

“性能”是区块链领域最受关注的话题之一,如果没有高性能表现作为支撑,就无法运行快速的、执行复杂的智能合约逻辑,从而快速完成交易事务。本系列文章将以 FISCO BCOS 开源社区对区块链性能提升的研究成果为例,阐述区块链性能优化之路。
前 言
We should forget about small efficiencies, say about 97% of the time: premature optimization is the root of all evil. Yet we should not pass up our opportunities in that critical 3%.
——By Donald Knuth
『过早的优化是万恶之源』
说出这句话的计算机科学先驱 Donald Knuth 并不是反对优化,而是强调要对系统中的关键位置进行优化。假设一个 for 循环耗时 0.01 秒,即使使用循环展开等各种奇技淫巧将其性能提升 100 倍,把耗时降到 0.00001 秒,对于用户而言,也基本无法感知到。对性能问题进行量化测试之前,在代码层面进行各种炫技式优化,可能不仅提升不了性能,反而会增加代码维护难度或引入更多错误。
『没有任何证据支撑的优化是万恶之源』
在对系统施展优化措施前,一定要对系统进行详尽的性能测试,从而找出真正的性能瓶颈。奋战在 FISCO BCOS 性能优化的前线上,我们对如何使用性能测试工具来精确定位性能热点这件事积累了些许经验心得。本文将我们在优化过程中使用到的工具进行了整理汇总,以飨读者。
一、Poor Man’s Profiler
穷人的分析器,简称 PMP。尽管名字有些让人摸不着头脑,但人家真的是一种正经的性能分析手段,甚至有自己的官方网站https://poormansprofiler.org/。PMP 的原理是 Stack Sampling,通过调用第三方调试器(比如 gdb),反复获取进程中每个线程的堆栈信息,PMP 便可以得到目标进程的热点分布。
第一步,获取一定数量的线程堆栈快照:
第二步,从快照中取出函数调用栈信息,按照调用频率排序:
最后得到输出,如下图所示:

从输出中可以观察到哪些线程的哪些函数被频繁采样,进而可按图索骥找出可能存在的瓶颈。上述寥寥数行 shell 脚本便是 PMP 全部精华之所在。极度简单易用是 PMP 的最大卖点,除了依赖一个随处可见的调试器外,PMP 不需要安装任何组件,正如 PMP 作者在介绍中所言:『尽管存在更高级的分析技术,但毫无例外它们安装起来都太麻烦了……Poor man doesn’t have time. Poor man needs food.』😝。
PMP 的缺点也比较明显:gdb 的启动非常耗时,限制了 PMP 的采样频率不能太高,因此一些重要的函数调用事件可能会被遗漏,从而导致最后的 profile 结果不够精确。
但是在某些特殊场合,PMP 还是能发挥作用的,比如在一些中文技术博客中,就有开发人员提到使用 PMP 成功定位出了线上生产环境中的死锁问题,PMP 作者也称这项技术在 Facebook、Intel 等大厂中有所应用。不管怎样,这种闪烁着程序员小智慧又带点小幽默的技术,值得一瞥。
2.perf
perf 的全称是 Performance Event,在 2.6.31 版本后的 Linux 内核中均有集成,是 Linux 自带的强力性能分析工具,使用现代处理器中的特殊硬件 PMU(Performance Monitor Unit,性能监视单元)和内核性能计数器统计性能数据。
perf 的工作方式是对运行中的进程按一定频率进行中断采样,获取当前执行的函数名及调用栈。如果大部分的采样点都落在同一个函数上,则表明该函数执行的时间较长或该函数被频繁调用,可能存在性能问题。
使用 perf 需要首先对目标进程进行采样:
在上述命令中, 我们使用 perf record 指定记录性能的统计数据;使用-F 指定采样的频率为 1000Hz,即一秒钟采样 1000 次;使用-p 指定要采样的进程 ID(既 fisco-bcos 的进程 ID),我们可以直接通过 pidof 命令得到;使用-g 表示记录调用栈信息;使用 sleep 指定采样持续时间为 60 秒。
待采样完成后,perf 会将采集到的性能数据写入当前目录下的 perf.data 文件中。
上述命令会读取 perf.data 并统计每个调用栈的百分比,且按照从高到低的顺序排列,如下图所示:
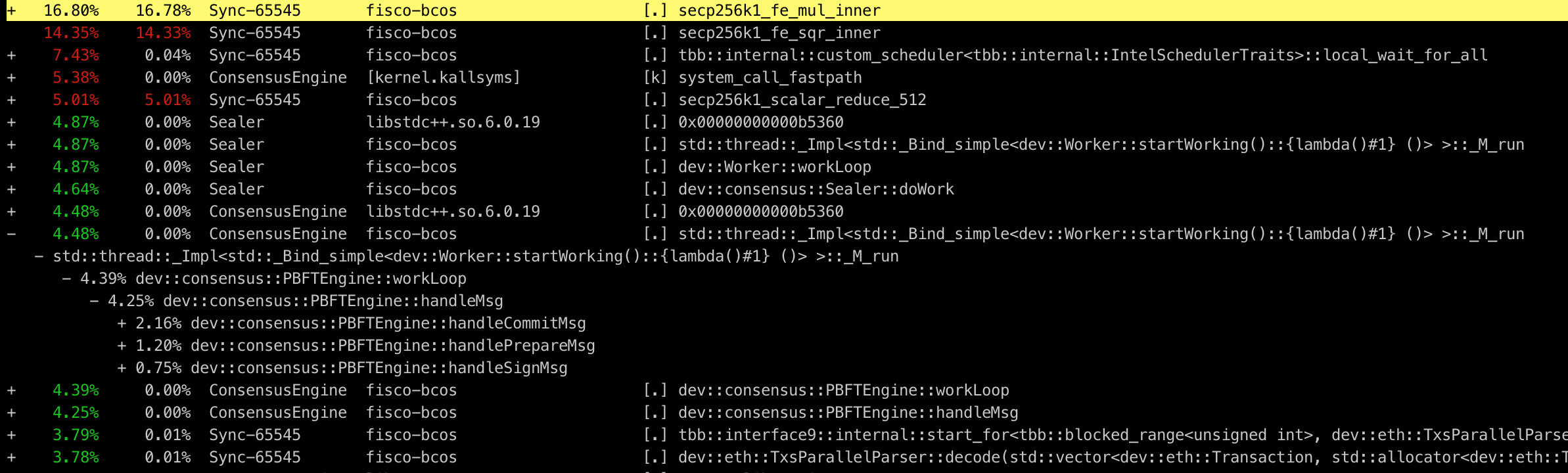
信息已足够丰富,但可读性仍然不太友好。尽管示例中 perf 的用法较为简单,但实际上 perf 能做的远不止于此。配合其他工具,perf 采样出的数据能够以更加直观清晰的方式展现在我们面前,这便是我们接下来要介绍的性能分析神器——火焰图。
3.火焰图
火焰图,即 Flame Graph,藉由系统性能大牛 Brendan Gregg 提出的动态追踪技术而发扬光大,主要用于将性能分析工具生成的数据进行可视化处理,方便开发人员一眼就能定位到性能问题所在。火焰图的使用较为简单,我们仅需将一系列工具从 github 上下载下来,置于本地任一目录即可:
3.1 CPU 火焰图
当我们发现 FISCO BCOS 性能较低时,直觉上会想弄清楚到底是哪一部分的代码拖慢了整体速度,CPU 是我们的首要考察对象。
首先使用 perf 对 FISCO BCOS 进程进行性能采样:
生成了采样数据文件后,接下来调用火焰图工具生成火焰图:
最后输出一个 SVG 格式图片,用来展示 CPU 的调用栈,如下图所示:
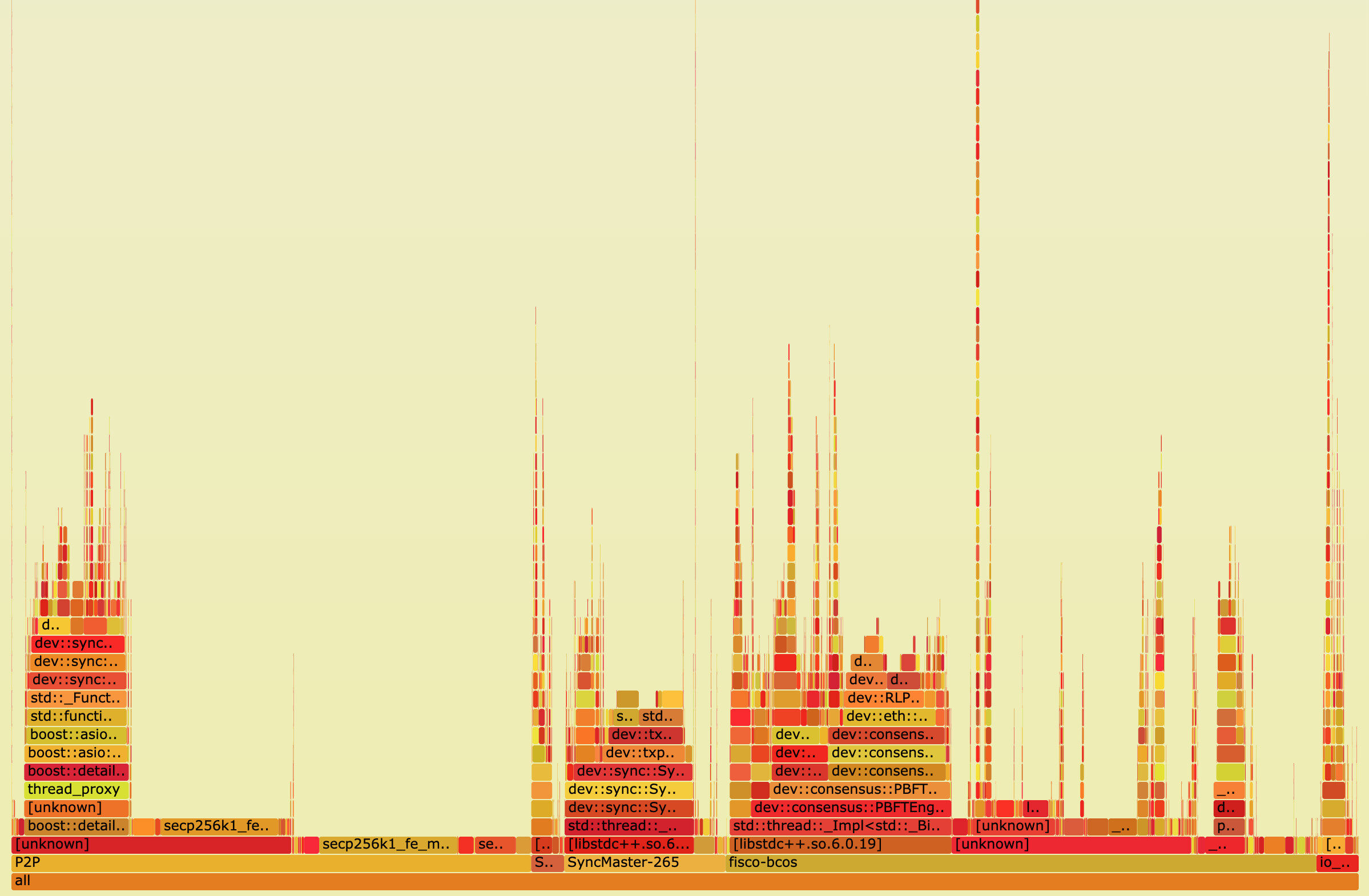
纵轴表示调用栈。每一层都是一个函数,也是其上一层的父函数,最顶部就是采样时正在执行的函数,调用栈越深,火焰就越高。
横轴表示抽样数。注意,并不是表示执行时间。若一个函数的宽度越宽,则表示它被抽到的次数越多,所有调用栈会在汇总后,按字母序列排列在横轴上。
火焰图使用了 SVG 格式,可交互性大大提高。在浏览器中打开时,火焰的每一层都会标注函数名,当鼠标悬浮其上,会显示完整的函数名、被抽样次数和占总抽样字数的百分比,如下:

点击某一层时,火焰图会水平放大,该层会占据所有宽度,并显示详细信息,点击左上角的『Reset Zoom』即可还原。下图展示了 PBFT 模块在执行区块时,各个函数的抽样数占比:
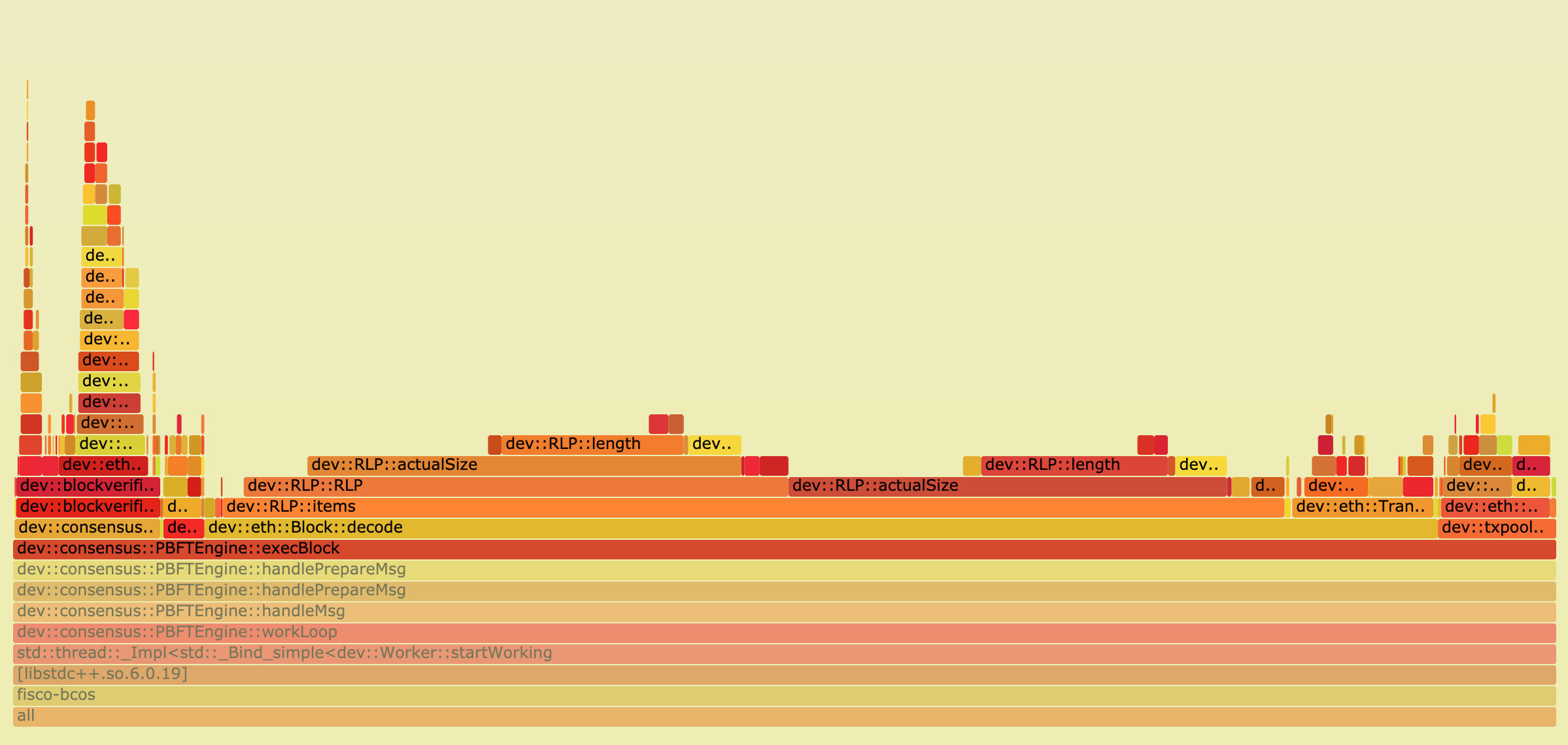
从图中可以看出,在执行区块时,主要开销在交易的解码中,这是由于传统的 RLP 编码在解码时,RLP 编码中每个对象的长度不确定,且 RLP 编码只记录了对象的个数,没记录对象的字节长度,若要获取其中的一个编码对象,必须递归解码其前序的所有对象。
因此,RLP 编码的解码过程是一个串行的过程,当区块中交易数量较大时,这一部分的开销将变得十分巨大。对此,我们提出了一种并行解码 RLP 编码的优化方案,具体实现细节可以参考上一篇文章《FISCO BCOS 中的并行化实践 》。
有了火焰图,能够非常方便地查看 CPU 的大部分时间开销都消耗在何处,进而也能针对性进行优化了。
3.2 Off-CPU 火焰图
在实现 FISCO BCOS 的并行执行交易功能时,我们发现有一个令人困惑的现象:有时即使交易量非常大,区块的负载已经打满,但是通过 top 命令观察到 CPU 的利用率仍然比较低,通常 4 核 CPU 的利用率不足 200%。在排除了交易间存在依赖关系的可能后,推测 CPU 可能陷入了 I/O 或锁等待中,因此需要确定 CPU 到底在什么地方等待。
使用 perf,我们可以轻松地了解系统中任何进程的睡眠过程,其原理是利用 perf static tracer 抓取进程的调度事件,并通过 perf inject 对这些事件进行合并,最终得到诱发进程睡眠的调用流程以及睡眠时间。
我们要通过 perf 分别记录 sched:sched_stat_sleep、sched:sched_switch、sched:sched_process_exit 三种事件,这三种事件分别表示进程主动放弃 CPU 而进入睡眠的等待事件、进程由于 I/O 和锁等待等原因被调度器切换而进入睡眠的等待事件、进程的退出事件。
在较新的 Ubuntu 或 CentOS 系统中,上述命令可能会失效,出于性能考虑,这些系统并不支持记录调度事件。好在我们可以选择另一种 profile 工具——OpenResty 的 SystemTap,来替代 perf 帮助我们收集进程调度器的性能数据。我们在 CentOS 下使用 SystemTap 时,只需要安装一些依赖 kenerl debuginfo 即可使用。
得到的 Off-CPU 火焰图如下图所示:

展开执行交易的核心函数后,位于火焰图中右侧的一堆 lock_wait 很快引起了我们的注意。分析过它们的调用栈后,我们发现这些 lock_wait 的根源,来自于我们在程序中有大量打印 debug 日志的行为。
在早期开发阶段,我们为了方便调试,添加了很多日志代码,后续也没有删除。虽然我们在测试过程中将日志等级设置得较高,但这些日志相关的代码仍会产生运行时开销,如访问日志等级状态来决定是否打印日志等。由于这些状态需要线程间互斥访问,因此导致线程由于竞争资源而陷入饥饿。
我们将这些日志代码删除后,执行交易时 4 核 CPU 的利用率瞬间升至 300%+,考虑到线程间调度和同步的开销,这个利用率已属于正常范围。这次调试的经历也提醒了我们,在追求高性能的并行代码中输出日志一定要谨慎,避免由于不必要的日志而引入无谓的性能损失。
3.3 内存火焰图
在 FISCO BCOS 早期测试阶段,我们采取的测试方式是反复执行同一区块,再计算执行一个区块平均耗时,我们发现,第一次执行区块的耗时会远远高于后续执行区块的耗时。从表象上看,这似乎是在第一次执行区块时,程序在某处分配了缓存,然而我们并不知道具体是在何处分配的缓存,因此我们着手研究了内存火焰图。
内存火焰图是一种非侵入式的旁路分析方法,相较于模拟运行进行内存分析的 Valgrid 和统计 heap 使用情况的 TC Malloc,内存火焰图可以在获取目标进程的内存分配情况的同时不干扰程序的运行。
制作内存火焰图,首先需要向 perf 动态添加探针以监控标准库的 malloc 行为,并采样捕捉正在进行内存申请/释放的函数的调用堆栈:
然后绘制内存火焰图:
得到的火焰图如下图所示:
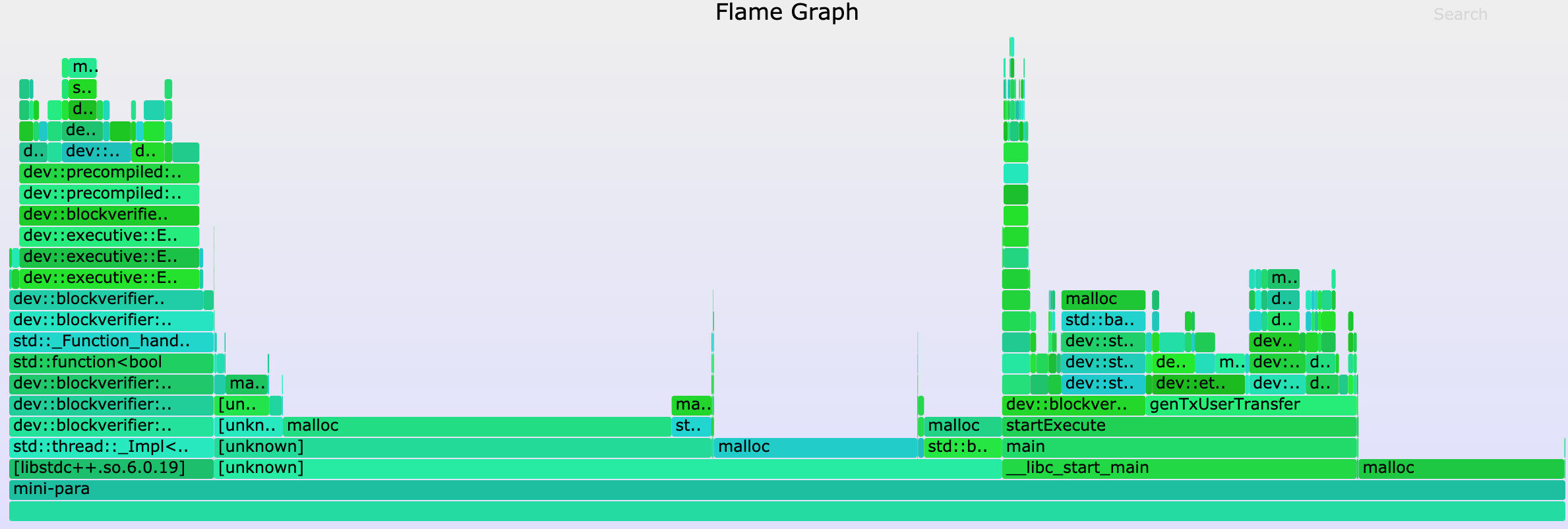
我们起初猜想,这块未知的缓存可能位于 LevelDB 的数据库连接模块或 JSON 解码模块中,但通过比对第一次执行区块和后续执行区块的内存火焰图,我们发现各个模块中 malloc 采样数目的比例大致相同,因此很快便将这些猜想否定掉了。直到结合 Off-CPU 火焰图观察,我们才注意到第一次执行区块时调用 sysmalloc 的次数异常之高。联想到 malloc 会在首次被调用时进行内存预分配的特性,我们猜想第一次执行区块耗时较多可能就是由此造成的。
为验证猜想,我们将 malloc 的预分配空间上限调低:
export MALLOC_ARENA_MAX=1
然后再次进行测试并绘制 Off-CPU 火焰图,发现虽然性能有所降低,但是第一次执行区块的耗时和 sysmalloc 调用次数,基本无异于之后执行的区块。据此,我们基本可以断定这种有趣的现象是由于 malloc 的内存预分配行为导致。
当然,这种行为是操作系统为了提高程序整体性能而引入的,我们无需对其进行干涉,况且第一个区块的执行速度较慢,对用户体验几乎也不会造成负面影响,但是再小的性能问题也是问题,作为开发人员我们应当刨根问底,做到知其然且知其所以然。
虽然这次 Memory 火焰图并没有帮我们直接定位到问题的本质原因,但通过直观的数据比对,我们能够方便地排除错误的原因猜想,减少了大量的试错成本。面对复杂的内存问题,不仅需要有敏锐的嗅觉,更需要 Memory 火焰图这类好帮手。
4.DIY 工具
尽管已经有如此多优秀的分析工具,帮助我们在性能优化前进的道路上披荆斩棘,但强大的功能有时也会赶不上性能问题的多变性,这种时候就需要我们结合自身的需求,自给自足地开发分析工具。
在进行 FISCO BCOS 的稳定性测试时,我们发现随着测试时间的增长,FISCO BCOS 节点的性能呈现衰减趋势,我们需要得到所有模块的性能趋势变化图,以排查出导致性能衰减的元凶,但现有的性能分析工具基本无法快速、便捷地实现这一需求,因此我们选择另寻他路。
首先,我们在代码中插入大量的桩点,这些桩点用于测量我们感兴趣的代码段的执行耗时,并将其附加上特殊的标识符记录于日志中:
当节点性能已经开始明显下降后,我们将其日志导出,使用自己编写的 Python 脚本将日志以区块为单位进行分割,随后读取每个区块在执行时产生的桩点日志,并解析出各个阶段的耗时,然后由脚本汇总到一张大的 Excel 表格中,最后再直接利用 Excel 自带的图表功能,绘制出所有模块的性能趋势变化图,如下图所示:
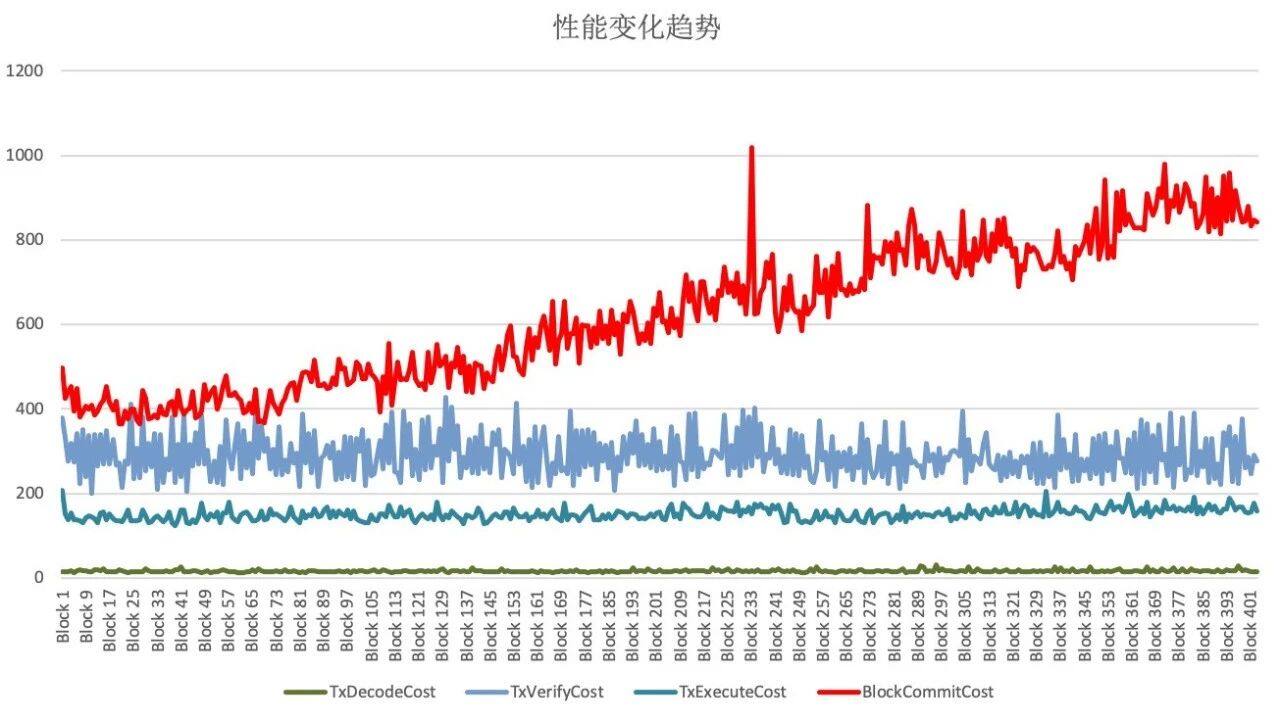
其中,横坐标为区块高度,纵坐标为执行耗时(ms),不同颜色曲线代表了不同模块的性能变化。
从图中可以看出,只有由红色曲线代表的区块落盘模块的执行耗时明显地随着数据库中数据量的增大而迅速增加,由此可以判断节点性能衰减问题的根源就出在区块落盘模块中。使用同样的方式,对区块落盘模块的各个函数进一步剖析,我们发现节点在向数据库提交新的区块数据时,调用的是 LevelDB 的 update 方法,并非 insert 方法。
两者的区别是,由于 LevelDB 以 K-V 的形式存储数据,update 方法在写入数据前会进行 select 操作,因为待 update 的数据可能在数据库中已存在,需要先按 Key 查询出 Value 的数据结构才能进行修改,而查询的耗时与数据量成正比,insert 方法则完全不需要这一步。由于我们写入的是全新的数据,因此查询这一步是不必要的,只需改变数据写入的方式,节点性能衰减的问题便迎刃而解。
相同的工具稍微变换一下用法,就能衍生出其他的用途,比如:将两批桩点性能数据放入同一张 Excel 表格中,便能够通过柱状图工具清晰地展现两次测试结果的性能变化。
下图展示的是我们在优化交易解码及验签流程时,优化前后性能柱状对比图:
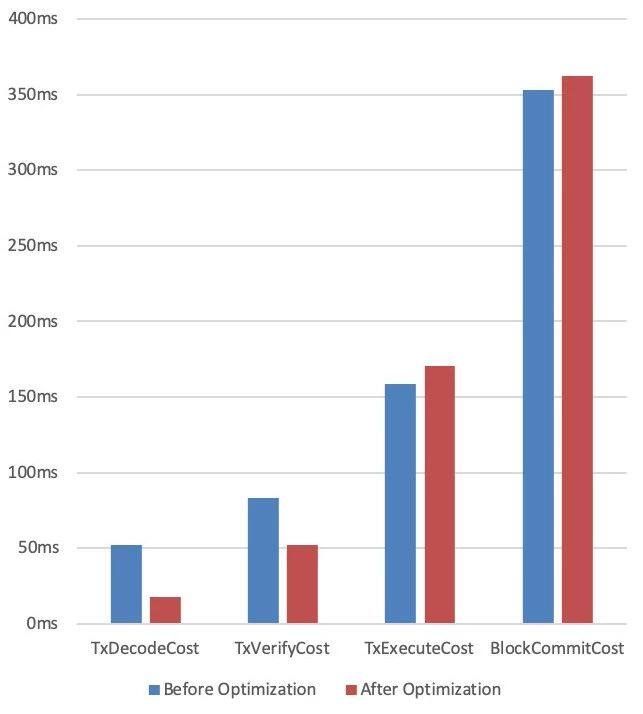
从图中可以看出,交易解码和验签流程优化后的耗时的确比优化前有所降低。借由柱状对比图,我们能够轻松地检查优化手段是否行之有效,这一点在性能优化的过程中起到了重要的指导作用。
综上可见,DIY 工具并不一定需要有多复杂,但一定可以最快地满足我们的定制化需求。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论