

Docker 是在云中部署 ML 模型的绝佳工具。如果你想在云中创建一套生产级部署,那么 AWS 和 GCP 上有很多选项可用。我正在撰写一本书,其中的第 4 章重点介绍用于模型服务的 ECS,同时还会深入探索谷歌 Kubernetes 引擎。这篇文章省略了第 4 章关于 AWS 的容器部署部分,其余部分则没有删减。
可复制模型的容器
部署数据科学模型时,重点在于复现培训时的环境和用于服务的环境。容器的理念是形成一个隔离的环境,你可以在其中设置执行任务所需的依赖项。任务可以是执行 ETL 工作、服务ML模型、支持 API 或托管交互式 Web 应用程序。容器框架的目标是在实例之间提供隔离,同时只占用很少的资源。使用容器框架,你可以指定代码所需的依赖项,并让该框架管理不同的执行环境。Docker 是容器的事实标准,人们围绕这一平台构建了大量工具。
弹性容器环境(例如弹性容器服务器——ECS)提供了与无服务器函数类似的功能,这种环境将服务器的概念从数据科学模型托管中抽象了出来。关键区别在于无服务器生态系统仅限于特定的运行时,通常具有内存限制,很难使用深度学习框架,并且是特定于云的。使用 ECS,你可以设置用于服务模型的实例类型,可以使用服务模型所需的任何语言,并且想用多少内存都没问题。ECS 也还是 AWS 的专有工具,但是诸如 EKS 之类的较新选项建立在开源和可移植的 Kubernetes 之上。
以下是我见过的一些容器数据科学用例:
可重现分析:容器是打包分析的好办法,分析被打包后其他团队成员就可以在几个月或几年后重新启动你的工作。
Web 应用程序:在第 2 章中,我们使用 Dash 构建了一个交互式 Web 应用程序。部署应用时,容器提供了一种很好的方式来抽象出托管事宜。
模型部署:如果要将模型公开为端点,容器提供了一种很好的方法来分离模型应用程序代码与模型服务基础架构。
本章的重点是最后一个用例。我们会使用第二章中的 Web 端点,并将应用程序包装在一个 Docker 容器中。我们首先会在 EC2 实例上本地运行容器,然后试着使用 ECS 创建可扩展、支持负载平衡和容错的模型部署。接下来,我们将展示如何使用 Kubernetes 在 GCP 上获得类似的结果。
既然我们正在探索可扩展的计算环境,那么使用 ECS 和 GKE 时务必要注意云成本。对于 AWS,我们应该密切关注服务了多少 EC2 实例;在 GCP 上,计费工具可很好地跟踪成本。关于编排的部分是专门针对 AWS 的,并且使用的方法不能迁移到其他云环境中。如果 AWS 环境不适合你的模型部署,请直接跳到 Kubernetes 的部分。
Docker
Docker和其他平台即服务工具提供了称为容器的虚拟化概念。容器在主机操作系统之上运行,但是为容器内运行的代码提供了标准化的环境。这种虚拟化方法的主要目标之一是你可以为目标环境编写代码,然后任何运行 Docker 的系统都可以运行你的容器。
容器是提供类似功能的虚拟机的轻量级替代方案。关键区别在于容器的启动速度要快得多,同时提供与虚拟机相同的隔离级别。另一个好处是,容器可以复用其他容器中的层,这样就可以更快地构建和共享容器。当你需要在一台机器上运行相冲突版本的 Python 运行时或库时,容器是一个很好的解决方案。
使用 docker,你可以编写一个名为 Dockerfile 的文件,该文件用于定义容器的依赖项。构建 Dockerfile 的结果是一个 Docker 镜像,该镜像打包了运行应用程序所需的所有运行时、库和代码。Docker 容器是运行应用程序的实例化镜像。Docker 的一个很有用的功能是新镜像可以在已有镜像的基础上构建。对于我们的模型部署,我们将扩展 ubuntu:latest 镜像。
本节将展示:如何在 EC2 实例上设置 Docker;编写 Dockerfile 来构建第 2 章中 echo 服务的镜像;使用 Docker 生成镜像及运行容器。要在 EC2 实例上安装 Docker,可以使用 amazon-linux-extras 工具简化过程。下面的命令将安装 Docker,在 EC2 实例上启动服务,并列出正在运行的容器,这里将返回一个空列表。
我们要部署的应用程序是第 2 章中的 echo 服务。这个服务是 Flask 应用程序,它可以解析 GET 或 POST 中的 msg 属性,并返回一个 JSON 负载来回显所提供的消息。这里与之前应用程序的唯一区别是 Flask 应用现在运行在 80 端口上,如下面的 echo.py 代码片段的最后一行所示。
现在我们已经安装了 Docker 和要容器化的应用程序,我们需要编写一个 Dockerfile 来描述如何构建镜像。下面的代码片段展示了用于执行此任务的 Dockerfile。第一步是使用 FROM 命令来标识要使用的基本镜像。ubuntu 镜像提供了一个支持 apt-get 命令的 linux 环境。MAINTAINER 命令将镜像维护者的名称添加到与镜像关联的元数据信息中。接下来使用 RUN 命令安装 python,设置符号链接并安装 Flask。对于具有许多 Python 库的容器,也可以使用 requirements.txt 文件。Copy 命令将脚本插入镜像,并将文件放置在根目录中。最后的命令指定要执行应用程序时要运行的参数。
编写 Dockerfile 之后,你可以使用 Docker 提供的 build 命令来创建镜像。下面的代码段中展示的第一个命令,显示了如何使用文件./Dockerfile 构建标记为 echo_service 的镜像。第二个命令显示了实例上可用的 Docker 镜像列表。输出将显示我们用作镜像基础的 ubuntu 镜像以及新创建的镜像。
要将镜像作为容器运行,我们可以使用下面的代码段中所示的 run 命令。-d 标志指定容器应作为守护进程运行,即使终端关闭,这个守护进程仍将继续运行。-p 标志会将主机上的端口映射到容器用来通信的端口上。没有这个设置,我们的容器就无法接收外部连接。ps 命令显示正在运行的容器列表,这个列表现在应包括 echo 服务。
为了测试容器,我们可以使用之前的一套流程,当时我们在 Web 浏览器中使用了 EC2 实例的外部 IP,并将 msg 参数传递给/predict 端点。由于我们设置了从主机端口 80 到容器端口 80 的端口映射,因此我们可以在开放的 Web 上直接调用容器。下面的例子显示了来自 echo 服务容器的调用和结果。
现在,我们完成了 Docker 镜像的构建,并将该镜像作为容器运行在 EC2 实例上。尽管这一方法确实提供了隔离机器上不同服务的解决方案,但它没有提供扩展和容错功能,而这通常是生产级模型部署所必需的。
GCP 上的 Kubernetes
谷歌云平台提供了一项称为谷歌 Kubernetes 引擎(GKE)的服务,用于服务 Docker 容器。Kubernetes是最初由谷歌开发的容器编排系统,现已开源。这个平台的用例覆盖很大的范围,但我们将重点关注使用托管版 Kubernetes 托管我们 echo 服务的任务。
使用 Kubernetes 托管 Docker 容器的流程很像 ECS,第一步是将镜像保存到可以与编排系统对接的 Docker 私有仓库(Registry)中。这个私有仓库服务的 GCP 版本称为容器仓库(Container Registry)。要将镜像从 AWS 上的 EC2 实例获取到 GCP 容器仓库,我们将再次使用 docker login 命令。为使此过程正常进行,你将需要我们在第 1 章中设置的 GCP 凭证 json 文件。下面的代码段显示了如何将 json 文件传递给 docker login 命令,标记该镜像以将其上传到仓库, 并将镜像推送到容器仓库。
你需要使用完整的谷歌帐户 ID 替换此脚本中的 gcp_acount 参数。执行完这些步骤后,echo 服务镜像应显示在 GCP 控制台的 Registry 视图下,如图 4.8 所示。通常来说,如果你使用 GCP 来服务模型,则可能会使用谷歌 Compute 实例而不是 EC2,但是最好练习在不同云平台的组件之间对接。
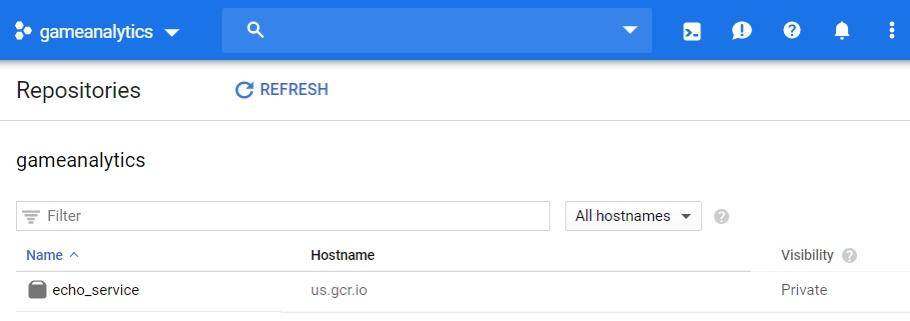
图 4.8:GCP 容器仓库上的 echo 镜像
与使用 ECS 所需的一大堆步骤相比,使用 GKE 托管容器的过程简化了许多。我们首先使用 GCP 控制台在 Kubernetes 上设置一个容器,然后将服务公开到开放的 Web 上。要部署 echo 服务容器,请从 GCP 控制台执行以下步骤:
找到并选择“Kubernetes Engine”
点击“Deploy Container”
选择“Existing Container Image”
选择“echo_service:latest”
分配应用程序名称“echo-kge”
点击“Deploy”
现在我们已经部署了 Kubernetes 集群,并准备提供 echo 服务。在 GKE 上部署 Kubernetes 集群可能需要几分钟来设置。部署完成后,你应该能在集群列表下方看到 echo 集群,如图 4.9 所示。
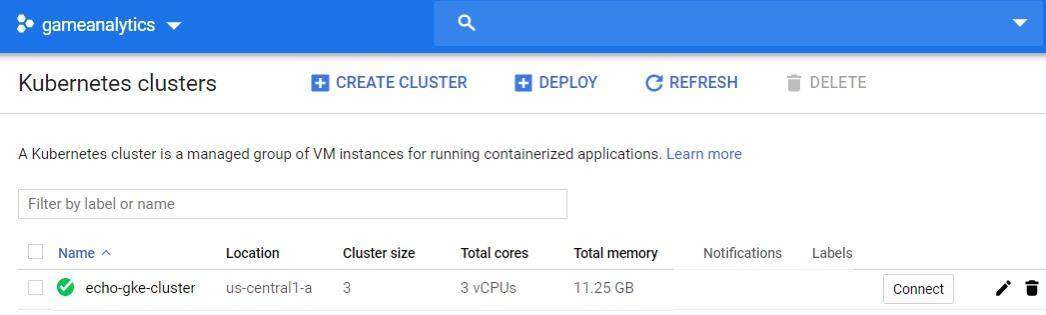
图 4.9:通过 Kubernetes 部署的 echo 镜像
要使用该服务,我们需要通过 GCP 控制台执行以下步骤,将集群公开到开放的 Web 上:
从 GKE 菜单中选择你的集群
点击“Workloads”
选择“echo-gke”负载
选择“Actions”标签,然后选择“Expose”
对于服务类型,选择“load balancer”
执行完这些步骤后,集群将配置一个可用于调用服务的外部 IP,如图 4.10 所示。GKE 将根据需要自动进行负载平衡并扩展服务以匹配负载。
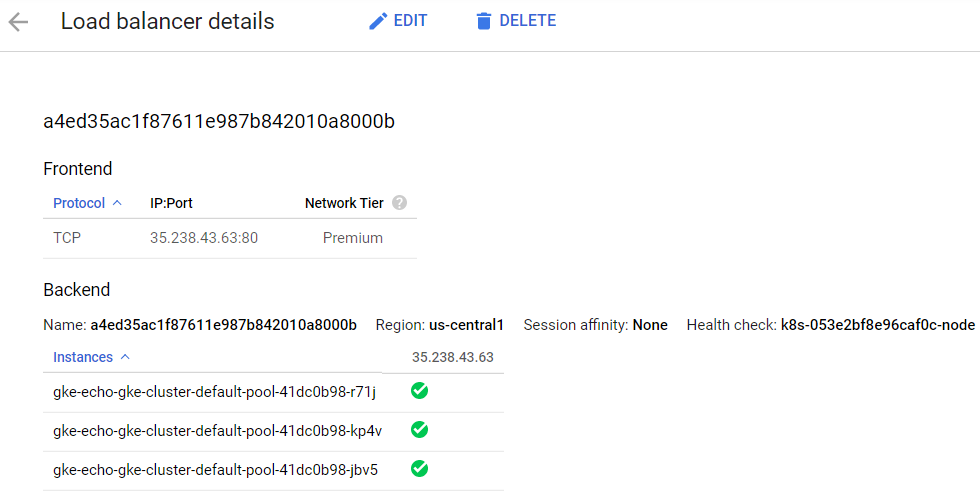
图 4.10:echo 服务已部署到开放的 Web
上面的代码段显示了使用服务的示例。我们能够使用 GKE 快速获取一个 Docker 镜像并将其部署在 Kubernetes 生态系统中。用 Kubernetes 托管 Docker 镜像的体验非常好,因为它是一种可移植的解决方案,可跨多个云环境运行,并且已被许多开源项目采用。
小结
容器非常适合用来在不同环境下重现你的分析和模型。尽管容器可以在单台机器上保持依赖项整洁有序,但它的主要好处是让数据科学家能够编写模型端点,而不必担心容器是怎样托管的。关注点分离后,我们就更容易与工程团队合作将模型部署到生产环境中;或者使用本章中展示的方法,数据和应用科学团队也可以自行将模型部署到生产环境中。
用来服务模型的最佳方法取决于你的部署环境和预期的负载。通常,在一家公司工作时,你只能使用特定的云平台,因为模型服务可能需要与云中的其他组件(例如数据库或云存储)交互。在 AWS 中有多种托管容器的选项,而 GCP 在 GKE 上整合为单个解决方案。你主要关心的一个问题是使用无服务器函数技术或弹性容器技术服务模型是否更具成本效益。正确的答案将取决于你需要处理的流量、最终用户可以忍受的延迟以及需要托管的模型的复杂程度。容器化解决方案非常适合用来服务复杂的模型,并确保你可以满足延迟要求,但是与无服务器函数方案相比,前者可能需要更多的 DevOps 开销。
原文链接:
https://towardsdatascience.com/using-docker-kubernetes-to-host-machine-learning-models-780a501fda49

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论