

背景与介绍
目前,大多数的推荐系统都将推荐一系列步骤当做一个静态的过程,并且通过一个固定的策略来实施推荐(比如离线训练一个 CTR 模型,然后上线做预测)。这样的做法有两个明显问题:无法建模用户兴趣的动态变化;只是最大化立即收益(比如点击率),忽略了长期奖赏。因此,本文提出了一种强化学习模型来建模推荐系统与用户的不断交互过程。具体:介绍了一种在线的用户和推荐系统的交互模拟器,可以在模型上线前对其进行预训练;并且验证了用户与推荐系统交互过程中实施 list-wise 推荐的重要性,因为这样能提供给用户多样性的选择。现有的强化学习大多先计算每一个 item 的 Q-value,然后通过排序得到最终的推荐结果,这样忽略了推荐列表中商品本身的关联。而 list-wise 的推荐,计算的是一整个推荐列表的 Q-value,可充分考虑列表中物品的相关性,从而提升推荐的性能。
模型选择
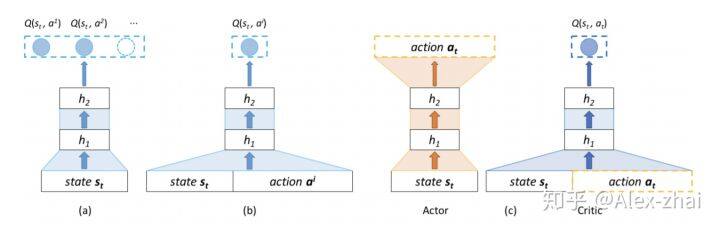
a 模型需要输入一个 state,输出所有动作的 Q-value,当 action 太多时,该结构不适合应用。
b 模型输入是 state 和一个具体的 action,然后模型输出是一个具体的 Q-value,该模型的时间复杂度非常高。
c 模型是 Actor-Critic 结构。Actor 输入一个具体的 state,输出一个 action,然后 Critic 输入这个 state 和 Actor 输出的 action,得到一个 Q-value,Actor 根据 Critic 的反馈来更新自身的策略。
Online 环境模拟器
不像一些游戏场景,可以随机采取动作并实时得到相应的反馈。在推荐场景里面,实时奖赏很难在模型上线之前得到。因此在模型上线之前,需要基于用户的历史行为数据进行线下的预训练和评估。但是,我们只有 ground-truth 的数据和相应的反馈。因此,对于整个动作空间来说(也就是所有物品的可能组合),这是非常稀疏的。这会造成两个问题,首先只能拿到部分的 state-action 对进行训练,无法对所有的情况进行建模(可能造成过拟合),其次会造成线上线下环境的不一致性。因此,需要一个模拟器来仿真没有出现过的 state-action 的 reward 值,用于训练和评估线下模型。模拟器的构建主要基于用户的历史数据,其基本思想是给定一个相似的 state 和 action,不同的用户也会作出相似的 feedback。
系统框架
MDP 五元组
状态:用户的历史浏览行为,即在推荐之前,用户点击或购买过的最新的 N 个物品。
动作:推荐给用户的商品列表。
reward:根据用户对推荐列表的反馈(忽略、点击或购买)来得到当前 state-action 的即时奖励 reward。
如果用户忽略推荐的这些商品,那么下一个时刻的 state 和当前的 state 是一样的,如果用户点击了其中的两个物品,那么下一个时刻的 state 是在当前 state 的基础上,从前面剔除两个商品同时将点击的这两个物品放在最后得到的。
实际中,如果使用离散的 indexes 去表示 items 不能建模不同 item 的之间的关系。一个常见的做法是增加一些信息来表示 item,比如 brand,价格,每月销量。本文则是使用用户和推荐系统交互信息,比如用户的购买历史。具体:将每个 item 当做一个 word,一个 session 下点击的 items 序列当做一个 sentence,通过 word-embedding 技术可以得到每个 item 的低维度向量表示。
User-Agent 交互仿真环境
仿真器主要基于历史数据,因此我们首先需要对历史真实数据的((state,action)-reward)对进行一个存储:

有了历史记忆 M 之后,仿真器可以输出从未见过的(s, a)状态动作对的奖励,该(s,a)定义为 [公式] 。首先需要计算[公式]和历史中状态-动作对 [公式] 的相似性:
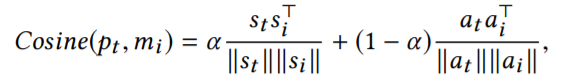
那么 [公式] 获得 [公式] 对应的奖励 [公式] 的可能性定义如下:
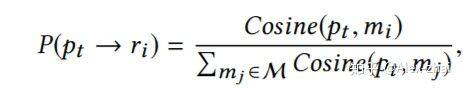
然后这种做法计算复杂度太高,需要计算[公式]和历史记忆 M 中每条记录的相似性,为了处理这个问题,本文的做法是按照奖励序列对历史记忆进行分组,来建模[公式]获得某个奖励序列的可能性。
奖励序列表示:假设我们按一定的顺序推荐了两个商品,用户对每个商品的反馈可能有忽略/点击/下单,对应的奖励分别是 0/1/5,那么我们推荐给用户这两个物品的反馈一共有九种可能的情况(0,0),(0,1),(0,5),(1,0),(1,1),(1,5),(5,0),(5,1),(5,5)。这九种情况就是我们刚才所说的奖励序列,定义为: [公式] 。
将历史记忆按照奖励序列进行分组后, [公式] 所能获得某个奖励序列的概率是:
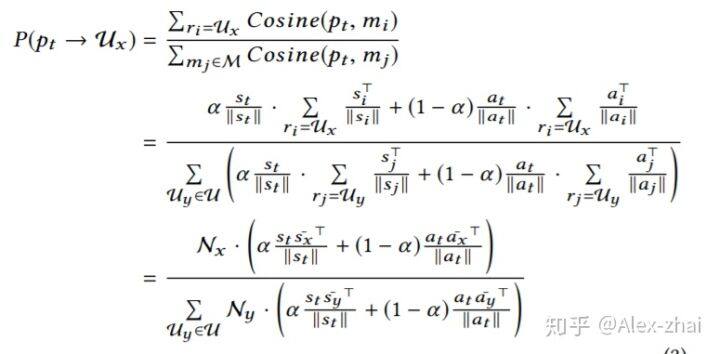
基于上述公式,得到了[公式]所获得的各个奖励序列的概率,然后进行采样得到具体的奖励序列。得到奖励序列后按照如下的公式将奖励序列转化为一个具体的奖励值:
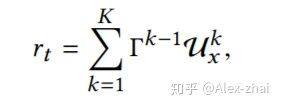
模型结构
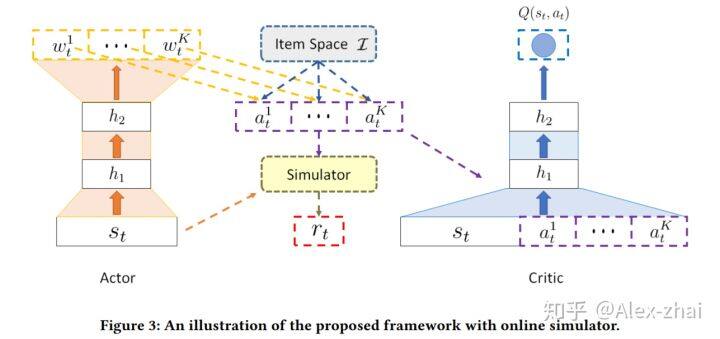
Actor 部分
输入是一个具体的 state,输出一个 K 维的向量 w,K 对应推荐列表的长度:
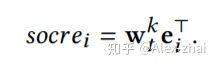
需要注意的是,state 只考虑用户的正向行为(点击购买),比如用户最近 10 次的点击。然后,用 w 和每个 item 对应的 embedding 进行线性相乘,计算每个 item 的得分,根据得分选择 k 个最高的物品作为推荐结果:

Critic 部分
Critic 部分建模的是 state-action 对应的 Q 值,需要有 Q-eval 和 Q-target 来指导模型的训练,Q-eval 通过 Critic 得到,损失函数为:
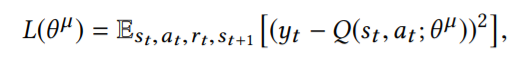
其中:
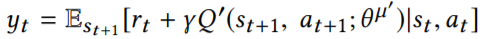
整个算法流程为:

总结
除了使用 item 的位置顺序信息外,也可以使用 items 的时间顺序信息。
该方法还没有在有 agent-user 交互的很多场景中都验证其有效果。
参考文献:
https://arxiv.org/pdf/1801.00209.pdf
https://www.jianshu.com/p/b9113332e
本文转载自 Alex-zhai 知乎账号。
原文链接:https://zhuanlan.zhihu.com/p/75264048

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论