
宣布“Hadoop 已死”已成为一种时尚。但,Hadoop 让企业失去了对大数据的恐惧。Hadoop 反过来又释放出一种创新的良性循环,为我们今天所知的云分析和人工智能服务带来了大量市场。
最近 ZDNet 的 Big on Data 专栏撰稿人 Andrew Brust 发表的一篇关于Hadoop 项目“春季大扫除”的文章阅读数爆表,显然触动了人们的神经。
迄今为止,Apache Hadoop项目系列不再像十年前那样是大数据的中心,事实上,有关Hadoop 已死的论调已经流传很久,以至于听起来更像是“弗朗西斯科・弗朗哥最后还是死了”这则老标语的最新版本。(译注:弗朗西斯科・弗朗哥,Francisco Franco,西班牙国家元首、最高统帅、大独裁者,1975 年 9 月 27 日被宣告政治死亡,1975 年 11 月 20 日,死于帕金森症。)
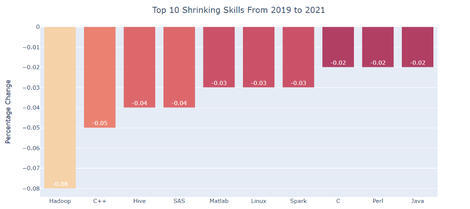
如果你想进一步了解情况,看看招聘信息就知道了。最近,Terence Shin在上个月发布的一项调查(如下图所示),通过网络搜索整理了超过 15000 个数据科学家的工作清单,清单显示,雇主对 Hadoop 技能的需求正在急剧下降,C++、Hive 和一些遗留的专用语言也在其中。顺便说一下,对了,Spark 和 Java 也同样在清单中。如果向数据工程师提出同样的问题,结果是否会有所不同?
解决方案“Hadoop”被认为是 2014 年的事情。对于大数据来说,这个世界也在不断发展。大数据之所以被贴上这样的标签,是因为在那个时候,很少有人会对多达 TB 或 PB 级的数据进行梳理,对非关系数据进行分析的能力也有限。
如今,多模型数据库已经变得越来越普遍,而大多数关系数据仓库(Data Warehouse)也增加了解析 JSON 数据和叠加图形数据视图的功能。在云存储中直接查询数据和 / 或从数据仓库进行联合查询的功能也已变得司空见惯。
正如 Andrew 所说,“春季大扫除”旨在“清除蜘蛛网”。和传统的观念相反,Hadoop 并没有死亡。在Cloudera Data Platform(CDP)中,Hadoop 生态系统的一些核心项目仍在继续,这一产品非常有活力。因为幸存下来的是 CDP 之前还没有出现的打包平台,所以我们不再称之为 Hadoop 了。现在,动物园里的动物都安全地关进了笼子。
用几个甚至更多的独立开源项目来组建自己的集群的想法已经过时了。既然有其他可供选择的方案(我们不仅仅是在讨论 CDP),为什么还要浪费时间手工实现 ApacheMapReduce、Hive、Ranger或者Atlas呢?至少在过去 30 年里,这一直是数据库领域的常态;当你购买 Oracle 时,你不必分别安装查询优化器和存储引擎。为什么我们用来调用 Hadoop 的数据平台会有所不同呢?
到 2020 年,对于新的项目,你的组织可能计划实施云服务,而非安装打包的软件。尽管推动云计算最初是为了转移成本,但现在更多是关于公共控制平面下的操作简化和敏捷性。
现在,有多种方法可以分析过去称为“三个 V”(Volum、Velocity、Variety,即体积、速度、种类)的数据。如今,你可以随时访问位于云对象存储中的数据,也就是事实上的数据湖(Data Lake)。
通过使用Amazon Athena等服务进行特别查询,可以实现这一点;在大多数云数据仓库服务中利用可选的联合查询功能;使用Databricks等专用服务或Azure Synapse Analytics等云数据仓库服务对数据运行Spark。由于数据仓库和数据湖之间的界限越来越模糊,现在很多人采用了模糊术语数据湖屋(Data Dakehouses),或者整合跨数据仓库和数据湖的访问,或者把数据湖变成 80% 的数据仓库。
而且我们甚至还没有涉及到人工智能和机器学习。就像早期的 Hadoop 只属于数据科学家(在数据工程师的帮助下)一样,最初机器学习和更广泛的人工智能也是如此。如今,数据科学家拥有许多工具和框架来管理他们所创建模型的生命周期。对于公民数据科学家而言,AutoML 服务使构建机器学习模型变得触手可及,而云数据仓库正在增加它自己的预打包机器学习模型,可以通过 SQL 命令来触发。
可能人们很容易忘记,仅仅在十年前,这一切似乎还是不可能发生的事情。谷歌的创新研究推动了这一领域的发展。借助谷歌文件系统,这家互联网巨头设计出了一个仅限于附加的文件系统,利用廉价磁盘的优势,突破了传统存储网络的限制。通过MapReduce,谷歌破解了这一密码,它在商品硬件上实现了几乎线性的可扩展性。在当时广泛采用的扩展性 SMP 架构中,很难做到这一点。
谷歌发表了这些论文,这对Doug Cutting和Mike Cafarella来说是件好事,他们当时正在开发一个能够索引至少 10 亿页的搜索引擎项目,发现了一条开源之路,可以大幅降低实现这样一个系统的成本。后来,社区的其他成员接过了 Cutting 和 Cafarella 的工作,例如,Facebook 开发了Hive,它提供了一种类似于 SQL 的编程语言,用来在 PB 级别梳理 PB 级各种数据集。
如今,随着经典 Hadoop 项目的采用率的下降,人们很容易忘记,Hadoop 项目的发现带来了一个良性循环,创新吞噬了年轻一代。在 Hadoop 出现的时候,数据就变得如此庞大,以至于我们不得不对数据进行计算。
随着云原生架构的出现,廉价、大量的带宽使之成为可能:再一次将更多的存储层、计算层和数据层分开。并不是说这两种方法都是正确或错误的,而是说它们适用于当时设计时就已存在的技术。这就是科技创新的周期性本质。
从 Hadoop 学到的经验突破了规模化处理的限制,从而促生了一个循环,很多旧的假设,比如 GPU 严格用于图形处理,都被抛在了一边。
Hadoop 的“遗产”不仅在于它所催生的创新良性循环,还在于它使企业能够克服对数据处理的恐惧,而且还是海量数据。
作者介绍:
Tony Baer,dbInsight LLC 的负责人,负责大数据和数据管理以及一些系统工程。领导 Ovum 的大数据研究领域,从事该行业的 25 年中,研究了数据集成、软件和数据架构、中间件和应用开发等问题。拥有多学科背景,涉及企业软件的不同层次。与他人合作出版了一些关于 Java 和 .NET 框架的早期书籍,并在多家杂志社发表过许多文章。
原文链接:
https://www.zdnet.com/article/hadoops-legacy-no-more-fear-of-data/#ftag=RSSbaffb68




