

数据库架构的演变
在业务数据量比较少的时代,我们使用单机数据库就能满足业务使用,随着业务请求量越来越多,数据库中的数据量快速增加,这时单机数据库已经不能满足业务的性能要求,数据库主从复制架构随之应运而生。
主从复制是将数据库写操作和读操作进行分离,使用多个只读实例(slaver replication)负责处理读请求,主实例(master)负责处理写请求,只读实例通过复制主实例的数据来保持与主实例的数据一致性。由于只读实例可以水平扩展,所以更多的读请求不成问题,随着云计算、大数据时代的到来,事情并没有完美的得以解决,当写请求越来越多,主实例的写请求变成主要的性能瓶颈。
如何解决上述问题?如果仅仅通过增加一个主实例来分担写请求,写操作如何在两个主实例之间同步来保证数据一致性,如何避免双写,问题会变的更加复杂。这时就需要用到分库分表(sharding),对写操作进行切分来解决,如图 1 所示:
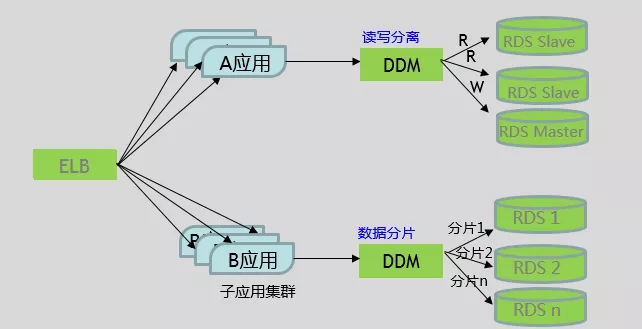
图 1:典型的读写分离和分库分表
华为云中间件产品 DDM(Distributed Database Middleware)作为 RDS 的前置分布式数据库访问服务,彻底解决了数据库的扩展性问题,对应用透明地实现海量数据的高并发访问,实现了读写分离和分库分表。
数据分片的实现方案
数据分片的实现方案可分为应用层分片和中间件分片,这两种实现方案的特点如图 2 所示:
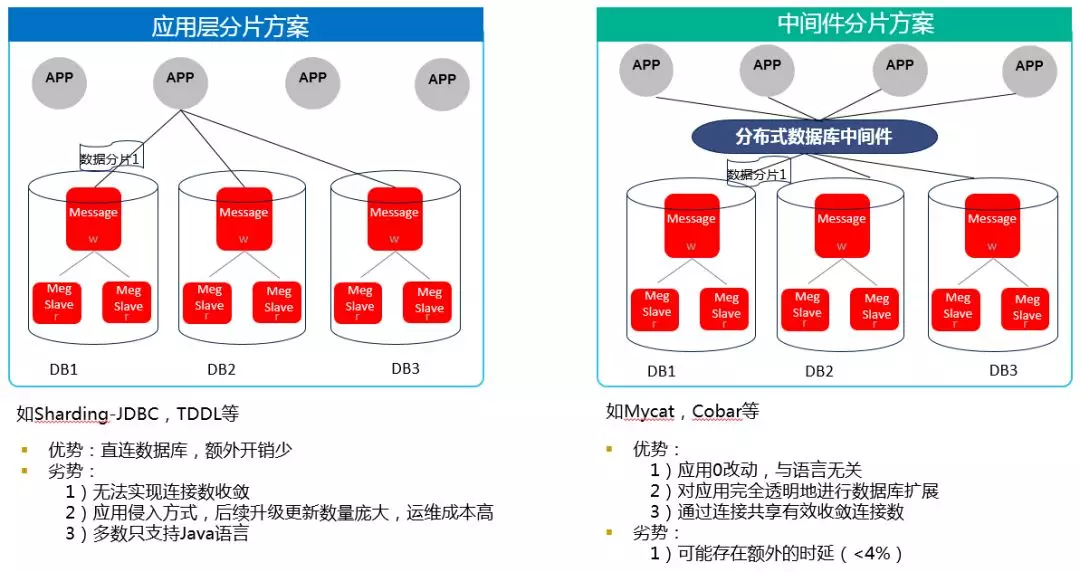
图 2:应用层分片和中间件分片
DDM 作为一款优秀的分布式数据库中间件产品,实现了读写分离和数据分片功能,使用 DDM 来分库分表,应用 0 改动,对应用完全透明。
分库分表的切分方式
数据的切分(Sharding)根据其切分规则的类型,可以分为两种切分模式。一种是按照不同的表(或者 Schema)来切分到不同的数据库(主机)之上,这种切分方式可以称之为数据的垂直(纵向)切分;另外一种则是根据表中的数据的逻辑关系,将同一个表中的数据按照某种条件拆分到多台数据库(主机)上面,这种切分称之为数据的水平(横向)切分。
垂直切分最大特点就是规则简单,实施也更为方便,尤其适合各业务之间的耦合度非常低,相互影响很小,业务逻辑非常清晰的系统。在这种系统中,可以很容易做到将不同业务模块所使用的表分拆到不同的数据库中。根据不同的表来进行拆分,对应用程序的影响也更小,拆分规则也会比较简单清晰。
水平切分于垂直切分相比,相对来说稍微复杂一些。因为要将同一个表中的不同数据拆分到不同的数据库中,对于应用程序来说,拆分规则本身比根据表名来拆分更为复杂,后期的数据维护也会更为复杂一些。
具体而言,如果单个库太大,这时我们要看是因为表多而导致数据多,还是因为单张表里面的数据多。如果是因为表多而数据多,使用垂直切分,根据业务切分成不同的库。如果是因为单张表的数据量太大,这时要用水平切分,即把表的数据按某种规则切分成多张表,甚至多个库上的多张表。分库分表的顺序应该是先垂直分,后水平分。因为垂直分更简单,更符合我们处理现实世界问题的方式。
水平切分
相对于垂直拆分,水平拆分不是将表做分类,而是按照某个字段的某种规则来分散到多个库之中,每个表中包含一部分数据。简单来说,我们可以将数据的水平切分理解为是按照数据行的切分,就是将表中的某些行切分到一个数据库,而另外的某些行又切分到其他的数据库中,如图 3:
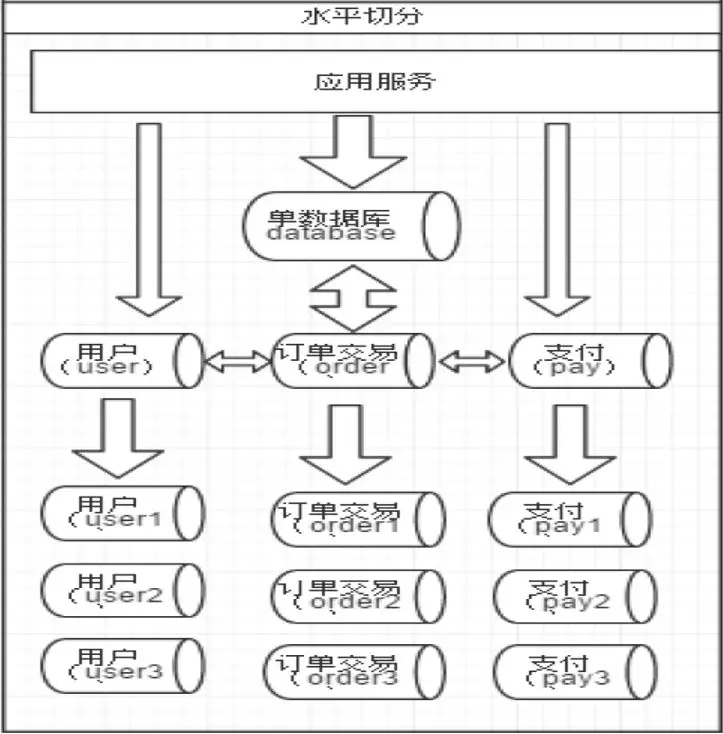
图 3:水平切分
水平切分的优点
1、拆分规则抽象好,join 操作基本可以数据库做。
2、不存在单库大数据,高并发的性能瓶颈。
3、应用端改造较少。
4、 提高了系统的稳定性跟负载能力。
水平切分的缺点
1、拆分规则难以抽象。
2、分片事务一致性难以解决。
3、数据多次扩展难度跟维护量极大。
4、跨库 join 性能较差。
水平切分的典型分片规则
1、HASH 取模
例如:取用户 id,然后 hash 取模,分配到不同的数据库上。
2、RANGE
例如:从 0 到 10000 一个表,10001 到 20000 一个表。
3、时间
按照时间切分,例如:将 6 个月前,甚至一年前的数据切出去放到另外的一张表,因为随着时间流逝,这些表的数据被查询的概率变小,所以没必要和”热数据“放在一起,这个也是“冷热数据分离”。
切分原则一般是根据业务找到适合的切分规则分散到不同的库,如图 4,根据用户 ID 取模作为切分规则。
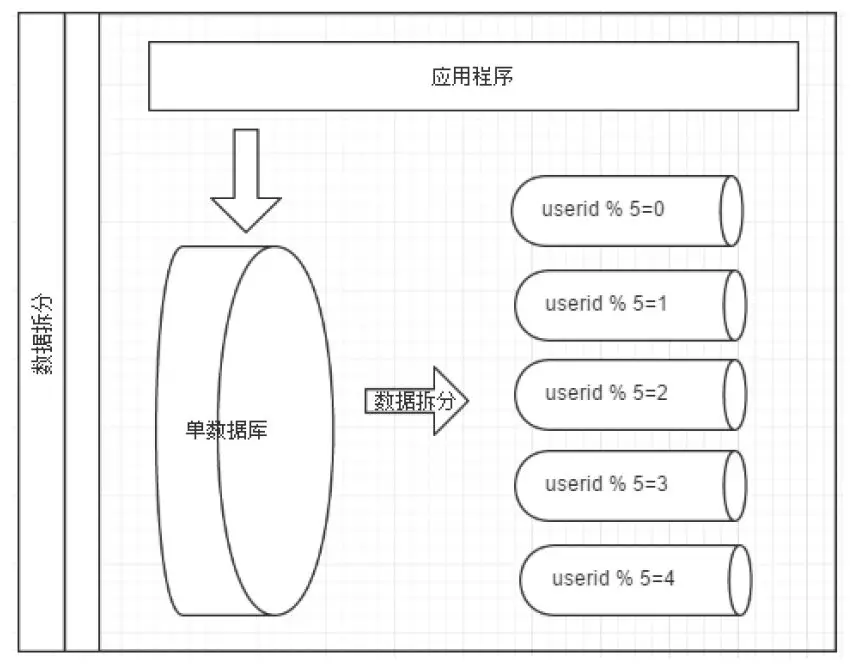
图 4:根据 userid 取模进行切分
垂直切分
一个数据库由很多表的构成,每个表对应着不同的业务,垂直切分是指按照业务将表进行分类,分布到不同的数据库上面,这样也就将数据或者说压力分担到不同的库上面,如图 5:
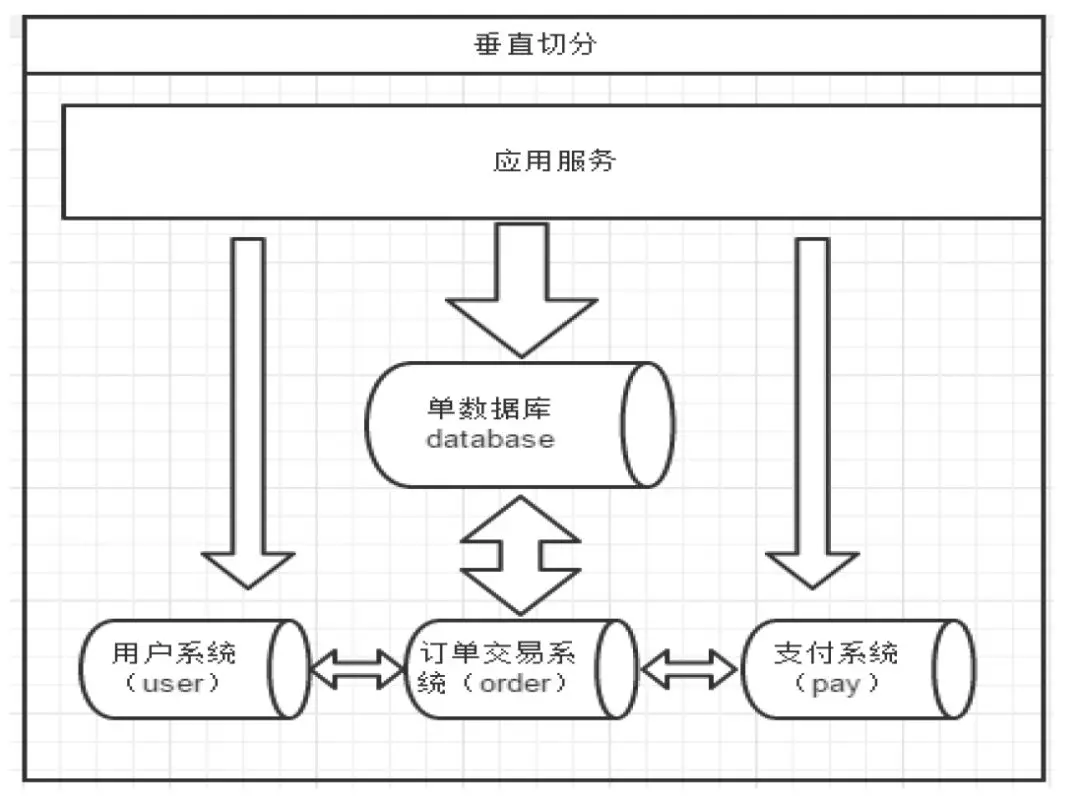
图 5:垂直切分
垂直切分的优点
1、数据维护简单。
2、拆分后业务清晰,拆分规则明确。
3、系统之间整合或扩展容易。
垂直切分的缺点
1、事务处理复杂。
2、部分业务表无法 join,只能通过接口方式解决,提高了系统复杂度。
3、受每种业务不同的限制存在单库性能瓶颈,不易数据扩展跟性能提高。
由于垂直切分是按照业务的分类将表分散到不同的库,所以有些业务表会过于庞大,存在单库读写与存储瓶颈,所以就需要水平拆分来做解决。
切分原则
由于数据切分后数据 Join 的难度,在此也分享一下数据切分的经验:
第一原则:能不切分尽量不要切分。
第二原则:如果要切分一定要选择合适的切分规则,提前规划好。
第三原则:数据切分尽量通过数据冗余或表分组(Table Group)来降低跨库 Join 的可能。
第四原则:由于数据库中间件对数据 Join 实现的优劣难以把握,而且实现高性能难度极大,业务读取尽量少使用多表 Join。
分库分表后的问题和应对策略
分库分表主要用于应对当前互联网常见的两个场景:海量数据和高并发。然而,分库分表是一把双刃剑,虽然很好的应对海量数据和高并发对数据库的冲击和压力,但也提高了系统的复杂度和维护成本,带来一些问题。
1、事务支持
在分库分表后,就成为分布式事务了,如何保证数据的一致性成为一个必须面对的问题。一般情况下,使存储数据尽可能达到用户一致,保证系统经过一段较短的时间的自我恢复和修正,数据最终达到一致。
2、分页与排序问题
一般情况下,列表分页时需要按照指定字段进行排序。在单库单表的情况下,分页和排序也是非常容易的。但是,随着分库与分表的演变,也会遇到跨库排序和跨表排序问题。为了最终结果的准确性,需要在不同的分表中将数据进行排序并返回,并将不同分表返回的结果集进行汇总和再次排序,最后再返回给用户。
3、表关联问题
在单库单表的情况下,联合查询是非常容易的。但是,随着分库与分表的演变,联合查询就遇到跨库关联的问题。粗略的解决方法:ER 分片:子表的记录与所关联的父表记录存放在同一个数据分片上。全局表:基础数据,所有库都拷贝一份。字段冗余:这样有些字段就不用 join 去查询了。ShareJoin:是一个简单的跨分片 join,目前支持 2 个表的 join,原理就是解析 SQL 语句,拆分成单表的 SQL 语句执行,然后把各个节点的数据汇集。
4、分布式全局唯一 ID
在单库单表的情况下,直接使用数据库自增特性来生成主键 ID,这样确实比较简单。在分库分表的环境中,数据分布在不同的分表上,不能再借助数据库自增长特性,需要使用全局唯一 ID。
分库分表案例
某税务核心征管系统,全国 34 个省国/地税,电子税务局 15 省格局。
技术路径:核心征管 + 纳税服务 业务应用分布式上云改造。
业务挑战
1、数据查询时间 3-5 秒,响应速度慢严重影响体验
当前业务逻辑大量放在数据库层,一个办税业务的事务边界过大(40 条 SQL 语句),涉及以“申报”、“发票”大表为主的多张表关联事务操作,导致业务查询响应速度慢。
2、亿级数据快速的增长,挑战业务性能瓶颈
省级税务局,办税高峰期承载百万级用户并发量,3000-5000TPS。现网分析得到数据:核心征管库近 1000 张表,其中“申报”、“发票”业务表数据量大、增长快,是主要瓶颈表;发票综合信息:每省 10 亿级条记录,每年千万到亿条记录级别增量;申报信息表:亿级记录数据量。
解决方案
1、垂直分库、微服务分解数据库压力,降低单业务 sql 数
基于微服务将大事务拆解为异步小事务,业务逻辑从数据库层面剥离。拆分主库数据,将大表垂直拆分到多个数据库中,一个业务 40 条 SQL 缩减到 20 条 SQL,达到分解数据库压力的目的。
2、数据分片支撑海量数据增长,线性提升业务处理速度
单表亿级记录以纳税人作为拆分键,拆分到 RDS-MySQL 的 128 个分片上。实现支撑海量数据的存储。拆分后数据库设计简洁、简单,数据库的表之间不设外键,不写触发器,不写存储过程,实现数据库记录的水平扩展。
3、读写分离提升查询性能
DDM 自动实现读写分离,透明地完成写操作和读操作的分发,应用程序无需做特殊的改动和处理逻辑。写操作分发到 RDS 主实例,读操作自动分发到 RDS 的多个读实例上,这样写操作不会影响读操作的并发,读并发业务增长时只需要按需增加只读实例即可。
企业受益
1、使用了 DDM 之后,轻松突破原来的性能瓶颈,一次业务操作,原来需要 3 到 5 秒,现在只需要 1 秒。
2、读写操作通过 DDM 的自动读写分离,在不改动业务情况下,轻松提升了整体的读写并发能力。
本文转载自公众号中间件小哥(ID:huawei_kevin)。
原文链接:
https://mp.weixin.qq.com/s/zG90mtqhDkHOuM-Z41Utpg

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 1 条评论