

导读:CTR 预估是计算广告的底层通用技术,在 CPC/OCPC 营销模式下,预估准确性对广告主流量采买成本和平台变现效率有着非常重要的作用。我们在业界常用解法基础上,纳入时间维度和空间维度信息,基于模型学习用户历史行为和广告上下文 ( 目前是上文 ) 来辅助学习当前广告点击率,在业务上取得了显著的收益 ( 论文已被 KDD-2019 和 KDD-2019 workshop 收录 )。
本次分享的内容包括:
背景介绍
DSTN 模型
MA-DNN 模型
01 背景介绍
1. 业务场景
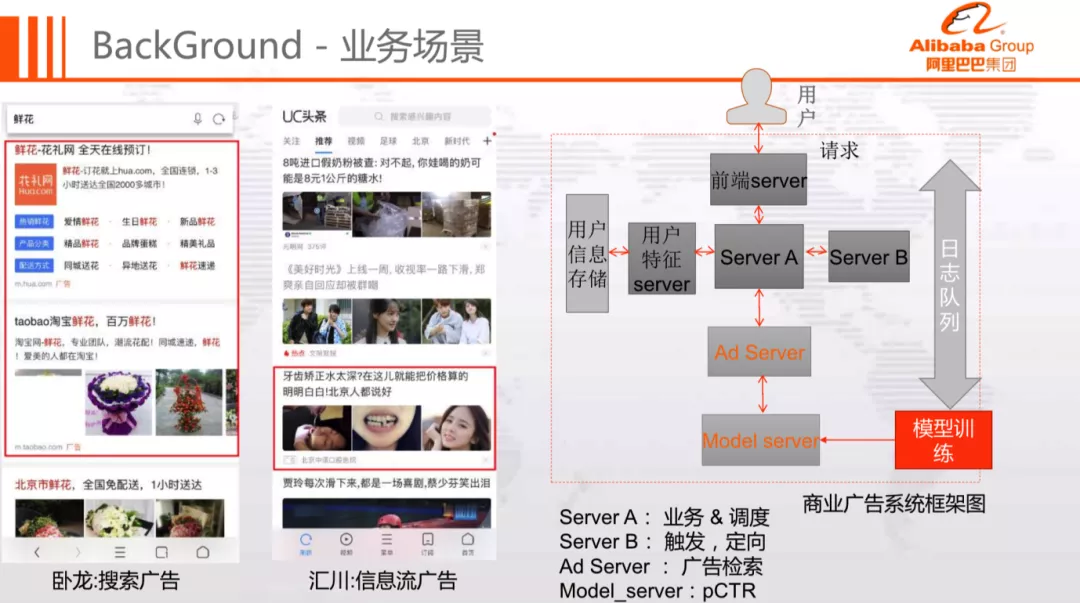
我们的业务场景主要是卧龙-搜索广告和汇川-信息流广告,系统架构如上图所示,模型训练模块负责离线训练和模型产出,Model Server 负责模型加载并提供点击率预估服务,Ad Server 负责广告检索和排序。
2. CTR 预估简介

目前主流的效果广告通常 按照 eCPM ( Pctr x Bid ) 对广告进行 排序,并配合采用 CPC/OCPC 计费模式 ( 仅在用户点击广告时进行扣费 )。eCPM 是由 Pctr 和 Bid 构成,所以点击率预估的准确性将会对平台收益、广告主成本和用户体验产生极大的影响。
CTR 预估问题可以抽象为如下函数:
即根据用户、Query、广告、上下文信息来预估用户在当次请求中对广告的点击概率。
3. 点击率预估场景
当下常见的点击率预估模型包括 LR、FM、DNN、Wide&Deep、DeepFM 等,这里不再进行赘述。这些模型通常在建模时只考虑目标广告,忽略了其他广告对目标广告点击率的影响。举例而言:
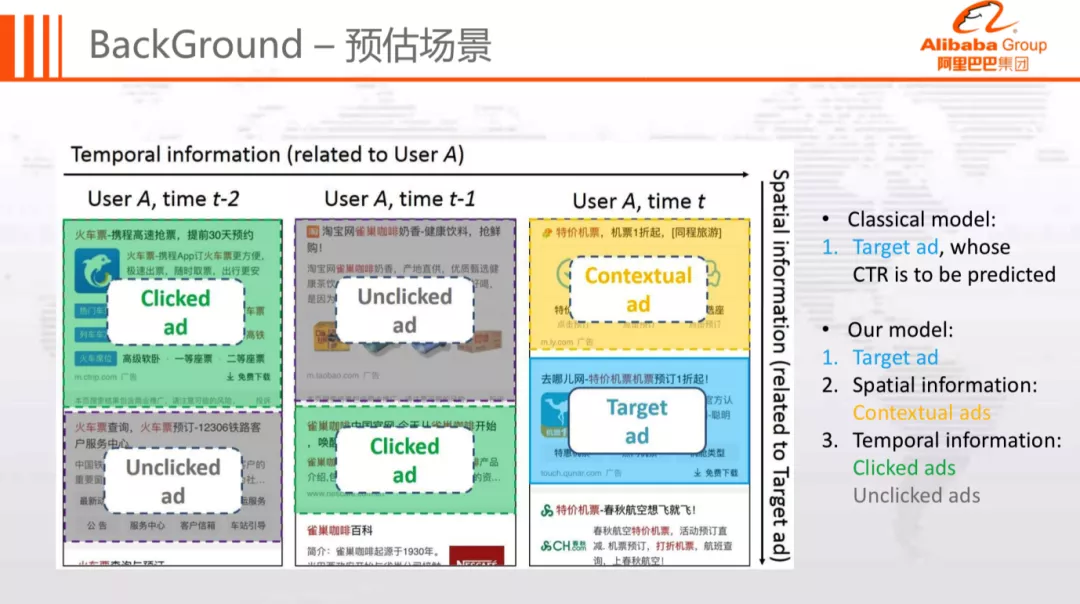
除了目标广告以外,预估场景的时序信息 ( Clicked ad、Unclicked ad ) 和空间信息 ( contextual ad ) 也会对当前广告的点击率预估产生较大的影响,所以我们尝试从这两个方面进行探索,提升预估效果。建模的细节将在后面的 DSTN 和 MA-DNN 章节中详细介绍。
4. 用户行为建模
用户历史行为在一定程度上表达了用户感兴趣和不感兴趣的信息,对于点击率预估有着非常重要的作用。目前业界对于这类特征的建模的方式通常有以下两种:
基于特征工程的方法
基于模型的方法
基于特征工程的方法,一般通过构造统计或序列特征来生成用户画像,依赖人工经验,较为繁琐,而且通常会伴有信息损失。基于模型的方法则一般采用类 RNN 模型,使用用户行为历史数据进行训练,它的缺点是不支持多类型历史行为建模,模型复杂度很高。
针对这两种的方式的缺陷,我们提出了两个模型:
深度时空网络 DSTN
深度记忆网络 MA-DNN
深度时空网络 DSTN 模型基于深度学习来捕获用户历史 ( 时间 ) 和前文广告 ( 空间 ) 的信息。注意,这里仅使用了前文而没有使用后文,是因为在预估的时候无法获得下文信息。
深度记忆网络 MA-DNN 则是通过设计记忆单元,自动抽象用户历史行为构建用户行为表示。
这两篇论文目前都已经被 KDD 2019 收录:
(KDD 2019)Deep Spatio-Temporal Neural Networks for Click-Through Rate Prediction
(KDD 2019 Workshop)Click-Through Rate Prediction with the User Memory Network
02 DSTN 模型
DSTN ( Deep Spatio-Temporal Neural Network ) 通过利用辅助广告 ( 前文广告、历史点击广告、历史展现未点击广告 ) 对用户行为建模。下面将逐步揭露 DSTN 诞生的过程。
1. 模型设计的挑战
在使用时空信息建模时,需要解决以下几个问题:
辅助广告数量不等,如何兼容?
同类型的辅助广告中,既包含与当前广告相关的信息,也包含无用噪声,如何区分对待?
不同类型的辅助广告对目标广告影响不同,怎样融合所有可用信息?
针对这三个问题,我们分别尝试了三种模型结构:
DSTN-P:Pooling Model
DSTN-S:Self-attention Model
DSTN-I:Interactive Attention Model
接下来我们会按照模型结构,逐步阐述模型的演进过程。
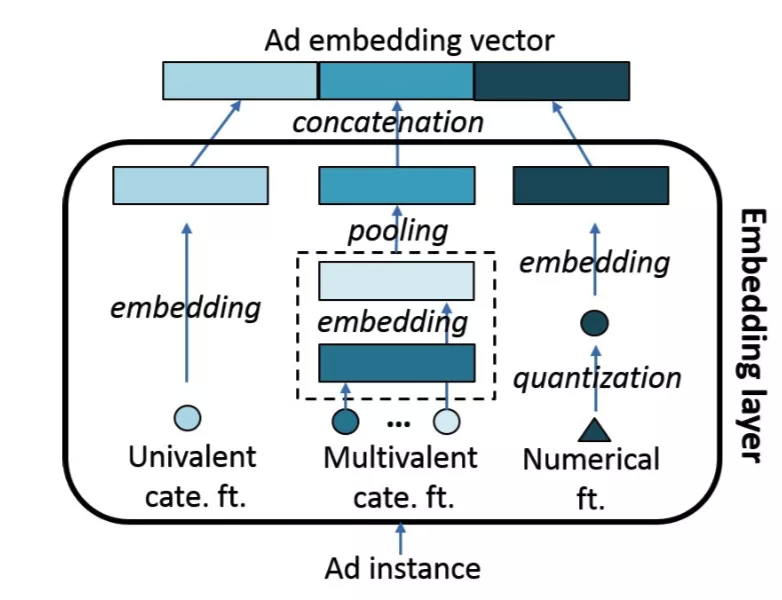
2. 特征 Embedding 化
首先,三类 DSTN 模型都会对广告进行 Embedding 化,Embedding 时会对不同类型的特征将进行如下变换:
单值离散特征:直接 Embedding
多值离散特征:Embedding 后接 Sum Pooling 映射为单个 Embedding
数值特征:离散化后映射为 Embedding
最终,拼接广告所有特征的 Embedding 构造整体输入 Embedding 向量。整体流程如图所示:
3. DSTN-P:Pooling Model
DSTN-P 模型主要考虑解决辅助广告数目不等的问题,模型结构如下图所示:
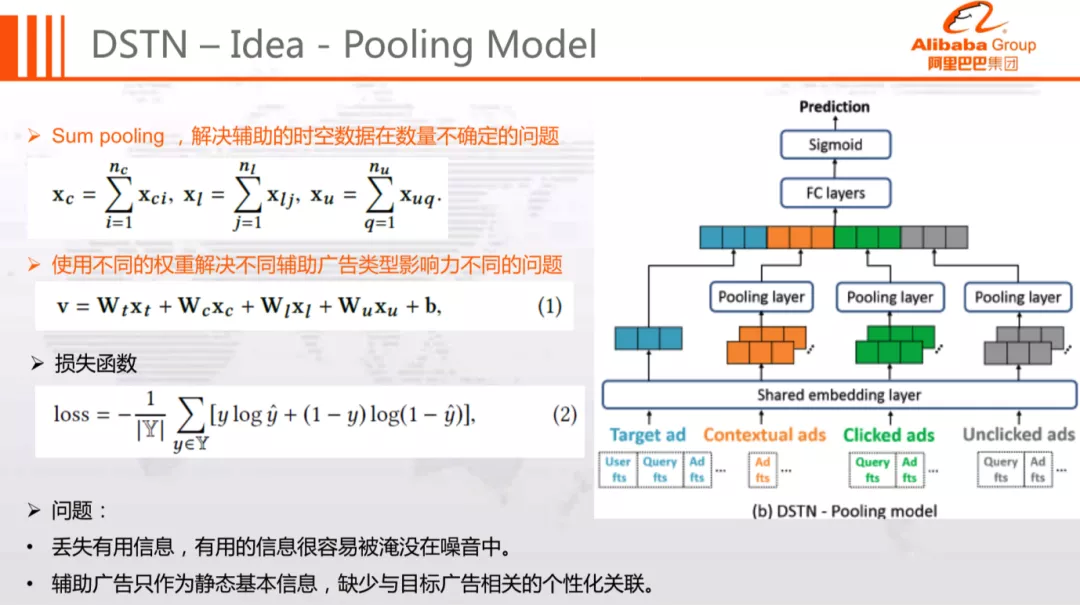
DSTN-P 模型整体流程如下:
分别对目标广告、前文广告、点击广告、未点击广告进行 Embedding 化
每种类型的辅助广告集合通过 Sum Pooling 合并成一个 Embedding
四类广告 ( 目标广告 xt 和三类辅助广告 xc、xl、xu ) 的 Embedding,通过各自权重矩阵 Wt、Wc、Wl、Wu 映射到统一语义空间,得到整体融合表达 v 向量
整体表示 v 经过多层前馈神经网络 ( 激活函数为 Relu ),计算 sigmoid 函数得到预估点击率,以 logloss 为损失函数迭代学习模型参数
该模型通过 Sum Pooling 解决同类型辅助广告数目不等的问题;基于权重矩阵融合不同类型广告的 Embedding,解决了不同类型广告对目标广告影响不同的问题。
这种结构虽然能够解决同类辅助广告数目不等、不同类型辅助广告影响不同的问题,但是依然存在以下缺点:
同类型广告无区分度:在 Sum Pooling 时直接等权求和,可能会导致有用的信息被淹没在大量的噪音中。
Target 无关:在构造辅助广告的 Embedding 表达时,并未考虑辅助广告与 Target 广告的关系
接下来看看 DSTN-S 和 DSTN-I 是如何解决这两个问题的。
4. DSTN-S:Self-attention Model
DSTN-S 模型结构如下图所示:
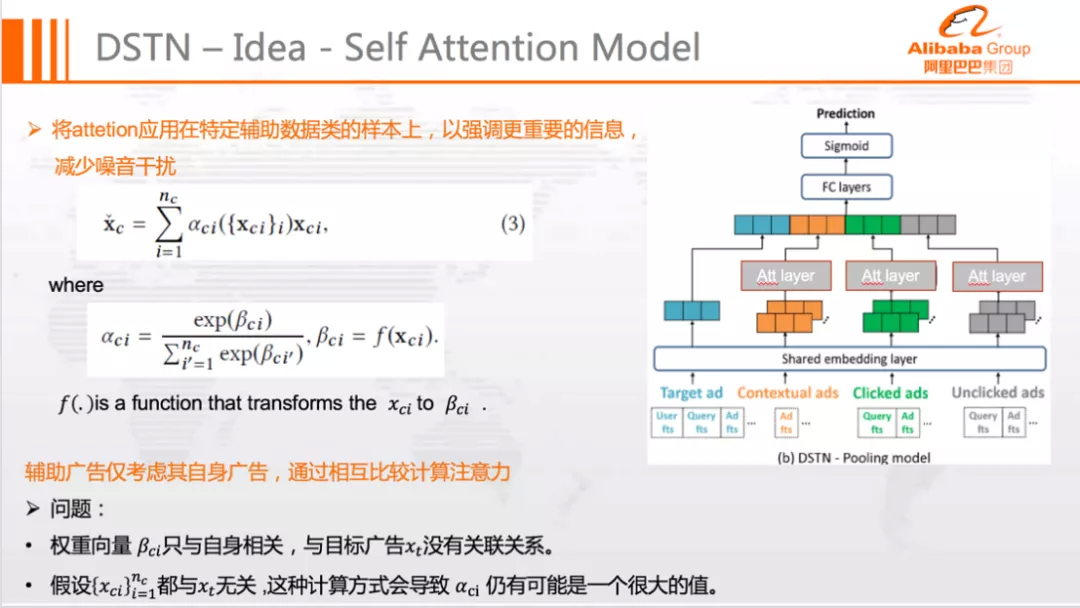
相比于 DSTN-P,DSTN-S 将 Sum Pooling 结构替换为了 Self-attention Model,增强有用信息的同时抑制了无用噪声,缓解了 DSTN-S 模型在同类辅助广告上没有区分度的问题。但是该模型存在以下缺陷:
Target 无关:Self-attention 依然与 Target 广告无关
噪音区分能力较弱:尽管使用了 Attention 机制,但 Attention 权重通过 Softmax 归一化,极端情况下噪音数据影响仍然较大
对于第二点,举例来说,假设总共 3 个辅助广告,且都与目标无关,那么 3 个广告计算出来的 Attention 得分都接近于 0,合理的情况下它们不应该对本次预估产生影响。不过,经过 Softmax 归一化后,三者的权重均为 1/3,依然对预估结果产生了一定程度的影响。
最后,我们来看看 DSTN-I 是如何解决这里的问题。
5. DSTN-I:Interactive-attention Model
模型结构如图所示:
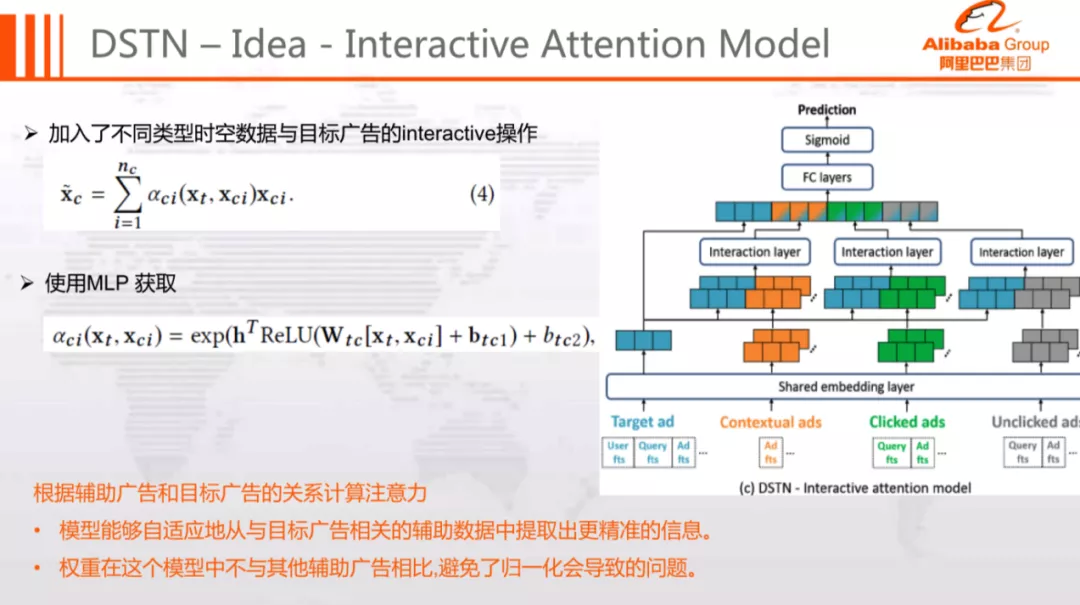
相比于 DSTN-S 模型,DSTN-I 进行了如下优化:
基于辅助广告和目标广告的相互关系计算 Attention,根据目标广告动态地提取最有用的信息
不对同类广告进行 Softmax 归一化,避免了上面提到的归一化问题
通过这两个优化,DSTN-I 模型能够较好的解决之前所述的问题。
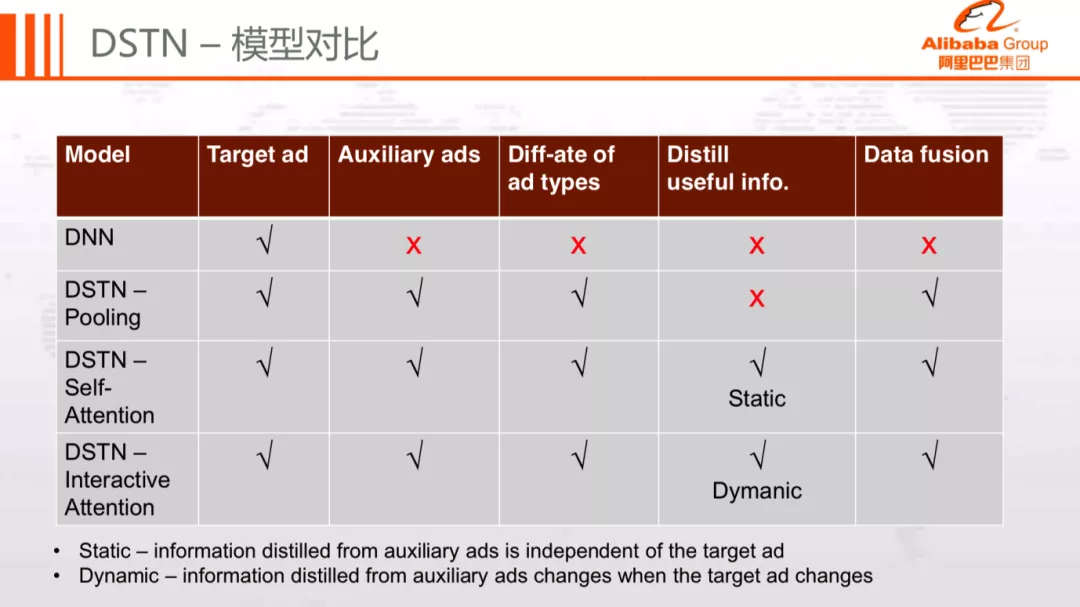
总而言之,相较于普通 DNN 模型,DSTN 模型有以下几点优势:
引入了三种类型的辅助广告信息
对不同的辅助广告类型采用不同权重
基于注意力机制,从同类辅助广告中动态提取有用的信息
在统一框架下,融合多种类型的不定数目的辅助广告信息
对比三类 DSTN 模型,它们的主要区别在于信息提取方式,其中:
DSTN-P 采用 Sum Pooling,信息提取能力最弱
DSTN-S 采用 Self-Attention,基于同类辅助广告的相互关系提取有用信息,信息提取能力适中
DSTN-I 采用 Interactive Attention,根据与目标广告的关系动态提取有用信息,信息提取能力最强
6. 实验分析
我们基于 Avito,Search,Feed 三份数据集进行了离线实验,其中 Avito 是第三方比赛数据集,Search 和 Feed 则是公司内部业务数据集。对比方法包括常用的 CTR 预估模型,评价指标采用 AUC 和 Logloss,辅助广告数据统一采用最近 3 天。详细实验信息如下:

实验结果如下:
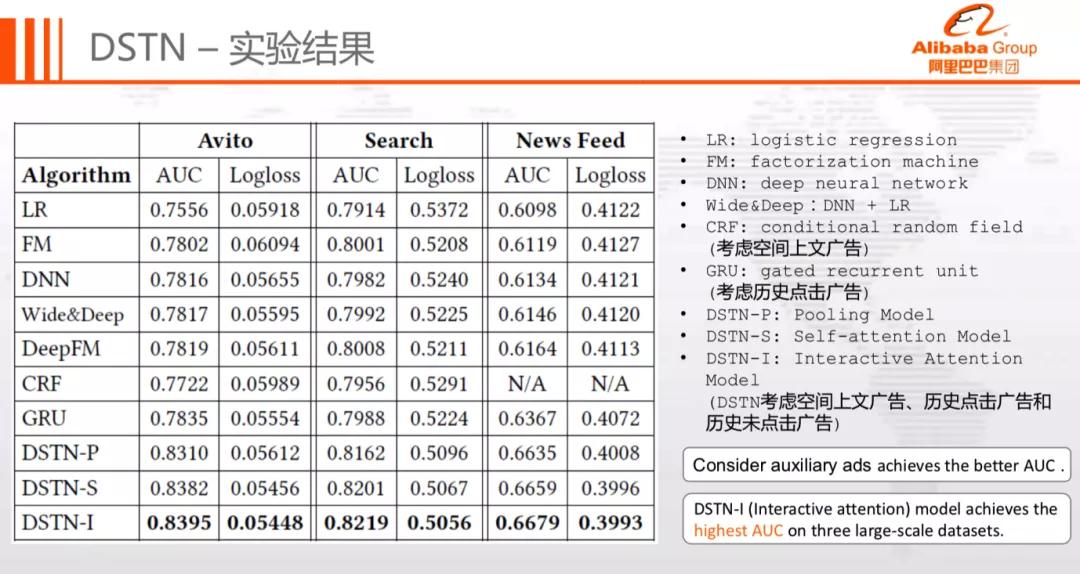
其中 LR、FM、DNN、Wide&Deep 仅考虑了目标广告,未加入时空、上下文等信息,CRF 模型中加入了空间上文,GRU 模型加入了历史点击广告。
从上图可以看到几个比较有意思的现象:
Wide&Deep 模型优于 LR 和 DNN 模型,DeepFM 模型优于 FM 和 DNN 模型
CRF 模型 ( 引入空间上文广告 ) 优于 LR 模型
GRU 模型 ( 引入历史点击广告 ) 优于 DNN 模型
DSTN 模型整体均优于其他模型
这说明了两点:
深浅层模型优于独立模型
历史行为信息和空间信息能够起到重要作用
接下来我们细化分析各个优化点的影响和收益。
首先分析的是不同的辅助广告类型所起作用的大小,通过控制变量法单独使用某种类型的辅助广告进行实验,实验指标分别考虑绝对 AUC 和归一化 AUC。
注:归一化 AUC 指标是为了屏蔽不同数据集的辅助广告数量不同带来的偏差。
实验结果如下图所示:

从绝对 AUC 指标来看,对于不同的数据集,没有绝对的胜利者,不同辅助广告在不同数据集起到的作用不同。从归一化 AUC 指标来看,历史未点击广告的影响最小。
接下来将可视化分析不同模型学到的广告 Embedding 表示,效果图如下:
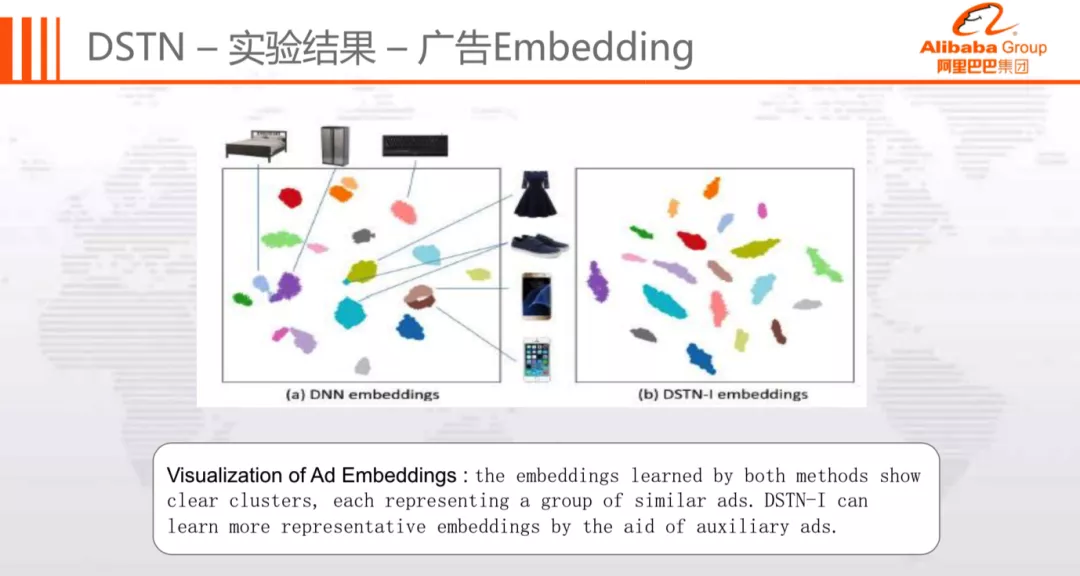
可以看到,DNN Embedding 的整体结果不错,但是对于部分广告区分度不高,如:床和冰箱,裙子和鞋,三星和苹果手机依然存在一定程度的重叠。而对于 DSTN-I Embedding,各个类别的广告都能够被很好的分开。
最后我们观察模型学到的注意力得分的分布。

图中第一列代表目标广告,一二三行分别表示前文广告、点击广告、未点击广告。从左到右,辅助广告与目标广告的相似度逐渐增加。辅助广告下面的横条代表注意力得分。
从中可以观察到以下现象:
第一行,目标广告与前文广告越相似,注意力的得分越低。推测因为它们会相互竞争用户的注意力。
第二行,历史点击广告与目标广告越相似,注意力得分越高。说明历史点击行为能够在一定程度上反应用户兴趣。
第三行,历史未点击的广告与目标广告越相似,注意力得分越高。说明历史不点击行为能够在一定程度上反应用户不感兴趣。 与第二行不同的是,历史点击广告表达的是正向相关,而历史未点击广告则表示负向相关。
纵向对比三行的注意力得分绝对值,可以看出不同类型的辅助广告产生的作用是不同的。
接下来展示的是在线实验框架:
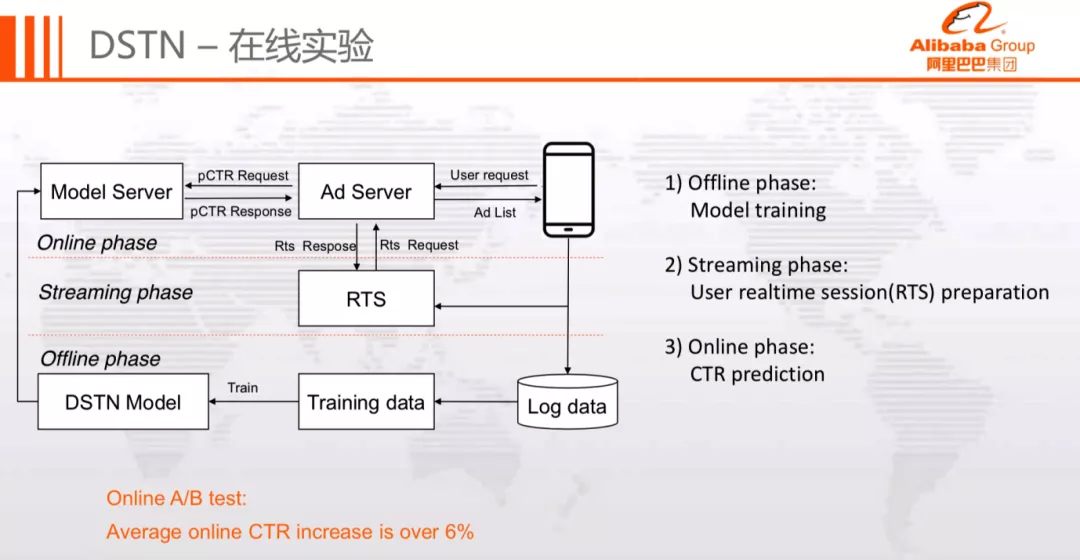
在线实验框架主要包含 3 部分:
离线模型训练,产出 Model,并推送到 Model Server
User realtime session ( RTS ) 实时流,为用户准备实时历史行为数据
Model Server 进行在线 pCTR 预估
最终在线上 A/B 实验中取得了+6%的 CTR 提升,十分显著。
7. 小结
深度时空网络 ( DSTNs ) 利用三种类型的辅助数据 ( contextual,clicked and unclicked ad ) 来提升对目标广告 CTR 预估的准确性。模型具体的优化可以归纳为以下三点:
DSTN-I 模型引入了时间和空间维度的辅助数据,并能够有效区分不同类型辅助数据的重要性
DSTN-I 模型能够动态地从辅助数据中提取与目标广告相关的有用信息
DSTN-I 模型能够将多种不同类型的数据有效融合
03. MA-DNN 模型
MA-DNN ( Memory Augmented Deep Neural Network ) 通过巧妙地设计用户兴趣记忆单元和损失函数,建模用户行为兴趣。
1. 背景
在使用 DSTN 模型对用户行为历史建模时,会碰到下面几个问题:
输入数据拼接复杂
数据存储空间消耗大
仅能建模有限数量的辅助广告
在线 Inference 复杂
这些问题使得 DSTN 模型在实际训练和部署时需要较高的机器和人力成本,在一定程度上制约了模型的应用场景。所以我们继续尝试其他模型结构的探索,进一步扩大用户行为建模的应用场景。
首先,再回顾一下业界用户行为序列建模的代表— GRU 模型,模型结构如下图所示:
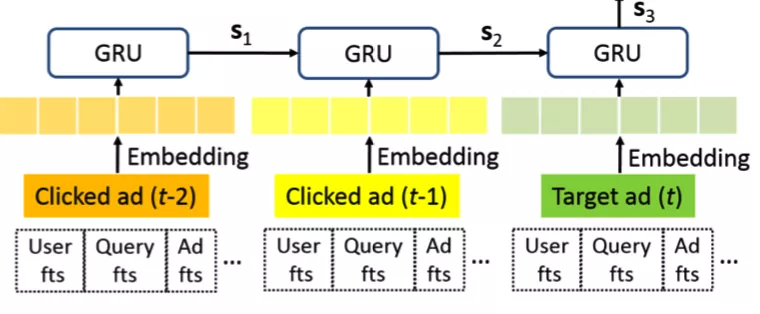
它通过输入用户行为序列,再经过门控函数逐步学习,建模用户历史行为。GRU 模型存在以下两个缺陷:
训练数据准备复杂
在线 Inference 耗时严重
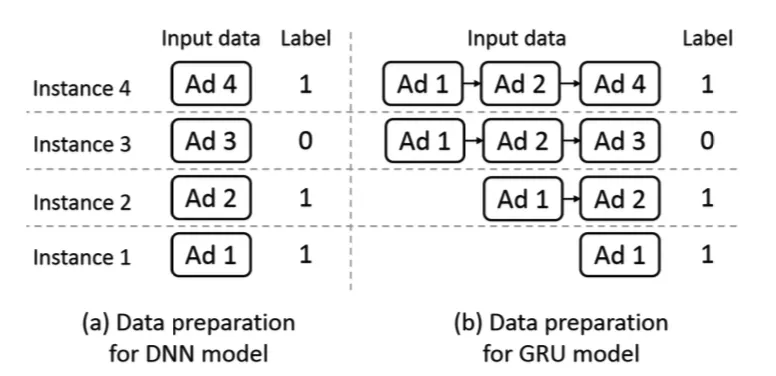
如上图所示,普通 DNN 的训练数据只需要准备当前的广告,而 GRU 模型则需要拼接用户行为序列。其次,GRU 模型的训练数据存在一定冗余。如示例所示,Ad1 在 DNN 中只出现了一次,而 GRU 中则每条样本都会出现。
在线预估方面,DNN 和 GRU 的对比如下图所示:
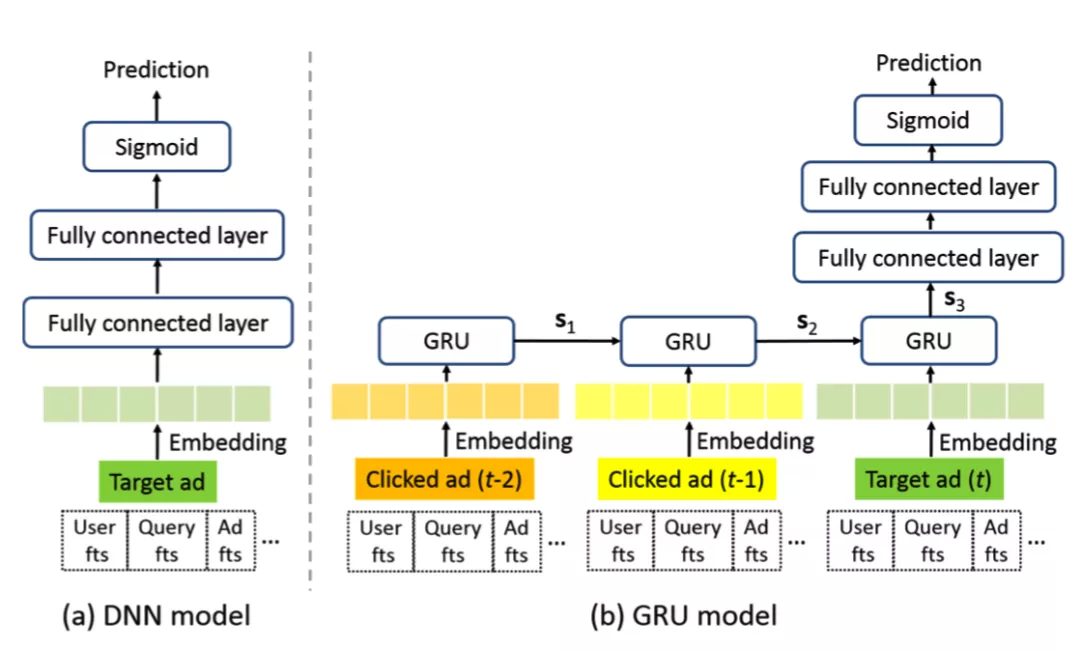
相比于 DNN 只有标准的 FC 连接层,GRU 模型需要串行地经过多个 GRU 单元,再经过 FC 层进行预估,这大大提高了 Inference 复杂度。
针对这里的问题,我们思考是否可以通过设计更高效的模型结构,在基本保留 GRU 效果的前提下,大幅降低模型复杂度,使得 Inference 效率与 DNN 基本持平。基于这样的考虑,我们设计了 MA-DNN 网络。
2. MA-DNN Model
MA-DNN 模型的结构如下图所示:
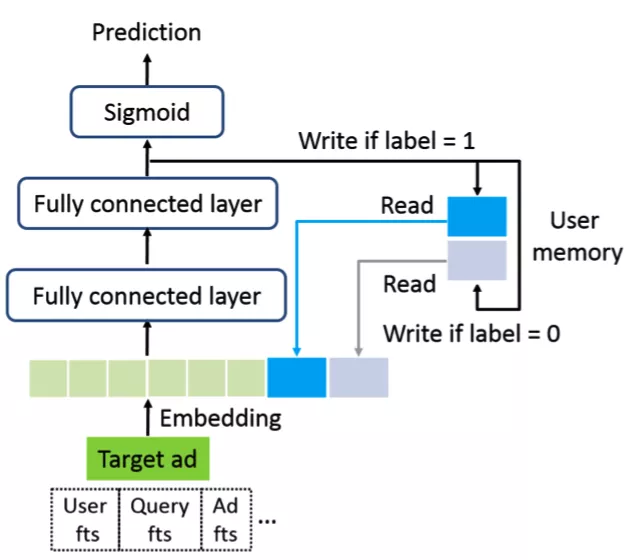
对于每个用户 U,MA-DNN 会保留两个记忆向量 mu0和 mu1( 图中 User memory ),分别记忆用户不喜欢和喜欢的信息。在预估时,我们会查询当前 User 的两个记忆向量,并将它拼接到 DNN 的输入 Embedding 层,再通过 MLP 获得最终的 CTR 预估结果。
那么如何准确的学习用户的两个记忆向量 mu0和 mu1 呢?回顾一下 DNN 模型结构,我们可以将最后一层的 embedding 看成是对输入向量的高阶抽象。那么理想情况下,当发生点击时,应该让用户感兴趣的向量 mu1和最后一层 embedding 尽可能相似;同理,当没有发生点击时,应该让用户不感兴趣的向量 mu0 和最后一层 embedding 尽可能相似。
基于上述考虑,我们在设计了如下损失函数:
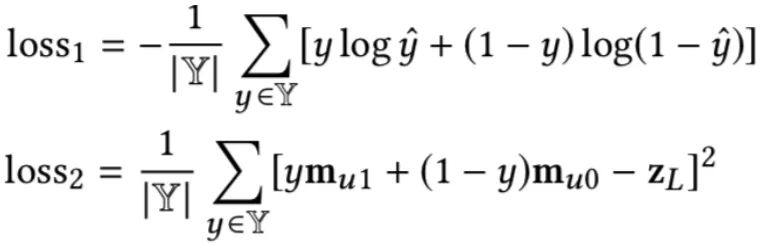
loss1 是经典的交叉熵损失,用于训练 CTR 主模型;loss2 是均方损失,用来学习用户记忆向量 mu0和 mu1。通过巧妙地设计损失函数,使得 Label 为 1 时更新感兴趣向量 mu1,label 为 0 时更新不感兴趣向量 mu0。
整体 loss = loss1 + αloss2,α 是可调节超参。值得注意的是,loss2 只是用来训练兴趣向量,不应该影响 DNN 最后一层的高阶抽象向量 zL,所以在训练时,loss2 只更新 mu0 和 mu1,不更新 zL。
3. 实验分析
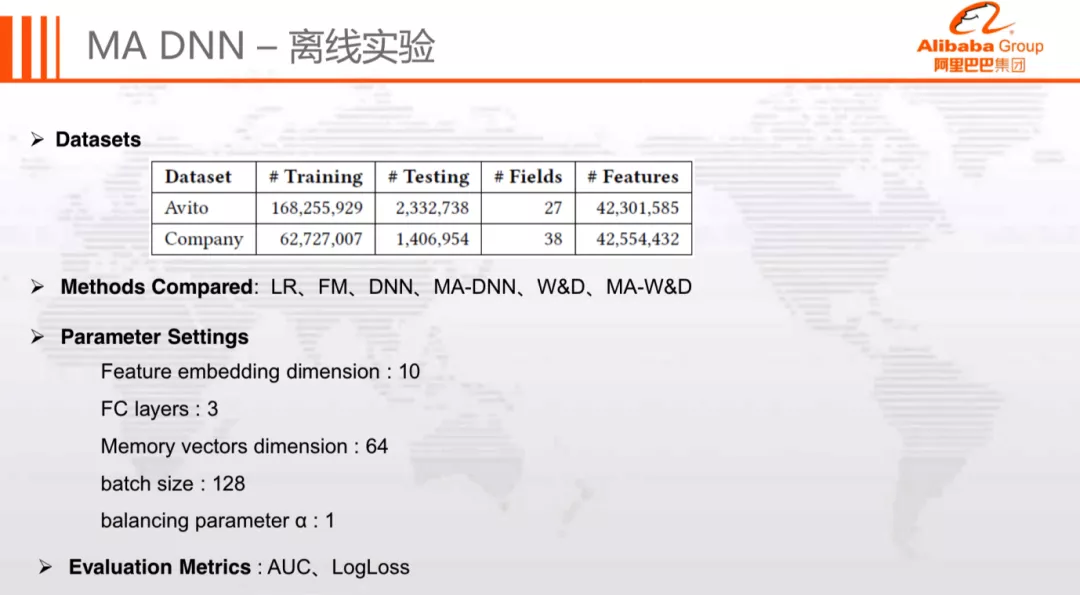
离线实验的数据集分别采用了 Avito 和公司内部数据集,评估指标采用 AUC 和 LogLoss,对比模型包括 LR、FM、DNN 等。整体实验数据和模型参数如下图所示:
实验结果如下:
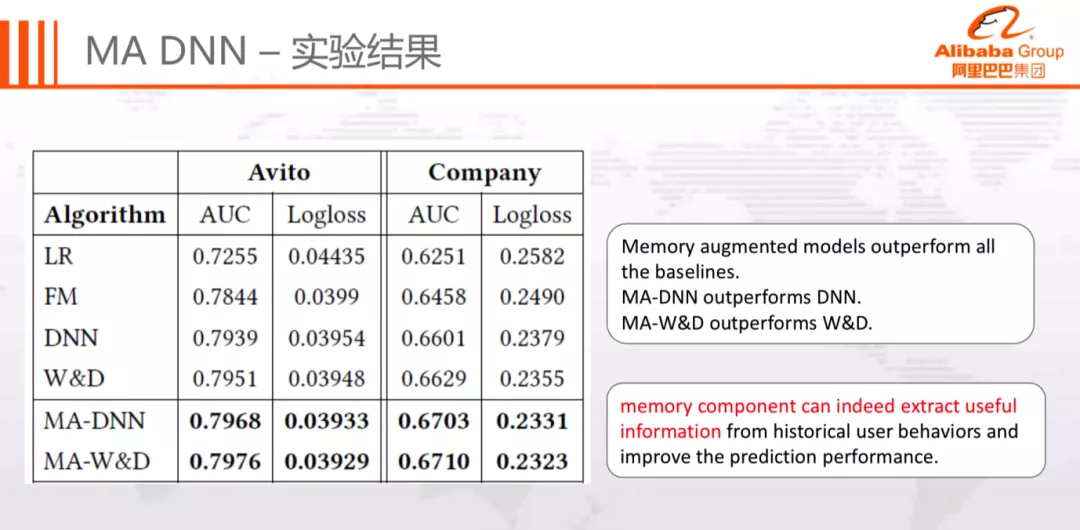
可以看到,记忆组件能够从用户历史行为中提取有用信息,进而提升模型效果。同时,记忆组件具有良好的扩展性,在较低的成本下,能够快速地接入迁移至 DNN、Wide&Deep 等模型。
在线实验的框架和 DSTN 一致,只是将 DSTN 替换为 MA-DNN。最终在线上 A/B 实验中取得了+2.5%的 CTR 提升。
4. MA-DNN vs DSTN

MA-DNN 模型和 DSTN 模型,两者各有优劣。DSTN 优势在于支持多种辅助数据的学习,基于注意力机制高效地提取有用信息,效果很显著; 不足在于复杂度和应用门槛较高,导致扩展性受限。MA-DNN 不足在于只支持时间信息的学习,信息提取能力稍弱;优势在于支持更加长期的时间信息学习,拥有良好的扩展性和 Inference 性能,应用门槛更低,能够适用更多场景。
5. 小结
MA-DNN 为每个用户设计了两个记忆向量,分别记录用户感兴趣和不感兴趣的信息。
MA-DNN 实现了在 DNN 和 RNN 之间很好的平衡,以近似 DNN 的复杂度,达到了近似 RNN 的效果。
MA-DNN 拥有良好的扩展性,记忆组件可以灵活的添加至多种模型。
本次的分享就到这里,谢谢大家。
作者介绍:
邹衡,阿里巴巴算法专家
本文来自 DataFunTalk
原文链接:
活动推荐:
2023年9月3-5日,「QCon全球软件开发大会·北京站」 将在北京•富力万丽酒店举办。此次大会以「启航·AIGC软件工程变革」为主题,策划了大前端融合提效、大模型应用落地、面向 AI 的存储、AIGC 浪潮下的研发效能提升、LLMOps、异构算力、微服务架构治理、业务安全技术、构建未来软件的编程语言、FinOps 等近30个精彩专题。咨询购票可联系票务经理 18514549229(微信同手机号)。

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...













评论