

如果你在生产环境中使用过 Kubernetes,那么相信你对 Deployment 一定不会陌生,Deployment 提供了一种对 Pod 和 ReplicaSet 的管理方式,每一个 Deployment 都对应集群中的一次部署,是非常常见的 Kubernetes 对象。
我们在这篇文章中就会介绍 Deployment 的实现原理,包括它是如何处理 Pod 的滚动更新、回滚以及支持副本的水平扩容。
概述
作为最常用的 Kubernetes 对象,Deployment 经常会用来创建 ReplicaSet 和 Pod,我们往往不会直接在集群中使用 ReplicaSet 部署一个新的微服务,一方面是因为 ReplicaSet 的功能其实不够强大,一些常见的更新、扩容和缩容运维操作都不支持,Deployment 的引入就是为了就是为了支持这些复杂的操作。
YAML
当我们在 Kubernetes 集群中创建上述 Deployment 对象时,它不只会创建 Deployment 资源,还会创建另外的 ReplicaSet 以及三个 Pod 对象:
Bash
每一个 Deployment 都会和它的依赖组成以下的拓扑结构,在这个拓扑结构中的子节点都是『稳定』的,任意节点的删除都会被 Kubernetes 的控制器重启:
#mermaid-1575352932913 .label{font-family:trebuchet ms,verdana,arial;color:#333}#mermaid-1575352932913 .node circle,#mermaid-1575352932913 .node ellipse,#mermaid-1575352932913 .node polygon,#mermaid-1575352932913 .node rect{fill:#ececff;stroke:#9370db;stroke-width:1px}#mermaid-1575352932913 .node.clickable{cursor:pointer}#mermaid-1575352932913 .arrowheadPath{fill:#333}#mermaid-1575352932913 .edgePath .path{stroke:#333;stroke-width:1.5px}#mermaid-1575352932913 .edgeLabel{background-color:#e8e8e8}#mermaid-1575352932913 .cluster rect{fill:#ffffde!important;stroke:#aa3!important;stroke-width:1px!important}#mermaid-1575352932913 .cluster text{fill:#333}#mermaid-1575352932913 div.mermaidTooltip{position:absolute;text-align:center;max-width:200px;padding:2px;font-family:trebuchet ms,verdana,arial;font-size:12px;background:#ffffde;border:1px solid #aa3;border-radius:2px;pointer-events:none;z-index:100}#mermaid-1575352932913 .actor{stroke:#ccf;fill:#ececff}#mermaid-1575352932913 text.actor{fill:#000;stroke:none}#mermaid-1575352932913 .actor-line{stroke:grey}#mermaid-1575352932913 .messageLine0{marker-end:“url(#arrowhead)”}#mermaid-1575352932913 .messageLine0,#mermaid-1575352932913 .messageLine1{stroke-width:1.5;stroke-dasharray:“2 2”;stroke:#333}#mermaid-1575352932913 #arrowhead{fill:#333}#mermaid-1575352932913 #crosshead path{fill:#333!important;stroke:#333!important}#mermaid-1575352932913 .messageText{fill:#333;stroke:none}#mermaid-1575352932913 .labelBox{stroke:#ccf;fill:#ececff}#mermaid-1575352932913 .labelText,#mermaid-1575352932913 .loopText{fill:#000;stroke:none}#mermaid-1575352932913 .loopLine{stroke-width:2;stroke-dasharray:“2 2”;marker-end:“url(#arrowhead)”;stroke:#ccf}#mermaid-1575352932913 .note{stroke:#aa3;fill:#fff5ad}#mermaid-1575352932913 .noteText{fill:#000;stroke:none;font-family:trebuchet ms,verdana,arial;font-size:14px}#mermaid-1575352932913 .section{stroke:none;opacity:.2}#mermaid-1575352932913 .section0{fill:rgba(102,102,255,.49)}#mermaid-1575352932913 .section2{fill:#fff400}#mermaid-1575352932913 .section1,#mermaid-1575352932913 .section3{fill:#fff;opacity:.2}#mermaid-1575352932913 .sectionTitle0,#mermaid-1575352932913 .sectionTitle1,#mermaid-1575352932913 .sectionTitle2,#mermaid-1575352932913 .sectionTitle3{fill:#333}#mermaid-1575352932913 .sectionTitle{text-anchor:start;font-size:11px;text-height:14px}#mermaid-1575352932913 .grid .tick{stroke:#d3d3d3;opacity:.3;shape-rendering:crispEdges}#mermaid-1575352932913 .grid path{stroke-width:0}#mermaid-1575352932913 .today{fill:none;stroke:red;stroke-width:2px}#mermaid-1575352932913 .task{stroke-width:2}#mermaid-1575352932913 .taskText{text-anchor:middle;font-size:11px}#mermaid-1575352932913 .taskTextOutsideRight{fill:#000;text-anchor:start;font-size:11px}#mermaid-1575352932913 .taskTextOutsideLeft{fill:#000;text-anchor:end;font-size:11px}#mermaid-1575352932913 .taskText0,#mermaid-1575352932913 .taskText1,#mermaid-1575352932913 .taskText2,#mermaid-1575352932913 .taskText3{fill:#fff}#mermaid-1575352932913 .task0,#mermaid-1575352932913 .task1,#mermaid-1575352932913 .task2,#mermaid-1575352932913 .task3{fill:#8a90dd;stroke:#534fbc}#mermaid-1575352932913 .taskTextOutside0,#mermaid-1575352932913 .taskTextOutside1,#mermaid-1575352932913 .taskTextOutside2,#mermaid-1575352932913 .taskTextOutside3{fill:#000}#mermaid-1575352932913 .active0,#mermaid-1575352932913 .active1,#mermaid-1575352932913 .active2,#mermaid-1575352932913 .active3{fill:#bfc7ff;stroke:#534fbc}#mermaid-1575352932913 .activeText0,#mermaid-1575352932913 .activeText1,#mermaid-1575352932913 .activeText2,#mermaid-1575352932913 .activeText3{fill:#000!important}#mermaid-1575352932913 .done0,#mermaid-1575352932913 .done1,#mermaid-1575352932913 .done2,#mermaid-1575352932913 .done3{stroke:grey;fill:#d3d3d3;stroke-width:2}#mermaid-1575352932913 .doneText0,#mermaid-1575352932913 .doneText1,#mermaid-1575352932913 .doneText2,#mermaid-1575352932913 .doneText3{fill:#000!important}#mermaid-1575352932913 .crit0,#mermaid-1575352932913 .crit1,#mermaid-1575352932913 .crit2,#mermaid-1575352932913 .crit3{stroke:#f88;fill:red;stroke-width:2}#mermaid-1575352932913 .activeCrit0,#mermaid-1575352932913 .activeCrit1,#mermaid-1575352932913 .activeCrit2,#mermaid-1575352932913 .activeCrit3{stroke:#f88;fill:#bfc7ff;stroke-width:2}#mermaid-1575352932913 .doneCrit0,#mermaid-1575352932913 .doneCrit1,#mermaid-1575352932913 .doneCrit2,#mermaid-1575352932913 .doneCrit3{stroke:#f88;fill:#d3d3d3;stroke-width:2;cursor:pointer;shape-rendering:crispEdges}#mermaid-1575352932913 .activeCritText0,#mermaid-1575352932913 .activeCritText1,#mermaid-1575352932913 .activeCritText2,#mermaid-1575352932913 .activeCritText3,#mermaid-1575352932913 .doneCritText0,#mermaid-1575352932913 .doneCritText1,#mermaid-1575352932913 .doneCritText2,#mermaid-1575352932913 .doneCritText3{fill:#000!important}#mermaid-1575352932913 .titleText{text-anchor:middle;font-size:18px;fill:#000}#mermaid-1575352932913 g.classGroup text{fill:#9370db;stroke:none;font-family:trebuchet ms,verdana,arial;font-size:10px}#mermaid-1575352932913 g.classGroup rect{fill:#ececff;stroke:#9370db}#mermaid-1575352932913 g.classGroup line{stroke:#9370db;stroke-width:1}#mermaid-1575352932913 .classLabel .box{stroke:none;stroke-width:0;fill:#ececff;opacity:.5}#mermaid-1575352932913 .classLabel .label{fill:#9370db;font-size:10px}#mermaid-1575352932913 .relation{stroke:#9370db;stroke-width:1;fill:none}#mermaid-1575352932913 #compositionEnd,#mermaid-1575352932913 #compositionStart{fill:#9370db;stroke:#9370db;stroke-width:1}#mermaid-1575352932913 #aggregationEnd,#mermaid-1575352932913 #aggregationStart{fill:#ececff;stroke:#9370db;stroke-width:1}#mermaid-1575352932913 #dependencyEnd,#mermaid-1575352932913 #dependencyStart,#mermaid-1575352932913 #extensionEnd,#mermaid-1575352932913 #extensionStart{fill:#9370db;stroke:#9370db;stroke-width:1}#mermaid-1575352932913 .branch-label,#mermaid-1575352932913 .commit-id,#mermaid-1575352932913 .commit-msg{fill:#d3d3d3;color:#d3d3d3}#mermaid-1575352932913 {
color: rgb(58, 65, 69);
font: normal normal 400 normal 18px / 33.3px “Hiragino Sans GB”, “Heiti SC”, “Microsoft YaHei”, sans-serif, Merriweather, serif;
}
所有的 Deployment 对象都是由 Kubernetes 集群中的 DeploymentController 进行管理,家下来我们将开始介绍该控制器的实现原理。
实现原理
DeploymentController 作为管理 Deployment 资源的控制器,会在启动时通过 Informer 监听三种不同资源的通知,Pod、ReplicaSet 和 Deployment,这三种资源的变动都会触发 DeploymentController 中的回调。
#mermaid-1575352933069 .label{font-family:trebuchet ms,verdana,arial;color:#333}#mermaid-1575352933069 .node circle,#mermaid-1575352933069 .node ellipse,#mermaid-1575352933069 .node polygon,#mermaid-1575352933069 .node rect{fill:#ececff;stroke:#9370db;stroke-width:1px}#mermaid-1575352933069 .node.clickable{cursor:pointer}#mermaid-1575352933069 .arrowheadPath{fill:#333}#mermaid-1575352933069 .edgePath .path{stroke:#333;stroke-width:1.5px}#mermaid-1575352933069 .edgeLabel{background-color:#e8e8e8}#mermaid-1575352933069 .cluster rect{fill:#ffffde!important;stroke:#aa3!important;stroke-width:1px!important}#mermaid-1575352933069 .cluster text{fill:#333}#mermaid-1575352933069 div.mermaidTooltip{position:absolute;text-align:center;max-width:200px;padding:2px;font-family:trebuchet ms,verdana,arial;font-size:12px;background:#ffffde;border:1px solid #aa3;border-radius:2px;pointer-events:none;z-index:100}#mermaid-1575352933069 .actor{stroke:#ccf;fill:#ececff}#mermaid-1575352933069 text.actor{fill:#000;stroke:none}#mermaid-1575352933069 .actor-line{stroke:grey}#mermaid-1575352933069 .messageLine0{marker-end:“url(#arrowhead)”}#mermaid-1575352933069 .messageLine0,#mermaid-1575352933069 .messageLine1{stroke-width:1.5;stroke-dasharray:“2 2”;stroke:#333}#mermaid-1575352933069 #arrowhead{fill:#333}#mermaid-1575352933069 #crosshead path{fill:#333!important;stroke:#333!important}#mermaid-1575352933069 .messageText{fill:#333;stroke:none}#mermaid-1575352933069 .labelBox{stroke:#ccf;fill:#ececff}#mermaid-1575352933069 .labelText,#mermaid-1575352933069 .loopText{fill:#000;stroke:none}#mermaid-1575352933069 .loopLine{stroke-width:2;stroke-dasharray:“2 2”;marker-end:“url(#arrowhead)”;stroke:#ccf}#mermaid-1575352933069 .note{stroke:#aa3;fill:#fff5ad}#mermaid-1575352933069 .noteText{fill:#000;stroke:none;font-family:trebuchet ms,verdana,arial;font-size:14px}#mermaid-1575352933069 .section{stroke:none;opacity:.2}#mermaid-1575352933069 .section0{fill:rgba(102,102,255,.49)}#mermaid-1575352933069 .section2{fill:#fff400}#mermaid-1575352933069 .section1,#mermaid-1575352933069 .section3{fill:#fff;opacity:.2}#mermaid-1575352933069 .sectionTitle0,#mermaid-1575352933069 .sectionTitle1,#mermaid-1575352933069 .sectionTitle2,#mermaid-1575352933069 .sectionTitle3{fill:#333}#mermaid-1575352933069 .sectionTitle{text-anchor:start;font-size:11px;text-height:14px}#mermaid-1575352933069 .grid .tick{stroke:#d3d3d3;opacity:.3;shape-rendering:crispEdges}#mermaid-1575352933069 .grid path{stroke-width:0}#mermaid-1575352933069 .today{fill:none;stroke:red;stroke-width:2px}#mermaid-1575352933069 .task{stroke-width:2}#mermaid-1575352933069 .taskText{text-anchor:middle;font-size:11px}#mermaid-1575352933069 .taskTextOutsideRight{fill:#000;text-anchor:start;font-size:11px}#mermaid-1575352933069 .taskTextOutsideLeft{fill:#000;text-anchor:end;font-size:11px}#mermaid-1575352933069 .taskText0,#mermaid-1575352933069 .taskText1,#mermaid-1575352933069 .taskText2,#mermaid-1575352933069 .taskText3{fill:#fff}#mermaid-1575352933069 .task0,#mermaid-1575352933069 .task1,#mermaid-1575352933069 .task2,#mermaid-1575352933069 .task3{fill:#8a90dd;stroke:#534fbc}#mermaid-1575352933069 .taskTextOutside0,#mermaid-1575352933069 .taskTextOutside1,#mermaid-1575352933069 .taskTextOutside2,#mermaid-1575352933069 .taskTextOutside3{fill:#000}#mermaid-1575352933069 .active0,#mermaid-1575352933069 .active1,#mermaid-1575352933069 .active2,#mermaid-1575352933069 .active3{fill:#bfc7ff;stroke:#534fbc}#mermaid-1575352933069 .activeText0,#mermaid-1575352933069 .activeText1,#mermaid-1575352933069 .activeText2,#mermaid-1575352933069 .activeText3{fill:#000!important}#mermaid-1575352933069 .done0,#mermaid-1575352933069 .done1,#mermaid-1575352933069 .done2,#mermaid-1575352933069 .done3{stroke:grey;fill:#d3d3d3;stroke-width:2}#mermaid-1575352933069 .doneText0,#mermaid-1575352933069 .doneText1,#mermaid-1575352933069 .doneText2,#mermaid-1575352933069 .doneText3{fill:#000!important}#mermaid-1575352933069 .crit0,#mermaid-1575352933069 .crit1,#mermaid-1575352933069 .crit2,#mermaid-1575352933069 .crit3{stroke:#f88;fill:red;stroke-width:2}#mermaid-1575352933069 .activeCrit0,#mermaid-1575352933069 .activeCrit1,#mermaid-1575352933069 .activeCrit2,#mermaid-1575352933069 .activeCrit3{stroke:#f88;fill:#bfc7ff;stroke-width:2}#mermaid-1575352933069 .doneCrit0,#mermaid-1575352933069 .doneCrit1,#mermaid-1575352933069 .doneCrit2,#mermaid-1575352933069 .doneCrit3{stroke:#f88;fill:#d3d3d3;stroke-width:2;cursor:pointer;shape-rendering:crispEdges}#mermaid-1575352933069 .activeCritText0,#mermaid-1575352933069 .activeCritText1,#mermaid-1575352933069 .activeCritText2,#mermaid-1575352933069 .activeCritText3,#mermaid-1575352933069 .doneCritText0,#mermaid-1575352933069 .doneCritText1,#mermaid-1575352933069 .doneCritText2,#mermaid-1575352933069 .doneCritText3{fill:#000!important}#mermaid-1575352933069 .titleText{text-anchor:middle;font-size:18px;fill:#000}#mermaid-1575352933069 g.classGroup text{fill:#9370db;stroke:none;font-family:trebuchet ms,verdana,arial;font-size:10px}#mermaid-1575352933069 g.classGroup rect{fill:#ececff;stroke:#9370db}#mermaid-1575352933069 g.classGroup line{stroke:#9370db;stroke-width:1}#mermaid-1575352933069 .classLabel .box{stroke:none;stroke-width:0;fill:#ececff;opacity:.5}#mermaid-1575352933069 .classLabel .label{fill:#9370db;font-size:10px}#mermaid-1575352933069 .relation{stroke:#9370db;stroke-width:1;fill:none}#mermaid-1575352933069 #compositionEnd,#mermaid-1575352933069 #compositionStart{fill:#9370db;stroke:#9370db;stroke-width:1}#mermaid-1575352933069 #aggregationEnd,#mermaid-1575352933069 #aggregationStart{fill:#ececff;stroke:#9370db;stroke-width:1}#mermaid-1575352933069 #dependencyEnd,#mermaid-1575352933069 #dependencyStart,#mermaid-1575352933069 #extensionEnd,#mermaid-1575352933069 #extensionStart{fill:#9370db;stroke:#9370db;stroke-width:1}#mermaid-1575352933069 .branch-label,#mermaid-1575352933069 .commit-id,#mermaid-1575352933069 .commit-msg{fill:#d3d3d3;color:#d3d3d3}#mermaid-1575352933069 {
color: rgb(58, 65, 69);
font: normal normal 400 normal 18px / 33.3px “Hiragino Sans GB”, “Heiti SC”, “Microsoft YaHei”, sans-serif, Merriweather, serif;
}
不同的事件最终都会在被过滤后进入控制器持有的队列,等待工作进程的消费,下面的这些事件都会触发 Deployment 的同步:
Deployment 的变动;
Deployment 相关的 ReplicaSet 变动;
Deployment 相关的 Pod 数量为 0 时,Pod 的删除事件;
DeploymentController 会在调用 Run 方法时启动多个工作进程,这些工作进程会运行 worker 方法从队列中读取最新的 Deployment 对象进行同步。
同步
Deployment 对象的同步都是通过以下的 syncDeployment 方法进行的,该方法包含了同步、回滚以及更新的逻辑,是同步 Deployment 资源的唯一入口:
Go
根据传入的键获取 Deployment 资源;
调用
getReplicaSetsForDeployment获取集群中与 Deployment 相关的全部 ReplicaSet;查找集群中的全部 ReplicaSet;
根据 Deployment 的选择器对 ReplicaSet 建立或者释放从属关系;
调用
getPodMapForDeployment获取当前 Deployment 对象相关的从 ReplicaSet 到 Pod 的映射;根据选择器查找全部的 Pod;
根据 Pod 的控制器 ReplicaSet 对上述 Pod 进行分类;
如果当前的 Deployment 处于暂停状态或者需要进行扩容,就会调用
sync方法同步 Deployment;在正常情况下会根据规格中的策略对 Deployment 进行更新;
Recreate策略会调用rolloutRecreate方法,它会先杀掉所有存在的 Pod 后启动新的 Pod 副本;RollingUpdate策略会调用rolloutRolling方法,根据maxSurge和maxUnavailable配置对 Pod 进行滚动更新;
这就是 Deployment 资源同步的主要流程,我们在这里可以关注一下 getReplicaSetsForDeployment 方法:
Go
该方法获取 Deployment 持有的 ReplicaSet 时会重新与集群中符合条件的 ReplicaSet 通过 ownerReferences 建立关系,执行的逻辑与 ReplicaSet 调用 AdoptPod/ReleasePod 几乎完全相同。
扩容
如果当前需要更新的 Deployment 经过 isScalingEvent 的检查发现更新事件实际上是一次扩容或者缩容,也就是 ReplicaSet 持有的 Pod 数量和规格中的 Replicas 字段并不一致,那么就会调用 sync 方法对 Deployment 进行同步:
Go
同步的过程其实比较简单,该方法会从 apiserver 中拿到当前 Deployment 对应的最新 ReplicaSet 和历史的 ReplicaSet 并调用 scale 方法开始扩容,scale 就是扩容需要执行的主要方法,我们将下面的方法分成几部分依次进行介绍:
Go
如果集群中只有一个活跃的 ReplicaSet,那么就会对该 ReplicaSet 进行扩缩容,但是如果不存在活跃的 ReplicaSet 对象,就会选择最新的 ReplicaSet 进行操作,这部分选择 ReplicaSet 的工作都是由 FindActiveOrLatest 和 scaleReplicaSetAndRecordEvent 共同完成的。
当调用 IsSaturated 方法发现当前的 Deployment 对应的副本数量已经饱和时就会删除所有历史版本 ReplicaSet 持有的 Pod 副本。
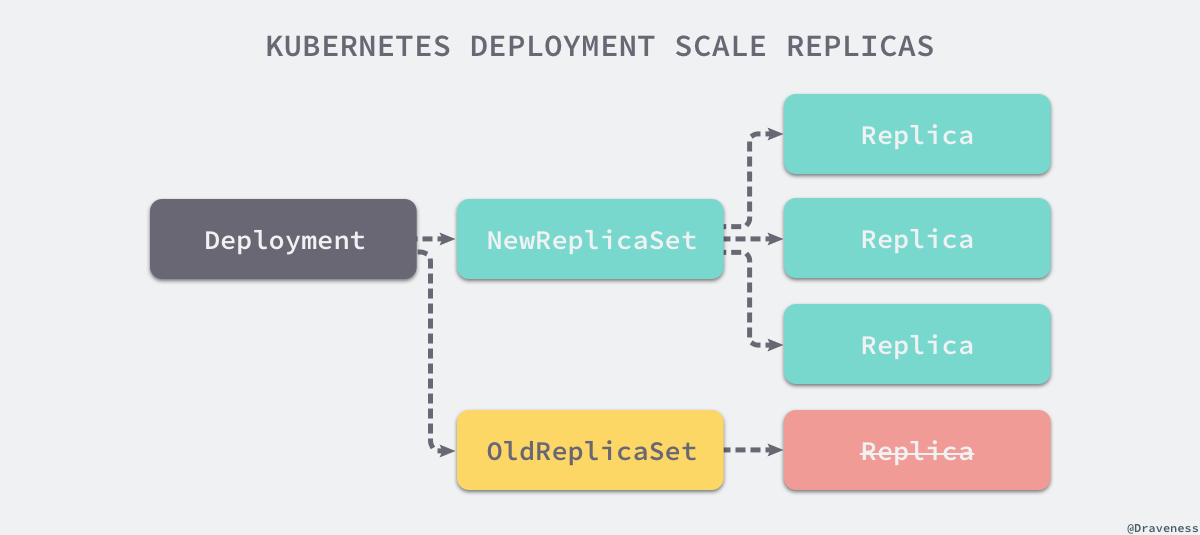
但是在 Deployment 使用滚动更新策略时,如果发现当前的 ReplicaSet 并没有饱和并且存在多个活跃的 ReplicaSet 对象就会按照比例分别对各个活跃的 ReplicaSet 进行扩容或者缩容:
Go
通过
FilterActiveReplicaSets获取所有活跃的 ReplicaSet 对象;调用
GetReplicaCountForReplicaSets计算当前 Deployment 对应 ReplicaSet 持有的全部 Pod 副本个数;根据 Deployment 对象配置的
Replicas和最大额外可以存在的副本数maxSurge以计算 Deployment 允许创建的 Pod 数量;通过
allowedSize和allRSsReplicas计算出需要增加或者删除的副本数;根据
deploymentReplicasToAdd变量的符号对 ReplicaSet 数组进行排序并确定当前的操作时扩容还是缩容;如果
deploymentReplicasToAdd > 0,ReplicaSet 将按照从新到旧的顺序依次进行扩容;如果
deploymentReplicasToAdd < 0,ReplicaSet 将按照从旧到新的顺序依次进行缩容;
maxSurge、maxUnavailable是两个处理滚动更新时需要关注的参数,我们会在滚动更新一节中具体介绍。
Go
因为当前的 Deployment 持有了多个活跃的 ReplicaSet,所以在计算了需要增加或者删除的副本个数 deploymentReplicasToAdd 之后,就会为多个活跃的 ReplicaSet 分配每个 ReplicaSet 需要改变的副本数,GetProportion 会根据以下几个参数决定最后的结果:
Deployment 期望的 Pod 副本数量;
需要新增或者减少的副本数量;
Deployment 当前通过 ReplicaSet 持有 Pod 的总数量;
Kubernetes 会在 getReplicaSetFraction 使用下面的公式计算每一个 ReplicaSet 在 Deployment 资源中的占比,最后会返回该 ReplicaSet 需要改变的副本数:
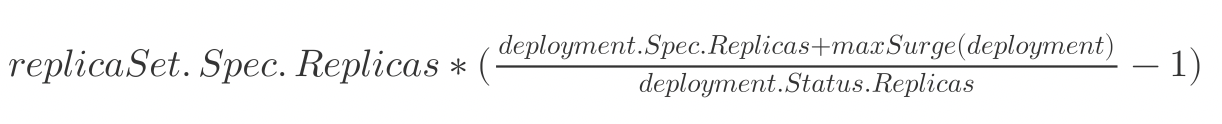
该结果又会与目前期望的剩余变化量进行对比,保证变化的副本数量不会超过期望值。
Go
在 scale 方法的最后会直接调用 scaleReplicaSet 将每一个 ReplicaSet 都扩容或者缩容到我们期望的副本数:
Go
这里会直接修改目标 ReplicaSet 规格中的 Replicas 参数和注解 deployment.kubernetes.io/desired-replicas 的值并通过 API 请求更新当前的 ReplicaSet 对象:
Bash
我们可以通过 describe 命令查看 ReplicaSet 的注解,其实能够发现当前 ReplicaSet 的期待副本数和最大副本数,deployment.kubernetes.io/desired-replicas 注解就是在上述方法中被 Kubernetes 的 DeploymentController 更新的。
重新创建
当 Deployment 使用的更新策略类型是 Recreate 时,DeploymentController 就会使用如下的 rolloutRecreate 方法对 Deployment 进行更新:
Go
利用
getAllReplicaSetsAndSyncRevision和FilterActiveReplicaSets两个方法获取 Deployment 中所有的 ReplicaSet 以及其中活跃的 ReplicaSet 对象;调用
scaleDownOldReplicaSetsForRecreate方法将所有活跃的历史 ReplicaSet 持有的副本 Pod 数目降至 0;同步 Deployment 的最新状态并等待 Pod 的终止;
在需要时通过
getAllReplicaSetsAndSyncRevision方法创建新的 ReplicaSet 并调用scaleUpNewReplicaSetForRecreate函数对 ReplicaSet 进行扩容;更新完成之后会调用
cleanupDeployment方法删除历史全部的 ReplicaSet 对象并更新 Deployment 的状态;
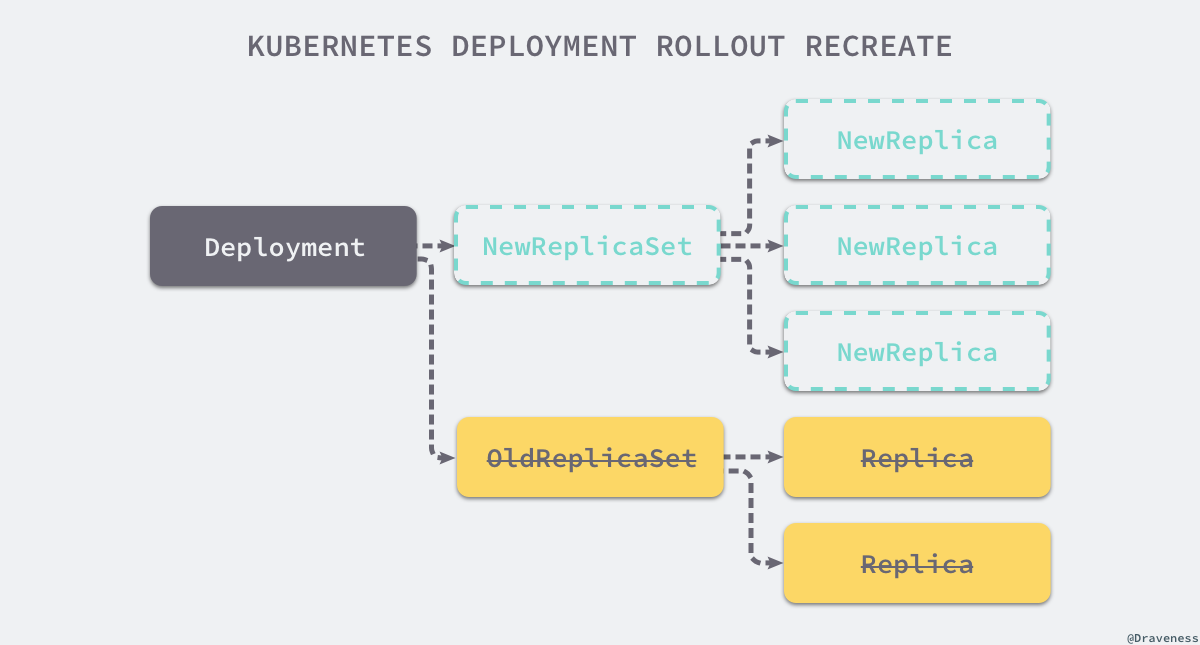
也就是说在更新的过程中,之前创建的 ReplicaSet 和 Pod 资源全部都会被删除,只是 Pod 会先被删除而 ReplicaSet 会后被删除;上述方法也会创建新的 ReplicaSet 和 Pod 对象,需要注意的是在这个过程中旧的 Pod 副本一定会先被删除,所以会有一段时间不存在可用的 Pod。
滚动更新
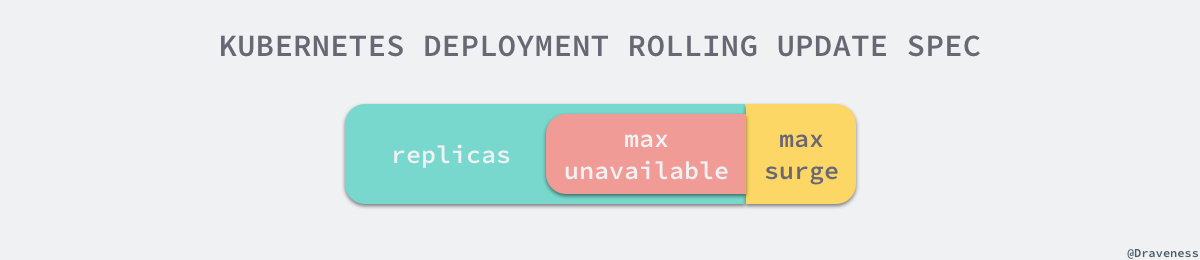
Deployment 的另一个更新策略 RollingUpdate 其实更加常见,在具体介绍滚动更新的流程之前,我们首先需要了解滚动更新策略使用的两个参数 maxUnavailable 和 maxSurge:
maxUnavailable表示在更新过程中能够进入不可用状态的 Pod 的最大值;maxSurge表示能够额外创建的 Pod 个数;
maxUnavailable 和 maxSurge 这两个滚动更新的配置都可以使用绝对值或者百分比表示,使用百分比时需要用 Replicas * Strategy.RollingUpdate.MaxSurge 公式计算相应的数值。
rolloutRolling 方法就是 DeploymentController 用于处理滚动更新的方法:
Go
首先获取 Deployment 对应的全部 ReplicaSet 资源;
通过
reconcileNewReplicaSet调解新 ReplicaSet 的副本数,创建新的 Pod 并保证额外的副本数量不超过maxSurge;通过
reconcileOldReplicaSets调解历史 ReplicaSet 的副本数,删除旧的 Pod 并保证不可用的部分数不会超过maxUnavailable;最后删除无用的 ReplicaSet 并更新 Deployment 的状态;
需要注意的是,在滚动更新的过程中,Kubernetes 并不是一次性就切换到期望的状态,即『新 ReplicaSet 运行指定数量的副本』,而是会先启动新的 ReplicaSet 以及一定数量的 Pod 副本,然后删除历史 ReplicaSet 中的副本,再启动一些新 ReplicaSet 的副本,不断对新 ReplicaSet 进行扩容并对旧 ReplicaSet 进行缩容最终达到了集群期望的状态。
当我们使用如下的 reconcileNewReplicaSet 方法对新 ReplicaSet 进行调节时,我们会发现在新 ReplicaSet 中副本数量满足期望时会直接返回,在超过期望时会进行缩容:
Go
如果 ReplicaSet 的数量不够就会调用 NewRSNewReplicas 函数计算新的副本个数,计算的过程使用了如下所示的公式:
Go
该过程总共需要考虑 Deployment 期望的副本数量、当前可用的副本数量以及新 ReplicaSet 持有的副本,还有一些最大值和最小值的限制,例如额外 Pod 数量不能超过 maxSurge、新 ReplicaSet 的 Pod 数量不能超过 Deployment 的期望数量,遵循这些规则我们就能计算出 newRSNewReplicas。
另一个滚动更新中使用的方法 reconcileOldReplicaSets 主要作用就是对历史 ReplicaSet 对象持有的副本数量进行缩容:
Go
计算历史 ReplicaSet 持有的副本总数量;
计算全部 ReplicaSet 持有的副本总数量;
根据 Deployment 期望的副本数、最大不可用副本数以及新 ReplicaSet 中不可用的 Pod 数量计算最大缩容的副本个数;
通过
cleanupUnhealthyReplicas方法清理 ReplicaSet 中处于不健康状态的副本;调用
scaleDownOldReplicaSetsForRollingUpdate方法对历史 ReplicaSet 中的副本进行缩容;
Go
该方法会使用上述简化后的公式计算这次总共能够在历史 ReplicaSet 中删除的最大 Pod 数量,并调用 cleanupUnhealthyReplicas 和 scaleDownOldReplicaSetsForRollingUpdate 两个方法进行缩容,这两个方法的实现都相对简单,它们都对历史 ReplicaSet 按照创建时间进行排序依次对这些资源进行缩容,两者的区别在于前者主要用于删除不健康的副本。
回滚
Kubernetes 中的每一个 Deployment 资源都包含有 revision 这个概念,版本的引入可以让我们在更新发生问题时及时通过 Deployment 的版本对其进行回滚,当我们在更新 Deployment 时,之前 Deployment 持有的 ReplicaSet 其实会被 cleanupDeployment 方法清理:
Go
Deployment 资源在规格中由一个 spec.revisionHistoryLimit 的配置,这个配置决定了 Kubernetes 会保存多少个 ReplicaSet 的历史版本,这些历史上的 ReplicaSet 并不会被删除,它们只是不再持有任何的 Pod 副本了,假设我们有一个 spec.revisionHistoryLimit=2 的 Deployment 对象,那么当前资源最多持有两个历史的 ReplicaSet 版本:
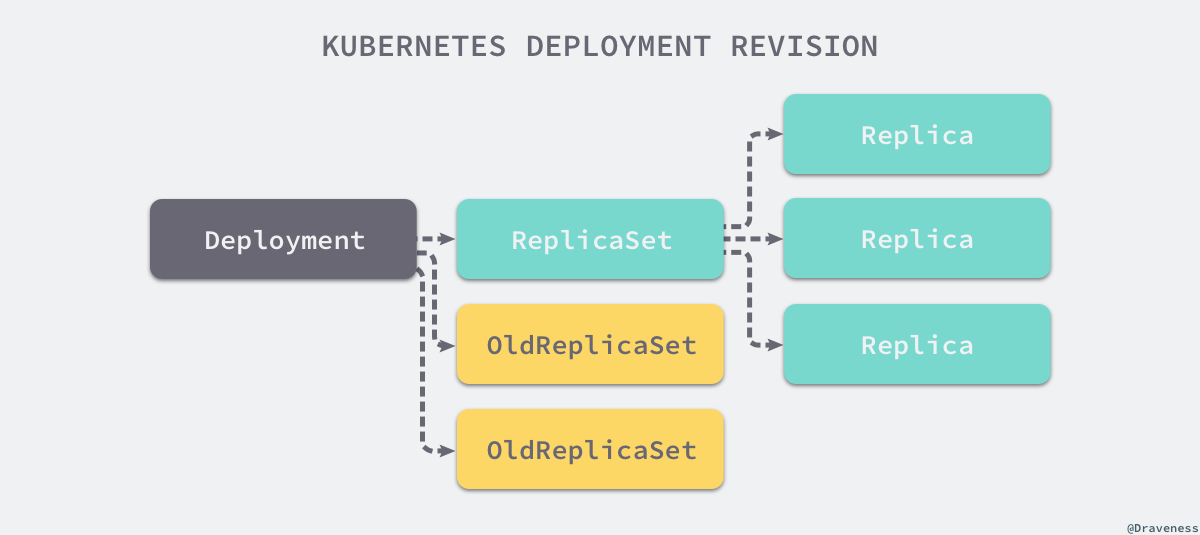
这些资源的保留能够方便 Deployment 的回滚,而回滚其实是通过 kubectl 在客户端实现的,我们可以使用如下的命令将 Deployment 回滚到上一个版本:
Bash
上述 kubectl 命令没有指定回滚到的版本号,所以在默认情况下会回滚到上一个版本,在回滚时会直接根据传入的版本查找历史的 ReplicaSet 资源,拿到这个 ReplicaSet 对应的 Pod 模板后会触发一个资源更新的请求:
Go
回滚对于 Kubernetes 服务端来说其实与其他的更新操作没有太多的区别,在每次更新时都会在 FindNewReplicaSet 函数中根据 Deployment 的 Pod 模板在历史 ReplicaSet 中查询是否有相同的 ReplicaSet 存在:
Go
如果存在规格完全相同的 ReplicaSet,就会保留这个 ReplicaSet 历史上使用的版本号并对该 ReplicaSet 重新进行扩容并对正在工作的 ReplicaSet 进行缩容以实现集群的期望状态。
Bash
在之前的 Kubernetes 版本中,客户端还会使用注解来实现 Deployment 的回滚,但是在最新的 kubectl 版本中这种使用注解的方式已经被废弃了。
暂停和恢复
Deployment 中有一个不是特别常用的功能,也就是 Deployment 进行暂停,暂停之后的 Deployment 哪怕发生了改动也不会被 Kubernetes 更新,这时我们可以对 Deployment 资源进行更新或者修复,随后当重新恢复 Deployment 时,DeploymentController 才会重新对其进行滚动更新向期望状态迁移:
Go
暂停和恢复也都是由 kubectl 在客户端实现的,其实就是通过更改 spec.paused 属性,这里的更改会变成一个更新操作修改 Deployment 资源。
Bash
如果我们使用 YAML 文件和 kubectl apply 命令来更新整个 Deployment 资源,那么其实用不到暂停这一功能,我们只需要在文件里对资源进行修改并进行一次更新就可以了,但是我们可以在出现问题时,暂停一次正在进行的滚动更新以防止错误的扩散。
删除
如果我们在 Kubernetes 集群中删除了一个 Deployment 资源,那么 Deployment 持有的 ReplicaSet 以及 ReplicaSet 持有的副本都会被 Kubernetes 中的 垃圾收集器 删除:
Go
由于与当前 Deployment 有关的 ReplicaSet 历史和最新版本都会被删除,所以对应的 Pod 副本也都会随之被删除,这些对象之间的关系都是通过 metadata.ownerReference 这一字段关联的,垃圾收集器 一节详细介绍了它的实现原理。
总结
Deployment 是 Kubernetes 中常用的对象类型,它解决了 ReplicaSet 更新的诸多问题,通过对 ReplicaSet 和 Pod 进行组装支持了滚动更新、回滚以及扩容等高级功能,通过对 Deployment 的学习既能让我们了解整个常见资源的实现也能帮助我们理解如何将 Kubernetes 内置的对象组合成更复杂的自定义资源。
相关文章
基础
数据库
分布式协调 & 服务发现
容器编排
**本文转载自 Draveness 技术博客。
原文链接:https://draveness.me/kubernetes-deployment

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论