

本文来自对论文:Applying Deep Learning To Airbnb Search 的解读。
内容大纲:
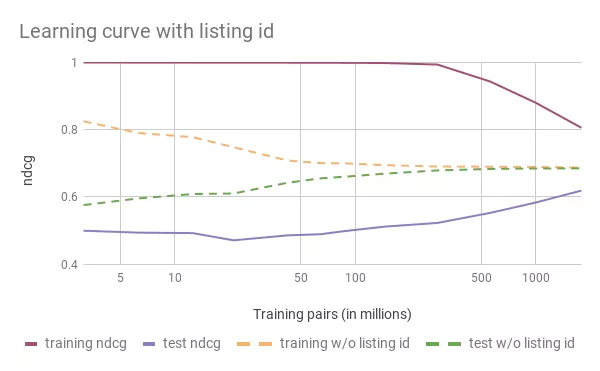
效果概览
模型演进
失败尝试
特征工程
系统介绍
一、效果概览
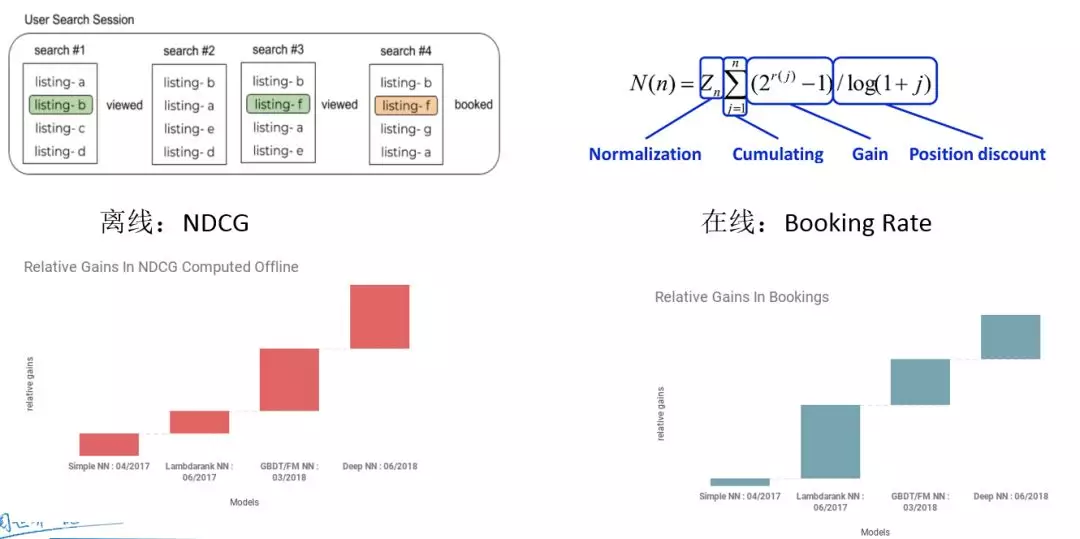
分为离线和在线俩部分。其中,一个重要指标是 NDCG 标准化文档累计增益,NDCG = DCG/IDCG 。
二、模型演进
演进 1:SimpleNN
超简单网络结构,其特点:
一层隐含层,32 个 ReLUunits
所有用到的特征 GBDT 一样
训练目标与 GBDT 一致,最小化均方误差用户预定了就是 1,没有预定就是 0
结论:
SimpleNN 相对 GBDT 排序效果提升较小
验证 NN 的线上可行性
演进 2:LambdaRankNN
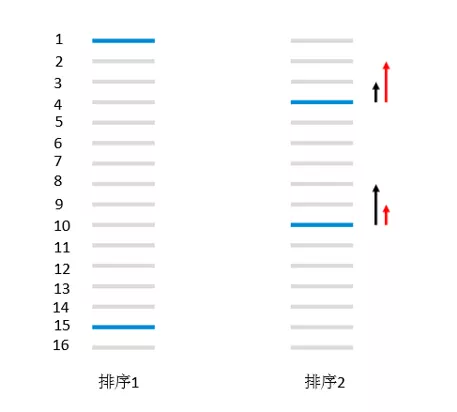
网络结构保持不变:
改用 pairwise 损失,并在训练的时候最小化 crossentropy loss
使用 listing 对调带来的 delta NDCG 作为 pairwiseloss 的权重,得到最终的损失函数
结论:
线下小幅度提升 NDCG
线上大幅度提升
演进 3:GBDT/FM NN
在研究 NN 模型的同时,Airbnb 还探索了 GBDT 和 FM 模型。三者线下表现差不多,但是得到的排序结果却很不相同。所以,Airbnb 尝试了将三种模型进行模型结构的融合,也算是常用的做法:
将 GBDT 的每一颗树的预测结果在叶节点中的 index ,作为 categorical feature ,输入到 NN 中;
将 FM 的预测点击概率结果,直接作为特征放到 NN 中。
单隐层全连接使用 ReLU 激活函数
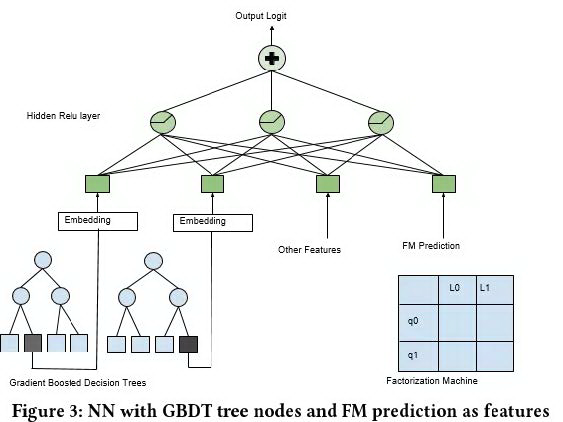
结论:
GBDT/FM/SimpleNN 效果基本一致
单纯排序结果三者差异性较大
融合后线上收益较高
演进 4:Deep NN
引入复杂深度模型探索特征空间:
195 个 features 输入 ( 还是把类别型特征 embedding 之后的 )
两层 hiddenlayer 。第一层 127Units 输出,第二层 83Units 输出,使用 ReLU 激活函数。
数据量增加了 10 倍后效果显现
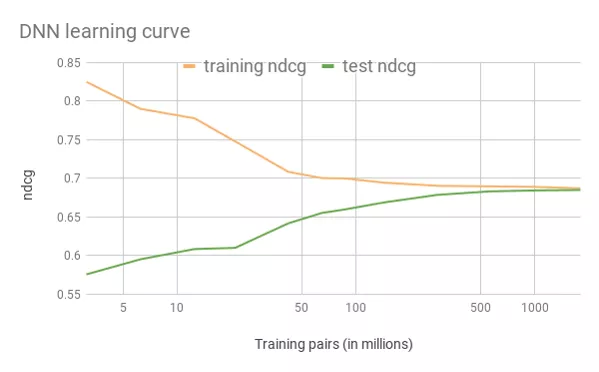
结论:
离线/在线均获得较大收益
离线训练量达到 10 亿量级时,训练与测试之间的效果 gap 消失
强调在 DL 中数据重要性
三、失败尝试
1. 失败 Embedding List
类比 item2vec 对 list ( 这里也是指某 item ) 进行 embedding :
直接使用用户 booking 顺序,产出 list2vec
考虑现实情况,单条 booking 顺序中没有大量的重复数据 ( 低频触发 )
考虑现实冲突,某个 house 一年最多 booking 365 次
结论:
应用于线上带来大量过拟合,更大规模的训练数据也无法消灭低频
Airbnb 的现实场景导致 item 冲突约束性,大量房子预订量极低
2. 尝试挽救
发现:
Item 预定量低频,但浏览量不低
长时间浏览行为,与 booking 预定行为强相关
尝试:
多任务训练,以预定/浏览时长为多任务目标
隐层共享,利用 view 浏览时长数据修正过拟合,促进 embedding 效果
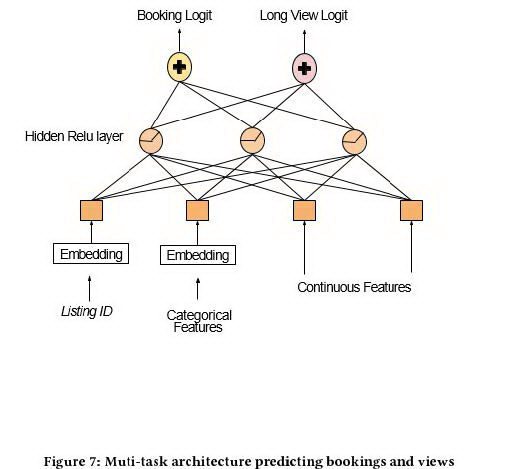
结论:
线上实验 longview 大幅提升,预订量无显著提升
人工分析,优先推荐:
① 高端但价格高的 item
② 特别而滑稽的 item
③ 文字描述很长的 item
四、特征工程
1. 深度学习也要做特征工程!
认知:
1 ) GBDT 考虑的是有序分裂点,对归一化不敏感
2 ) DL 对特征的绝对数值 较为敏感
较大的数值变化,会在 BP 学习中带来较大的梯度变化
较大数值在 ReLU 作为激活层时,甚至会导致其永久关闭
3 ) 满足一定条件的输入数据,会让深度学习模型表现得更好
特征值映射到 [-1,+1] 区间,中值为 0
输入值尽量稠密平滑,去除输入毛刺点
归一化方法:
1 ) 将满足正太分布的特征归一化:
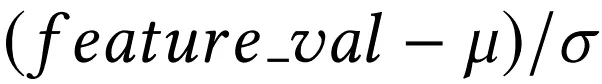
2 ) 将满足幂度分布的特征归一化:
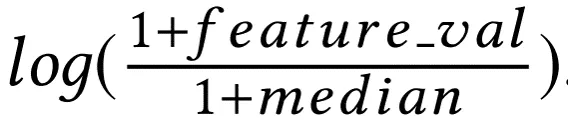
2. 特征平滑
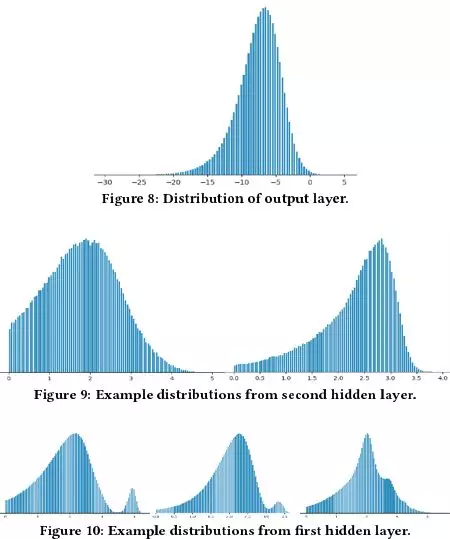
发现:
DL 中的每一层,输出都是越来越平滑
上图中,从下到上,分别是模型每层的输出
如果在输入层就平滑,将会提升泛化能力
底层的平滑输出,将保证高层对未知特征组合的稳定性
便于排查异常,保证特征完整性
下图是预定天数特征,左边为原始预定天数分布,右图为考虑预定天数中值后的分布
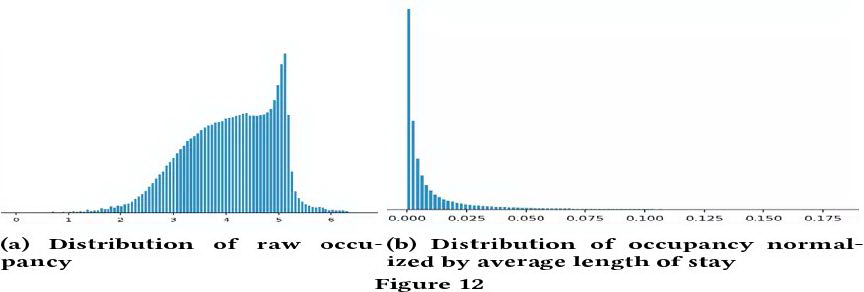
3. 特殊特征 ( 经纬度 ) 平滑
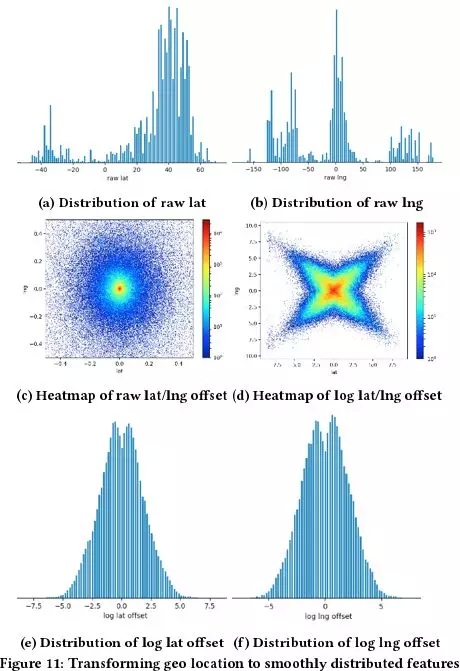
经纬度平滑过程:
直接使用经纬度特征,分布极其不均衡 ( 见上图第一层图片 ) 。
第二层图片左图,是对目标地点的距离特征分布,可以看出大部分的点走在原点位置,其他的很多点以原点为中心均匀的分散开来。
第二层图片右图,是对经纬度分别取 log 。
将经纬度的 offset 分别取 log ( 上图最底层图片 ) ,得到基于距离的全局特征,而不是基于特定地理位置的特征。
4. 离散特征 embedding
发现:
虽然 item-embedding 在此场景不适用,但一些零散特征的 embedding 仍然有效 ( 主要针对不可比较、选项较多的离散值特征 )
利用搜索城市后的街道连续点击行为,构建街道 embedding
对全局 query 搜索内容进行初步聚合,再建立 embedding,产出作为用户搜索特征输入
5. 特征重要性评估
失败做法:
分解深度学习的 score,给出每一部分特征重要度
分析:多层非线性断绝分解的希望
依次移除特征,查看模型性能变化。
分析:特征之间不完全独立,在特征工程后尤其如此
随机修改某些特征,查看性能变化
分析:特征依旧不独立,没法排除 noise
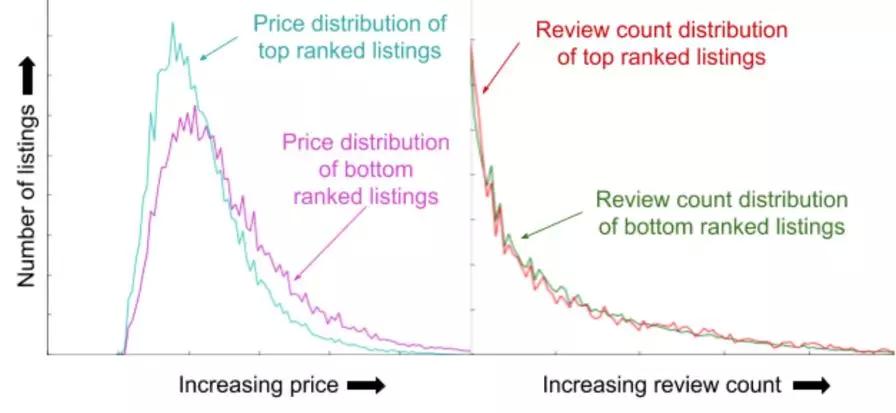
成功做法:( TopBot 分析法 )
产出测试集预测的 list 排序
观察某个特征在头部 list 与尾部 list 的区别,有区分度为重要特征
下图中,左侧为 price ,头部 price 比尾部低;右侧为评论数,头部与尾部没区别
五、系统工程
Airbnb 系统介绍:
1. 工程架构
JavaServer 处理 query
Spark 记录 logs
Tensorflow 进行模型训练
JavaNNLibrary 线上低延迟预测
2. 数据集
GBDT 时代采用 CSV ,读入耗时长
Tf 时代改用 Protobufs ,效率提升 17 倍,GPU 利用率达到 90%
3. 统计类特征
大量样本共同拥有的统计类特征,成为数据读取瓶颈
整合统计类特征,将其汇总后,看作不可训练的 embedding 矩阵,作为 tf 的统计特征节点输入层参数
4. 超参数
Dropout 层没有带来增益
初始化采用 {-1,1} 的范围均匀随机,比全 0 初始化要好
Batchsize 选用 200,最优化使用 lazyAdom
参考资料:
Applying Deep Learning To Airbnb Search,论文链接:
https://arxiv.org/abs/1810.09591v2
论文 pdf 版本可直接关注本文公众号,回复“Airbnb”下载。
作者介绍:
马宇峰,阅文信息 资深研发工程师 内容挖掘平台技术负责人。前百度高级研发工程师,研究方向主要包括知识图谱、用户理解、推荐系统。曾获 2014 百度知识图谱竞赛第 1 名。
原文链接:

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论