最近几年,SOA 获得了巨大进步。它由软件爱好者的实验性实现走向了今天 IT 的主流。这一进步背后的一个主要驱动力就是对服务接口背后现有企业 IT 资产的合理运用和虚拟化能力,而这一能力又是与企业业务模型和当下及今后的企业流程高度对齐的。此外,通过引入企业服务总线实现了 SOA 的进步,而它正是一个虚拟化服务基础设施的模式。通过利用仲裁、服务位置解析、服务水平协议(SLA)支持等,ESB 允许软件架构师显著地简化服务基础设施。整个 SOA 中所缺失的最后一个环节就是企业数据访问。文献 [1,2] 引入了针对该问题的一个可行性解决方案,企业数据总线(EDB 一种统一访问企业数据的模式)。EDB 为 SOA 虚拟化加入了第三维度,这使得 SOA 虚拟化可以被分解成:
- 服务:IT 资产的虚拟化;
- ESB:企业服务访问的虚拟化;
- EDB:企业数据访问的虚拟化;
在其它 SOA 开发中,一些文章 [3,4,5] 建议使用网格技术来增进 SOA 实现的可伸缩性、高可用性和吞吐量。在这篇文章中,我将讨论如何把网格运用到整体的 SOA 架构中,并介绍一种在服务实现中利用网格的编程模型。我同时还会讨论一个支持这一架构提议的实验性网格实现。
包含 EDB 的 SOA——整体架构
按照 [1,2],带 EDB 的 SOA 整体架构如图 1 所示
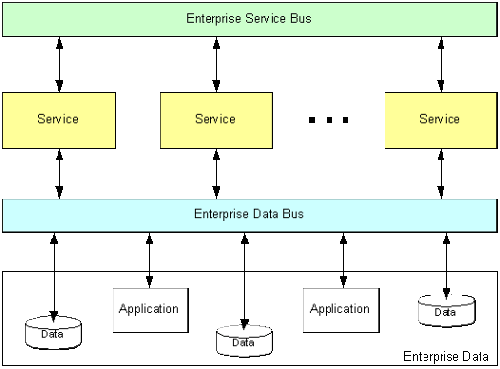
图 1:包含企业数据总线的 SOA 架构
在这里,ESB 负责调用合适的服务,这是通过利用 EDB 访问这些服务可能需要的企业数据来实现的 [ 1 ]。这一架构提供了如下的优势:
- 显式地分离了服务功能实现(业务逻辑)与企业数据访问逻辑之间的关注点。
企业数据总线有效地创建了一个抽象层,将企业数据访问的细节封装在内,为服务实现提供了“标准化接口”。 - EDB 通过将所有对企业数据的访问进行封装,为服务使用的企业语义数据模型 [2] 与企业应用数据模型之间的所有转换提供了单一的场所。
结果,服务实现可以通过 SOA 语义模型来访问企业数据,从而极大简化了企业服务的设计与实现。 - 服务实现得以访问由 EDB 提供的所需企业数据,大大简化了服务接口,并在服务消费者和提供者之间提供了松耦合:
- 因为服务(消费者)可以直接访问数据 [ 2 ],例如,服务调用并不要求真实的参数值(输入 / 输出)作为服务调用的一部分来发送。所以作为结果,服务接口可以按照数据引用(键)而不是真实数据来表达。
- 虽然企业服务模型会随 SOA 实现的成熟而演化,但数据引用的定义却很少发生变化。其结果是,基于键数据的服务接口将更加稳定。
- 使用额外数据来扩展服务实现可以在不影响其消费者的情况下办到。
加入网格
EDB 的一个可行实现是使用数据网格,如 Websphere eXtreme Scale,Oracle Coherence 数据网格,GigaSpaces 数据与应用网格或者 NCache 分布式数据网格。
数据网格是为构建某类解决方案而设计的软件系统,其适用的解决方案范围从简单的内存数据库到分布于规模达数千台服务器之上的强大分布式一致缓存。典型的数据网格实现会将数据分割到跨机器存储于内存里的不重合的块中。其结果是,通过标准的流程可达到极高水平的性能和伸缩性。性能是通过并行执行更新和查询(数据的不同部分可以在不同的机器上同时访问)实现的,而伸缩性和容错性则通过在多台机器上复制同一数据得以实现。
图 2 展示了使用网格作为 EDB 的实现。网格维持了企业数据的内存拷贝,它代表了企业数据库和应用的状态。
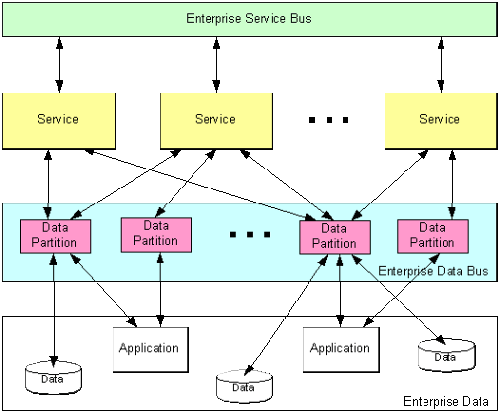
图 2 作为 EDB 的网格
网格的引入允许重新分割存在于多个数据库和应用的数据,以便让它符合企业语义模型。这需要将企业中不同应用 / 数据库中逻辑相关的数据一起并入到一个统一、内聚的数据表示中,并不可避免地伴随着对企业中重复数据进行合理化。
网格的实现典型的是由发布 / 订阅机制来支持的,这使得数据变更在网格内存和现有企业应用及数据间保持同步。一个基于网格的仲裁可以利用专为该服务使用而优化的数据模型高速访问企业数据。
尽管基于网格的 EDB(图 2)简化了对企业数据的高速访问,它仍然有可能要求 EDB 和服务实现之间进行大量的数据交换。服务必须加载所有所需数据,执行其处理,然后将结果存储回网格中去。
一个更优的架构是让服务执行点离企业数据更近;将服务实现为 Agent(代理)的协调人 [7],而这些 Agent 则在包含企业数据的内存空间里执行(图 3)。在这个例子中,服务实现接收一个请求并启动一个或多个 Agent,它们在网格节点的上下文里执行,将结果返回给服务实现,服务实现再组合 Agent 的执行结果并将服务执行结果返回。
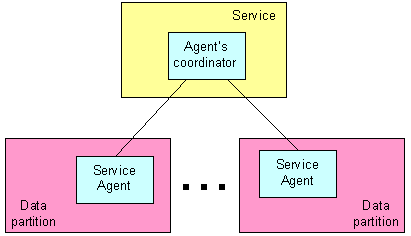
图 3 作为 Agent 协调人的服务
较发布 / 订阅数据交换模型而言,这一方式提供了如下优势:
- 它允许操纵本地数据,这极大的提升了整体的服务执行性能,特别是当处理大量数据时(MB 或 GB 的数据)
- 类似于数据分割,真正的执行被分割到多个网格节点之间,因此更进一步提升了这一架构的性能、伸缩性和可用性。
- 因为所有服务都可以访问同一数据,当服务执行仅仅只通过最少数目的请求 / 响应处理数据时,根本没必要传输数据。
软件 Agent
Agent 的概念可以回溯到分布式人工智能(DAI)的早期研究,当时引入了这一自完备、可交互、并发执行的对象概念。这一对象有某些被封装好的内部状态并能对其它类似对象发来的消息作出响应。根据文献 [7],“一个 Agent 是一个能精确行动以代表用户完成任务的软件组件以及 / 或硬件。”
在文献 [7] 中认定的几类 Agent 如下:
- 协作式 Agent
- 接口 Agent
- 移动 Agent
- 信息 / 因特网 Agent
- 反应式 Agent
- 智能 Agent
基于(图 3)的服务实现架构,我们所说的 Agent 属于多个类别:
- 协作式:一个或多个 Agent 共同实现服务功能。
- 移动:Agent 执行于网格节点上,服务上下文之外。
- 信息:Agent 的执行直接利用了位于网格节点的数据。
在本文接下来的篇幅中,我们将会讨论一个网格的简单实现以及一种可用于构建基于网格的 EDB 和基于 Agent 的服务实现的编程模型。
网格实现
在实现网格最困难的挑战之中,包括高可用性,可伸缩性以及数据 / 执行分割机制。
保证网格高可用性和可伸缩性的一种最简单方式是在网格内部通信中使用消息传递。网格实现可同时从点对点和发布——订阅消息传递中获得益处:
- 在点对点通信中使用消息传递可支持消费者和提供者之间的解藕。请求并不是直接发送给提供者,而是发送给提供者监视的队列。作为结果,队列提供了:
- 通过增加监听同一队列的网格节点的数量可以透明地提升整体吞吐量。
- 通过控制监听队列的线程数量可简单地调节网格节点的负载。
- 简化负载均衡。不是由消费者来决定调用哪个提供者,而是将请求写入到队列中。提供者在线程能够处理请求时选取请求进行处理。
- 透明的故障转移支持。如果监听同一队列的一些进程终止了,剩下的仍然会继续选取并处理消息。
- 发布 / 订阅消息传递的使用简化了在网格基础设施内实现“广播”。这一支持在同步一个网格配置时将会非常有用。
取决于网格实现,数据 / 执行分割方式的范围可以从单纯的负载均衡策略(在相同节点的情况下)到对网格数据的动态索引。这一机制既可被硬编码到网格实现里,也可被抽取出来由专门的网格服务(分割管理器)完成。分割管理器的角色是在节点和服务器间分割网格数据,同时还作为在路由请求过程中用来定位节点(节点队列)的“注册中心”。将分割管理器外部化为单独的服务给整体架构引入了附加的灵活性,其实现方式可以是通过使用“可插拔”的分割管理器实现,甚至也可是为不同类型请求实现不同路由机制的多个分割管理器。
整体的网格基础设施,包括分割管理器和网格节点通信,既可以直接以 API 的形式暴露给网格消费者,在网格请求提交过程中使用;也可以被封装进一系列特别的网格节点(网格 Master[控制器])当中。在第一种情况里,一个特定的网格包将负责实现请求分发和 (可选的) 组合必须对应到一个网格消费者实现的响应。尽管这一选择能够从理论上提供最佳的整体性能,但它通常会在网格实现和消费者之间产生更紧密的耦合 [ 3 ]。在第二种情况里,网格 Master 为网格实现了一个外观模式 [8],并带来了这一模式的所有优点——在网格消费者看来,它完整地封装了网格功能(以及基础设施)。尽管网格 Master 实现增加了额外的网络跳跃(因此会有一些性能开销),但松耦合的实现通常更为重要。
图 4 显示了支持两层(Master/Node 实现)结构的整体高级网格架构。
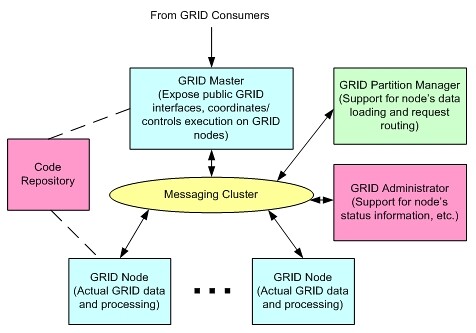
图 4 网格高级架构
除了组件之外,上述所提出的架构(图 4)还包括了两个附加的部分——网格管理器和代码存储库。
网格管理器提供了图形化的界面,展现现在运行的节点,它们的负载,内存利用率,所支持的数据,等等。
因为重启网格的 Node/Master 代价可能很昂贵 [ 4 ],我们需要能够在不重启网格 Node/Master 的情况下将新代码引入到 Node/Master 中。这是通过使用代码存储库(目前被实现为 Web 可访问的 jar 集合)来实现的。当开发者实现了他们想要将其运行在网格环境上的新代码时,他们可以将其代码存储在存储库里并在执行中动态加载 / 调用它(使用 Java 的 URLClassLoader)(见下)。
编程模型
为了简化创建运行于网格的应用,我们为在网格上执行的代码设计了一个 Job-Items 编程模型(图 5)。这一模型是 Map/Reduce 模式 [9] 的一个变种,它的工作如下图所示:

图 5 Job Items 模型
- 网格消费者向网格 Master 提交 Job 请求(以 Job 容器的形式)。Job 容器给 Master 环境提供了实例化 Job 必需的所有信息。这包括 Job 的代码位置(java jar 的位置,或是空字符串,解释为本地静态链接的代码),Job 的启动类,Job 的输入数据和 Job 的上下文类型,这使得可以在多个分割管理器之间进行选择以拆分 Job 执行。
- 网格 Master 的运行时实例化 Job 的类,给它传递合适的 Job 上下文(分割管理器);Master 还负责实例化回应对象,该对象负责给消费者进行回应。一旦创建 Job 对象,运行时就开始执行它。
- Job 的起始执行方法使用分割管理器将 Job 拆分成 Item,每个 Item 被发送给一个特定的网格节点执行——即 Map 步骤。
- 每个目的网格节点接收一个 Item 执行请求(以 Item 容器的形式)。Item 容器类似 Job 容器并且提供了足够的信息供网格节点实例化并执行 Item。这包括了 Item 的代码位置,Item 的起始类,Item 的输入数据和 Item 的执行类型。
- 网格节点的运行时实例化一个 Item 的类,将其传递给合适的 Item 上下文和回应对象,该对象负责给 Job 回应。一旦创建 Item 对象,运行时就开始执行它。
- Item 的执行使用一个回应对象来将局部结果发送回 Job。这允许一旦一个 Item 的局部结果变得可用,Job 实现就可以开始处理它(Reduce 步骤)。如果必要,在这一处理中,附加的 Item 可以被创建并发送给网格节点。
- 一旦局部结果可用,Job 就可以使用一个回应者来将它的局部结果发送给消费者。
整个执行过程如下所示(图 6)
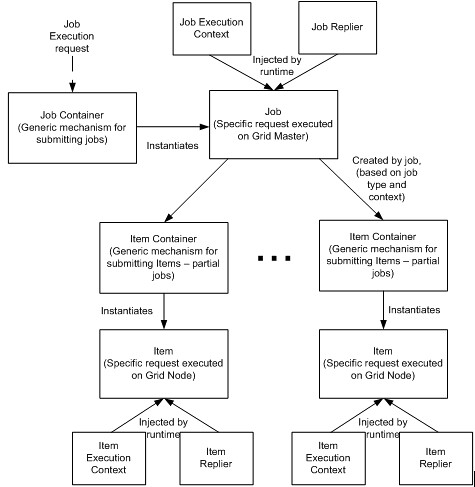
图 6 Job Items 执行
Grid Master 和 Node 的执行细节如图 7 所示
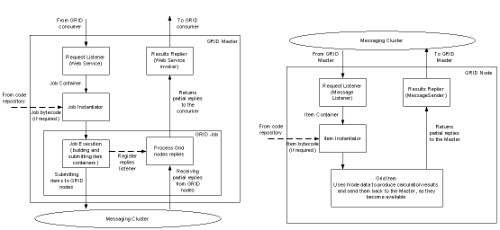
图 7 执行细节
在实现 Map/Reduce 模式的同时,这一编程模型还在所有的层次都提供了对完全异步数据交付的支持。这不仅可以在 Job 消费者能使用局部回应时显著提升整体性能(例如:交付局部信息给浏览器),同时还通过限制消息的大小(消息块)提升了整体系统的伸缩性和吞吐量 [ 5 ]。
网格接口
使用 Job 容器作为 Job 调用机制的同时还为向网格提交 Job 提供了一种标准接口 [ 6 ](图 8)。我们为该 web 服务接口提供了两个功能完全相同的方法——invokeJobRaw 和 invokeJobXML。

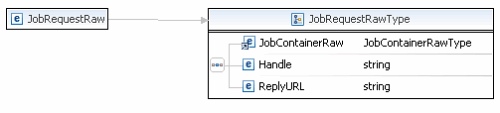
图 8 GridJobService WSDL
两个方法都允许在网格上调用 Job。第一种方式使用 MTOM 来传递一个二进制序列化的 JobContainer 类,而第二种方式支持对 JobContainer 的所有元素以 XML 编组(图 5)。除了 JobContainer,两种方法都将传递两个额外的参数给网格:
- 请求句柄,用来唯一标识请求,并可以被消费者用来将回应与请求相匹配(见后)
- 回应 URL,消费者监听回应的 URL。这个 URL 应当暴露给 GridJobServiceReplies 服务(图 9)
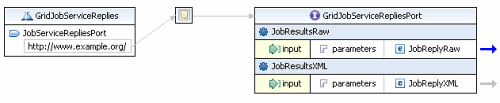
图 9 网格 Job 服务回应的 WSDL
Grid Master 实现
Grid Master 的类图如图 10 所示。除了实现上述的基本 Job 运行时以外,Master 的软件同时还实现了基本的框架特性,包括线程 [ 7 ],请求 / 响应匹配,请求超时等等。
为了支持 Item 执行的请求 / 多回应范式,而不是使用“等待回应”(使用消息时一个常见的请求 / 回应模式),我们决定使用单监听者并构建我们自己的回应匹配机制。最终,我们实现了一个超时机制,保证 Job 能在一个预定的数据间隔(在 Job 容器里定义)里从每一个 Item 得到“第一个”回应。
图 10 Grid Master 实现
Grid Node 实现
Grid Node 的类图如图 11 所示。类似于 Master 运行时,在这里我们对基本的 Item 执行进行了框架支持的补充,包括线程,执行超时等等。

图11 Grid Node 实现
为了避免Item 无限运行而让Node 耗尽,我们已实现了一个基于Item 执行时间的Item 驱逐策略。如果一个Item 的执行比它所声明的时间(在Item 容器里)运行要长时,将会被终止,超时异常将会被发送回Job。
网格消费者框架
同样,我们还开发了一个消费者实现,用简单的Java API(图12)包装了Web 服务(图8,图9)。它利用了内嵌的Jetty Web 服务器,并允许提交Job 请求给网格,然后注册一个接收回应的回调。

图12 网格消费者
总结
EDB 的引入允许架构师进一步简化 SOA 实现,这是通过在服务实现和企业数据之间引入“标准化的”访问实现的。它同时简化了服务调用和执行模型,还为服务提供了进一步的解耦。使用网格作为 EDB 实现对 EDB 的可伸缩性和高可用性提供了支持。最后,使用直接在网格内部执行的服务 Agent 更进一步提升了可伸缩性和性能。本文所描述的网格的高级架构和编程模型,为这一实现提供了一个简单却健壮的基础。
致谢
非常感谢我在 Navteq 的同事们,特别是 Michael Frey,Daniel Rolf 和 Jeffrey Her 和我一起讨论并帮助了网格编程模型的实现。
参考资料
1. B. Lublinsky. http://www.infoq.com/articles/SOA-enterprise-data">Incorporating Enterprise Data into SOA . November 2006, InfoQ.
2. Mike Rosen, Boris Lublinsky, Kevin Smith, Mark Balcer. Applied SOA: : Service-Oriented Architecture and Design Strategies . Wiley 2008, ISBN: 978-0-470-22365-9.
3. Art Sedighi. Enterprise SOA Meets Grid . June 2006.
4. David Chappell and David Berry. SOA - Ready for Primetime: The Next-Generation, Grid-Enabled Service-Oriented Architecture. A SOA Magazine, September 2007.
5. David Chappell. Next Generation Grid Enabled SOA .
6. Data grid
7. Hyacinth S. Nwana. Software Agents: An Overview
9. Map Reduce .
查看英文原文: SOA Agents──Grid Computing meets SOA 。




