

2019 年 7 月 16 日,YugaByte DB 创始人兼 CTO Karthik Ranganathan在其官方博客发文宣布 YugaByte DB 已经 100%开源,遵守 Apache 2.0 开源许可。YugaByte DB 具有基于 Google Spanner 的存储架构和基于 PostgreSQL 的查询层,此次开源意味着其之前闭源的商业及企业功能现在也可以在开源项目中完全免费使用,而且即将推出的新功能也可以完全免费使用。
与 YugaByte DB 选择 100%开源不同,近段时间多家开源软件公司选择了收紧授权许可。针对这些公司的开源许可变更, Karthik Ranganathan 也发表了自己的看法,他认为:“这些公司变更开源许可表面看起来似乎都是为了和 AWS 的 DBaaS 服务抗衡,但其实真正的原因各不相同,例如 MongoDB 改为 SSPL 的主要目的其实是为了打击多年来兴起的较小的 MongoDB 托管服务商,并且想要将这部分托管云业务迁移到他们自己的 Atlas 服务;Cockroach Labs 改为 BSL 的原因是为了给自己树立一个知名度高的竞争对手;而 Confluent 的目的则真的是为了禁止 AWS 从其开发的企业功能中获利。”
以下为 Karthik Ranganathan 博客原文的译文:
我们很高兴地宣布,YugaByte DB现在已经实现了 100%开源,遵守 Apache 2.0 开源许可。这意味着之前闭源的商业以及企业功能,例如分布式备份、数据加密和只读副本,现在都可以在开源项目中完全免费的使用。并且这也同样适用于YugaByte DB即将推出的新功能,例如Change Data Capture 和 2 Data Center Deployments。
100%开源也意味着我们不再拥有 YugaByte DB 的 Community Edition 和 Enterprise Edition,只有一个 YugaByte DB 版本,那就是完全开源的版本。同时,我们宣布之前闭源的管理软件也将开源可用。以上这些修改从1.3版本开始生效,该版本于 7 月 16 日可用。
“开发人员越来越多地将PostgreSQL作为一种 Oracle 的逻辑替代方案,因为他们不再使用基于多个云上运行的、基于微服务的应用程序的单一数据库。但是PostgreSQL并不是专为云平台构建的,开源替代方案也有所限制。而Yugabyte DB通过支持PostgreSQL的现代云基础架构功能,填补了其在这一方面的空白。如今100%开源,Yugabyte DB也消除了其它使用障碍,成功吸引了在云原生平台上构建关键业务应用程序的开发人员。”
- Matt Asay,Adobe的专栏作家兼开发者生态系统负责人
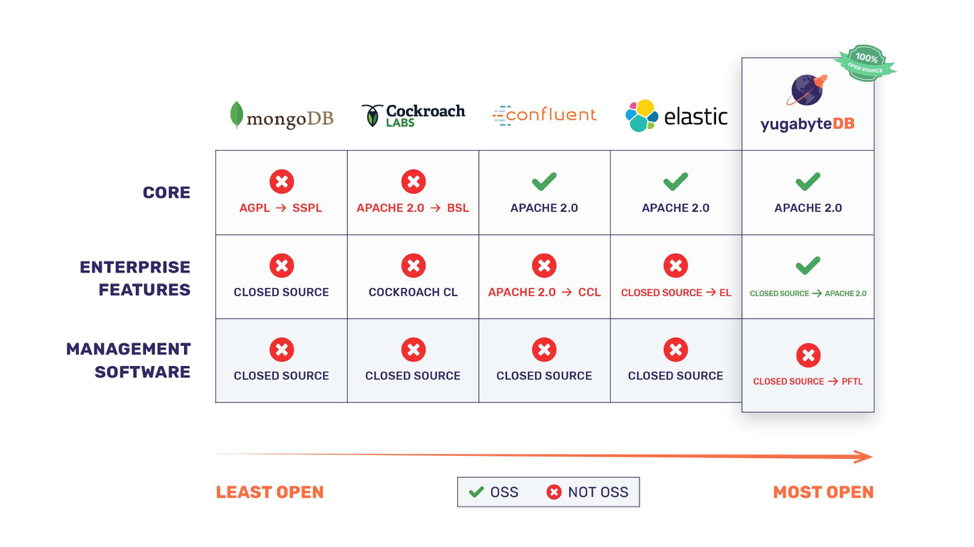
行业观察员和开源专家指出:“Yugabyte DB 的开源举措,与最近数据库和数据基础设施公司取消部分或全部核心项目开源许可有很大不同。”下图总结了 Yugabyte DB 与 MongoDB、Cockroach Labs,Confluent(Apache Kafka 背后的主要商业公司)和 Elastic(2018-2019 年)所做的开源更改。
本文将详细介绍 YugaByte DB OSS 项目和 YugaByte 作为商业 OSS 公司的目标以及开源变化背后的原因。
为什么要开源?
多年来,开源已被证明是开发和分发业务关键型基础架构软件最成功的方法。首先,它消除了用户的入门门槛,而且由于软件具有绝对的自由度,所以使得采用率的指数式增长成为可能。这种采用为快速、协作、社区驱动的功能丰富的软件开发提供了必要的快速反馈回路,同时也保持了高质量和可靠性。通过这种方法,安全性加强、生态系统集成、可扩展性框架和其他企业功能自然会变得更强。
具有免费增值层的专有基础设施软件也能做到这一点吗?是的,也可以做到,不过如果软件要成熟到相同的水平线,那么可能需要比较长的时间。此外,协作开发的损失和较慢的反馈循环意味着软件可能无法获得市场吸引力,从而逐渐消失。
开源许可变更
正如《Building a High Growth Business by Monetizing Open Source Software》文章中描写的,“开源软件和商业盈利并不矛盾。”健康的商业盈利是持续投资开源的必备条件,特别是在单一供应商的 OSS 项目中。针对那些认为 OSS 项目不能从单一供应商开源的纯粹主义者,我们也想提一个问题:“你们能否想象一个没有 MongoDB、Elastic、Confluent、Databricks、Redis Labs、InfluxData、Hashicorp 和更多商业 OSS 公司的世界?”
目前开源基础设施软件的商业模式大致可以分为以下三种:
Service, Support & Training
Open Core
Managed Service
其中,第一种和第三种比较容易理解,但是围绕着开源基础软件商业模式的讨论仍是大家关注的问题。对于数据库和数据基础设施公司而言,传统的 Open Core 意味着公司要为商业版本单独保留某些“企业级功能”,这类功能往往会包含附加功能,例如构建新数据模型、备份存储的数据、安全数据以及加密、多数据中心复制等。而管理软件位于核心之外,提供自动化集群创建、扩展、升级、备份和监控。托管云服务可以视为是具有内置云基础设施业务流程的托管管理软件。
有了以上的认知之后,我们来一起分析一下前文中提到的四家公司的开源许可变更,虽然在有些人看来,这四个事件大同小异,但其实每个案例都是独一无二的。
MongoDB:Core DB 的开源许可从 APGL 更改为 SSPL
2018 年 10 月,MongoDB 宣布将其核心数据库的开源许可从 AGPL 更改为 SSPL。由于 SSPL 不是 OSI 批准的许可证,因此这种变化实质上意味着 MongoDB 现在已经成为了专有软件。
虽然大家都认为 MongoDB 改变开源许可是为了与 AWS 提供的数据库即服务竞争,但其实 MongoDB 真正要竞争的并不是 AWS,2019 年 1 月 AWS 推出的兼容 MongoDB 的 DocumentDB 就是最好的证明,而且 MongoDB 最初的 AGPL 许可其实也有效的阻止了 AWS 按原样托管 MongoDB。
由于 MongoDB 的创新一直是基于其查询语言,所以 AWS 必须为该查询语言重建服务器,并在类似 Aurora 的存储架构上运行它。这也是 Azure Cosmos DB 在 2017 年推出兼容 MongoDB 的 API 时所采用的方法。
MongoDB 公司的管理人员不可能不清楚这些情况,所以他们更改为 SSPL 的主要目的其实是为了打击多年来兴起的较小的 MongoDB 托管服务商,并且想要将这部分托管云业务迁移到他们自己的 Atlas 服务。所以,我们看到云数据库服务公司 MLAB 在 SSPL 发布前一周被 MongoDB 收购了。
Cockroach Labs:Core DB 的开源许可从 Apache 2.0 更改为 BSL
2019 年 6 月,Cockroach Labs 更改了许可证,其核心数据库从 Apache 2.0 更改为 Business Source License(BSL),由于最初由 MariaDB 创建、采用的 BSL 也未经 OSI 批准,因此 CockroachDB 现在也是专有软件。
开源许可修改的公开原因也是因为 AWS 提供的托管云服务,不过,从现实情况来看,CockroachDB 还没有达到 AWS 感兴趣的采用水平。那么为什么 Cockroach Labs 会做出改变呢?我们认为主要原因是将对手设为 AWS 有利于宣传,尤其是把对手定位为 AWS 增长最快的服务 Amazon Aurora,因为有竞争才更有利于市场定位。
那么开源社区的反对声音怎么办呢?从目前的情况看,批评者的声音很小,时间一长,新用户未必会关心其开源许可是否发生了变化。
Confluent:Enterprise Features 从 Apache 2.0 更改为 CCL
Confluent 是 Apache Kafka 背后的主要商业公司,Apache Kafka 是一个广受欢迎的流媒体平台。在 2018 年 12 月,Confluent宣布将其部分企业功能的开源许可从 Apache 2.0 更改为 Confluent Community License(CCL)。CCL 是可用的开源许可证,但也不允许与 Confluent 商业产品竞争的托管服务使用该功能。
由于 Apache Kafka 是由 Apache Source Foundation(ASF)管理的 Apache 2.0 许可的 OSS 项目,所以可以被所有云提供商托管。在 Confluent 公告发布之前,AWS 已于 2018 年 11 月宣布了 Kafka 管理流(MSK)服务。所以,这次开源许可变更的原因很明确,就是为了禁止 AWS 从其开发的企业功能中获利。
Elastic: Enterprise Features 从闭源更改为 Elastic License
自 2015 年 10 月以来,AWS 一直在提供 Elasticsearch 服务,因此,AWS 并不是 Elastic 在 2018 年 2 月更改许可的原因,Elastic 在新的开源许可下发布了其以前的闭源商业软件 X-Pack 的源代码,这一开源许可被称为 Elastic License(EL)。
Elastic 这样做是为了促进协作开发和快速反馈循环。Apache 2.0 和 Elastic License 许可下的代码都存放在相同的 GitHub 仓库中,可用于构建纯 OSS 代码以及 OSS + EL 代码。与所有最新的开源许可一样,Elastic License 不允许来自托管服务的竞争。
DB Monetization 已死, DBaaS Monetization 长青
抛开最近的开源许可趋势不谈,我们能从 OSS DB 商业化的历史中学到什么吗?首先,我们要了解 Amazon Aurora 成功地将 PostgreSQL 和 MySQL 规模化采用实现商业化背后的原因。其次,我们要分析 MongoDB Atlas 做的同样的事情,它也实现了 MongoDB 规模化采用的商业变现。另外,还有一个数据分析市场的例子,Databricks 和 AWS 的 Apache Spark EMR 商业化的例子。
在这些例子中,直接将 OSS 商业化,只有部分公司取得了成功,但是将云服务商业化的例子都获得了成功。用户需要很长时间来建立对数据库的信任,但是这种信任一旦建立成功,他们愿意为 DBaaS 的便利性支付更多的成本,尤其是当他们的数据库采用达到了一定的规模。
我们 YugaByte 认为,如果 AWS 想要基于 OSS 项目构建托管服务,几乎没有什么可以阻止它,唯一的问题可能就在于 AWS 需要为开发 OSS 付出代价。包括 AGPL 在内的限制性许可虽然可以减缓 AWS 的速度,但不能阻止它,所以这类许可真正的影响应该是降低用户的使用。
另外,AWS 构建服务也从另一个侧面证明了该 OSS 项目的持久力,让用户可以相信,他们的投资将获得多方保护。但是,对于商业 OSS 公司来说,这意味着他们必须提供足够出色的 DBaaS 服务来与 AWS 竞争,而不是依靠核心 OSS DB 的优势。在这一方面,Elastic 就做得很好,它非常详细地强调了它与 AWS 的区别。
OSS 项目与商业产品
鉴于上文的认知,我们不仅决定将YugaByte DB 100%开源,同时也会在 OSS DB 项目和商业 DBaaS 产品之间划清界限。之前企业版的自我管理 DBaaS 功能将会重新命名为 YugaByte Platform 。同时,我们还会宣布YugaByte Cloud的早期计划,这是我们在 AWS 和 Google Cloud 上完全托管的 DBaaS 产品。

在 Polyform Free Trial License 1.0 (PFTL)下,YugaByte Platform 的源代码现在可以在与 YugaByte DB 相同的 GitHub 存储库中获得。考虑到 PFTL 存在免费试用的限制,不符合开源的定义,因此 YugaByte Platform 应该被视为专有软件。
GitHub 存储库中的默认构建目标只生成 OSS 二进制文件,以确保对基于 PFTL 的商业 DBaaS 特性不感兴趣的用户也可以拥有好的使用体验。对于有兴趣与提交者就商业特性进行协作的用户,此更改允许进行协作,包括讨论问题、提供设计反馈,甚至在上游提交自己的修复程序。这种方法类似于 Elastic,但有一个显著的区别,即 YugaByte DB 的企业特性是 OSS,而 Elastic 不是。
Oracle for the Cloud
我们从不羞于承认我们想成为云上的 Oracle 的野心。在此之前,有很多公司都为此目标做了很多努力,但是都失败了,那么我们有什么不同之处吗?
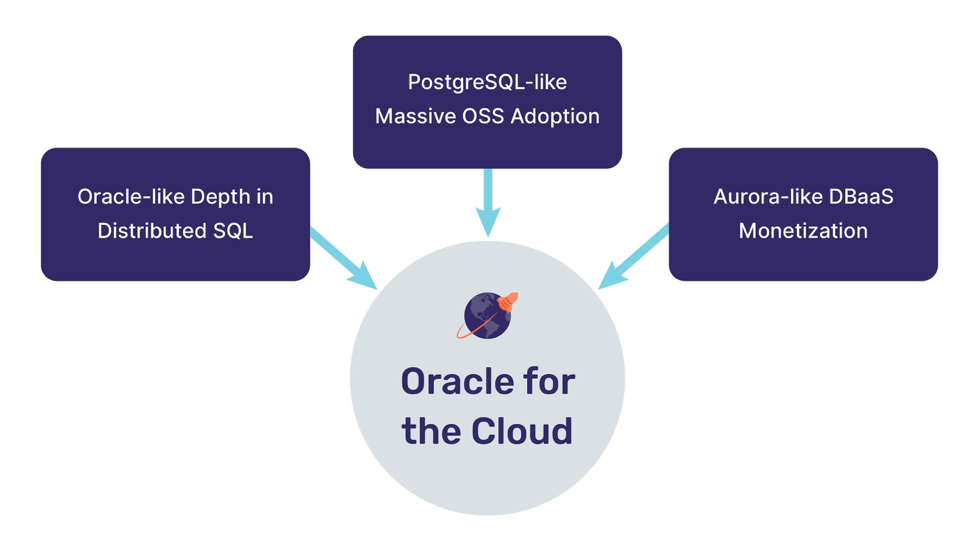
1. Oracle-like Depth in Distributed SQL
我们的团队中有很多前 Oracle 数据库工程师,所以我们很清楚,只有数据库客户端的语言在确保高性能的同时,还能提供类似于 Oracle 的数据建模灵活性,应用程序开发人员才会把它放在和 Oracle 同样重要的位置上。
而这正好是YugaByte SQL(YSQL)的用武之地。YSQL 按原样重用了 PostgreSQL 的查询层,但运行在 DocDB (YugaByte DB 受谷歌 Spanner 启发开发的分布式文档存储)之上。这种组合为 YSQL 提供了两种独特的优势,确保开发人员可以获得类似于 Oracle 的体验。
支持广泛的现有PostgreSQL结构,如存储过程、函数、触发器、扩展等。这涵盖了分布式SQL的“SQL”深度方面,现有的企业级SQL被设计用于高性能和可靠性高的分布式存储体系结构。
即将支持新的SQL构造来定义co-partitioned tables、行级地理分区以及增强SQL驱动程序,支持拓扑感知路由,从而确保高性能查询。这涵盖了分布式SQL的“分布式”深度方面,其中SQL得到了增强,可以最大限度地利用底层分布式存储体系结构。
2.类似 PostgreSQL 的大规模 OSS 采用
仅仅在分布式 SQL 中具有类似 Oracle 的深度是不够的,开发人员必须能够在自己的应用程序环境中体验到这种深度。这意味着需要与应用程序开发框架、对象关系映射器以及其它云基础架构的安装程序进行广泛和深入的集成。然后,通过开发人员将这些整合的好处带到各自的社区。通过这种方式,多年来 PostgreSQL 变得越来越受欢迎,作为 PostgreSQL 的分布式化身,我们完全可以执行类似的方法。
3.类似 Aurora 的 DBaaS 商业化
如果没有有效的商业化战略来实现对 OSS 项目的持续再投资,从长远来看,OSS 项目可能会失败。正如我们之前强调的那样,DBaaS 驱动的商业化是最佳选择。Amazon Aurora 是非常成功的完全托管 DBaaS 的典范。但是,企业可能还需要额外的灵活性来自行管理自己基础架构上的 DBaaS,这正是 YugaByte Cloud 和 YugaByte Platform 的发挥空间。
总结
YugaByte DB 具有基于 Google Spanner 的存储架构和基于 PostgreSQL 的查询层,旨在为现代应用程序在云原生基础架构上提供分布式 SQL 中类似 Oracle 的体验,这次完全开源之后,我们希望工程团队能够比以往更快地向这种云原生应用程序发展。也许,有些人会觉得我们的目标有点大,甚至是不可能实现的,但是我们会一直努力,请大家持续关注我们。
下一步规划
将 YugaByte DB与CockroachDB,Google Cloud Spanner和Amazon Aurora 等数据库进行深入比较。
支持在云或容器上使用YugaByte DB。
原文链接:
https://blog.yugabyte.com/why-we-changed-yugabyte-db-licensing-to-100-open-source/

InfoQ 编辑

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论