

如果你是一家实体企业的老板,很快就会发现客流量模式(尤其是在节假日期间),实现销售目标依赖于你提供及时而优质的服务。如果你是一家网店的老板,就像 Curalate 的 1000 多名客户一样,也并没有什么不同:假日期间的销售对成功来说至关重要,而它们在很大程度上取决于网站的可靠性。
在 Curalate,我们为能够全年保持客户集成的高可用性和低延迟而感到自豪。在“黑色星期五”期间以及圣诞节前一周和圣诞节之后的几天,来自客户站点对我们 API 的请求量增加了大约 5 倍。我们的系统需要能够处理增加的负载,并提前对系统进行负载测试,以证明我们的系统设计是有效的。
这篇文章描述了我们如何对基础架构进行负载测试,以应对假日流量对我们的 API 带来的冲击。此外,我们还介绍了动态伸缩方法是如何通过避免过度配置来降低成本的。
负载测试计划
我们的第一个问题是:我们的预期流量是多大?为了回答这个问题,我们查阅了过去几年的假日流量数据。第二个问题:流量有哪些重要的特征?例如,大部分流量是使用缓存还是不使用?是总请求量重要还是瞬时负载更重要?由于之前的一篇文章已经讨论了缓存与未缓存的测试,因此本文将重点介绍 API 请求率。
一天的总请求量只表明了平均每秒请求数(RPS),而我们更感兴趣的指标是日 RPS 峰值。它可以让我们了解一天中最繁忙的时刻,如果我们能够应对这个时刻的请求速率,那么就应该有信心处理其他时间段较低的请求速率。
每秒请求峰值
通过查询历史数据,我们发现,黑色星期五的日 RPS 峰值通常比同年 9 月的正常峰值高 5 倍。因此,我们基于 2018 年 9 月的数据计算出了 5 倍 RPS 峰值,然后使用了一些简单的 bash 脚本和其他工具来稳定地将 API 请求负载增加到预测的最大速率。
下图显示了我们的 API 在整个第四季度(2018 年 9 月至 12 月)期间的日 RPS 峰值。其中 11 月 5 日显示了使用以下脚本生成的内部负载(目标是预期的 5 倍流量)。11 月 24 日(黑色星期五)和 12 月 5 日是最终用户生成的 API 流量的两个峰值。
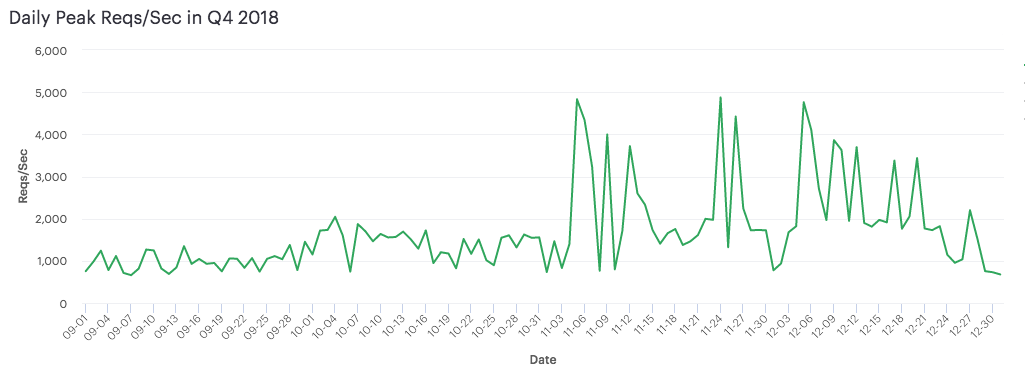
我们的预测完全正确!事实上,我们并没有期望预测能够接近准确的峰值流量负载,或许我们还可以测试高一点的负载。
执行负载测试
我们已经在 2017 年的一篇有关假期流量负载测试的文章中分享了我们执行的不同负载测试(缓存和未缓存、各种 API 端点等),并提供了一些示例输出。因此,现在这里只提供其中的一个脚本。为了执行实际的负载测试,我们今年再次使用了Vegeta,因为去年用过它,对它感到很满意。
以下的 bash 脚本显示了我们如何使用 Vegeta 逐步增加对指定 API 端点的请求率:
上面的脚本将重复执行 Vegeta,逐步增加请求率,直到达到指定的最大速率。每次 Vegeta 将运行指定的持续时间,最后一次(达到最大速率)将会一直运行,直到被手动终止。此外,每次执行都会生成一个不同的 Vegeta 输出文件。
弹性缩放示例
处理日流量负载的 5 倍峰值其实非常简单,对吧?
如果不考虑成本,这真的很容易。但对于关心成本的人来说,我们的目标是随着对服务需求的增加动态扩展计算资源,然后随着需求的减少优雅地缩减资源。
动态缩放
显然,只要配置得当,AWS 会使这一切变得非常容易。我们的一些遗留服务仍然作为 AMI 运行(部署在 EC2 实例的自动伸缩组中),不过大多数微服务现在作为容器运行在 Amazon ECS 上。今年早些时候,我们写了一篇文章,详细介绍了在 ECS 上运行我们的生产系统时所涉及的各个方面。
由于之前的文章已经解释了我们如何在 ECS 上运行我们的系统,所以这篇文章只提供一个动态缩放的例子。下图显示了我们的一项叫作“Media API”(“media-api-service”)的服务请求率,以及从圣诞节到 12 月 27 日三天期间为该服务提供的相应容器数量(“media-api-service_v3”)。
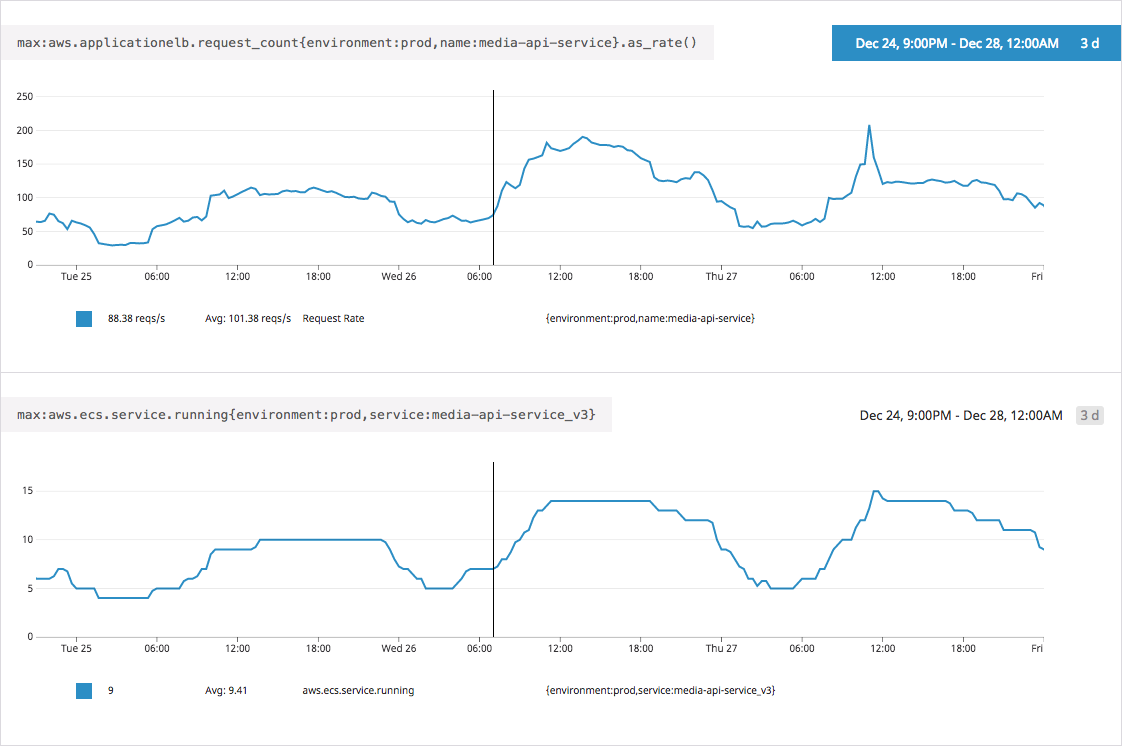
我们快速添加了更多的容器来满足不断增长的请求需求,在请求率下降后又很快移除它们。虽然下方的图并不能直接表示底层 EC2 实例的数量变化情况,但如果集群中的所有服务都采用类似的扩展方法,那么它可以很好用来估计 EC2 的动态容量(和成本)。
缩放指标
说到缩放,我们需要度量哪些指标?我们可以考虑 CPU 和内存利用率,以及延迟和队列大小。根据我们的经验,CPU 利用率的伸缩对于基于容器的服务来说已经足够好了。当给定服务的容器平均 CPU 利用率超过某个阈值(比如 75%),我们就添加一个新容器,并在一段时间后重新计算。当 CPU 利用率下降到 60%以下时,我们停止一个容器,并在一段时间后重新计算。我们以相同的方式基于内存使用率来伸缩服务。
讨论和相关说明
为了简洁起见,这篇文章跳过了与上述各方面相关的几个点。接下来让我谈谈一些值得注意的问题和相关细节,虽然它们不是这篇文章主题的核心。
虽然总请求量不直接描述每秒峰值请求,但它可能会影响对总数据大小比较敏感的其他资源,例如事件队列和日志记录/诊断数据。在执行负载测试和面对增加的实时流量时,请将这些类型的资源考虑在内。
我们讨论了扩展计算资源以满足增加的服务请求率,但如果你的流量出现极端的突发(例如在几秒钟内从 1 倍变为 10 倍或更高),那么你应该考虑使用 CDN 而不是动态伸缩。CDN 在推送新数据方面引入了一些延迟,但它可以承受更高的请求率,因为响应是由输入的请求决定的。
生产环境基础设施的综合负载测试可能会因为使用了一些资源(比如数据库、缓存和事件队列)给实时的生产流量带来影响。例如,如果你在实时基础设施上运行“无缓存”测试,可能会将所有真实客户的数据从缓存中移除,并大幅降低生产流量的性能。
文章开头提到了假期服务可靠性的重要性。要了解在 2018 年黑色星期五期间 Curalate 与其他几个竞争对手之间的可靠性对比,请看这篇文章。
英文原文:http://engineering.curalate.com/2018/12/31/holiday-load-prep.html

暂无签名

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论