

导读:众所周知,机器学习模型需要大量的计算、内存和功耗,这就给我们在实时推理或在计算资源有限的嵌入式设备上运行模型带来了瓶颈。更复杂、更庞大的模型带来的是更多的内存消耗,进而带来更多的功耗。这就是模型优化要解决的问题。模型优化的技术有剪枝、量化等,我们今天翻译并分享了 Amandeep Singh 的文章,讲述了如何让模型变得再小一些,以飨读者。
机器学习模型变得越来越大,计算成本也越来越高。嵌入式设备的内存、计算能力和电池都受到限制。但我们可以对模型进行优化,使其在这些设备上能够顺利运行。通过减小模型的大小,我们减少了需要执行的操作数量,从而减少了计算量。较小的模型也很容易转化为更少的内存使用,也就更节能。人们一定会认为,减少计算次数可以减少功耗,但相反,从内存访问获得的功耗比进行加法或乘法运算要高出 1000 倍左右。现在,既然没有免费的午餐,也就是说,所有一切都是有代价的,因此,我们就会失去模型的正确率。记住,这些加速的措施并不是为了训练模型,而是为了进行推理。
剪枝
剪枝(Pruning)就是删除对输出贡献不大的多余网络连接。剪枝网络的想法可以追溯到 20 世纪 90 年代,即“最优脑损伤”(Optimal Brain Damage)和“最优脑手术”(Optimal Brain Surgeon)。这些方法使用 Hessians 来确定连接的重要性,这也使得它们不适用于深度网络。剪枝方法使用迭代训练技术,即训练 → 剪枝 → 微调。剪枝后的微调恢复了网络经剪枝后丢失的正确率。一种方法是使用 L1/L2 范数对网络中的权重进行排序,并去掉最后的 x% 的权重。其他类型的方法也使用排序,使用神经元的平均激活,神经元在验证集上的激活次数为零,还有许多其他创造性的方法。这种方法是由 Han 等人在 2015 年的论文中首创的。
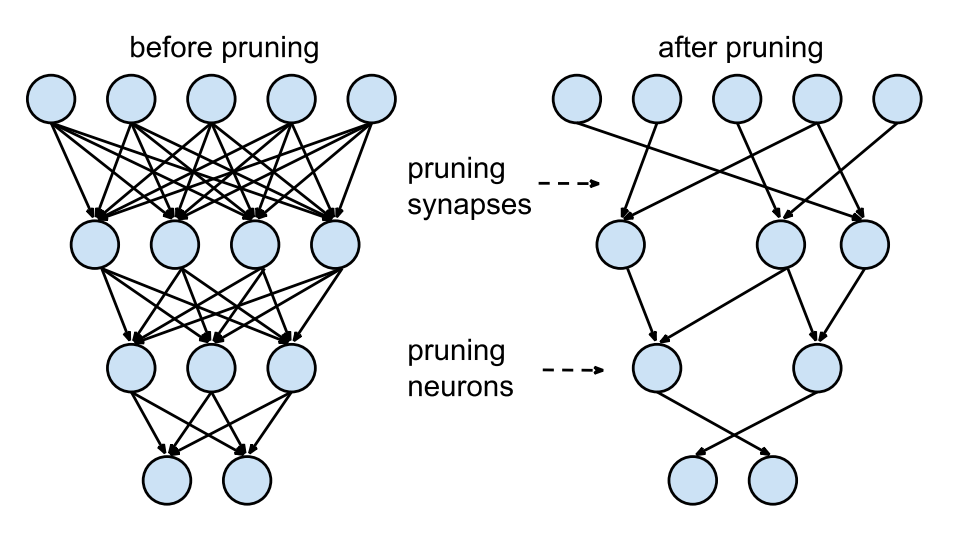
神经网络的剪枝。Han 等人
更近一些的是 2019 年,Frankle 等人在论文《彩票假说》(The Lottery Ticket Hypothesis)中发现,在每个深度神经网络中都存在一个子集,在同等数量的训练下,该子集也具有同样的正确率。这些结果适用于非结构化剪枝,即剪枝整个网络,从而得到一个稀疏网络。稀疏网络在 GPU 上效率低下,因为它们的计算没有结构。为了补修这一点,需要进行结构化剪枝,即对网络的一部分进行剪枝,例如某一层或某一通道。Liu 等人发现,前面讨论的彩票假说在这里并不适用。相反,他们发现,在剪枝之后重新训练网络比微调更好。除了性能之外,稀疏网络还有其他用途吗?是的,正如 Ahmed 等人的论文所指出的那样,稀疏网络在噪声输入的情况下更具健壮性。在 TensorFlow(tensorflow_model_optimization 包)和 PyTorch(torch.nn.utils.prune)都支持剪枝。
要在 PyTorch 中使用剪枝,你可以从 torch.nn.utils.prune 中选择一个技术类,或者实现 BasePruningMethod 的子类。
为了对模块进行剪枝,我们可以使用 torch.nn.utils.prune 中给出的剪枝方法(基本上就是上述的类的包装器),并指定哪个模块要进行剪枝,甚至是该模块的哪个参数。
这将使用剪枝后的结果替换参数权重,并添加一个参数 weight_orig 来存储输入的未剪枝版本。剪枝掩码(pruning mask)存储为 weight_mask,并作为模块缓冲区保存。这些参数可以通过 module.named_parameters() 和 module.named_buffers() 来检查。为了实现迭代剪枝,我们可以只在下一次迭代中应用剪枝方法,这样它就可以正常工作了,这是因为 PurningContainer 在处理最终掩码的计算时,考虑到了之前使用 computer_mask 方法的剪枝。
量化
量化(Quantization)是为了限制一个权重可以取的可能值的数量,这将减少一个权重可以减少的内存,从而减小模型的大小。实现这一点的一种方法是,更改用于存储权重的浮点数的位宽。以 32 位浮点数或 FP32 到 FP16、或 8 位定点数形式存储的数字,越来越多地以 8 位整数的形式存储。减少位宽具有以下许多优点:
从 32 位转换到 8 位,可以让我们立即获得 4 倍的内存优势。
较低的位宽还意味着,我们可以在寄存器 / 高速缓存中压缩更多的数字,从而减少内存访问,进而减少时间和功耗。
整数计算总是比浮点计算要快。
之所以可行,是因为神经网络对其权重的微小扰动是非常健壮的,我们可以很轻松地舍去它们,而不会对网络的正确率产生太大的影响。此外,由于训练中使用的正则化技术,权重并不包含在非常大的范围内,因此我们不必使用过大的范围,比如,对于 32 位浮点数,取 到 就可以了。例如,在下图中,MoboileNet 中的权重值都非常接近于零。
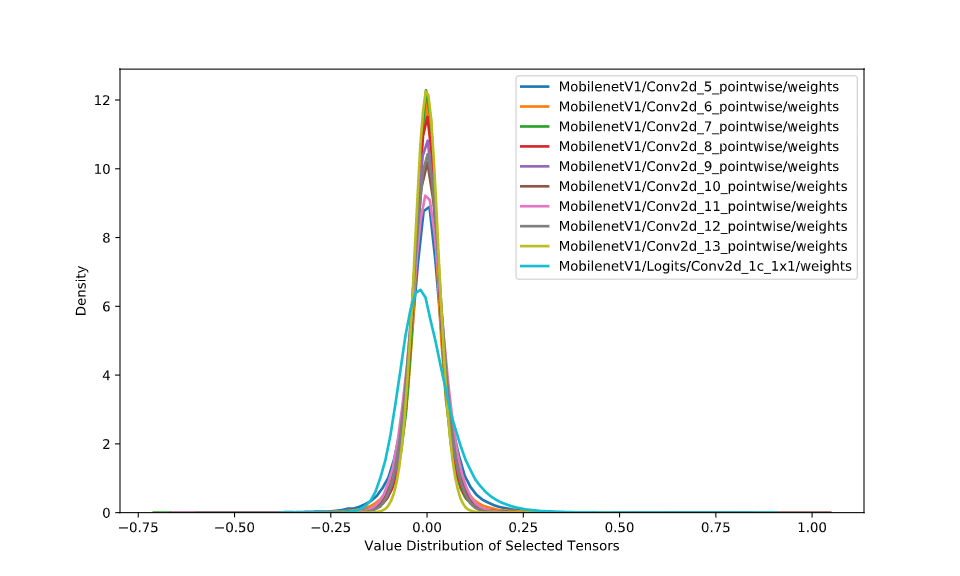
MobileNetV1 的 10 层的权重分布
一个量化方案是我们如何将实际权重转换为量化权重,该方案的一个最基本的形式是线性缩放。假设我们要讲范围 的值转换为 的整数范围,其中, 为 , 是整数表示的位宽。因此,
其中, 是权重的原始值, 是比例, 是量化值, 是映射到 0.0f 的值。这也称为仿射变换(affine mapping)。由于 为整数,因此对结果进行四舍五入。现在的问题是,我们如何选择 和 。实现这一点的简单方法是生成权重和激活的分布,然后用量化分布计算他们的 KL 散度(Kullback-Leibler divergence,缩写为 KLD 或 KL divergences),并使用与原始值差异最小的那个。一种更为优雅的方法是使用伪量化(Fake Quantization),即,在训练期间将量化感知层引入网络。这个想法是由 Jacob 等人 提出的。
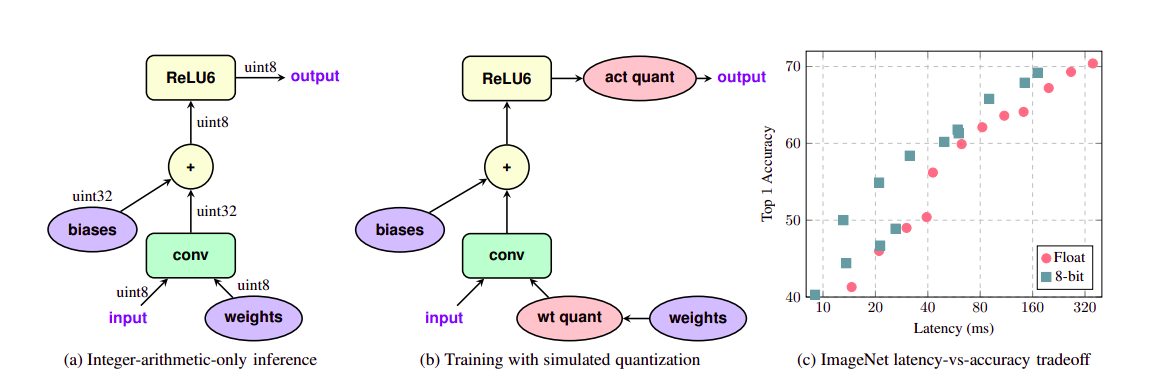
(a)普通卷积层;(b)增加伪量化单元的卷积层;(c)量化网络的时延与正确率的比较。Jacob 等人
在训练时,伪量化节点计算权重和激活的范围,并存储它们的移动平均值。完成训练后,我们用这个范围来对网络进行量化,以获得更好的性能。
Rastegari 等人的关于异或(XOR)网络的论文、Courbariaux 等人的关于三值(Ternary)网络的论文、Zhu 等人的关于二值(Binary)网络的论文中也探讨了更大的位宽。在 PyTorch 1.3 中,引入了量化支持。为量化操作引入了三种新的数据类型:torch.quint8、torch.qint8 和 torch.qint32。它还提供了各种量化技术,包含在 torch.quantization 中。
训练后动态量化:将浮点权重替换为其动态量化版本。默认情况下,只对权重交大的层(即线性和 RNN 变体)进行权重量化。
训练后静态量化:静态量化不仅可以将浮点数权重转换为整数,还可以记录激活的分布情况,并用于确定推理时的量化比例。为了支持这种校准类型的量化,我们在模型的开头和结尾分别添加了
QuantStub和DeQuantStub。它涉及下面提到的步骤。
量化感知训练:在训练时使用伪量化模块来存储比例。为了启用量化感知训练,我们使用
qconfig作为get_default_qat_qconfig('fbgemm'),使用prepare_qat来代替prepare。之后,就可以对模型进行训练或微调,在训练结束时,使用 与上述相同的torch.quantization.convert得到量化模型。
PyTorch 中的训练后量化目前仅支持 CPU 上的操作。
有关详细的代码示例,请参阅 PyTorch 文档。在 TensorFlow 方面,通过 将 optimizations 参数设置为 tf.lite.Optimize.OPTIMIZE_FOR_SIZE,可以使用 TFLite 的 tf.lite.TFLiteConverter API 进行量化。伪量化是通过 tf.contrib.quantize 包启用的。
作者介绍:
Amandeep Singh,供职于 99acres.com 的高级软件工程师。之前曾在三星诺伊达(印度)研究院 工作。广泛研究设备上的机器学习和自然语言处理的问题。
原文链接:
https://amandeepsp.github.io/ml-model-compression-part1/

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论