

Web 应用程序安全简介
让我们开始 Web 应用程序安全性的系列文章,其中解释了浏览器的工作方式以及它们是如何做到的。由于您的大多数客户都将通过浏览器与您的 Web 应用程序进行交互,因此了解浏览器怎样工作是很重要的基础。
浏览器是渲染引擎,它的工作是下载网页并以可视化方式呈现。
尽管这很简单,但我这里再次强调一下步骤。
用户在浏览器地址栏中输入一个地址。
浏览器通过该 URL 下载“文档”并进行呈现。
您可能已经习惯了使用最流行的浏览器之一,例如 Chrome、Firefox、Edge 或 Safari,但这并不意味着没有其他浏览器。
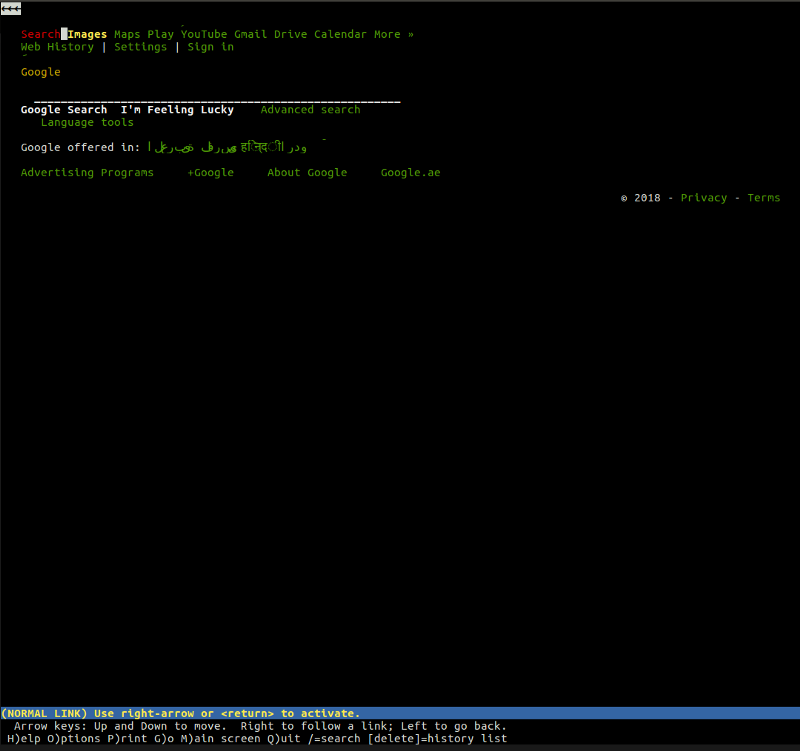
例如,lynx 是一种轻量级的基于文本的浏览器,可以从命令行运行。 当用户输入网址(URL),浏览器将获取文档并进行呈现。唯一的区别是,lynx 不使用视觉渲染引擎,而是使用基于文本的界面,这使得类似 Google 的网站看起来像这样 :
我们大致了解浏览器的功能,下一步我们逐步分析各个执行步骤。
浏览器做什么?
长话短说,浏览器的工作主要包括:
DNS 解析
HTTP 协议交互
渲染
重复上面步骤
DNS 解析
此过程可确保当用户输入 URL,浏览器就会知道它必须连接到哪个服务器。浏览器访问 DNS 服务器,以将google.com转换为216.58.207.110(浏览器可以连接到的 IP 地址)。
HTTP 交换协议
一旦浏览器确定了哪个服务器将满足我们的请求,它将与之启动 TCP 连接并开始 HTTP 交互。这不过是浏览器与服务器进行通信以及服务器进行交互的一种方式。
HTTP 只是最流行的网络通信协议名称,浏览器在与服务器通信时大多通过 HTTP 进行通信。 HTTP 涉及客户端(我们的浏览器)发送请求,而服务器则通过响应进行回复。
例如,浏览器成功连接到google.com的服务器后,它将发送如下请求:
让我们逐行细分请求:
GET / HTTP/1.1:在第一行中,浏览器要求服务器在/位置检索文档,并补充说,其余请求将遵循 HTTP / 1.1 协议(也可以使用1.0或2)Host: google.com:这是 HTTP / 1.1 中唯一必需的 HTTP 标头。 由于服务器可能服务于多个域(google.com,google.co.uk等),因此此处的客户端提到请求是针对该特定主机Accept: */*:浏览器告诉服务器它将接受的响应格式。 服务器可能具有 JSON、XML 或 HTML 格式的资源,它可以选择其希望的格式.
当客户端的浏览器完成请求后,轮到服务器进行回复。 响应如下所示:
服务器让我们知道请求已成功(200 OK),并在响应中添加了一些标头,例如,它公布了处理我们请求的服务器(服务器:gws),该响应的X-XSS-Protection策略是什么等等。
现在,您无需了解响应中的每一行细节, 您需要了解的是客户端和服务器正在通过 HTTP 协议进行信息交换即可。
渲染
最后是渲染过程。 如果仅向用户显示的是有趣字符列表,浏览器的效果如何?
在响应的正文中,服务器根据Content-Type标头包含响应的表现形式。 在我们的例子中,内容类型设置为text / html,因此我们期望响应中有 HTML 标记——这正是我们在正文中找到的内容。
这是浏览器真正“闪耀”的地方。 它解析 HTML,加载标记中包含的其他资源(例如,可能有 JavaScript 文件或 CSS 文档要提取),并尽快将其呈现给用户。
再一次,最终结果是用户可以看到的可视化页面。
由于本系列文章的重点是安全性,因此我将提醒一下我们刚刚学到的内容:攻击者可以轻松地摆脱 HTTP 协议交互和呈现部分中的漏洞。漏洞和恶意用户也潜伏在其他地方,但是在这些级别上更好的安全性方法已经可以使您在改善安全性方面取得长足的进步。
浏览器厂家
最受欢迎的浏览器有如下厂家:
Chrome by Google
Firefox by Mozilla
Safari by Apple
Edge by Microsoft
除了互相竞争以提高其市场占有率外,各个厂家还相互合作以提高 Web 标准,这是浏览器的一种“最低要求”,非常关键。
W3C是标准制定的主体,但浏览器厂家开发自己的功能并最终使其成为 Web 标准并不少见,安全性也不例外。
例如,Chrome 51 引入了SameSite cookies,该功能使 Web 应用程序可以摆脱一种称为 CSRF 特定类型的漏洞(稍后详细介绍)。其他厂家认为这是个好主意,因此也效仿,这让 SameSite 成为一个 Web 标准:到目前为止,Safari 是唯一不支持SameSite cookie的主流浏览器。

这告诉我们两件事:
Safari 对用户的安全性似乎不太关心(开个玩笑:Safari 12 中将提供 SameSite cookies)
在一个浏览器上修补漏洞并不意味着您所有的用户都是安全的
第二点真的很重要。在开发网络应用程序时,我们不仅需要确保它们在各种浏览器中的外观相同,而且还需要确保我们的用户在各种平台上都受到相同的安全保护。
您的网络安全策略应根据浏览器厂家允许我们执行的操作而有所不同。如今,大多数浏览器都支持相同的功能集,并且很少偏离其通用路线图,但是仍然出现上述情况,因此在定义安全策略时需要考虑这一点。
就我们而言,如果我们决定仅通过 SameSite Cookies 来缓解 CSRF 攻击,那么我们应该意识到,我们使 Safari 用户面临风险。我们的用户也应该知道这一点。
最后,您应该记住,可以决定是否支持浏览器版本:支持每种浏览器版本都不切实际(考虑支持 Internet Explorer 6 是开发者噩梦)。不过,确保支持主要浏览器的最后几个版本通常是一个不错的决定。不过,如果您不打算在特定平台上提供保护,通常建议让您的用户知道。
专家提示:您永远不应鼓励您的用户使用过时的浏览器版本。 即使您已采取所有必要的预防措施,其他 Web 开发人员也可能没有采取措施。 提示用户使用主要浏览器的最新版本。
供应商还是标准错误?
普通用户通过第三方客户端(浏览器)访问我们的应用程序这一事实为实现清晰、安全的浏览体验增加了另一种间接访问级别:浏览器本身可能存在安全漏洞。
供应商通常会向可以在浏览器上发现漏洞的安全研究人员提供奖励(即漏洞赏金)。
例如,Chrome 奖金计划使安全工程师可以与 Chrome 安全团队联系,以报告他们发现的漏洞。如果确认这些漏洞,则会发布补丁,通常会向公众发布安全建议通知,研究人员将从项目中获得(通常是财务上的)奖励。
像 Google 这样的公司在他们的 Bug Bounty(漏洞赏金)计划中投入大量资金,因为它允许他们发现应用程序问题时,通过保证财务利益来吸引研究人员。
在 Bug 赏金计划中,双方方都是“赢家”:供应商设法提高其软件的安全性,研究人员因此而获得报酬。我们稍后将讨论这些程序,因为我认为 Bug Bounty(漏洞赏金)计划在安全领域应有的一席之地。
杰克·阿奇博尔德(Jake Archibald)是 Google 的开发人员拥护者,他最近发现了一个影响多个浏览器的漏洞。 他在一篇有趣的博客文章中记录了他的努力,与其他供应商的接触方式以及他们的反应,我建议您阅读。
开发人员专用的浏览器
到现在为止,我们应该已经理解了一个非常简单但相当重要的概念:浏览器只是为普通互联网上网构建的 HTTP 客户端。
它们绝对比平台上的裸 HTTP 客户端(例如 NodeJS 的require('http'))更强大,但是到最后,它们“只是”简单 HTTP 客户端的自然演变。
作为开发人员,我们选择的 HTTP 客户端可能是 Daniel Stenberg 的cURL,Daniel Stenberg 是 Web 开发人员每天使用的最受欢迎的软件程序之一。 它允许我们通过从命令行发送 HTTP 请求来即时进行 HTTP 交换:
在上面的示例中,我们在localhost:8080 /处请求了文档,并且本地服务器已成功回复。
与其将响应的主体转储到命令行,我们在这里使用了 -I 标志,该标志告诉 cURL 我们仅对响应标头感兴趣。 向前迈出一步,我们可以指示 cURL 转储更多信息,包括它执行的实际请求,以便我们可以更好地了解整个 HTTP 交互。 我们需要使用的选项是-v(详细):
主流浏览器的 DevTools 可以提供几乎相同的信息。
如我们所见,浏览器仅是精心设计的 HTTP 客户端。当然,它们添加了大量功能(例如安全凭据管理、书签、历史记录等),但事实是它们作为对用户体验友好的 HTTP 客户端而诞生的。
这很重要,因为在大多数情况下,您不需要浏览器即可测试 Web 应用程序的安全性,因为您只需下载最新的浏览器版本即可。
我想指出的最后一件事是,任何东西都可以是浏览器。如果您有一个通过 HTTP 协议使用 API的移动应用程序,那么该应用程序就是您的浏览器-它恰好是您自己构建的高度定制化的应用程序,仅能理解特定类型的 HTTP 响应(通过您自己的 API) 。
英文原文:

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 3 条评论