

深度学习模型之所以在各种任务中取得了成功,足够的网络深度起到了很关键的作用,那么是不是模型越深,性能就越好呢?
为什么加深可以提升性能
Bengio 和 LeCun 在 2017 年的文章[1]中有这么一句话,“We claim that most functions that can be represented compactly by deep architectures cannot be represented by a compact shallow architecture”,大体意思就是大多数函数如果用一个深层结构刚刚好解决问题,那么就不可能用一个更浅的同样紧凑的结构来解决。
要解决比较复杂的问题,要么增加深度,要么增加宽度,而增加宽度的代价往往远高于深度。
Ronen Eldan 等人甚至设计了一个能被小的 3 层网络表示,而不能被任意的 2 层网络表示的函数。总之,一定的深度是必要的。
那么随着模型的加深,到底有哪些好处呢?
1.1、更好拟合特征
现在的深度学习网络结构的基本模块是卷积,池化,激活,这是一个标准的非线性变换模块。更深的模型,意味着更好的非线性表达能力,可以学习更加复杂的变换,从而可以拟合更加复杂的特征输入。
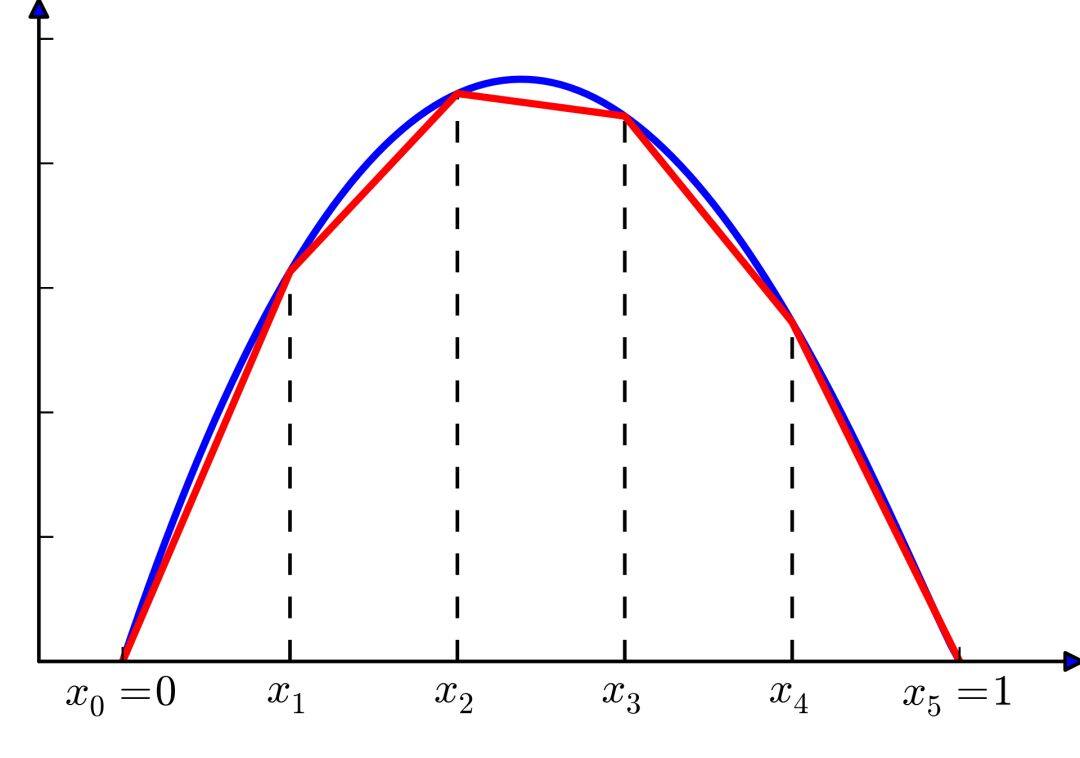
看下面的一个对比图[2],实线是一个只有一层,20 个神经元的模型,虚线是一个 2 层,每一层 10 个神经元的模型。从图中可以看出,2 层的网络有更好的拟合能力,这个特性也适用于更深的网络。
1.2、网络更深,每一层要做的事情也更加简单了。
每一个网络层各司其职,我们从 zfnet 反卷积看一个经典的网络各个网络层学习到的权重。
第一层学习到了边缘,第二层学习到了简单的形状,第三层开始学习到了目标的形状,更深的网络层能学习到更加复杂的表达。如果只有一层,那就意味着要学习的变换非常的复杂,这很难做到。

上面就是网络加深带来的两个主要好处,更强大的表达能力和逐层的特征学习。
如何定量评估深度与模型性能
理论上一个 2 层的网络可以拟合任何有界的连续函数,但是需要的宽度很大,这在实际使用中不现实,因此我们才会使用深层网络。
我们知道一个模型越深越好,但是怎么用一个指标直接定量衡量模型的能力和深度之间的关系,就有了直接法和间接法两种方案。
直接法便是定义指标理论分析网络的能力,间接法便是通过在任务中的一系列指标比如准确率等来进行比较。
2.1、直接法
早期对浅层网络的研究,通过研究函数的逼近能力,网络的 VC 维度等进行评估,但是并不适用于深层网络。
目前直接评估网络性能一个比较好的研究思路是线性区间(linear regions)。可以将神经网络的表达看作是一个分段线性函数,如果要完美的拟合一个曲线,就需要无数多的线性区间(linear regions)。线性区间越多,说明网络越灵活。
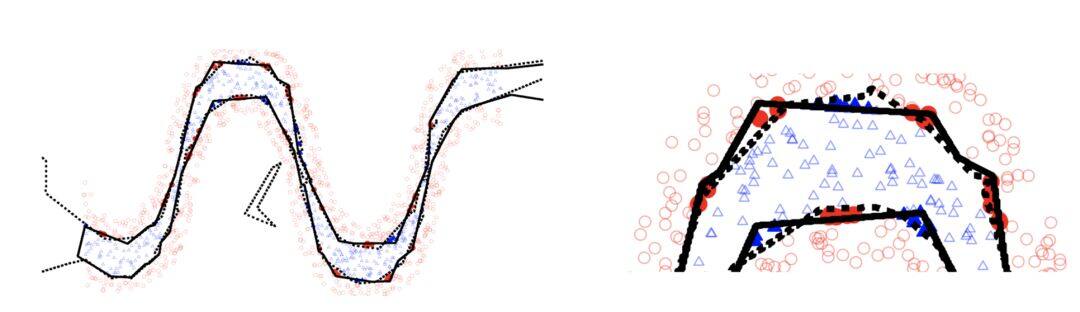
Yoshua Bengio 等人就通过线性区间的数量来衡量模型的灵活性。一个更深的网络,可以将输入空间分为更多的线性响应空间,它的能力是浅层网络的指数级倍。
对于一个拥有 n0 个输入,n 个输出,kn 个隐藏层的单层网络,其最大数量为:
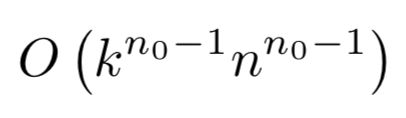
对于拥有同样多的参数,n0 个输入,n 个输出,k 个隐藏层,每一层 n 个节点的多层网络,其最大数量为:
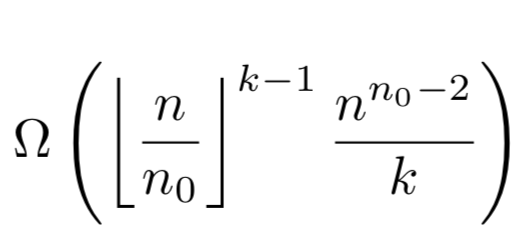
因为 n0 通常很小,所以多层网络的数量是单层的指数倍(体现在 k 上),计算是通过计算几何学来完成,大家可以参考论文[3]。
除此之外还有一些其他的研究思路,比如 monica binachini[4]等使用的 betti number,Maithra Raghu 等提出的 trajectory length[5]。
虽然在工程实践中这些指标没有多少意义甚至不一定有效,但是为我们理解深度和模型性能的关系提供了理论指导。
2.2、间接法
间接法就是展现实验结果了,网络的加深可以提升模型的性能,这几乎在所有的经典网络上都可以印证。比较不同的模型可能不够公平,那就从同一个系列的模型来再次感受一下,看看 VGG 系列模型,ResNet 系列模型,结果都是从论文中获取。
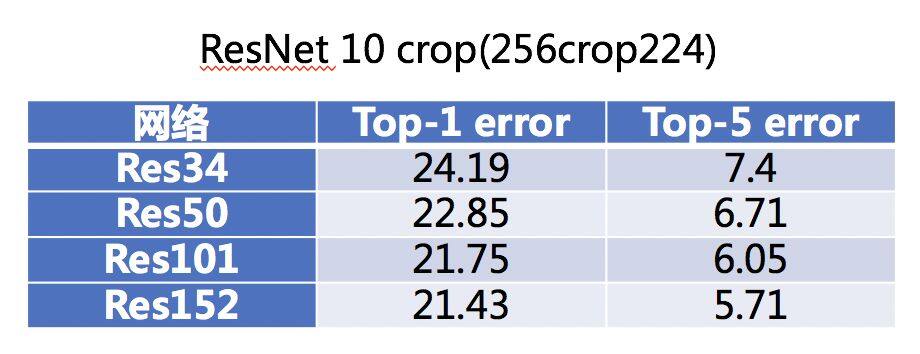
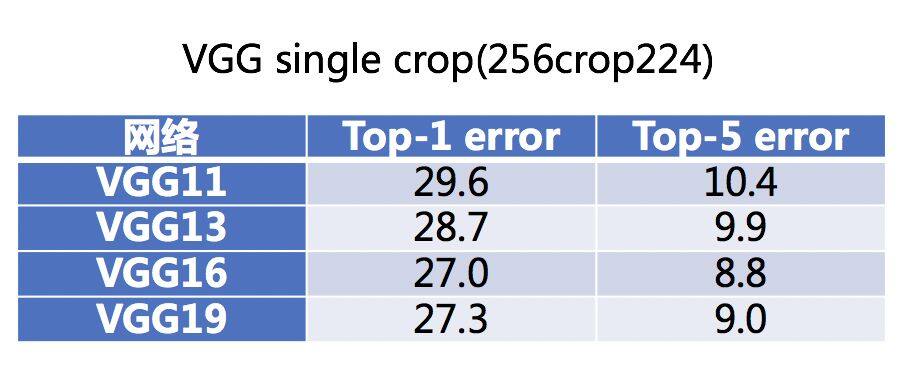
在一定的范围内,网络越深,性能的确就越好。
3 加深就一定更好吗?
前面说到加深在一定程度上可以提升模型性能,但是未必就是网络越深就越好,我们从性能提升和优化****两个方面来看。
3.1、加深带来的优化问题
ResNet 为什么这么成功,就是因为它使得深层神经网络的训练成为可行。虽然好的初始化,BN 层等技术也有助于更深层网络的训练,但是很少能突破 30 层。
VGGNet19 层,GoogleNet22 层,MobileNet28 层,经典的网络超过 30 层的也就是 ResNet 系列常见的 ResNet50,ResNet152 了。虽然这跟后面 ImageNet 比赛的落幕,大家开始追求更加高效实用的模型有关系,另一方面也是训练的问题。
深层网络带来的梯度不稳定,网络退化的问题始终都是存在的,可以缓解,没法消除。这就有可能出现网络加深,性能反而开始下降。
3.2、网络加深带来的饱和
网络的深度不是越深越好,下面我们通过几个实验来证明就是了。公开论文中使用的 ImageNet 等数据集研究者已经做过很多实验了,我们另外选了两个数据集和两个模型。
第一个数据集是 GHIM 数据集,第二个数据集是从 Place20 中选择了 20 个类别,可见两者一个比较简单,一个比较困难。
第一个模型就是简单的卷积+激活的模型,第二个就是 mobilenet 模型。
首先我们看一下第一个模型的基准结构,包含 5 层卷积和一个全连接层, 因此我们称其为 allconv6 吧,表示深度为 6 的一个卷积网络。
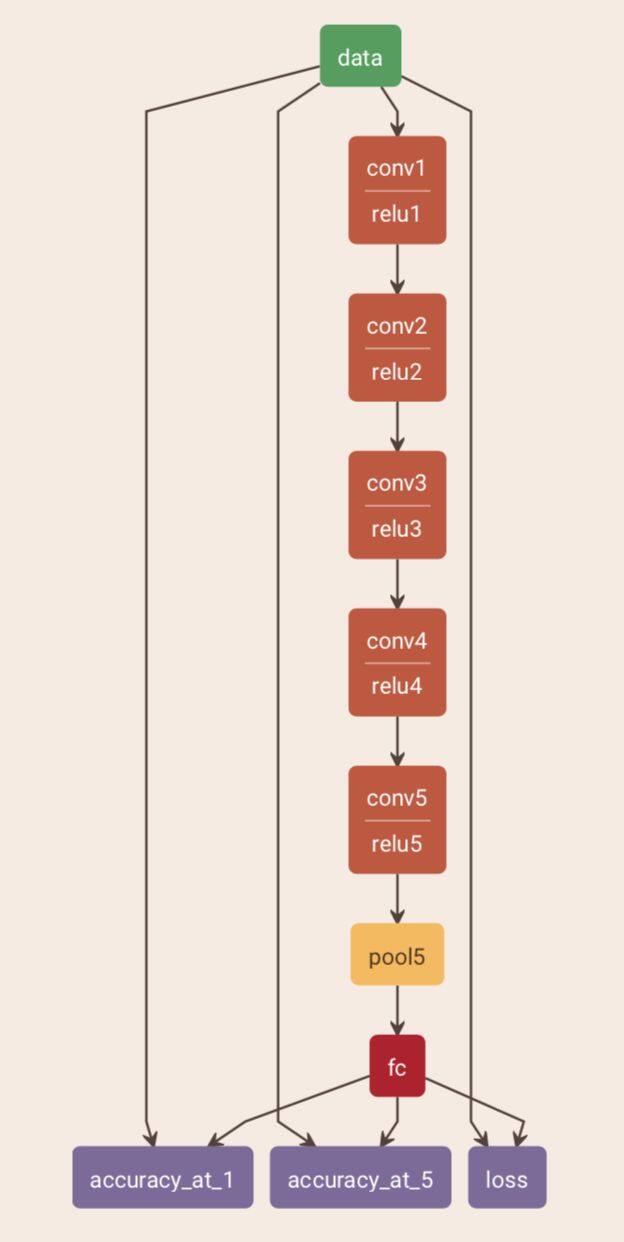
接下来我们试验各种配置,从深度为 5 到深度为 8,下面是每一个网络层的 stride 和通道数的配置。
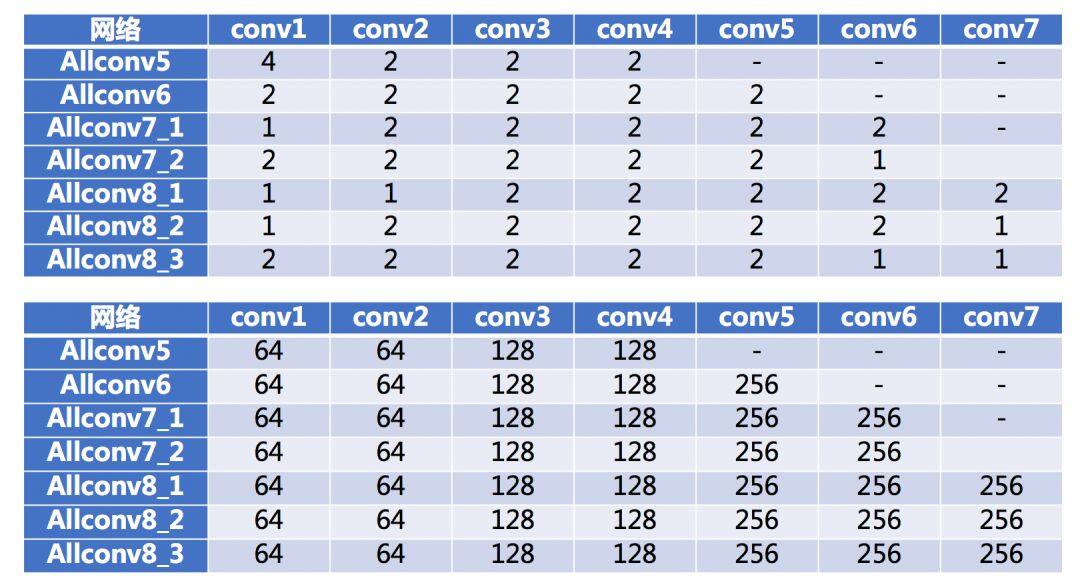
我们看结果,优化都是采用了同一套参数配置,而且经过了调优,具体细节篇幅问题就不多说了。
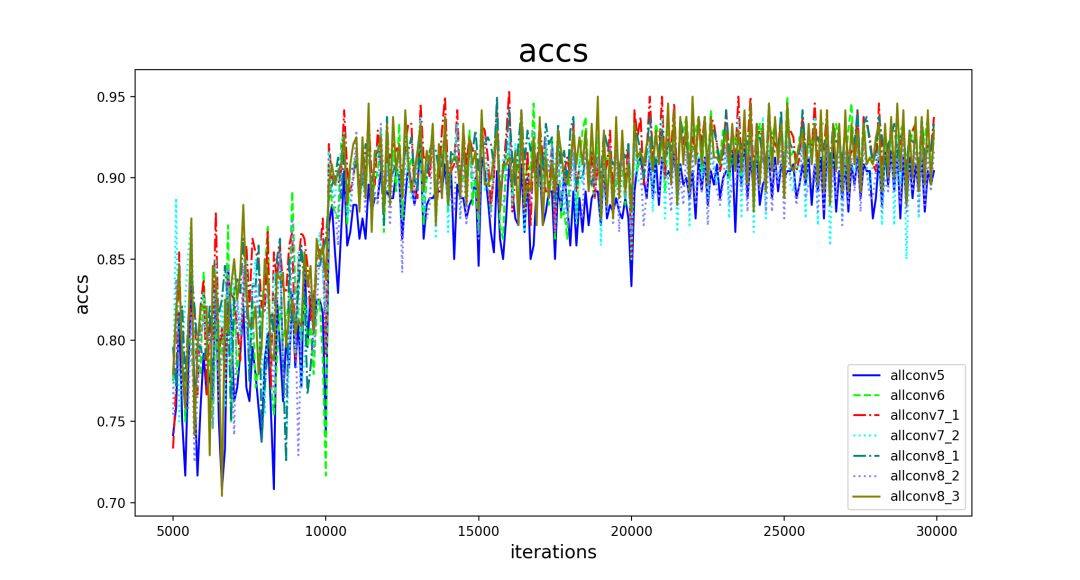
看的出来网络加深性能并未下降,但是也没有多少提升了。allconv5 的性能明显更差,深度肯定是其中的一个因素。
我们还可以给所有的卷积层后添加 BN 层做个试验,结果如下,从 allconv7_1 和 allconv8_1 的性能相当且明显优于 allconv6 可以得出与刚才同样的结论。
那么,对于更加复杂的数据集,表现又是如何呢?下面看在 place20 上的结果,更加清晰了。
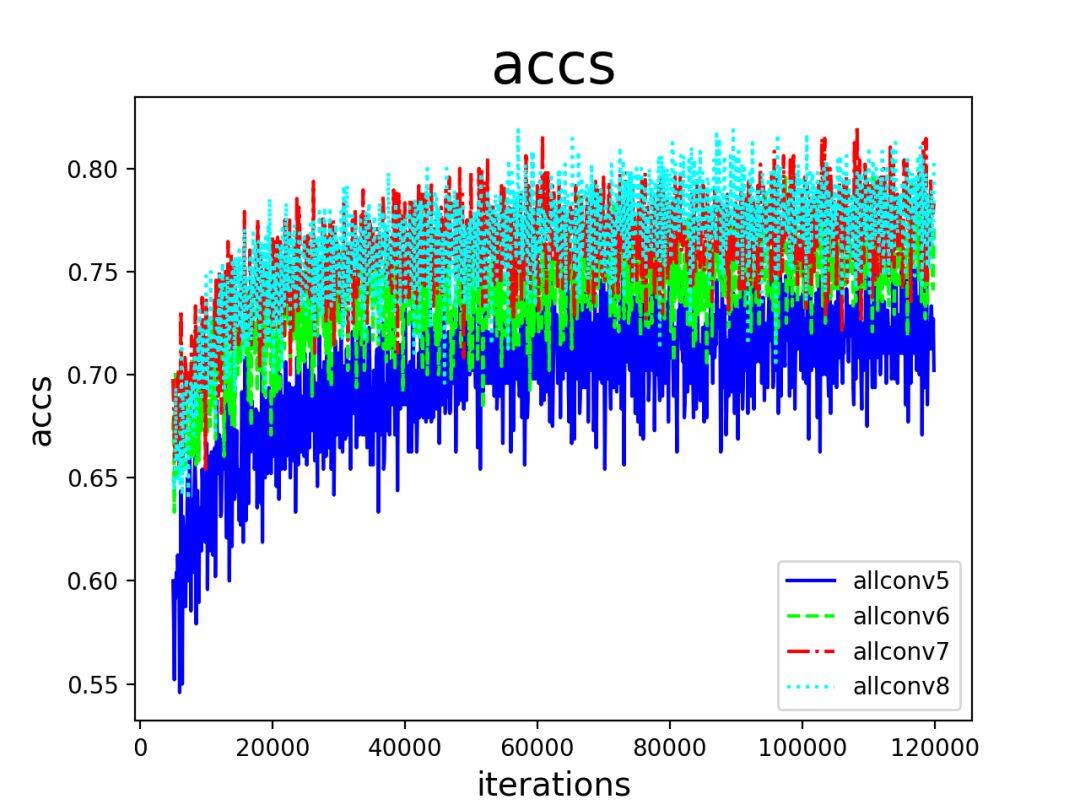
allconv5,allconv6 结果明显比 allconv7,allconv8 差,而 allconv7 和 allconv8 性能相当。所以从 allconv 这个系列的网络结构来看,随着深度增加到 allconv7,之后再简单增加深度就难以提升了。
接下来我们再看一下不同深度的 mobilenet 在这两个数据集上的表现,原始的 mobilenet 是 28 层的结构。
不同深度的 MobileNet 在 GHIM 数据集的结果如下:
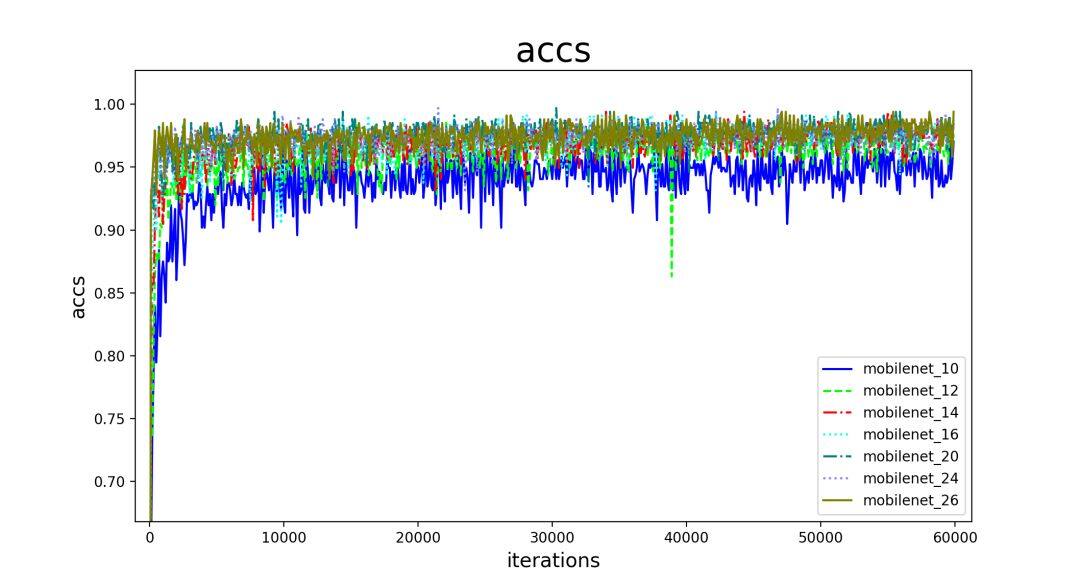
看得出来当模型到 16 层左右后,基本就饱和了。
不同深度的 MobileNet 在 Place20 数据集的结果如下:
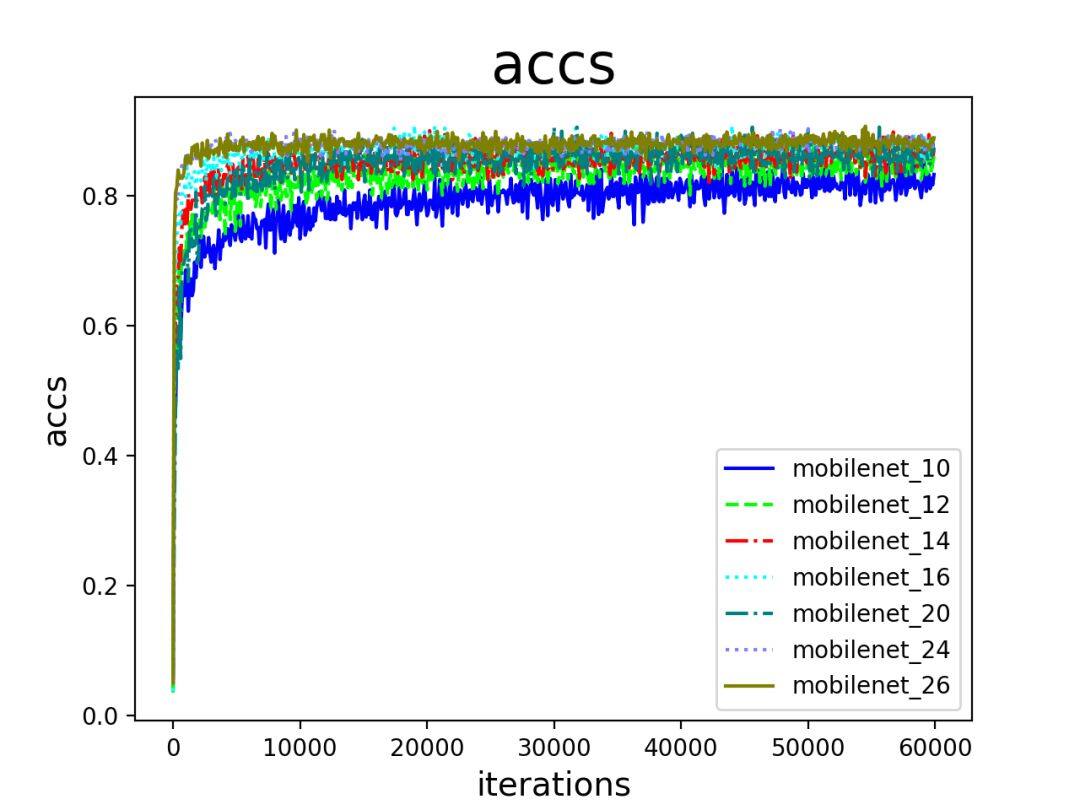
与 GHIM 的结果相比,深度带来的提升更加明显一些,不过也渐趋饱和。
这是必然存在的问题,哪有一直加深一直提升的道理,只是如何去把握这个深度,尚且无法定论,只能依靠更多的实验了。
除此之外,模型加深还可能出现的一些问题是导致某些浅层的学习能力下降,限制了深层网络的学习,这也是跳层连接等结构能够发挥作用的很重要的因素。
参考链接:
[1] Bengio Y, LeCun Y. Scaling learning algorithms towards AI[J]. Large-scale kernel machines, 2007, 34(5): 1-41.
[2] Montufar G F, Pascanu R, Cho K, et al. On the number of linear regions of deep neural networks[C]//Advances in neural information processing systems. 2014: 2924-2932.
[3] Pascanu R, Montufar G, Bengio Y. On the number of response regions of deep feed forward networks with piece-wise linear activations[J]. arXiv preprint arXiv:1312.6098, 2013.
[4] Bianchini M, Scarselli F. On the complexity of neural network classifiers: A comparison between shallow and deep architectures[J]. IEEE transactions on neural networks and learning systems, 2014, 25(8): 1553-1565.
[5] Raghu M, Poole B, Kleinberg J, et al. On the expressive power of deep neural networks[C]//Proceedings of the 34th International Conference on Machine Learning-Volume 70. JMLR. org, 2017: 2847-2854.
作者介绍
言有三,公众号《有三 AI》作者,致力于为读者提供 AI 各个领域所需的系统性的专业知识。
原文链接
本文源自言有三的知乎,链接:
https://zhuanlan.zhihu.com/p/63560913

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论