
输入音乐流派风格、内容主题,仅需几秒钟内就可生成 2 分钟音乐......
近日,人工智能初创企业 Suno 对外发布了 Suno 模型 V3 版本,并在官网上提供了免费试用。据介绍,在 V2 版本基础上,V3 版本增加了更多音乐风格和流派,同时也加强了对提示词的依从性,减少了幻觉问题,效果更加令人惊艳。所以这款 AI 驱动的歌曲生成器在社区内迅速传播,引发了一股创作热潮。
Suno 能够根据用户输入的简单文本描述,生成完整的歌曲作品,包括歌词、人声和配器等所有内容。这使得音乐创作不再局限于专业人士,即使是没有任何音乐基础的人,也能轻松创作出属于自己的歌曲。尽管 Adobe 的 Project Music GenAI、YouTube 的 Dream Track 和 Voicify AI 等 AI 音乐生成器已先行推出,但只有 Suno 脱颖而出,被誉为“音乐界的 ChatGPT”。

让 Transformer 唱起来
文本转语音(TTS)的发展历程,其底层架构的演变可以概括为共振峰合成→串联合成→神经网络。现如今,最先进的 TTS 只需调用一次 API,即可使用 Eleven Labs 和 OpenAI 的 TTS 模型或 Descript 产品。整个过程延迟极低,语调顺畅自然,甚至能够模仿各种口音。一天之内,大家就能拥有自己的语音 AI 陪聊。那有了语音陪聊 AI 的下一步是什么?当然是让它唱起来!
据报道,Suno 创业团队仅成立不到两年时间,由 Mikey Shulman、Keenan Freyberg、Georg Kucsko 和 Martin Camacho 联合创立。四人都是机器学习方面的专家,此前曾一同就职于人工智能企业 Kensho,并想打造出以财务场景为核心的语音识别工具(例如财报电话会议)。但身为音乐家兼音响发烧友,他们开始尝试将文字转语音、AI 和音频生成结合起来,最终离开 Kensho 选择全职创业。
当初创办公司时,很多人提醒我们应该专注于语音。大家都说如果想建立一家音频公司,那语音的市场空间更为广阔。但我一直觉得音乐中蕴藏着众多个性化的要素,所以总想要探索一番。于是我们总会情不自禁地构建音乐模型并加以使用,并深深为此而着迷。
他们的第一款规模产品就是 Bark,这是首个基于开源 Transformer 的“文本到音频”模型(架构受到 Karpathy NanoGPT 的启发),一个月内就在 GitHub 上从零开始获得 1.9 万颗 star。当时,他们觉得音频生成相较于文本和图像实在太过落后。而且与之前的模型不同,Bark 不仅能够生成语音,还可以输出音乐与音效,例如哭、笑和叹息等。
当时困扰他们的核心难题,就是文本到语音的训练数据极其有限。因此,他们决定从头开始构建一款新的基础模型,利用音频进行训练,之后再做微调以实现文本到语音转换。这种将音频转化为令牌来进行自监督学习的方法成为重要的创新成果。与以往适用度有限且相当不自然的 TTS 模型不同,Bark 根据来自广泛上下文的真实音频进行训练,因此输出结果可谓丝滑流利。
随着 Bark 的流行,越来越多用户开始使用它生成音乐。从实际效果来看,他们的模型架构确实能够生成人们喜爱的音乐,而且走上了一条其他研究机构相对忽视的独特道路:
大家都高度关注大语言模型,特别是其强大的信息处理与智能表现。但我觉得人们似乎忘记了事情的另一面——音乐创作,虽然这部分市场相对较小,但带给人们的感受和愉悦却是非常真实。
2023 年 12 月,Suno 凭借华丽的新网站加公告帖而一夜爆红:

体验过的用户也是好评如潮:
音乐是人类文化的核心,但能够参与音乐制作的群体却始终有限。Mikey 和团队希望让每个人都成为积极的音乐创作者,而不仅仅是被动的接受者。
大家开始放飞自我了
现在 Suno 正式推出了 V3 Alpha,其中包含大量改进:
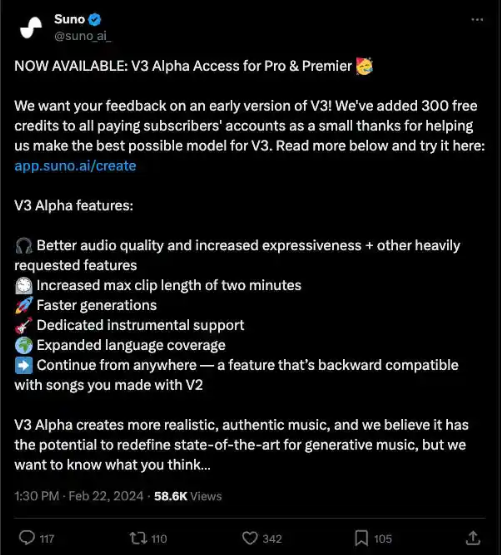
一经发布,网上便有了大量的演示和用户评论。
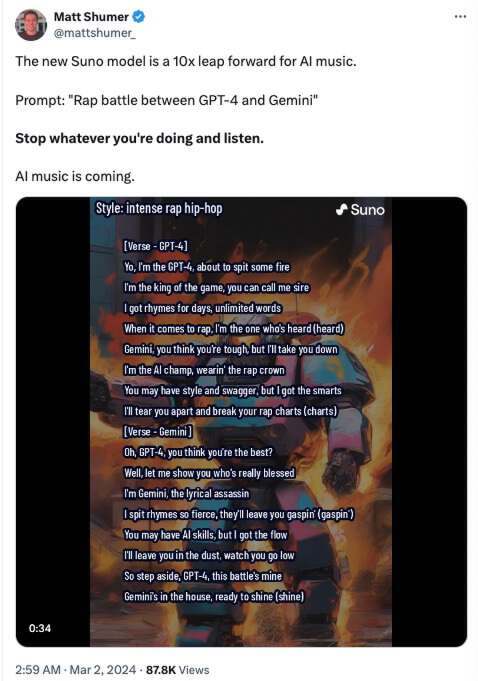
新的 Suno 模型代表着人工智能音乐的巨大飞跃,其能力是过去版本的 10 倍以上。
提示:“GPT-4 和 Gemini 的说唱对决”
这不仅仅是升级,它是音乐界的革命!音乐的未来不仅仅在进化,它正以前所未有的速度进行着变革。
网友 Yong 则表示从此他不需要花钱请专业的人来帮忙写歌了。
而且不仅英文歌曲在行,中文歌曲也很溜。有人将周杰伦的《夜曲》歌词喂给 Suno,作出的歌被网友评价:“这版《夜曲》太震撼了,简直要碾压如今的华语乐坛。”
Suno 还能将《七里香》换成粤语版本的。网友 Gorden Sun 表示,方法很简单,就是让 ChatGPT 给歌词生成粤语拼音标注,然后在 style 里写上 Cantonese song,就可以了。
甚至有人还将菜谱放进了 Suno,这曲恶搞的《宫保鸡丁》直接爆火,妥妥地展示了一把 Suno 的实力。
还有放飞得更厉害的,用 ChatGPT 按以下意思生成了歌词,喂给了 Suno,来了首《刚转行工程师就遇上了大裁员》。

Suno 音频生成模型的背后
音频生成具体场景分为三大类:音乐、语音和音效(SFX)。Suno 是这波将音乐与语音相结合的音频生成探索中的最新产物,其历史可以追溯至 Tensorflow Magenta(也许之前还有更早的 AI 音乐项目,但我们暂时没有查到)。其他相关尝试还包括翻译与语音生成的无缝混合、Audiobox 加语音与音效,以及专门生成音乐和音效的 Stable Audio。目前市面上还没有出现能够搞定所有这些用例的模型,但相信未来定会出现,而 Transformers(也许是 Diffusion Transformers)大概率会继续充当其核心。
Mikey Shulman 认为音频生成的这些细分用例仍有改进的空间,文本那边也同样如此。所以这是个不断发展的领域。而且从宏观上看,音频生成已经明显落后于图像和文本生成了。粗略地讲,音频生成可能落后图像和文本一到两年时间。而现在的我们必须像 2022 年思考文本生成那样考虑音频生成。毕竟 Transformers 就在那里,也的确有效,但还远远不够。
他们倾向选择 Transformers,也就是说 Suno 的音频生成之道跟文本生成非常相似。其中提出了 token 令牌的抽象概念,通过训练模型来预测接下来将要出现的 token 的概率。所以在本质上 Suno 仍然是个语言模型。该团队从文本生成领域的先驱者那里学到了很多,包括这些 transformers 模型的工作效果如何、适合解决哪些问题、不适合解决哪些问题等等。
“从本质上讲,我们用 Transformers 处理音频的方式跟用它处理文本的方式完全相同。我们是在预测下一小段音频,并不断重复这个过程以根据需要输出音频结果。”
Mikey 表示 Suno 刚开始的研究工作确实比较困难、进展也不理想。但好在思路始终清晰,那就是尽可能少加入显式知识。举例来说,他们不会在 GPT 中以编程的形式告诉它这是名词、那是动词,模型本身会隐式掌握所有这一切。这种人类的干涉反而会破坏模型的学习过程,所以在音乐和音频方面也一样,尽量不人为地向模型强加任何规则,而是让它自己学习和探索。
“现在来看这种方法确实得到了回报,但当初我们也不确定这种做法到底可不可行。”
比如说,我们可以采取文本转语音之类的原有技术,也可以用音素之类的方式进行编程,可选的方法很多。但这些会把模型限制在通过音素来表达这种单一方法上。哪怕在短期之内关键效果很好,但从长远来看,这种方式也可能上限不高。所以 Suno 的方法就是始终强调泛化、始终强调端到端,哪怕这意味着模型的短期表现会差一些,他们也坚信这才是长远意义上的正确选择。
如何分配不同音乐流派的比例、是否需要把声乐和器乐部分区分开,这跟高质量音乐模型的微调工作相关,这部分要做的事情很多,而这也是 Suno 团队投入精力最多、堪称秘密武器的部分。Mikey 介绍说这部分的工作核心就是把 Transformers 在文本领域的优势转移到音频中来。一大关注核心就是如何将音频正确转化成 token,这个令牌化的过程非常重要。具体方法跟目前的开源大模型类似,还会使用多种不同模型来学习离散表示,借此对音频进行编码。其中包括找出正确的隐式偏差,还有向模型注入正确的数据。比如要如何确保用户能随意生成所有音频?这肯定需要区分语音、背景乐还有人声的部分,而这一切都是为了确保真正捕捉到音频生成所需要的手段。
对于训练数据,Mikey 表示单凭音乐来训练高质量模型不太行,还得辅以其他素材,比如最让大家头痛的真实人声素材。跟大语言模型一样,Suno 的音频模型也需要接纳各种各样的人声,它们虽然不属于音乐,但同样能帮助模型学习知识。
“总之,我觉得目前的发现还处于极早期阶段,我们才刚刚触及到实现目标的正确方法的浅表。当然,这也同样令人非常兴奋,就是说从后续发展的角度看,我们还有很多易于实现的目标能够达成。”
参考资料:
https://twitter.com/FinanceYF5/status/1772189513726431517




