作为系统扩容、性能及压力测试时的直接参考。查询特定的 URL,比如下单页面,了解每天的下单状况,导出 CSV 格式,或使用可视化工具,更直观地了解一段时间内的请求、下单数据:
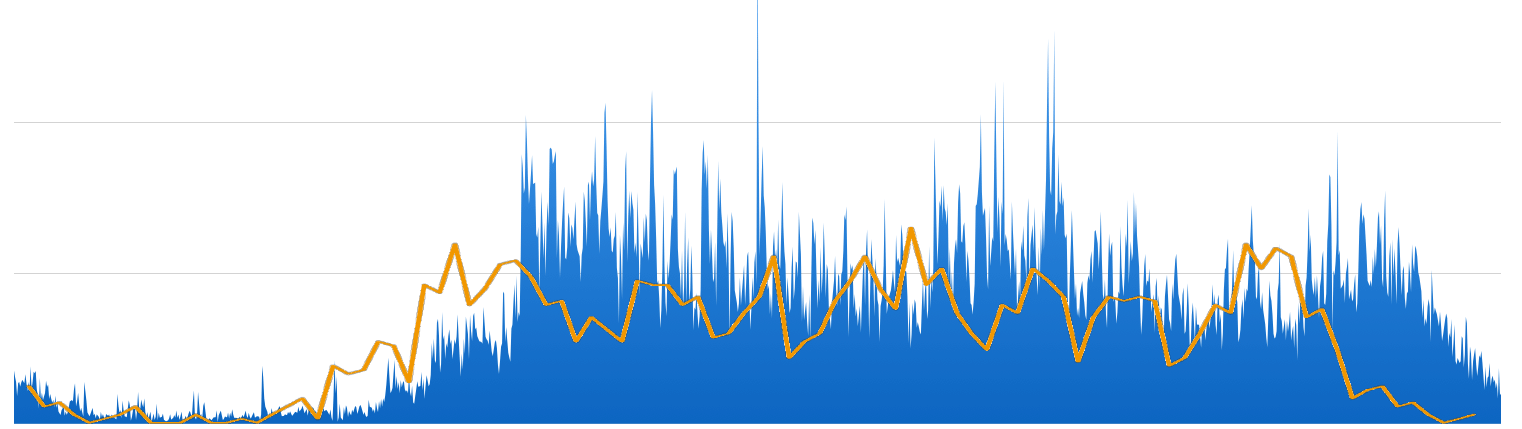
备注:本文使用 awk 命令处理,与 Nginx 日志的格式有关,如果您格式不同,请酌情修改命令。本文所用的 Nginx 日志格式:
$remote_addr - $remote_user [$time_local] "$request"
$status $body_bytes_sent $request_time $upstream_response_time
$upstream_addr "$http_referer" "$http_user_agent" "$http_x_forwarded_for"';
示例:
42.100.52.XX - - [10/Apr/2016:07:29:58 +0800] "GET /index
HTTP/1.1" 200 7206 0.092 0.092 "-" "Mozilla/5.0 (iPhone; CPU iPhone OS
7_1_2 like Mac OS X) AppleWebKit/537.51.2 (KHTML, like Gecko) Mobile/11D257" "-"
流量速率分析
Nginx 日志如果开启,除了请求时间,一般会包含响应时间、页面尺寸等字段,据此很容易计算出网络流量、速率。
等等,你可能会有疑问,上面的请求访问分析,这里的流量速率分析,按时间轴画出来,不就是监控系统干的事儿吗,何苦这么麻烦查询 Nginx 日志?
的确如此,监控系统提供了更实时、更直观的方式。而 Nginx 日志文件的原始数据,可以从不同维度分析,使用得当,会如大浪淘沙般,发现属于我们的金子。
对一般网站来说,带宽是最珍贵的资源,可能一不小心,某些资源如文件、图片就占用了大量的带宽,执行命令检查一下:
less static.log | awk 'url=$7; requests[url]++;bytes[url]+=$10}
END{for(url in requests){printf("%sMB %sKB/req %s %s\n", bytes[url] /
1024 / 1024, bytes[url] /requests[url] / 1024, requests[url], url)}}' | sort -nr | head -n 15
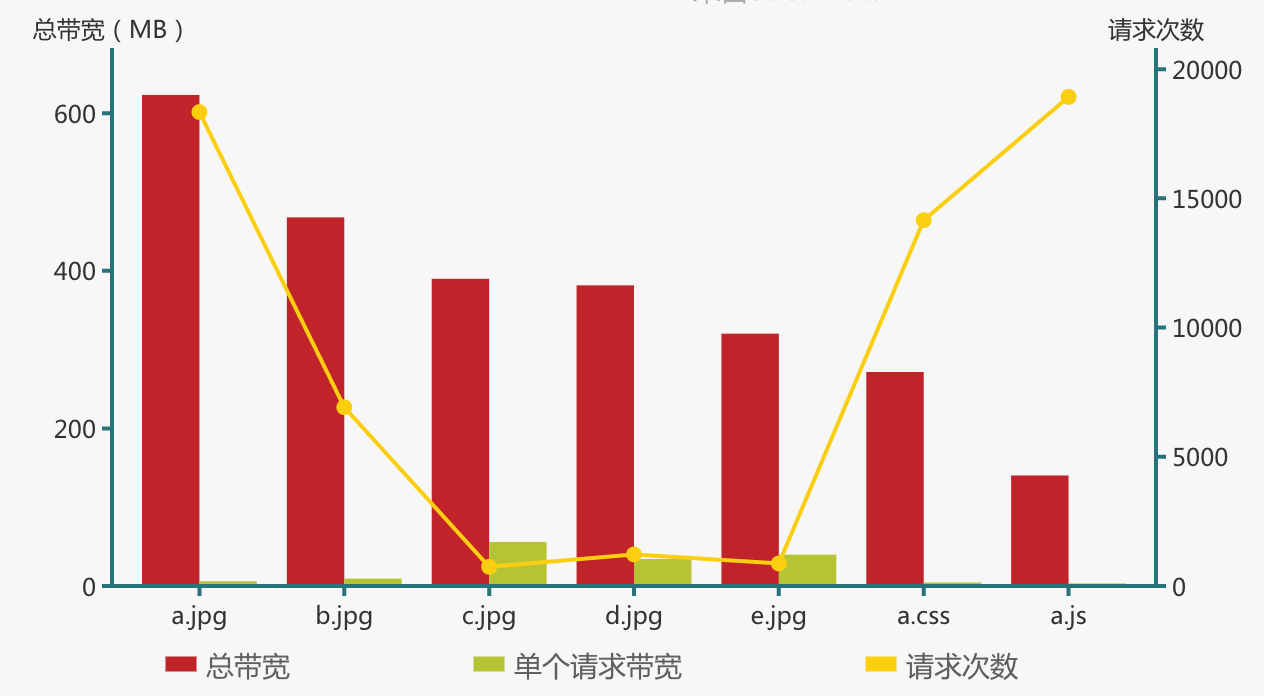
备注:Nginx 配置文件中日志格式使用了 $body_sent_size,指 HTTP 响应体的大小,如果想查看整个响应的大小,应该使用变量 $sent_size。
不出意外,静态资源、图片类(如果还没有放 CDN)占据榜首,自然也是优化的重点:是否可以再压缩,某些页面中是否可以用缩略图片代替等。
与之相比,后台调用、API 接口等通常消耗更多的 CPU 资源,按照一贯“先衡量、再优化”的思路,可以根据响应时间大体了解某个 URL 占用的 CPU 时间:
less main.log | awk '{url=$7; times[url]++} END{for(url in
times){printf("%s %s\n", times[url], url)}}' | sort -nr | more`
40404 /page/a?from=index
1074 /categories/food
572 /api/orders/1234.json
不对,发现一个问题:由于拥有服务号、App、PC 浏览器等多种前端,并且使用不规范,URL 的格式可能乱七八糟。比如/page/a页面,有的带有.html 后缀,有的未带,有的请求路径则带有参数;分类页 /categories/food 带有slug等信息;订单、详情或个人中心的 URL 路径则有ID等标记…。
借助 sed 命令,通过三个方法对 URL 格式进行归一化处理:去掉所有的参数;去掉.html及.json后缀;把数字替换为\*。可以得到更准确的统计结果,:
less main.log | awk '{print $7}' |sed -re 's/(.*)\?.*/\1/g' -e
's/(.*)\..*/\1/g' -e 's:/[0-9]+:/*:g' | awk '{requests[$1]++;time[$1]
+=$2} END{for(url in requests){printf("%smin %ss/req %s %s\n", time
[url] / 60, time[url] /requests[url], requests[url], url)}}' | sort -nr | head -n 50
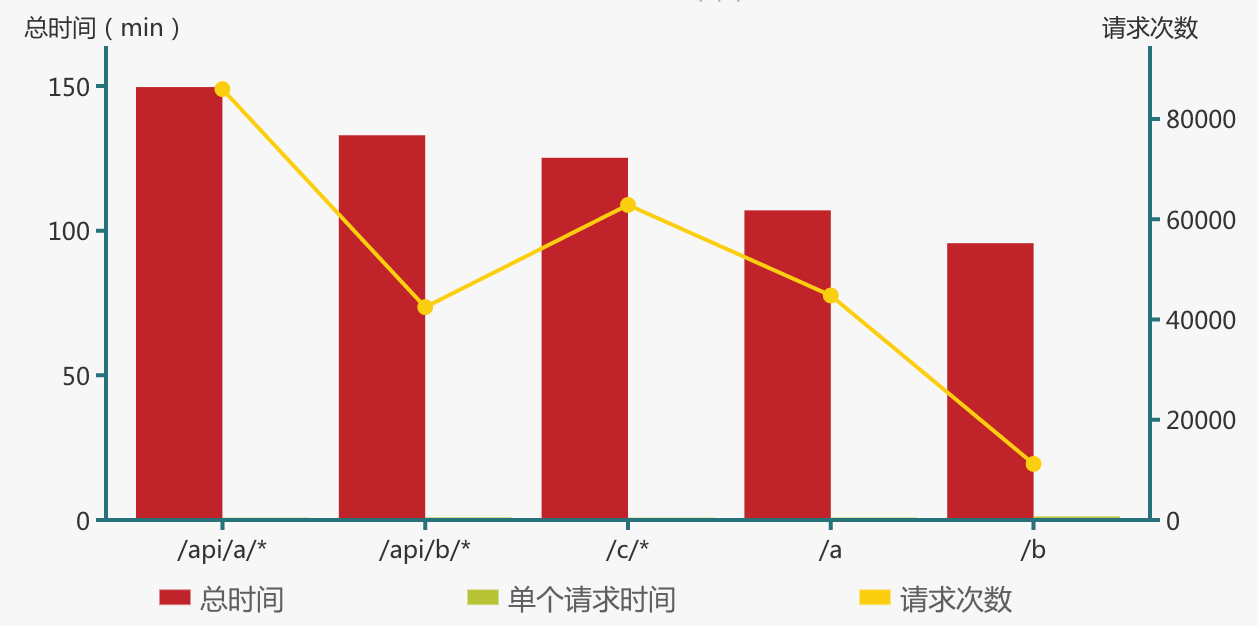
备注:这里使用了扩展正则表达式,GNU sed 的参数为 -r,BSD sed 的参数为 -E。
那些累计占用了更多响应时间的请求,通常也耗用了更多的 CPU 时间,是性能优化重点照顾的对象。
慢查询分析
“服务号刚推送了文章,有用户反映点开很慢”,你刚端起桌子上的水杯,就听到产品经理的大嗓门从办公室角落呼啸而来。“用户用的什么网络”,你一边问着,一边打开服务号亲自尝试一下。是用户网络环境不好,还是后台系统有了访问压力?是这一个用户慢,还是很多用户都慢?你一边脑子里在翻腾,一边又打开命令行去查看日志。
与 PC 浏览器相比,微信服务号在网络环境、页面渲染上有较大的掣肘,在缓存策略上也不如 APP 自如,有时会遇到诡异的问题。如果手里恰好有 Nginx 日志,能做点什么呢?
考虑一下 MySQL 数据库,可以打开慢查询功能,定期查找并优化慢查询,与此类似,Nginx 日志中的响应时间,不相当于自带慢查询功能嘛。利用这一特性,我们分步进行慢查询分析:
第一步:是不是用户的网络状况不好?根据既往的经验,如果只有少量的请求较慢,而前后其他 IP 的请求都较快,通常是用户手机或网络状况不佳引起的。最简单的方法,统计慢查询所占比例:
less main.log | awk -v limit=2 '{min=substr($4,2,17);reqs[min]
++;if($11>limit){slowReqs[min]++}} END{for(m in slowReqs){printf("%s
%s %s%s %s\n", m, slowReqs[m]/reqs[m] * 100, "%", slowReqs[m], reqs
[m])}}' | more
10/Apr/2016:12:51 0.367% 7 1905
10/Apr/2016:12:52 0.638% 12 1882
10/Apr/2016:12:53 0.548% 14 2554
慢查询所占比例极低,再根据用户手机型号、访问时间、访问页面等信息看能否定位到指定的请求,结合前后不同用户的请求,就可以确定是否用户的网络状况不好了。
第二步:是不是应用系统的瓶颈?对比应用服务器的返回时间 ($upstream_response_time 字段),与 Nginx 服务器的处理时间 ($request_time 字段),先快速排查是否某一台服务器抽风。
我们遇到过类似问题,平均响应时间 90ms,还算正常,但某台服务器明显变慢,平均响应时间达到了 200ms,影响了部分用户的访问体验。
less main.log | awk '{upServer=$13;upTime=$12;if(upServer ==
"-"){upServer="Nginx"};if(upTime == "-"){upTime=0};upTimes[upServer]
+=upTime;count[upServer]++;totalCount++;} END{for(server in upTimes)
{printf("%s %s%s %ss %s\n", count[server], count[server]/totalCount *
100, "%", upTimes[server]/count[server], server)}}' | sort -nr
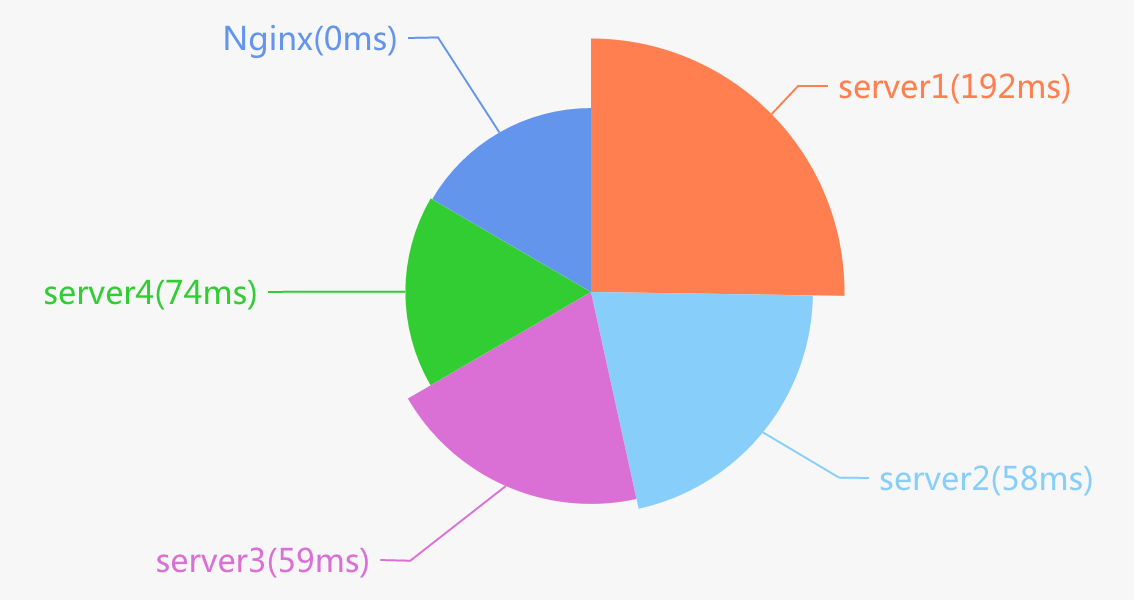
不幸,市场部此次推广活动,访问压力增大,所有服务器都在变慢,更可能是应用系统的性能达到了瓶颈。如果此时带宽都没跑满,在硬件扩容之前,考虑优化重点 API、缓存、静态化策略吧,达到一个基本的要求:“优化系统,让瓶颈落到带宽上”。
第三步:应用系统没有瓶颈,是带宽的问题?快速查看一下每秒的流量:
less main.log | awk '{second=substr($4,2,20);bytes[second]+=$10;}
END{for(s in bytes){printf("%sKB %s\n", bytes[s]/1024, s)}}' | more`
1949.95KB 10/Apr/2016:12:53:15
2819.1KB 10/Apr/2016:12:53:16
3463.64KB 10/Apr/2016:12:53:17
3419.21KB 10/Apr/2016:12:53:18
2851.37KB 10/Apr/2016:12:53:19
峰值带宽接近出口带宽最大值了,幸福的烦恼,利用前面介绍的不同 URL 的带宽统计,做定向优化,或者加带宽吧。
还能做那些优化?
SEO 团队抱怨优化了那么久,为什么页面索引量和排名上不去。打印出不同爬虫的请求频次($http_user_agent),或者查看某个特定的页面,最近有没有被爬虫爬过:
less main.log | egrep 'spider|bot' | awk '{name=$17;if(index
($15,"spider")>0){name=$15};spiders[name]++} END{for(name in spiders)
{printf("%s %s\n",spiders[name], name)}}' | sort -nr
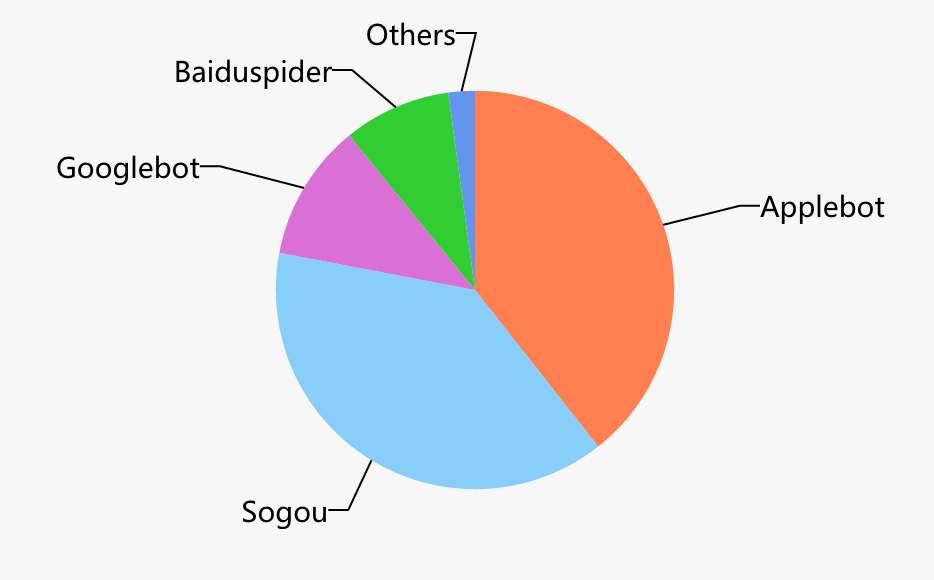
数据告诉我们,页面索引量上不去,不一定是某个爬虫未检索到页面,更多的是其他原因。
市场团队要上一个新品并且做促销活动,你建议避开周一周五,因为周三周四的转化率更高:
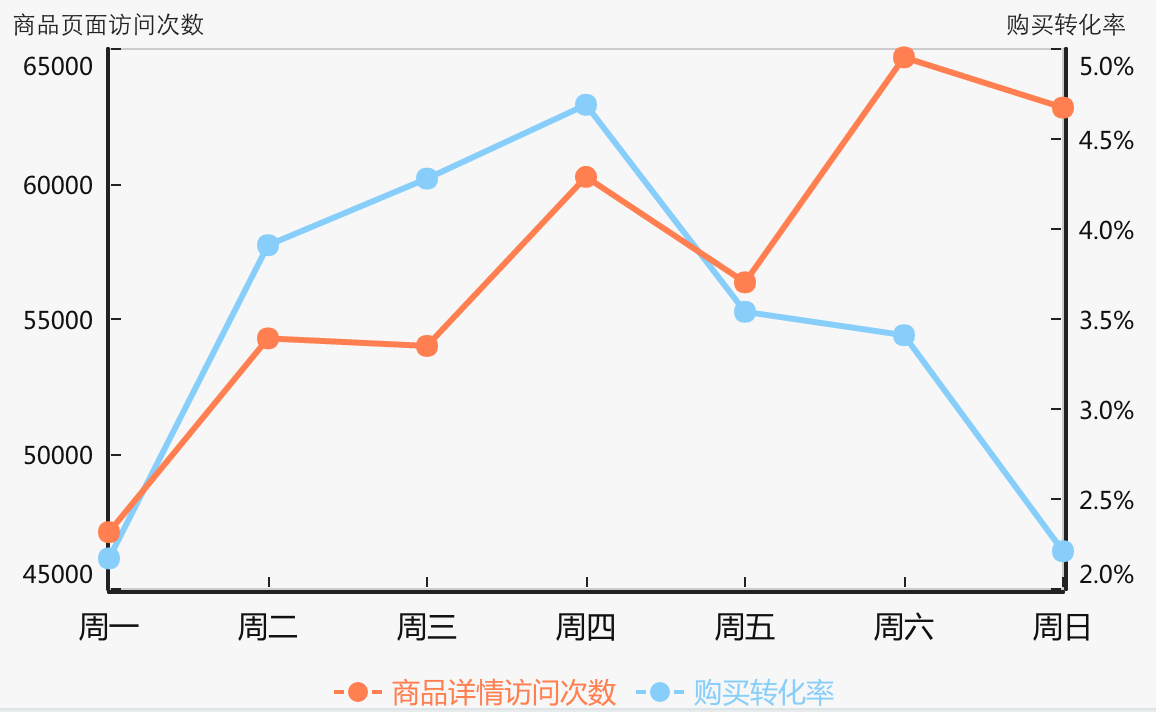
周三、周四的转换率比周末高不少,可能跟平台的发货周期有关,客户周三四下单,希望周末就能收到货,开始快乐的周末。你猜测到用户的心理和期望,连数据一起交市场品团队,期待更好地改善。
这样的例子可以有很多。事实上,上述分析限于 Nginx 日志,如果有系统日志,并且日志格式定义良好,可以做的事情远不止于此:这是一个时间序列数据库,可以查询 IT 系统的运行情况,可以分析营销活动的效果,也可以预测业务数据的趋势;这是一个比较小但够用的大数据源,运用你学会的大数据分析方法,也可以像滴滴那样,分并预测不同天气、时间段下不同地区的车辆供需,并作出优化。
几点建议
-
规范日志格式。这是很多团队容易忽略的地方,有时候多一个空格会让日志分析的复杂度大为增加。
-
无论如何,使用时间戳字段。以时间序列的方式看待日志文件,这也是很多公司把系统日志直接写入到时间序列数据库的原因;
-
如有可能,记录以下字段:用户(或者客户端)标识、单次请求标识、应用标识(如果单次请求会走到多个应用)。能够方便地查出用户链路、请求链路,是排查错误请求、分析用户行为的基础;
-
关注写的操作。就像业务建模时,需要特别关注具有时标性、状态会发生改变的模型一样,任何写的操作,都应记录到日志系统中。万一某个业务出错,不但可以通过业务模型复演,也可以通过日志系统复演。
-
规范 URL 格式。这一点同样容易遭到忽略,商品详情页面要不要添加"?from=XXX"来源参数?支付页面采用路径标记“payment/alipay”,还是参数标记“/payment?type=alipay”更合适?区别细微但影响不可忽略。
技术团队应该像对待协议一样对待这些规范。仔细定义并严格遵守,相当于拿到了金矿的钥匙。
还需要寻找一个合适的日志分析工具,基于 Python、Go、Lua,都有免费的日志分析工具可供使用;想更轻量,准备几条常用的 shell 脚本,比如作者整理了一些到 GitHub 的这个项目上;或者基于 ELK 技术栈,把 Nginx 访问日志、业务日志统一存储,并通过 Kibana 进行不同维度的聚合分析,都是不错的办法。
或许你早就使用 Nginx 日志了,你是怎么使用的,有什么好的方法呢,欢迎一起交流。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




