

文本分类是指将给定文本按照其内容判别到一个或多个预先确定的文本类别中的过程。文本分类是一种典型的有监督的学习过程,根据已经被标记的文本集合,通过学习,得到一个文本特征和文本类别之间的关系模型,然后利用这个关系模型对新文本进行类别判断。文本分类计数用于识别文档主题,并将之归类到预先定义的主题或主题集合中。
需要注意的是,多类文本分类与多标签分类并不同,其中多类分类区别于二分类问题,即在 个类别中互斥地选取一个作为输出;而多标签分类,是在 n 个标签中非互斥地选取 个标签作为输出。本文介绍了如何基于 TensorFlow 2.0 的长短期记忆网络进行多类文本分类,非常实用,希望对读者有所启迪。
对自然语言处理(Natural Language Processing,NLP)领域来说,很多创新之处都是关于如何在词向量中加入上下文。常用的方法之一就是使用递归神经网络(Recurrent Neural Networks,RNN)。下面是递归神经网络的概念:
它们利用顺序信息。
它们具备记忆能力,能够记住到目前为止计算过的内容,也就是说,我最后说的内容将影响我接下来要讲的内容。
递归神经网络是文本和语音分析的理想选择。
最常用的递归神经网络是长短期记忆网络(Long-Short Term Memory,LSTM)。
来源:https://colah.github.io/posts/2015-08-Understanding-LSTMs/
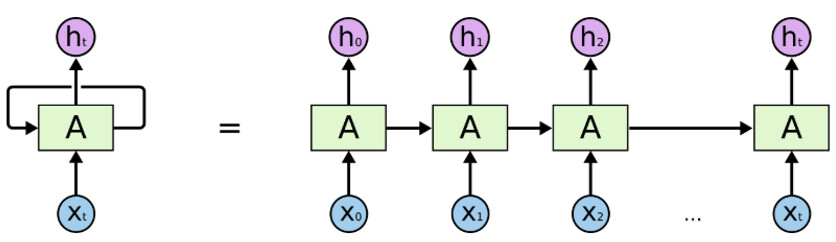
上图是递归神经网络的架构。
“A” 是前馈神经网络(Feedforward neural network)的一层。
如果我们只看右边的话,它会递归地遍历每个序列的元素。
如果我们将左边展开,它看起来将会跟右边一模一样。
译注: 前馈神经网络(Feedforward neural network),是最早发明、最简单的人工神经网络类型。在它内部,参数从输入层向输出层单向传播。和递归神经网络不通,它内部不会构成有向环。
来源:https://colah.github.io/posts/2015-08-Understanding-LSTMs
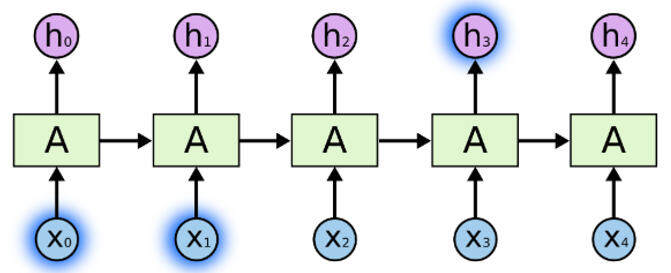
假设我们正在解决新闻文章数据集的文档分类问题。
我们输入每个单词,这些单词以某种方式相互关联。
当我们看到文章中所有的单词时,我们会在文章末尾做出预测。
递归神经网络通过传递上一次输出的输入,能够保留信息,并能够在最后利用所有信息进行预测。
来源:https://colah.github.io/posts/2015-08-Understanding-LSTMs
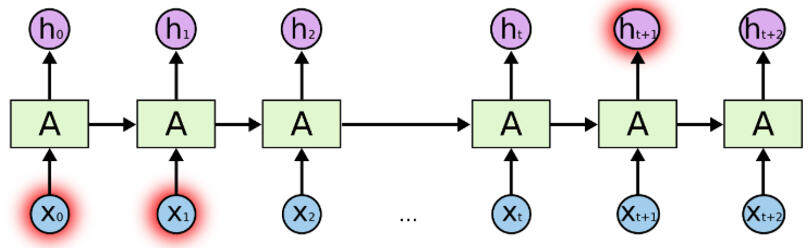
这对于短句很有效,但当我们处理一篇长文章时,将会有一个长期依赖问题。
因此,我们通常不是用普通的递归神经网络,而是使用长短期记忆网络。长短期记忆网络是一种递归神经网络,可以解决这种长期依赖问题。
译注: 长短期记忆网络(Long Short-Term Memory,LSTM),是一种时间递归神经网络,适合于处理和预测时间序列中间隔和延迟相对较长的重要事件。基于长短期记忆网络的系统可以实现机器翻译、视频分析、文档摘要、语音识别、图像识别、手写识别、控制聊天机器人、合成音乐等任务。
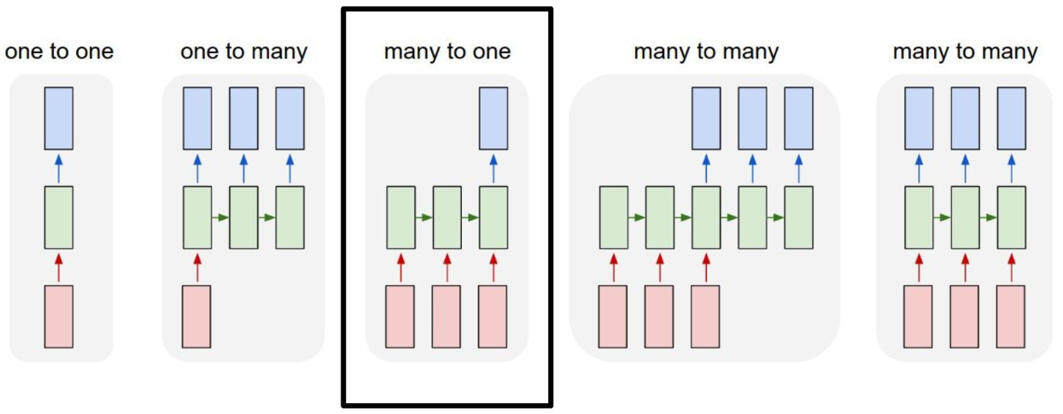
在我们的新闻文章文档分类示例中,有这种多对一的关系。输入是单词序列,而输出是单个类或标签。
现在,我们将使用 TensorFlow 2.0 和 Keras,解决一个使用长短期记忆网络的 BBC 新闻文档分类问题。数据集可以点击此链接来获取。
首先,我们导入库,并确保 TensorFlow 是正确的版本。
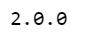
将超参数置于顶部,如下所示,便于进行更改和编辑。
届时,我们将会讲解每个超参数是如何工作的。
定义两个包含文章和标签的列表。同时,我们删除了停用词。

数据中有 2225 篇新闻文章,我们将它们分为训练集和验证集,根据我们之前设置的参数,80% 用于训练,20% 用于验证。

词法分析器(Tokenizer)为我们承担了所有繁重的工作。在我们的文章中,它将进行标记化,需要 5000 个最常见的单词。oov_token 是在遇到不可见的单词时放入一个特殊的值。这意味着我们希望 <OOV> 用于不在 word_index 中的单词。fit_on_text 将遍历所有文本,并创建如下词典:
译注: 词法分析器(Tokenizer),是计算机科学中将字符串行转换为标记(token)串行的过程。进行词法分析的进程或者函数叫作词法分析器(lexical analyzer,简称 lexer),也叫扫描器(scanner)。词法分析器一般以函数的形式存在,供语法分析器调用。
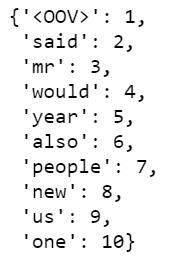
我们可以看到,“”是我们语料库中最常见的令牌,其次是“said”、“mr”等等。
完成标记化之后,下一步就是将这些标记转换为序列列表。下面是已经转换成序列的训练数据中的第 11 篇文章。
train_sequences = tokenizer.texts_to_sequences(train_articles)print(train_sequences[10])

" 图 1"
当我们为自然语言处理训练神经网络时,我们需要相同大小的序列,这就是我们为什么使用填充的原因。如果你查看一下的话,就会发现,我们的 max_length 是 200,所以我们使用 pad_sequences ,将所有文章的长度都设置为 200。结果,你会看到第一篇文章长度为 426,变成了 200;第二篇是 192,也变成了 200。以此类推。

此外,还有 padding_type 和 truncating_type, 还有所有的 post,例如,第 11 篇文章的长度是 186,我们需要填充到 200,我们就在结尾处开始填充,也就是说,填充了 14 个 0。
print(train_padded[10])

" 图 2"
对于第一篇文章,它的长度为 426,我们需要将其截断到 200,我们就在结尾处截断。
然后,我们对验证序列执行同样的操作。
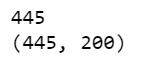
现在,我们来看一下标签。因为我们的标签是文本,因此,我们将它们进行标记。在训练时,标签应该是 numpy 数组。所以,我们要将标签列表转换为 numpy 数组,如下所示:
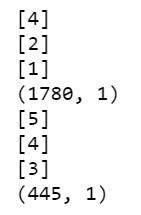
在训练深度神经网络之前,我们应该探索一下我们的原始文章和填充后的文章是什么样子的。运行下面的代码,我们浏览第 11 篇文章,可以看到,一些单词变成了“”,因为它们没有进入前 5000。

“图 3”
现在,是实施长短期记忆网络的时候了。
我们构建了一个
tf.keras.Sequential模型,从嵌入层开始。嵌入层为每个单词存储一个向量。调用时,它将单词索引序列转换为向量序列。经过训练后,具有相似意义的单词,通常会具有相似的向量。双向包装器(Bidirectional wrapper)与 LSTM 层一起使用,它通过 LSTM 层向前和向后传播输入,然后连接输出。这有助于长短期记忆网络学习长期依赖关系。然后我们将其拟合到密集神经网络(Dense Neural Network)中进行分类。
我们使用
relu代替than函数,因为这两个函数能够彼此很好地相互替代。我们添加了 6 个单位和
softmax激活的密集层(Dense Layer)。当我们有多个输出时,softmax将输出层转换为概率分布。

“图 4”
在我们的模型摘要中,我们有嵌入,双向包含长短期记忆网络,然后就是两个密集层(Dense layer)。双向的输出为 128,因为它是我们在长短期记忆网络中输入的两倍。我们也可以堆叠 LSTM 层,但我们发现,结果反而更糟。
print(set(labels))
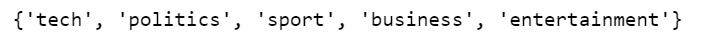
我们总共有 5 个标签,但因为我们没有对标签进行独热编码(One-hot encode),因此,我们不得不使用
sparse_categorical_crossentropy 作为损失函数,它似乎认为 0 也是一个可能的标签,而词法分析器对象是从整数 1 开始标记化,而不是整数 0。结果,尽管从未使用过 0,但最后一个密集层需要标签 0、1、2、3、4、5 的输出。
如果你希望最后一个密集层为 5,那么你就需要从训练和验证标签中减去 1。我决定保持现状。
我决定训练 10 个轮数,正如你将看到的,这是很多轮数。

“图 5”
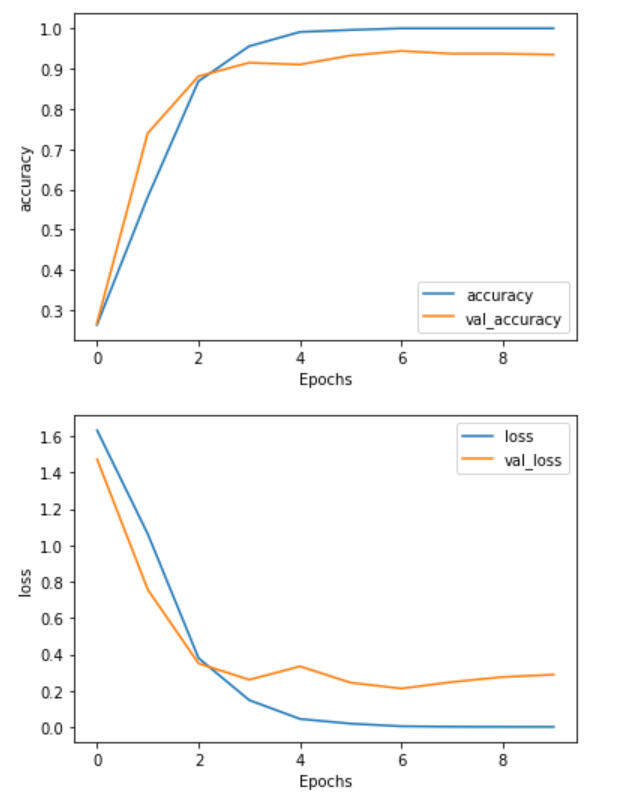
我们可能只需 3 到 4 个轮数。在训练结束时,我们可以发现有点过拟合。
在后续文章中,我们将致力于改进这一模型。
你可以在 Github 找到本文的 Jupyter notebook。
参考文献:
O’Reilly:Strata Data Conference 2019
作者介绍:
Susan Li,是加拿大多伦多的高级数据科学家。她的理想是,每次发表文章,就改变世界。
原文链接:

InfoQ高级技术编辑

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论