

01 数据探索性分析
首先,我们对接入整个数据仓库贴源层中的所有表所有字段的敏感类型 (也就是模型的目标变量 Y)进行了统计,其中敏感类型的字段占全部字段 2% 左右,主要的敏感信息类型包括:姓名,身份证号,手机号,固定电话号,银行卡号,邮箱等。可以看出这一个样本极度不均衡的问题。
其次,我们对于所能获取到的用于判断一个字段敏感类型的信息 (也就是模型的自变量 X)统计如下:
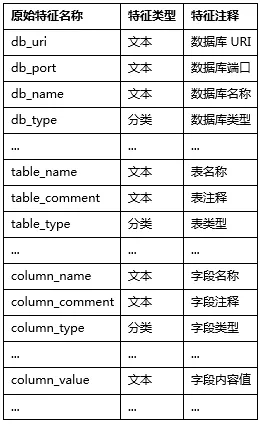
对于上表中的原始特征,通过统计分析确定相应的数据预处理方法和参数,从而衍生出更多的特征。例如,对于数据库名称 (db_name),我们衍生出数据库名称长度 (db_name_len)特征,并对其在是否为敏感字段上的分布统计如下:
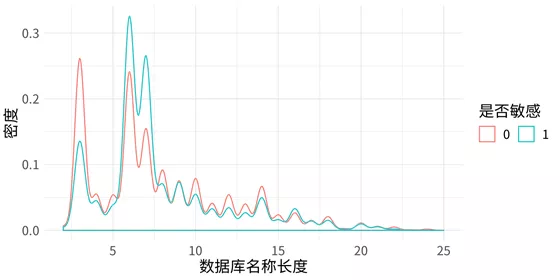
从上图中不难看出,数据库名称长度对于字段是否为敏感具有一定的区分性。从字段类型 (column_type) 角度分析,不同字段类型的敏感和非敏感字段占比如下:
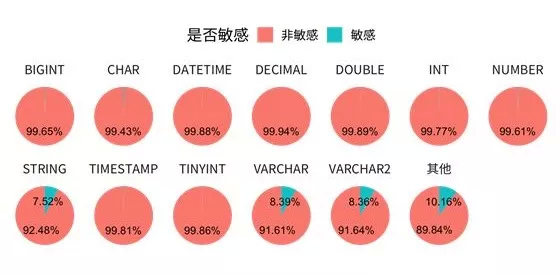
最终,通过数据预处理,特征衍生等多种手段得到模型最终的输入特征。
02 Wide&Deep 网络和 TextCNN
Wide&Deep 网络
Wide & Deep 网络是由 Google 提出的一种用于推荐系统的深度神经网络模型 [2]。整个网络框架如下图所示:
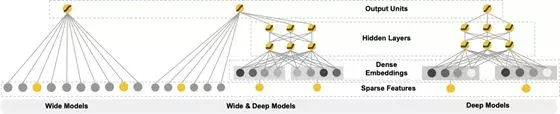
模型 Wide Models 部分的输入为数值型和利用 One-Hot 编码的分类型特征,Deep Models 部分通过学习得到了分类特征的 Embedding 编码。对两部分进行合并得到最终的 Wide & Deep 网络,模型预测的条件概率为:
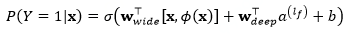
其中,Y 为预测标签,为 Sigmoid 函数,为原始特征的 X 的特征组合,为偏置项,为 Wide 部分的权重,为应用在 Deep 部分最后一层的权重。原文中 Wide 部分采用 FTRL 进行优化,Deep 部分采用 AdaGrad 进行优化。
敏感字段识别问题的输入中包含了大量的数值型特征和分类型特征,因此可以采用 Wide & Deep 网络进行处理。
TextCNN
TextCNN 是由 Kim 等人提出的一种利用卷积神经网络对文本进行分类的深度神经网络模型[3]。整个网络框架如下图所示:
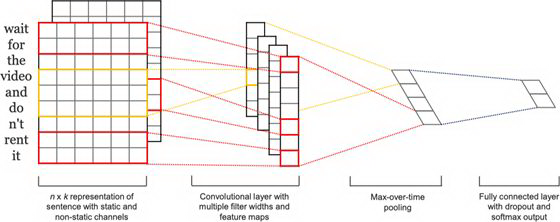
在卷积层中,一个特征由一个窗口内的词生成:
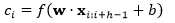
其中, h 为窗口的大小,为词向量表示,为卷积核参数,为偏置项, k 为词向量的维度。
敏感字段识别问题的输入中包含了大量的文本特征,因此可以采用 TextCNN 网络进行处理。
03 敏感字段识别模型
对于敏感字段识别问题,从问题和数据的特点出发,对原始的 Wide & Deep 模型和 TextCNN 做出了如下改进:
Wide&Deep 网络改进
原始 Wide & Deep 网络的深度模型的输入均为分类型特征,但在敏感字段识别问题还存在大量的文本特征。考虑到 CNN 在文本分类上具有较好的效果,因此对于文本特征在通过 Embedding 层后利用 CNN 网络对其进行处理,其它的分类型特征在通过 Embedding 层后仍使用全连接网络进行处理。改进后的网络框架如下图所示:
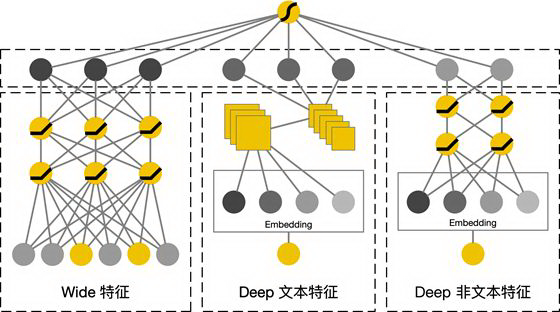
TextCNN 改进
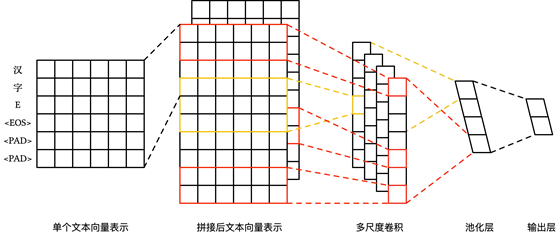
原始的 TextCNN 解决的是英文文本的分类问题,对于敏感字段识别问题,文本特征中存在大量的汉语信息。不同于英文,汉语没有天然的分隔符,传统的做法是采用分词技术对汉语文本进行预处理。但是这样模型的效果就会受制于分词效果的好坏,同时计算效率也会有一定的下降,因此我们选择不分词,直接采用字向量处理文本。
同时需要注意的是 CNN 会隐含地利用到文本的位置信息,因此对于不同的文本特征组合成一个定长的文本时,需先对每个文本特征进行截取和补全,再将其进行拼接得到最终的定长文本。改进后的网络框架如下图所示:
模型训练
在数据探索性分析阶段,我们指出了数据的不平衡性。因此在处理数据不平衡问题时可以采用如下两个方法:
数据的过采样和欠采样。即对较少类型的数据多采样一些,或者对于较多类型的数据少采样一些。
代价敏感学习。即在损失函数中赋予较少类型的样本更大的损失值,增加其在一批数据中的重要程度。
对于训练数据的生成,由于字段数量是有限的,但字段内容值 (column_value) 是大量的。因此我们以一个不为空的字段内容值搭配其他特征为一个训练样本。数据的划分采用常用的模式:训练集测试集划分 7:3,训练集内部训练集验证集划分 8:2。
模型训练的超参数采用常用的模式:
Wide 部分 Dropout 比例:0.5
Deep 部分 Dropout 比例:0.5
Concat 部分 Dropout 比例:0.5
Embedding 维度:128
优化器: Adam(lr=0.001, beta_1=0.9, beta_2=0.999)
训练数据 Batch Size: 128
模型性能
敏感字段识别问题为一个多分类问题,训练好的模型在测试集上的整体准确率为 93% 左右。但其在一些具体类型上的效果略有欠缺,通过具体的分析定位问题在于训练数据中包含了一些标注错误的样本,例如:敏感类型为“地址”,但该字段保存的却不是地址类型的数据。
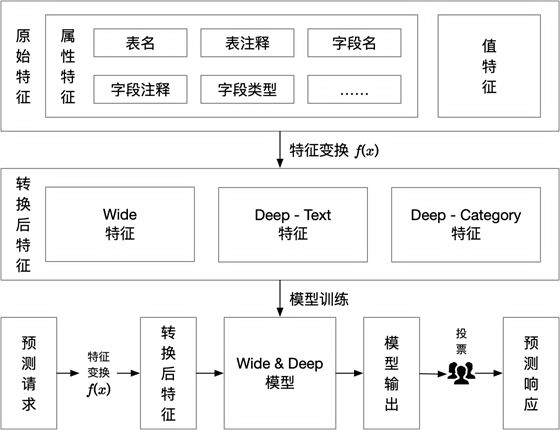
实施流程
模型的整个实施流程如下:
[1] https://en.wikipedia.org/wiki/Data_governance
[2] Cheng, H.-T., Koc, L., Harmsen, J., Shaked, T., Chandra, T.,Aradhye, H., … Shah, H. (2016). Wide & Deep Learning for RecommenderSystems. ArXiv:1606.07792 [Cs, Stat].
[3] Kim, Y. (2014). Convolutional Neural Networks for SentenceClassification. In Proceedings of the 2014 Conference on Empirical Methods inNatural Language Processing (EMNLP) (pp. 1746–1751).

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论