

在三大 Hadoop 发行商接连运转不顺之际,公众对 Hadoop 的担心迅速蔓延至 Kubernetes。众所周知,Kubernetes 的学习门槛较高、学习曲线较长,这一点已经被很多开发人员吐槽过,这被猜测是否会让其与 Hadoop 面临同样的处境,在辉煌过后开始走向下坡路。
如今,Kubernetes 是开源领域备受关注的项目,就好像曾经的 Hadoop 是大数据领域的事实标准一样。随着三大围绕 Hadoop 进行商业化的厂商Cloudera、Hortonworks 和 MapR 在公司运转层面先后出现问题(Cloudera 股价大跌、MapR 融资困难甚至被报道总部可能关闭),开源 Hadoop 生态的复杂性问题再次被提起,而这场讨论迅速将 Kubernetes 卷入其中。
近日,外媒 InfoWorld 发表了一篇题为“Will complexity kill Kubernetes?(复杂性会杀死 Kubernetes 吗?)”的文章,指出了 Kubernetes 本身过于复杂的事实,并分析了这种复杂性与 Hadoop 是否雷同,以及 Kubernetes 最终会不会重蹈 Hadoop 的覆辙。针对上述问题,InfoQ 第一时间对阿里巴巴高级技术专家张磊进行了独家采访,共同探讨 Kubernetes 背后的复杂性问题。

Kubernetes 的复杂性
Kubernetes 确实是一个比较复杂的开源项目,尤其是对大多数开发人员来说。——张磊
关于 Kubernetes 的复杂性问题,InfoQ 此前曾进行过简单报道。作为 Jira 和代码库 Bitbucket 背后的公司,Atlassian 的 Kubernetes 团队首席工程师 Nick Young 在采访中表示,虽然当初选择 Kubernetes 的战略是正确的(至少到现在也没有发现其他可能的选择),解决了现阶段遇到的许多问题,但部署过程异常艰辛。
此外,将 KubeSphere 容器平台开源的青云 QingCloud 公司应用及容器平台研发总监周小四也曾在接受采访中提到 Kubernetes 存在很多问题,比如学习门槛较高、学习曲线较长:
我曾经花了三个月时间学习 Kubernetes,但还是感觉没有完全掌握,之后又花了整整一年时间才把 Kubernetes 真正搞明白,这个时长对企业而言是很难接受和付出的。
所以,复杂性会成为阻碍 Kubernetes 发展的重要因素吗?
作为 Kubernetes 的创建者之一,Heptio(VMware)的 Joe Beda 在 Twitter 上表示:
First off: Kubernetes is a complex system. It does a lot and brings new abstractions. Those abstractions aren’t always justified for all problems. I’m sure that there are plenty of people using Kubernetes that could get by with something simpler.
参考译文:Kubernetes 是一个复杂的系统,它做并带来了很多新的抽象,但这并不适合所有问题。我确定,很多人通过更简单的工具实现 Kubernetes 的功能。
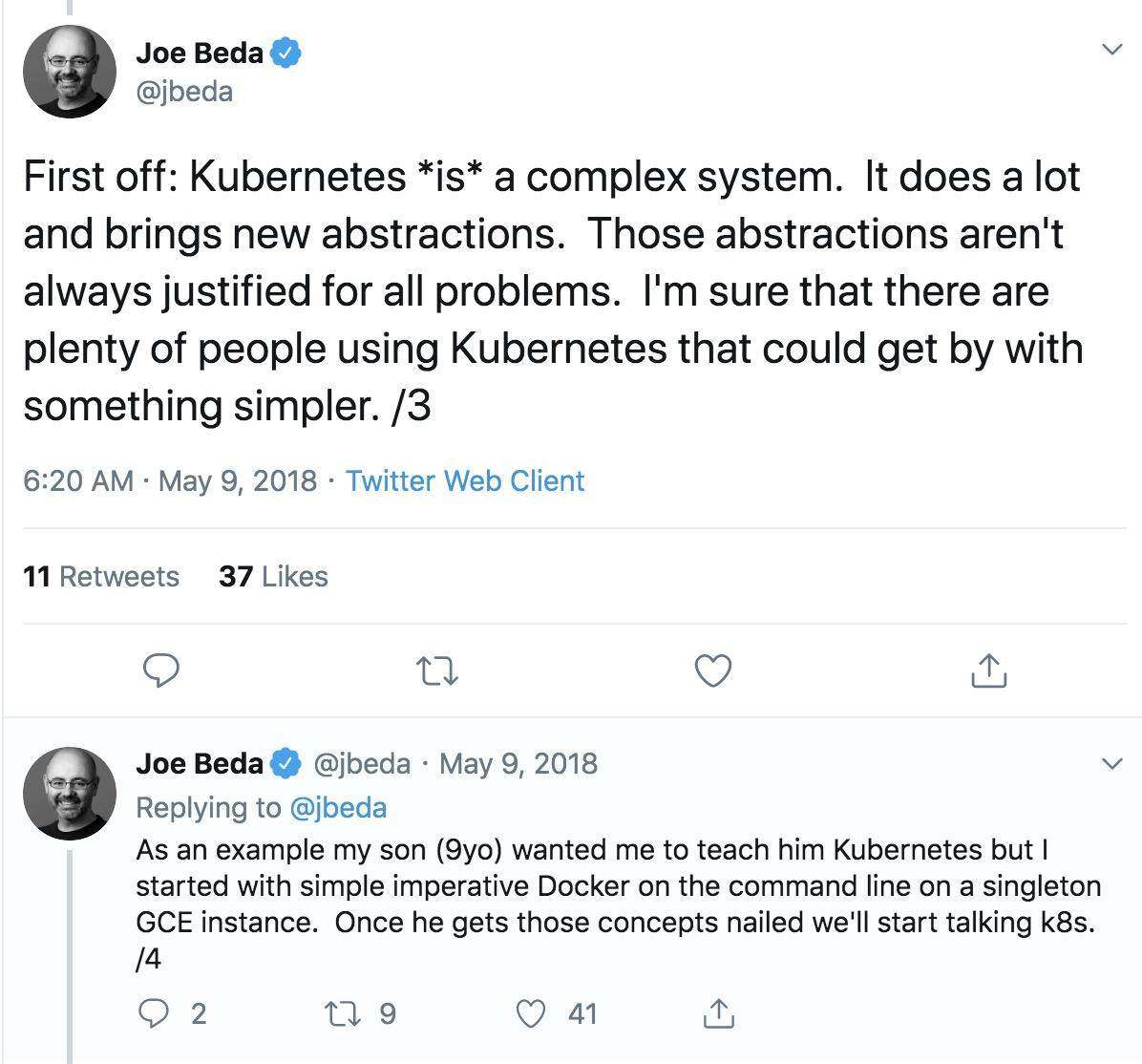
在随后的讨论中,Beda 强调,相比于学习的复杂性,工程师往往更擅长削减构建复杂性。当工程师决定使用 Jenkins、Bash、Puppet、Terraform 等创建系统时,最终会得到一个独特的复杂系统,工程师本人会感到很舒适,这可能解决了某些问题。但对新人而言,试图了解这些系统太过复杂。但是,这种复杂性与某些特定系统中的复杂性还不同,Kubernetes 是存在行业标准的,基本只要学习一次就可以在各处应用。
那么,Kubernetes 的复杂性到底来源于哪里?
采访中,张磊表示,Kubernetes 本质上是一个分布式系统而不是一个简单的 SDK 或者编程框架,这本身已经将其复杂度提升到了系统级分布式开源项目的位置(换言之,不可以简单地将 Kubernetes 的复杂性与编程框架等同日而语)。此外,Kubernetes 第一次将声明式 API 的思想在开源基础设施领域普及开来,并以此为基础提出了系列诸如容器设计模式和控制器模型等使用范式,这些具有一定先进性和前瞻性的设计也使得 Kubernetes 项目被大众接受是存在一定学习周期的。
Kubernetes 项目的定位与用户群体
首先,张磊认为,Kubernetes 项目的核心定位是要做一个 “Platform for Platform”的项目,即“用来帮助使用者构建分布式系统的分布式系统”。这也就意味着,Kubernetes 项目的首要目标用户其实是分布式应用的开发人员。当然,这里的分布式应用可以是稍具规模的网站,也可以是 TiDB 这样复杂的数据库系统。但这也就使得对不少技术从业者来说,Kubernetes 项目的很多设计与思想,都会比较难以一下子被理解和接受。这其实也是很自然的情况,举例来说,如果 Kubernetes 声明式 API 背后的控制器模型不能为这些用户带来直接好处,那么这个声明式 API 在这部分用户眼中就是累赘。然而,对于另一部分真正在使用控制器模型的用户来说,声明式 API 却是这个项目最具魅力的特性之一。因此,对于这样一个全世界排名前列的开源项目是否被认为“复杂”,更大程度取决于使用者对该项目的具体诉求。
当然,Kubernetes 项目时不时就会被与“复杂”联系在一起,这也就意味着业界一定广泛存在 Kubernetes 使用者的诉求与项目定位不一致的问题。
除了分布式应用的开发者,在 Kubernetes 项目当前的使用者群体中,还有很大一部分来自于 Docker 生态以及 PaaS 社区,这些用户往往是普通应用而非复杂应用的开发者。相比于纠结“高可用”、“高性能”和“大规模”,这些用户关注的价值点是他们编写的业务逻辑本身,而非程序和代码。对于这些用户来说,他们希望 Kubernetes 提供的,其实是朴素的应用托管和底层基础设施屏蔽能力。这些诉求对于 Kubernetes 项目来说当然不是问题,但是却很难透出 Kubernetes 项目核心设计思想带来的种种好处。
此外,Kubernetes 项目还有一部分用户是应用运维人员。对于这些用户来说,他们希望 Kubernetes 提供的主要是基础设施与资源管理能力,以帮助他们来运维业务方即应用开发者编写的应用。在这个场景下,Kubernetes 项目本身自然也没有问题。但是传统运维模式与 Kubernetes 提倡的声明式 API 和控制器模型之间,其实有着不小的思想与技术鸿沟需要跨越。
综上,这两部分用户群体与 Kubernetes 项目自身定位的”错位关系“,其实是 Kubernetes 项目“复杂性”控诉的主要来源。
Kubernetes 的复杂性是否有望降低?
2018 年底,Heptio 曾委托第三方公司对各行各业近 400 名 IT 决策者进行调查,试图了解哪些团队或企业正在转向 Kubernetes,过程中遇到了哪些障碍以及他们如何从技术中受益。
调查结果显示,团队在评估和运行 Kubernetes 的时候都遇到了不同程度的问题,包括早期的设计和部署决定(47%),内部团队对通用技术的统一认识(47%),内部缺少专家资源(45%),在关键任务中保证可靠性(43%),复杂策略的管理(42%),仅有 4% 的受访者表示,部署 Kubernetes 时不需要帮助,这意味着要想在生产环境中成功运行 Kubernetes 是不容易的。
如果,Kubernetes 社区可以采取相应动作降低部分复杂性,想必会让整个部署过程更为顺利。
对此,张磊表示,Kubernetes 社区的未来一定是继续向民主化和可扩展方向上不断演进,并且不断优化用户的使用体验。事实上,早在 1.14 版本发布时,Kubernetes 的核心 API 已经基本处于“锁定”状态,核心组件的很多特性也都被建议通过 CRD 实现,而像容器运行时接口(CRI),容器存储接口(CSI),容器网络接口(CNI),Admission Hook 等已经被广泛使用的扩展机制就更无需赘述了。
不过,越来越多的插件和可扩展机制,以及这种设计背后带来的技术复杂度,实际上往往会让上述提到的两部分错位的用户感到更加困惑,并进一步增加了学习曲线的陡峭度。
因此,这里的矛盾点在于 Kubernetes 项目发展的走向,并不以让所有用户都感到易用和容易上手为主要目标。更为本质的问题是,Kubernetes 项目的设计中,并没有区分用户角色,这使得“应用开发者”、“应用运维人员”、“基础设施运维人员”等多种用户群体,都必须面对同一套声明式 API ,学习同一套脱胎于 Google Borg/Omega 体系的系统架构思路。在这种“众口难调”的背景下,“复杂度”的控制其实成为一个“鱼与熊掌”般的哲学问题。
解决复杂性的关键:使用者角色解耦
当然,在 Kubernetes 良好的可扩展性机制下,要解决上述”复杂度“问题并非没有办法,关键在于实现开发与运维等使用者角色的解耦。
通过解耦,Kubernetes 项目以及对应的云服务商就可以为不同的角色暴露不同维度、更符合对应用户诉求的声明式 API。比如,应用开发者只需要在 YAML 文件中声明”应用 A 要使用 5G 可读写空间“,应用运维人员则只需要在对应的 YAML 文件里声明”Pod A 要挂载 5G 的可读写数据卷“。这种”让用户只关心自己所关心的事情“所带来的专注力,是降低 Kubernetes 使用者学习门槛和上手难度的关键所在。
事实上,Kubernetes 社区一直没有停止在这个领域的持续探索,尤其是在”如何定义一个区分不同用户角色的、统一的应用描述“这个问题上,社区已经取得一些关键性的突破。张磊透露,预计到 2019 年底,用户就有机会了解这些改变的具体情况。
这与 Hadoop 的复杂性并不相同
虽然 Kubernetes 的复杂性被大多数人员认可,但这与 Hadoop 并不相同。Apache Hadoop 在大致相当于“MapReduce”时就比较复杂。随着时间的推移,Hadoop 的功能越来越强大,生态中可供选择的组件数量激增,但彼此之间很难协同运行。
对于此,VMware 的 Jared Rosoff 精辟地分析了这个问题:“Hadoop 的复杂性来源于典型的 Hadoop 环境基本由几十个独立而复杂的系统组成,这些系统有着不同的生命周期和管理模型。Flume、Chukwa、Hive、Pig 和 ZooKeeper 等,这些名字听起来不错,但让它们协同运行起来非常困难。Rosoff 补充道,Hadoop 并没有考虑人们会如何扩展它,结果出现的生态系统包括不相兼容的扩展组件。与之相反,Kubernetes 做得很好的一点是精心设计了扩展 Kubernetes 的方式。容器运行时接口(CRI)、容器存储接口(CSI)和容器网络接口(CNI),这些确保随着更多供应商加入进来,可以合理有序的方式运行。换句话说,不像 Hadoop 及其不兼容的扩展组件,Kubernetes 在拥有众多 Operator 后仍然可以良好运转。
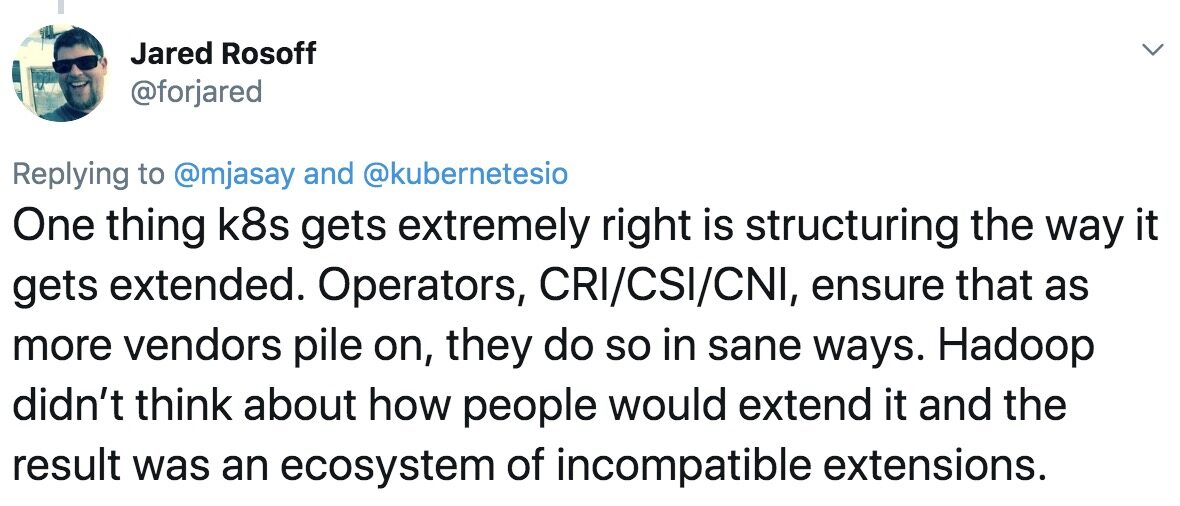
随着整体的不断发展,Hadoop 变得越来越复杂,但 Kubernetes 的组件和工具可以彼此良好协作,最终弥补 Kubernetes 可能存在的不足。虽然 Kubernetes 本身可能永远不会“简单”,但它的复杂性与 Hadoop 的复杂程度并不相同。
结束语
从诞生之日起,复杂度这个问题就一直伴随着 Kubernetes 项目。不过,可以看到的是,Kubernetes 本身也并没有因为这个问题受到太大影响,Kubernetes 项目的核心理念以及“Platform for Platform“的定位催生出整个云原生的生态,这才是其社区迅猛增长的主要动力源泉。
此外,CNCF 执行官 Chris Aniszczyk强调:虽然分布式系统本质上很复杂,但 Kubernetes 的优势在于全球每个主流云厂商都提供符合认证的版本(无分支),这对大多数用户来说可以缓解大规模管理的复杂性。
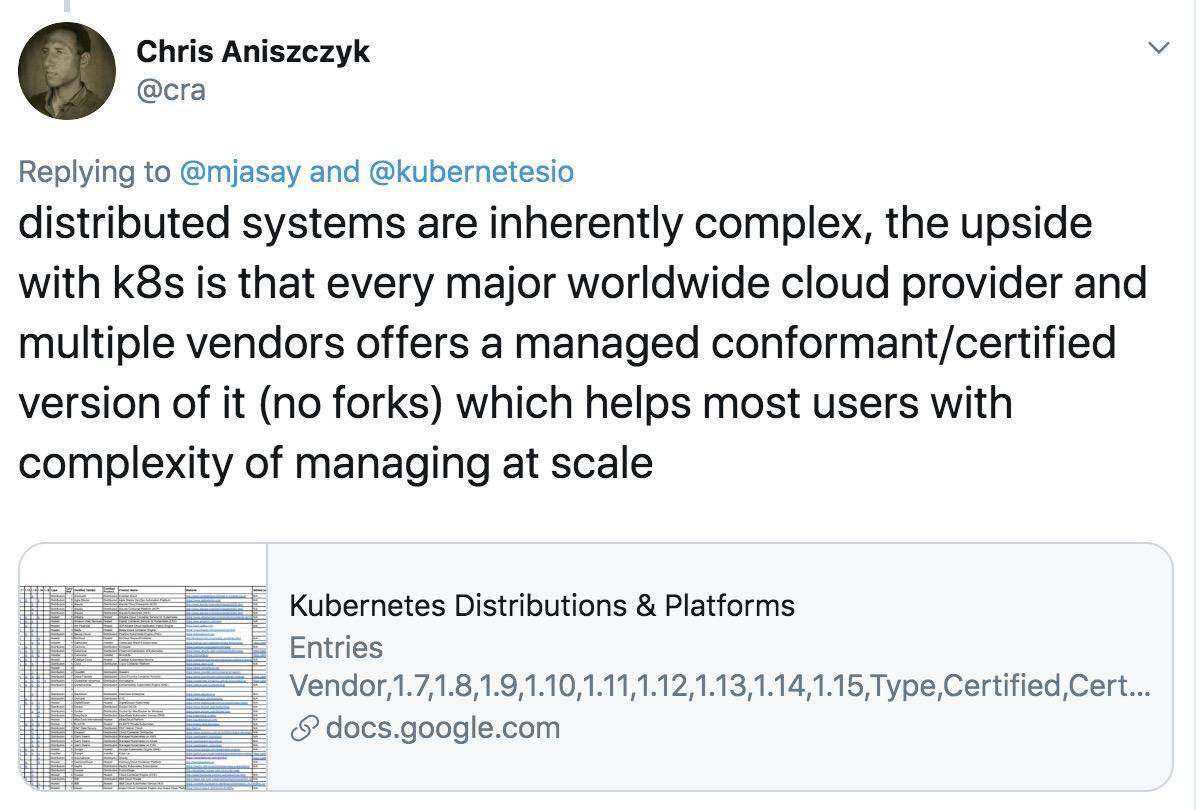
出于这些原因,未来应该可以看到 Kubernetes 继续作为容器编排的行业标准而蓬勃发展。

InfoQ 主编

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...










评论 4 条评论