剖析 Elasticsearch 集群系列涵盖了当今最流行的分布式搜索引擎 Elasticsearch 的底层架构和原型实例。
本文是这个系列的第二篇,我们将讨论 Elasticsearch 如何处理分布式的三个 C((共识 (consensus)、并发 (concurrency) 和一致 (consistency)) 的问题、Elasticsearch 分片的内部概念,比如 translog(预写日志,WAL(Write Ahead Log)),以及 Lucene 中的段。
本系列已经得到原文著者 Ronak Nathani 的授权
在本系列的前一篇中,我们讨论了 Elasticsearch 的底层存储模型及 CRUD(创建、读取、更新和删除)操作的工作原理。在本文中,我将分享 Elasticsearch 是如何应对分布式系统中的一些基本挑战的,以及分片的内部概念。这其中包括了一些操作方面的事情,Insight Data 的工程师们已经在使用 Elasticsearch 构建的数据平台之上成功地实践并真正理解。我将在本文中主要讲述:
共识——裂脑问题及法定票数的重要性
共识是分布式系统的一项基本挑战。它要求系统中的所有进程/ 节点必须对给定数据的值/ 状态达成共识。已经有很多共识算法诸如 Raft 、 Paxos 等,从数学上的证明了是行得通的。但是,Elasticsearch 却实现了自己的共识系统 (zen discovery),Elasticsearch 之父 Shay Banon 在这篇文章中解释了其中的原因。zen discovery 模块包含两个部分:
- Ping: 执行节点使用 ping 来发现彼此
- 单播 (Unicast): 该模块包含一个主机名列表,用以控制哪些节点需要 ping 通
Elasticsearch 是端对端的系统,其中的所有节点彼此相连,有一个 master 节点保持活跃,它会更新和控制集群内的状态和操作。建立一个新的 Elasticsearch 集群要经过一次选举,选举是 ping 过程的一部分,在所有符合条件的节点中选取一个 master,其他节点将加入这个 master 节点。ping 间隔参数 **ping_interval的默认值是 1 秒,ping 超时参数ping_timeout的默认值是 3 秒。因为节点要加入,它们会发送一个请求给 master 节点,加入超时参数join_timeout的默认值是ping_timeout** 值的 20 倍。如果 master 出现问题,那么群集中的其他节点开始重新 ping 以启动另一次选举。这个 ping 的过程还可以帮助一个节点在忽然失去 master 时,通过其他节点发现 master。
注意:默认情况下,client 节点和 data 节点不参与这个选举过程。可以在elasticsearch.yml配置文件中,通过设置 **discovery.zen.master_election.filter_client属性和discovery.zen.master_election.filter_data属性为false** 来改变这种默认行为。
故障检测的原理是这样的,master 节点会 ping 所有其他节点,以检查它们是否还活着;然后所有节点 ping 回去,告诉 master 他们还活着。
如果使用默认的设置,Elasticsearch 有可能遭到裂脑问题的困扰。在网络分区的情况下,一个节点可以认为master 死了,然后选自己作为master,这就导致了一个集群内出现多个master。这可能会导致数据丢失,也可能无法正确合并数据。可以按照如下公式,根据有资格参加选举的节点数,设置法定票数属性的值,来避免爆裂的发生。
discovery.zen.minimum_master_nodes = int(# of master eligible nodes/2)+1
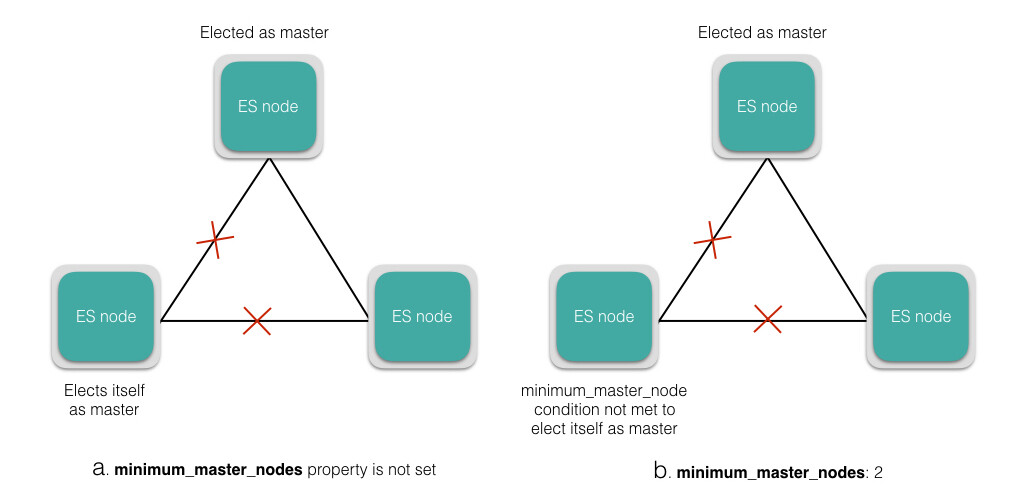
这个属性要求法定票数的节点加入新当选的 master 节点,来完成并获得新 master 节点接受的 master 身份。对于确保群集稳定性和在群集大小变化时动态地更新,这个属性是非常重要的。图 a 和 b 演示了在网络分区的情况下,设置或不设置 **minimum_master_nodes** 属性时,分别发生的现象。
注意:对于一个生产集群来说,建议使用 3 个节点专门做 master,这 3 个节点将不服务于任何客户端请求,而且在任何给定时间内总是只有 1 个活跃。
我们已经搞清楚了 Elasticsearch 中共识的处理,现在让我们来看看它是如何处理并发的。
并发
Elasticsearch 是一个分布式系统,支持并发请求。当创建 / 更新 / 删除请求到达主分片时,它也会被平行地发送到分片副本上。但是,这些请求到达的顺序可能是乱序的。在这种情况下,Elasticsearch 使用乐观并发控制,来确保文档的较新版本不会被旧版本覆盖。
每个被索引的文档都拥有一个版本号,版本号在每次文档变更时递增并应用到文档中。这些版本号用来确保有序接受变更。为了确保在我们的应用中更新不会导致数据丢失,Elasticsearch 的API 允许我们指定文件的当前版本号,以使变更被接受。如果在请求中指定的版本号比分片上存在的版本号旧,请求失败,这意味着文档已经被另一个进程更新了。如何处理失败的请求,可以在应用层面来控制。Elasticsearch 还提供了其他的锁选项,可以通过这篇来阅读。
当我们发送并发请求到Elasticsearch 后,接下来面对的问题是——如何保证这些请求的读写一致?现在,还无法清楚回答,Elasticsearch 应落在 CAP 三角形的哪条边上,我不打算在这篇文章里解决这个素来已久的争辩。
但是,我们要一起看下如何使用 Elasticsearch 实现写读一致。
一致——确保读写一致
对于写操作而言,Elasticsearch 支持的一致性级别,与大多数其他的数据库不同,允许预检查,来查看有多少允许写入的可用分片。可选的值有quorum、one和all。默认的设置为quorum,也就是说只有当大多数分片可用时才允许写操作。即使大多数分片可用,还是会因为某种原因发生写入副本失败,在这种情况下,副本被认为故障,分片将在一个不同的节点上重建。
对于读操作而言,新的文档只有在刷新时间间隔之后,才能被搜索到。为了确保搜索请求的返回结果包含文档的最新版本,可设置 replication 为sync(默认),这将使操作在主分片和副本碎片都完成后才返回写请求。在这种情况下,搜索请求从任何分片得到的返回结果都包含的是文档的最新版本。即使我们的应用为了更高的索引率而设置了replication=async,我们依然可以为搜索请求设置参数 **_preference为primary**。这样,搜索请求将查询主分片,并确保结果中的文档是最新版本。
我们已经了解了 Elasticsearch 如何处理共识、并发和一致,让我们来看看分片内部的一些主要概念,正是这些特点让 Elasticsearch 成为一个分布式搜索引擎。
Translog(预写日志)
因为关系数据库的发展,预写日志 (WAL) 或者事务日志 (translog) 的概念早已遍及数据库领域。在发生故障的时候,translog 能确保数据的完整性。translog 的基本原理是,变更必须在数据实际的改变提交到磁盘上之前,被记录下来并提交。
当新的文档被索引或者旧的文档被更新时,Lucene 索引将发生变更,这些变更将被提交到磁盘以持久化。这是一个很昂贵的操作,如果在每个请求之后都被执行。因此,这个操作在多个变更持久化到磁盘时被执行一次。正如我们在上一篇文章中描述的那样,Lucene 提交的冲洗(flush) 操作默认每30 分钟执行一次或者当translog 变得太大(默认512MB) 时执行。在这样的情况下,有可能失去2 个Lucene 提交之间的所有变更。为了避免这种问题,Elasticsearch 采用了translog。所有索引/ 删除/ 更新操作被写入到translog,在每个索引/ 删除/ 更新操作执行之后(默认情况下是每5 秒),translog 会被同步以确保变更被持久化。translog 被同步到主分片和副本之后,客户端才会收到写请求的确认。
在两次Lucene 提交之间发生硬件故障的情况下,可以通过重放translog 来恢复自最后一次Lucene 提交前的任何丢失的变更,所有的变更将会被索引所接受。
注意:建议在重启Elasticsearch 实例之前显式地执行冲洗translog,这样启动会更快,因为要重放的translog 被清空。 POST /_all/_flush命令可用于冲洗集群中的所有索引。
使用 translog 的冲洗操作,在文件系统缓存中的段被提交到磁盘,使索引中的变更持久化。现在让我们来看看 Lucene 的段。
Lucene 的段
Lucene 索引是由多个段组成,段本身是一个功能齐全的倒排索引。段是不可变的,允许 Lucene 将新的文档增量地添加到索引中,而不用从头重建索引。对于每一个搜索请求而言,索引中的所有段都会被搜索,并且每个段会消耗 CPU 的时钟周、文件句柄和内存。这意味着段的数量越多,搜索性能会越低。
为了解决这个问题,Elasticsearch 会合并小段到一个较大的段(如下图所示),提交新的合并段到磁盘,并删除那些旧的小段。
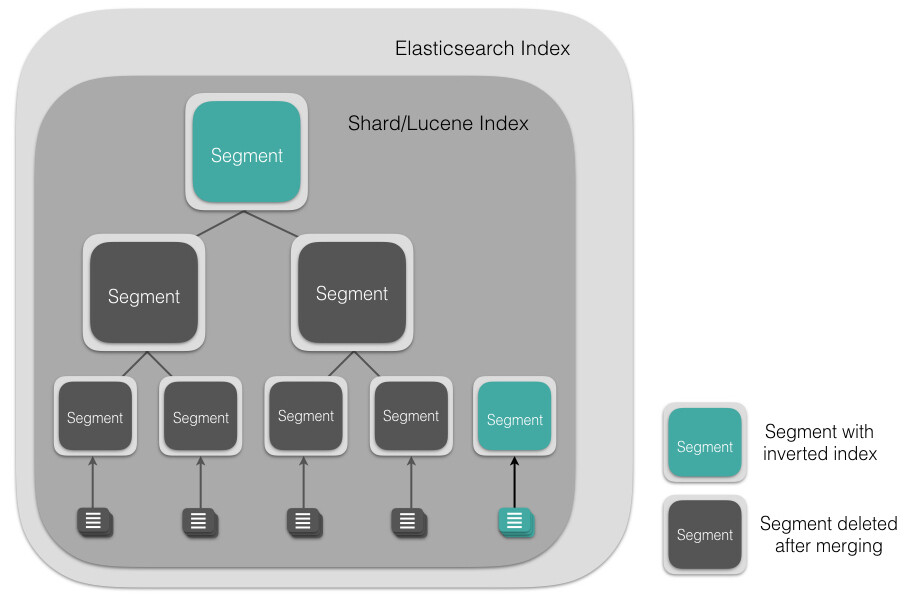
这会在后台自动执行而不中断索引或者搜索。由于段合并会耗尽资源,影响搜索性能,Elasticsearch 会节制合并过程,为搜索提供足够的可用资源。
接下来有什么?
从搜索请求角度来说,一个 Elasticsearch 索引中给定分片内的所有 Lucene 段都会被搜索,但是,从 Elasticsearch 集群角度而言,获取所有匹配的文档或者深入有序结果文档是有害的。在本系列的后续文章中我们将揭晓原因,让我们来看一下接下来的主题,内容包括了一些在 Elasticsearch 中为相关性搜索结果的低延迟所做的权衡。
- Elasticsearch 准实时性方面的内容
- 为什么搜索中的深层分页是有害的?
- 搜索相关性计算中的权衡之道
查看原文地址: Anatomy of an Elasticsearch Cluster: Part II
感谢丁晓昀对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




