NetKernel 是一个软件系统,它将 REST 和 Unix 的基本属性组装成一个叫做面向资源计算(resource oriented computing,ROC)的强大的抽象集。面向资源计算的核心是将信息(资源)的逻辑请求与传递请求的物理机制(代码)相分离。与其他方式相比,使用 ROC 构建的应用已被证明是小巧的、简单的、灵活的,并且无需太多代码。
Hello World!
在面向资源的系统中,我们对资源发出请求,然后系统将具体的、不变的资源表示返回给我们。这遵循 REST 和万维网(World Wide Web)的原理。在 web 中对形如 http://www.1060research.com 这样的资源的请求会被域名服务器(DNS)解析为对某个 IP 地址端点的请求。然后请求被发到该 IP 地址,最后由 web 服务器将该资源具体的、不变的资源表示,以响应的形式发送回来。在 NetKernel 中与此类似,请求被解析为对某个 _Accessor_ 端点的请求,该 _Accessor_ 负责将具体不变的资源表示返回。NetKernel 是用 Java 实现的,因此我们将用 Java 来完成第一个例子,但是要知道除了 Java,NetKernel 还支持很多其他语言。
由 Accessor 的 processRequest 方法来处理请求。下面的例子生成一个不变的 StringAspect 对象,该对象包含一个“Hello World”消息并在响应中将其返回。
public void processRequest(INKFConvenienceHelper context) throws Exception<br></br> { IURAspect aspect = new StringAspect("Hello World");<br></br> INKFResponse response = context.createResponseFrom(aspect);<br></br> context.setResponse(response);<br></br> }context 对象是 microkernel 的一个接口,在逻辑请求与具体代码之间架起了一座桥梁。当逻辑请求的 URI 被解析为对某个端点的请求时就会触发 processRequest 方法。我们只能从 Web 请求 Java Servlet,而访问 NetKernel accessors 的请求可以来自任何地方,甚至其他端点。
当 Servlet 需要其他信息时,例如使用 JDBC 访问数据库,它会引用其他 Java 对象,这样调用堆栈就会变得很深。这正是 ROC 擅长而 Web 不足的地方。内存中 Accessors 没有对其他 accessors 的引用。它们通过发送子请求来访问逻辑资源地址空间,以获得其他服务。
在 NetKernel 中资源由 URI 地址来标识,正如万维网那样。
现在让我们暂时不考虑 Java 对象的实现,而是先来看看如何定义 URI 地址以及如何将其绑定到代码上。NetKernel 是一个模块化的架构。软件资源可以被打包到叫做模块(modules)的物理容器中。同时作为一个可以独立部署的包,模块也定义了资源的逻辑地址空间以及它们与代码之间的关系。模块可以看作是软件的一个完全自我包含的微型万维网(micro-world-wide-web)。下面的模块定义将逻辑地址“ffcpl:/helloworld”映射到 accessor,即 HelloWorld 对象。
<ura><br></br> <match>ffcpl:/helloworld</match><br></br> <class>org.ten60.netkernel.tutorial.HelloWorld</class><br></br> </ura>请求与端点的绑定只发生在请求解析的时候。一旦访问完毕,关系就被解耦了。这不同于 Java 和其它语言,在这些语言中绑定将是持久的。这种动态逻辑绑定使得系统非常灵活,可以在运行时重新进行配置。
在逻辑地址空间我们拥有了更大的自由。我们可以如下方式来映射请求:逻辑到逻辑、逻辑到物理(如上所述)以及一个地址空间到另一个地址空间。下面的重写规则说明了我们可以使用正则表达式来改变请求的 URI:该规则的结果是将请求“ffcpl:/tutorial/helloworld”映射为“ffcpl:/helloworld”。
<rewrite><br></br> <from>ffcpl:/tutorial/(.*)</from><br></br> <to>ffcpl:/$1</to><br></br> </rewrite>模块就是一个封装的、私有的逻辑地址空间。模块可以导出一个公有地址空间,其他模块可以导入该公有地址空间。在我们的例子中,模块导出了公有地址空间“ffcpl:/tutorial/.*”,开放了位于 tutorial 路径下的所有资源。
<export><br></br> <uri>ffcpl:/tutorial/(.*)</uri><br></br> </export>目前为止我们还没考虑请求从何处而来。没有请求系统就什么都不会做。传送器(transport)是一个事件检测端点(检测外部事件)。当它检测到事件时它会在逻辑地址空间中产生一个根请求,准备定位、绑定、调度端点以处理该请求和返回其表示。一个模块可以容纳无数个传送器,每个传送器会将其根请求注入到模块中。例如,HTTP 传送器检测 HTTP 请求,然后生成相应的内部 NetKernel 根请求。下图说明了 HTTP 请求如何转化为 NetKernel 请求并到达 HelloWorld 访问类。
http://localhost:8080/tutorial/helloworld (at the transport)<br></br> |<br></br> v<br></br> ffcpl:/tutorial/helloworld (request issued by transport)<br></br> |<br></br> v<br></br> ffcpl:/tutorial/helloworld (request that enters our module)<br></br> |<br></br> v<br></br> ffcpl:/helloworld (after rewrite rule)<br></br> |<br></br> v<br></br> org.ten60.netkernel.tutorial.HelloWorld (Physical Accessor code)系统并没有规定对 Hello World 资源的请求是如何产生的。它的地址空间可以同时连接到 HTTP、JMS、SMTP、LDAP 等等。只要你能想得出,无论是外部应用协议还是软件架构的其他层,它都能连上。NetKernel 中每个模块都是一个自包含的、封装的、面向资源的子系统。
地址和地址空间
在 NetKernel 中一个模块定义了一个私有地址空间。在私有地址空间中只能发生三件事:
- 将逻辑地址映射为逻辑地址
- 将逻辑地址映射为物理端点
- 从其他模块中导入逻辑地址空间
通过这三个转换关系我们就可以获得清晰的层次结构以及良好的架构。因为转换关系是动态的,所以架构本身也是动态组合的。下图从高层次的视角展现了一个典型的 NetKernel 应用。首先转换器在模块的私有地址空间产生根请求,然后 NetKernel 寻找处理该请求的端点。在我们的例子中模块导入了“A”、“B”和“C”。每一个都将其公有地址空间导出到模块的私有地址空间中,分别如下:ffcpl:/accounting/.*,ffcpl:/payroll/.*以及ffcpl:/crm/.*。
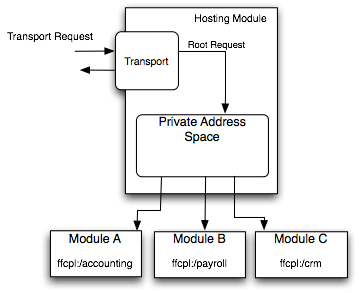
在该例中如果针对 URI ffcpl:/crm/contacts 的根请求产生了,它将匹配模块“C”的导出地址空间,然后请求就会被转发到该模块,最后由处理 ffcpl:/crm/contacts 请求的实际代码接管,可能在模块“C”的范围内由实际对象比如 JDBC 连接或者对关系数据库的请求来进行实际的处理。
访问器(Accessors)
下面我们回到物理层来仔细看看访问器。正如我们所知,访问器是返回资源表示的端点。访问器本身是非常简单的。它们只能做四件事:
- 解释被请求的资源是什么(通过检查初始的请求)
- 为附加信息创建和发送子请求(作为同步或者异步请求)
- 通过执行服务来创建值
- 创建和返回一个不可变的物理资源表示
访问器从其上下文中寻找它要做的事情。我们可以获得请求的 URI 以及参数的名值对。如果多个地址匹配同一个端点的话,访问器需要知道当前请求使用的 URI 是什么。通过逻辑 / 物理的分离,同样的代码可以有多个逻辑地址与其匹配。
使用 active:URI 模式可以调用带有命名参数的服务。active 模式如下:
active:{service-name}+{parameter-name}@{uri-address}每个 active URI 指定了一个服务以及任意数量的命名参数。例如,toUpper 服务带有一个叫做 operand 的参数,并且返回参数 URI 所表示的资源的大写形式。
active:toUpper+operand@ffcpl:/resources/message.txt下面的 BeanShell 脚本实现了 toUpper 服务。它通过 URI this:param:operand,利用方法 sourceAspect 获得了“operand”资源的不变的方面。我们可以使用上下文对象来获得调用的请求,寻找命名参数“operand”,获得其 URI 并对该资源发出一个子请求。相反,NetKernel API 提供一个局部的内部逻辑地址空间来处理请求参数。通过请求 URI this:param:operand,我们就可以不再引用 operand 指针。
import org.ten60.netkernel.layer1.representation.*;<br></br> import com.ten60.netkernel.urii.aspect.*;<p> void main()</p><br></br> {<br></br> sa=context.sourceAspect("this:param:operand",IAspectString.class);<br></br> s=sa.getString();<br></br> sa=new StringAspect(s.toUpperCase());<br></br> resp=context.createResponseFrom(sa);<br></br> resp.setMimeType("text/plain");<br></br> context.setResponse(resp);<br></br> }脚本指定它期望 operand 资源作为 IAspectString 接口的实现来返回。然而在逻辑层,代码并不知道物理层类型。这就产生了一个新的概念:透明表示(transrepresentation)。如果客户端请求了端点并未提供的表示类型,那么微核就可以起到媒介的作用。当发现不匹配时,微核就会去寻找 _Transreptor_,它会从一种类型转为另一种类型。
Transreptors 非常有用。从概念上讲,一个 transreptor 将信息从一种物理形式转化为另一种。这涵盖了大量的计算机处理,包括:
- 对象类型转化
- 对象结构转化
- 解析
- 编译
- 序列化
关键的是这是一种无损转化,物理表示在改变时,信息是不变的。Transreptors 通过对逻辑层隐藏了物理层的细节,来降低复杂性以此让开发者把精力集中在最重要的东西 — 信息。例如,active:xslt 服务请求 DOM 信息,处理逻辑层的开发者提供了资源的引用,该资源在物理层的表示是一个包含 XML 的文本文件。NetKernel 会自动地寻找 transreptor,它会将文本式的 XML 转化为 DOM 形式。transreption 的架构和设计的重要意义在于类型的解耦,以及提高应用和系统的灵活度。
此外,transreption 可以让系统将信息从低效形式转化为高效可处理的形式,例如,将源代码转化为字节码。这些转化是很频繁的,然而其转化代价却是一次性的,之后就可以以有效形式获取。从某种意义上说,transreption 移除了资源的熵。
资源模型
我们已经知道了一个逻辑层的 URI 地址是如何被解析为物理层端点以及开始处理时是如何绑定的。我们知道物理层比较关心像将类型隔离于物理层中的这类事情。我们还知道可以调用带有命名参数的服务,这些参数都被编码为 URI 地址。
这导致了资源模型想法的产生,它是物理资源表示类型(对象模式)与相关服务(访问器)的集合,它们共同提供了围绕着特定信息形式的工具集,例如:字节流、XML 文档、RDF 图、SQL 语句及结果集、图像、JMS 消息和 SOAP 消息等等。资源模型的想法使得开发者可以以资源模型组合的方式来构建组合应用,这反映了 Unix 的哲学:通过快速组合特定的可重用的工具来提供解决方案。
图像资源模型包含如下服务:imageCrop、imageRotate 以及``imageDither 等等。通过使用图像资源模型,开发者可以创建图像处理管道,例如下面简单的请求:
active:imageCrop+operator@ffcpl:/crop.xml+operand@http://1060research.com/images/logo.pngNetKernel 的 XML 资源模型包含了转换语言,几个验证语言和很多其他 XML 技术。在这之上,是一个特殊的 XML 资源模型 PiNKY,它是一个种子处理工具,支持 ATOM,RSS 以及很多简单的种子操作,并且它与 XML 资源模型是 100% 向下兼容的。通过使用 transreptors,开发者无需知道 XML 资源在物理上是 DOM,SAX 流还是其他类型。开发者可以通过 XML 资源模型来快速构建 XML 处理系统。下面的请求通过 XSLT 服务并使用样式资源 ffcpl:/style.xsl 来转化资源 ffcpl:/data.xml:
active:xslt+operator@ffcpl:/style.xsl+operand@ffcpl:/data.xml## 序列化
资源请求 URI 对于面向资源的计算模型来说本质上是“操作码”。就像 Java 字节码一样,它们太底层了以至于很难手工编码。我们可以利用很多脚本语言来定义和处理这些请求。之前我们了解的上下文对象 context 就是一个统一的 POSIX 的例子,就像是被称作 NetKernel 基础 API 的微核的抽象。该 API 对于所有受支持的动态过程式语言都适用。此外,还提供了专家声明式语言,其目的是单独定义和处理请求。
DPML 就是这样一个脚本语言,一个使用 XML 语法的简单语言。为什么使用 XML 语法呢?因为在一个动态松耦合的系统中,代码也是一种资源,而处理这种动态产生的代码非常直接。对于代码生成来说,XML 语法有非常简单的输出格式。拥有了 DPML,下面的指令可以请求同样的 XSLT 转化(与之前介绍的一样),每个“instr”相应于一个 active: URI 请求,而每个“target”是对另一个资源的转接。URI this:response 作为一个约定用以表示由该脚本返回的资源。
<instr><br></br> <type>xslt</type><br></br> <operator>ffcpl:/style.xsl</operator><br></br> <operand>ffcpl:/data.xml</operand><br></br> <target>this:response</target><br></br> </instr>有了这个基础就很容易解释下面的 DPML 程序了,该程序通过两个请求从数据库中创建一个 HTML 页面:
<idoc><br></br> <instr><br></br> <type>sqlQuery</type><br></br> <operand><sql>SELECT * from customers;</sql></operand><br></br> <target>var:result</target><br></br> </instr><br></br> <instr><br></br> <type>xslt</type><br></br> <operand>var:result</operand><br></br> <operator>ffcpl:/stylepage.xsl</operator><br></br> <target>this:response</target><br></br> </instr><br></br> </idoc>在 NetKernel 中,语言运行时就是服务。像其他服务一样,它们是无状态的,当程序代码根据状态转化时,它们就会执行程序。在物理层上,这与传统的软件视角的差异是相当明显的,因为传统上语言位于信息前端而不是扮演着访问信息的便利角色。例如,下面的请求提供了资源 ffcpl:/myprogram.gy 来使用 Groovy 语言的运行服务,同时该资源还包含了保持请求状态的程序。
active:groovy+operator@ffcpl:/myprogram.gyNetKernel 支持很多语言,包括:BeanShell、Groovy、Ruby、JavaScript、Python、DPML XML 如 XQuery 以及动态编译的 Java 语言。运行于 Java 虚拟机上的任何语言都可以集成到 NetKernel 中,包括像工作流引擎这样的客户化语言。
模式
ROC 展示了在逻辑层上一种新的架构设计模式。让我们看两个例子:Mapper 和 GateKeeper。
Mapper 模式特点如下:将无限的资源请求转向一个单独的物理节点。在该模式下,对一个空间资源的请求被映射到物理节点,该节点解释并重新发出每个请求到与其对应的地址空间中。mapper 将第二个请求的响应作为第一个请求的结果。
该模式有很多变量,一个叫做 active:mapper 的服务使用了一个包含地址空间之间的路由映射的资源。Gatekeeper 用来对进入地址空间的请求提供访问控制。Gatekeeper 只会允许验证通过的请求进入。
Mapper 模式的所有变量可以透明的加在任何应用的地址空间上。该模式的其他用途包括审计、日志、语义与结构验证以及其他适当的约束。该模式另一个优点是在对现有架构设计不产生影响的情况下集成到应用中。因为 NetKernel 中软件之间的关系是逻辑链接与动态解析的,对请求的拦截与转换完全是自然的。逻辑地址空间以统一的方式展现了物理层技术的所有特性,例如 AOP。
应用部署
使用 ROC 构建应用是直接的。如果需要新的物理层能力,比如新的资源模型,那么必要的访问器、transreptors 等等就会构建起来。然后在逻辑层,通过认证和聚集资源来组合应用。最后会加进如请求验证、安全 GateKeepers 与数据校验等约束。
ROC 的三 C——construct,compose,constrain 是按照先后顺序加进来的。该顺序可以颠倒——我们可以得到约束然后对它进行改变,随后该约束会重新起作用。这不同于面向对象编程,我们需要一开始就考虑约束——类一开始就会对它们的对象以及它们包含的信息加上约束。物理的面向对象的系统中信息结构的变化会产生一些事件——重新编译,分发以及系统重启等,在 NetKernel 系统中这一切都不需要了。与逻辑层系统的灵活性相比,物理层的面向对象的系统显得有些脆弱。
应用架构
采用物理层技术设计的系统通常依赖于驻留在架构不同层次上的可变对象。例如,像 Hibernate 这样的对象关系映射技术用于创建一个对象层,其状态与 RDBMS 管理的持久存储保持一致。在这样的设计中,更新被应用到了对象上,映射层的职责就是将这种变化反映到关系数据库中。
在 ROC 下,所有的表示都是不可变的。这直接产生了两种架构——首先,不可变对象的缓存能极大地改善性能(后面还会介绍这一点);其次,不可变对象是无法更新的——它们需要被标识为无效后重新被请求。
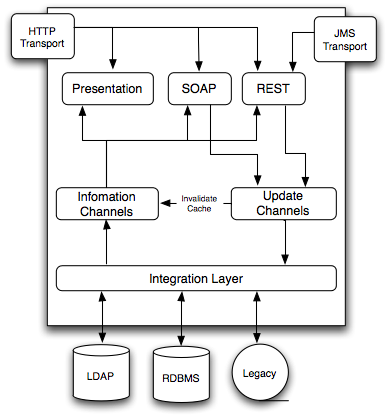
ROC 可以实现很多应用架构,我们常看到的数据通道方式(data channels approach )就是其中一种。在这种设计中,应用由逻辑层地址空间组成,对应用信息分离的读写通道垂直地穿过这些层。这些通道有形如 ffcpl:/customers or ffcpl:/register-user 这样的地址。
在下图中,集成层将不同来源的信息格式转化为通用的结构。读信息通道支持形如 ffcpl:/customers 这样的资源,该资源会返回请求信息的表示。在写通道中,URI 解决了像ffcpl:/register-user 这样的服务两件事情:首先它们更新持久存储,然后将缓存过的依赖于更新信息的资源表示置为无效。对于习惯于对象关系映射方式(如 Hibernate)的开发者来说,这显得非常奇怪。事实上,这是一个简单、优雅且高性能的解决方案。
性能
现在你一定在想 ROC 系统将大量时间花在了抽象上,却没有做多少实质性的工作。然而,与恰恰直觉相反,ROC 抽象会产生巨大的性能优势。
缓存
既然每个资源都由一个 URI 地址来标识,并且对资源的请求结果是一个不可变的表示,那么使用 URI 地址作为缓存键,就可以缓存任何可计算的资源。除了可计算的资源外,NetKernel 的缓存还存储了资源依赖和计算每个缓存点所需代价的元信息。借助于依赖信息,缓存可以保证只要被缓存的资源所依赖的其他资源是有效的,那么它就一定是有效的。如果一个资源变为无效,那么它所缓存的表示和所有依赖的资源表示就会自动变为无效。
NetKernel 使用其保存的计算代价信息来决定如何保持资源的最优化——通过资源使用的频率以及重新加入缓存的计算代价。NetKernel 缓存的操作结果就是从系统层面上消除冗余。经验表明在通常的商业应用中有 30% 到 50% 的资源请求可以从缓存中得到响应。在一个基本上只读的应用中,如果给动态系统以假的静态性能,这个数字几乎可以达到 100%。此外,当系统的负载随着时间而变化时,缓存也会重新计算以保留最有价值的资源。
对 CPU 的负载平衡
正如在简介中所介绍的,ROC 的本质就是将逻辑信息的处理与物理实现相分离。对逻辑资源的每个请求最终都会由实际的线程来执行。实现 ROC 系统的微核可以优化调度硬件,因为它会重复调度可用的线程去处理每个逻辑请求。本质上,逻辑信息系统会跨越多个 CPU 来进行负载平衡。
异步性
ROC 天生就是异步的。NetKernel 基础 API 提供了一个非常清晰的同步模型,然而实际上微核在内部以异步方式调度所有请求。因此开发者可以用很清晰的顺序同步代码来思考,并且可以跨越多核架构来度量应用。此外,我们可以显式地将访问器标识为是否线程安全,向微核发出是否可以调度并发请求的信号。可以集成第三方库而不必担心不可预知的结果。
总结
NetKernel 从根本上来说是与众不同的。它的目的不是创造另一种技术,而是利用核心原则(指的是 Web,Unix 以及集合论)的一个简单集合来将它们放到一个一致的信息处理系统中。事实上,NetKernel 起源于这个问题“Web 的经济属性能否转化为软件系统细粒度的本性?”。
从 Hewlett Packard 实验室诞生之日起,到如今的企业架构,甚至是作为关键 web 基础设施(Purl.org)的下一代平台,NetKernel 在经过将近 8 年的时间后已经变得很强壮了。NetKernel 已被证明是完全通用的并且可容易地应用到数据集成、消息处理以及 web/email 等 Internet 应用中。
参考
- 1060 研究
- 关于面向资源计算的白皮书: http://www.1060research.com/netkernel/whitepapers/
- NetKernel下载
查看英文原文: Introduction to NetKernel
译者简介:张龙,同济大学软件工程硕士,现就职于理光软件研究所。主要从事文档工作流和办公自动化解决方案的研发工作。热衷于 Java 轻量级框架的研究,对敏捷方法很感兴趣。曾有若干年的 J2EE 培训讲师经历。参与 InfoQ 中文站内容建设,请邮件至 china-editorial[at]infoq.com 。




