

导语 | 点击率(click-through rate, CTR)预估是互联网平台的核心任务之一。近年来,CTR 预估技术从传统的逻辑回归,到深度学习 DeepFM, Wide&Deep, DIN, DCN 等算法落地,经历了突飞猛进的发展。本文旨在以深度 CTR 预估模型为基础,探索在应用宝推荐场景下的算法优化。文章作者:赵程,腾讯算法研发工程师。
一、业务背景
点击率(click-through rate, CTR)预估的本质是对用户/商品建模,进而计算用户的点击概率。模型的衍变经历了从经典机器学习 LR、FM 再到深度学习 DNN、Wide&Deep、双塔、DIN 等的百花齐放。本文将针对应用宝的推荐场景,展开 CTR 模型探索优化。
应用宝推荐业务主要包括首页推荐、游戏推荐等,与常见信息流推荐(新闻/视频)不同,本场景下的数据分布具有明显的差异:
App 曝光频次差异巨大:头部 app 曝光占比很高,长尾 app 曝光严重不足;
用户行为极其稀疏:用户月下载中位数、平均数较少。
面对着以上问题,当前的推荐模型主要面临着以下挑战:
在训练样本稀缺的情况下,如何保证低频特征(e.g., 长尾 appid)的充分学习;
鉴于用户行为极其稀疏,如果更精准地捕捉用户的兴趣偏好。
本文主要针对以上挑战,在当下深度 CTR 预估模型的基础上展开模型优化探索,通过引入更长周期用户行为和 app 描述文本信息,并进一步挖掘用户行为兴趣,有效促进了推荐效果提升。
二、基本框架
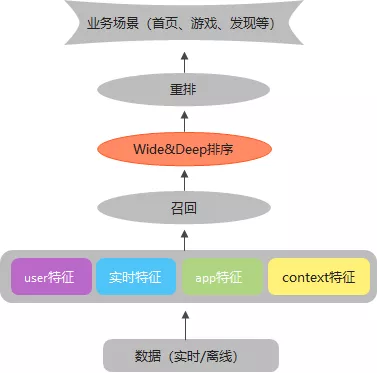
应用宝的整体推荐流程如下图所示,从底层数据流抽取特征,经过召回、排序以及重排,最终应用到实际业务场景中。本文主要针对排序模型优化。
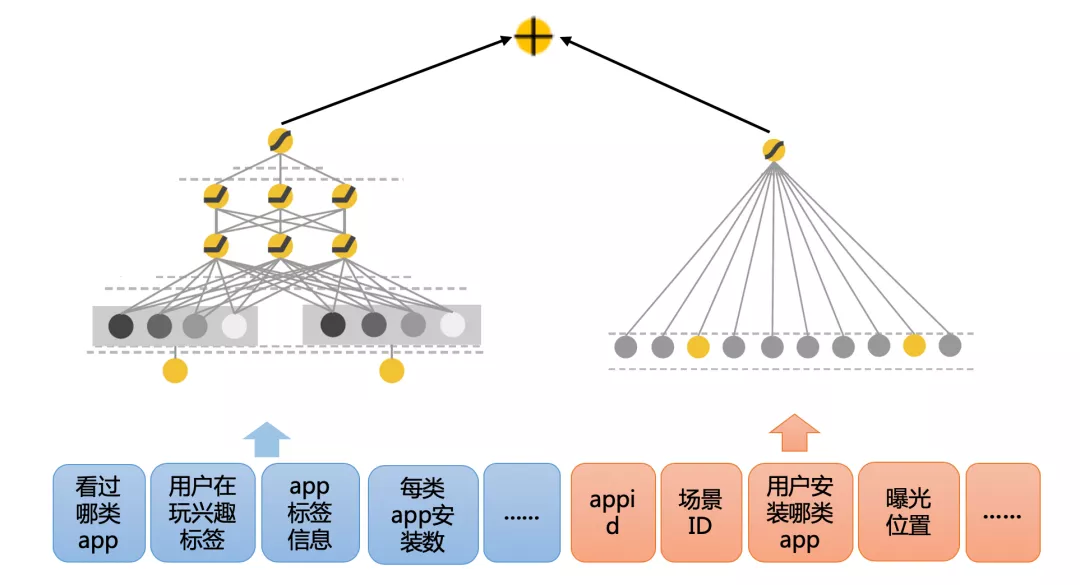
排序模型我们以业内广泛使用的 Wide&Deep 模型作为 baseline,其中,Wide 侧具有记忆能力,能够记住高频特征组合,达到准确推荐的目的;Deep 侧为了弥补交互矩阵稀疏的不足,将特征映射到低维向量表示,经过多层神经网络,使模型具有泛化能力。
三、多行为融合训练
在我们的场景中拥有很多 appid 相关的行为特征,例如用户历史点击、下载、安装等,基本的 Wide&Deep 框架会将每个行为特征映射到单独的 embedding,并单独更新。
由于每一类特征的用户行为记录十分稀疏,这种操作会造成低频特征 embedding 的训练不充分。
针对于此,我们设计了基于 appid embedding 共享的多行为融合训练机制,体现在模型中为 Deep 侧的 appid embedding 聚合共享。
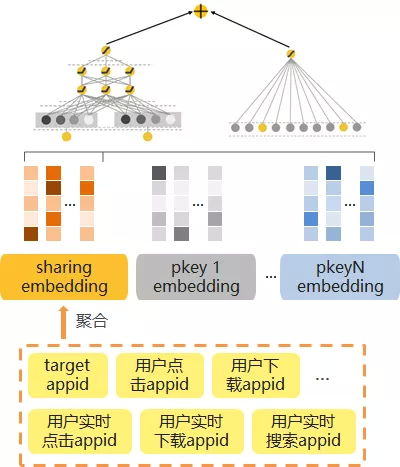
由于 appid 类的特征较多,在实际选取时,我们主要利用了用户的实时行为特征和短期行为特征,避免了由安装/卸载记录带来的数据噪音。
Wide&Deep 中 embedding 参数约占总量的 95%,通过特征共享,参数量从 2800w 降低到了 2000w,在模型保存和训练速度方面均有一定的优化。
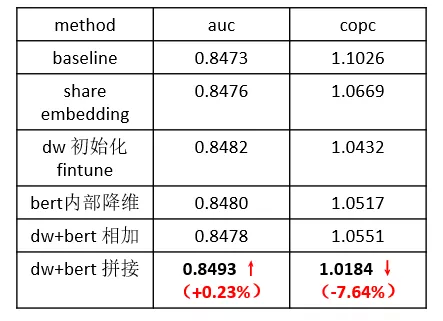
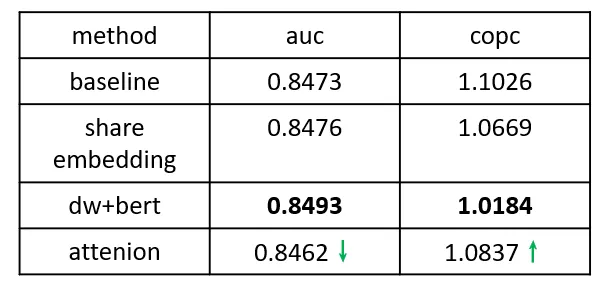
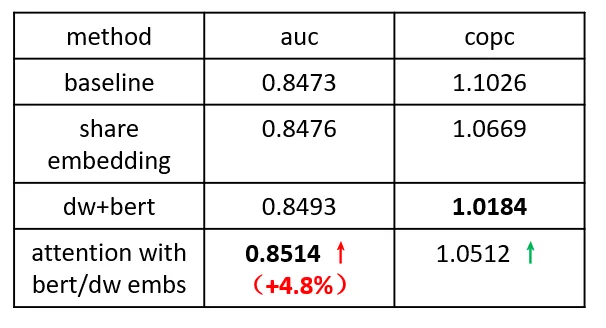
效果方面,我们主要考虑离线 auc 和 copc(pcvr/cvr,反映模型打分偏差),经过特征共享的模型效果在 auc 上基本持平,而在 copc 指标上得到了明显的优化,一定程度上缓解了模型的打分偏差。
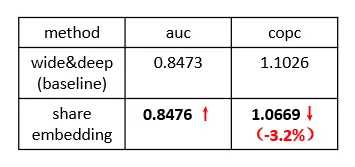
由于我们的特征中用户行为只涵盖了 15 天内近 30 个 app 的记录,对于低频 app 依然没有充足的学习样本,那么应该如何优化呢?
四、引入更长周期用户行为
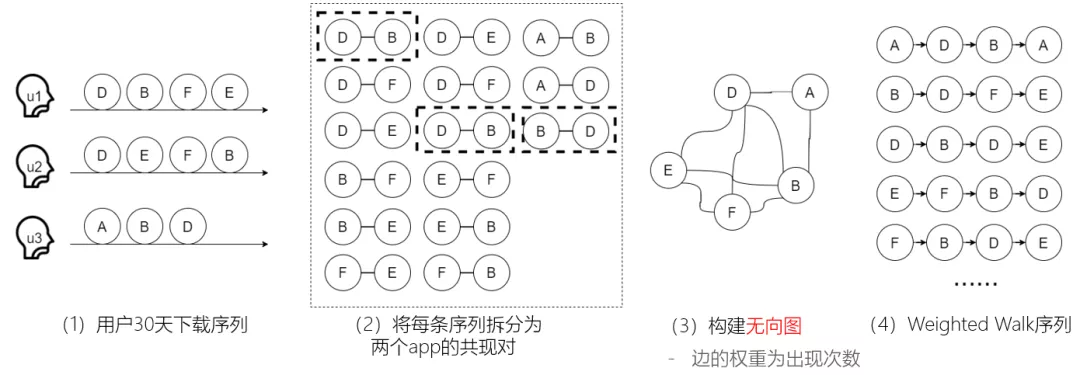
一种自然的想法便是引入更长周期的用户行为记录。近年来,以 DeepWalk, Graphsage 为代表的图模型能够较好地捕捉用户的长周期行为特点。
我们根据用户过去 30 天内的下载行为进行构图,考虑到用户在同一天中的下载序列无明显的先后关系,构建了基于共线下载的无向图,接着训练随机游走模型生成预训练的 deepwalk appid embedding,作为先验信息指导排序模型优化。
在共享 appid embedding 的基础上,我们尝试了多种训练策略。
固定初始化:直接将预训练的 deepwalk appid embedding 赋值给共享 appid embedding;
初始化微调:在 1 的基础上进行参数微调;
特征蒸馏:引入辅助 loss,度量学习得到的 embedding 与预训练 embedding 的相似度(向量点积)。
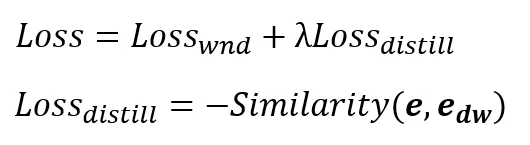
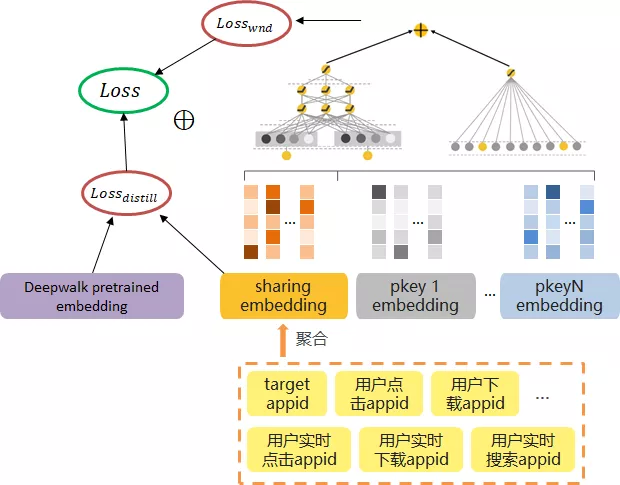
从效果来看,只有初始化微调的方式会带来一定的效果提升,说明经过 deepwalk 训练的 embedding 和 wide&deep 训练的 embedding 在向量分布上是有差异的。
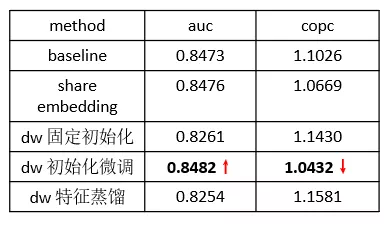
但目前为止 auc 的提升还很微弱,即使我们引入了 30 天甚至更久的用户行为数据,对于一些低频 app 依然无法充分学习,那是否还有外部信息可以利用呢?
五、引入 APP 描述文本信息
Deepwalk 的训练本质是从用户行为信息中发掘 app 间的相似关联,若直接从 app 自身的属性信息(e.g., 标题、描述文本)出发,是否也能发现相似的规律?
近年来,以 BERT 为代表的预训练语言模型在文本表示方面取得了巨大的成功,我们将每个 app 的标题和描述文本作为输入训练 tag 分类模型,得到一个高维(768 维)的向量表示,尝试指导 Wide&Deep 中的 appid embedding 学习。
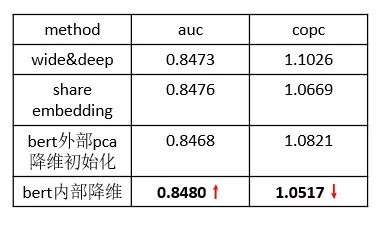
由于 Wide&Deep 模型规模的限制以及前期的经验,我们的 embedding size 往往很小(30 维/60 维),更高的维度会导致效果下降,所以需要探索一种有效的降维方式。
这里我们主要尝试了外部 pca 降维和内部通过全连层自动学习的降维方式,实验表明,在网络中进行端到端自动学习的降维方式更有效果。
六、预训练 embedding 融合
为了更直观地展现 embedding 分布,我们对 deepwalk 和 bert 预训练的 embs 分别进行了 tsne 可视化。
下图中不同的颜色表明不同的一级类目,二者均呈现了明显的类目空间聚集性,同类目的 app 自然地聚集到了一起。
同时两者的 embedding 分布也具有空间差异性,比如,bert 可视化图中的左下角部分是视频类 app,而 deepwalk 是出行类 app。

鉴于二者的差异性,我们的做法是将其分别做投影变换,投影到同一向量空间中,这里投影变换的参数随网络一起学习。融合 embedding 的方式则为拼接或相加。
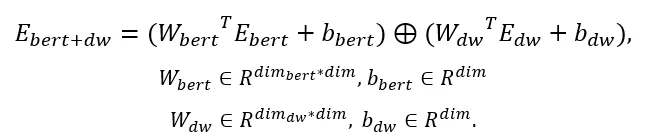
模型的整体框架图如下:
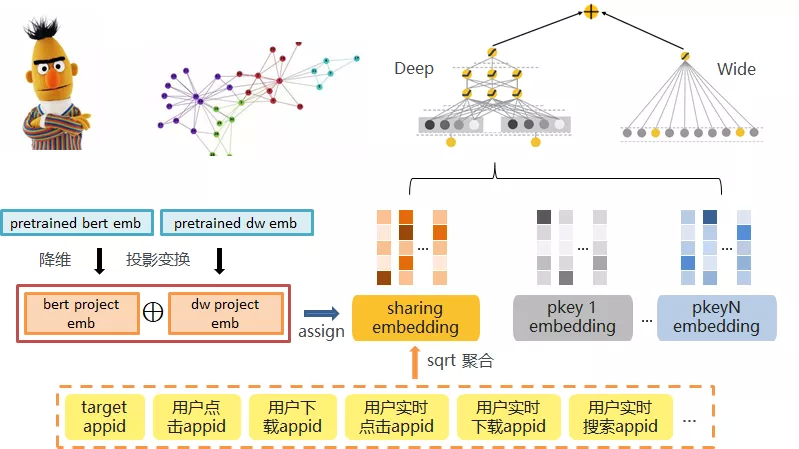
从实验效果来看,向量投影拼接的方式具有更好的表现:
为了进一步展示加入 deepwalk/bert 外部预训练 embedding 的效果,我们接着进行了 tsne 可视化,其中左边为 wide&deep appid embedding 的可视化表示,右边是融合 embedding 的可视化表示,可以发现 app 的分布从杂乱无序学到了呈现明显的聚簇,具有了一定的可解释性。

通过这个实验,我们已经知道 app embs 的初始化不同会对模型结果产生影响,那么它们分布的具体聚簇是否与模型效果有着严格的相关性,还需要更多的探索求证。
七、基于 attention 的用户行为挖掘
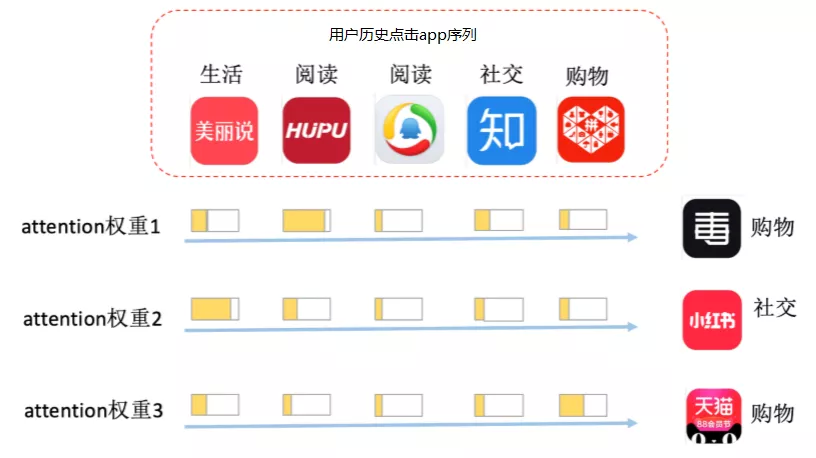
用户的历史行为对当前 app 推荐具有直观的影响,如下图中,同样的历史点击序列,对不同 app 的影响大小不同。
下图是用户近 72h 内同类目 app 点击次数(match 特征)与 cvr 的关系,我们可以发现,用户历史点击的同类目 app 次数越多,当前 app 的 cvr 也就越高。
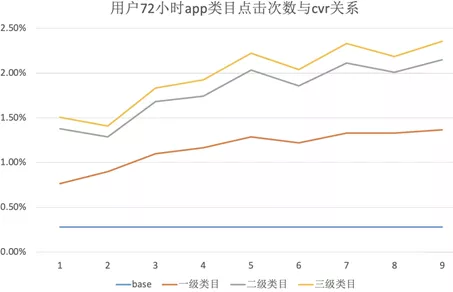
图中从 123 级类目由粗至细定位了用户的兴趣。但同类目的限制往往比较严苛,有时相关的 app 可能不在同一类目下(e.g., 和平精英、腾讯地图),而且用户的兴趣也更加广泛。
于是我们使用基于 attention 的方式对用户行为进行挖掘,希望可以从一定程度上缓解同类目限制所带来的泛化性弱的问题。但由于用户行为序列极短,一般的 attention 操作是否适用呢?
首先我们进行了一组基础 attention 的实验,额外引入 app embedding 作为 query,对用户行为序列进行 attenion 操作,具体公式和图示如下:
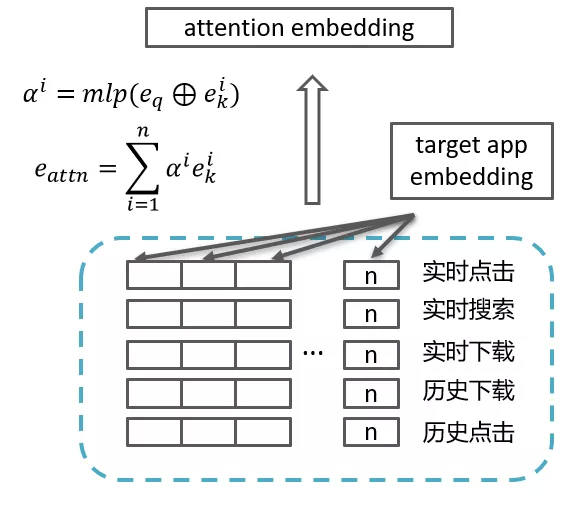
从效果来看,随机初始化 query embedding 的 attention 操作甚至会使效果变差,而且模型的训练过程往往第二个 epoch 开始就出现了过拟合。受上一步工作的影响,我们认为 app embs query 和 key 的初始化也对模型有着极大的影响。
下图中展示了在 i2i 召回中,app 相似度和 cvr 的关系。横坐标表示当前 app 和用户历史 app 的 cos 相似度的 log 值,蓝线表示 cvr。
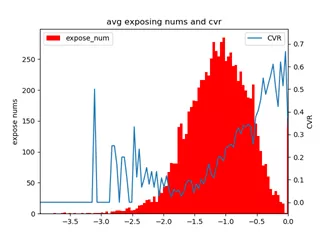
我们发现 app 召回中,cvr 随着相似度的增加而增加,用户总是倾向于喜欢与他历史行为 app 相似的 app。
体现在 deepwalk/bert 的融合 embedding 中,由于相似 app 具有明显的聚集性,它们的点乘得分也高。
在 attention 中,我们添加了以 dw+bert 融合向量为初始化 embedding 的点乘打分方式,最终效果 auc 效果提升明显。
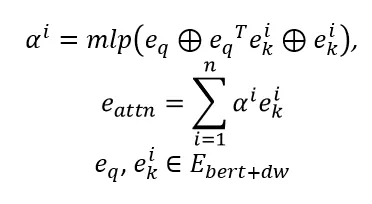
八、结语
综上,本文针对应用宝推荐场景下的两大挑战(app 曝光差异大、用户行为少),从两方面对现有的深度 CTR 模型进行了改进:
第一,引入了基于 Deepwalk 的长周期用户行为挖掘和基于 BERT 的 app 文本描述信息增强。
第二,利用 attention 机制挖掘用户的历史行为序列,并融合外部 embedding,实现用户兴趣发掘。
本文转载自公众号云加社区(ID:QcloudCommunity)。
原文链接:

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论