

最近基于 transformer 的一些 NLP 模型很火(比如 BERT,GPT-2 等),因此将 transformer 模型引入到推荐算法中是近期的一个潮流。transformer 比起传统的 LSTM、GRU 等模型,可以更好地建模用户的行为序列。本文主要整理 transformer 在推荐模型中的一些应用。
1. Self-Attentive Sequential Recommendation
模型结构:
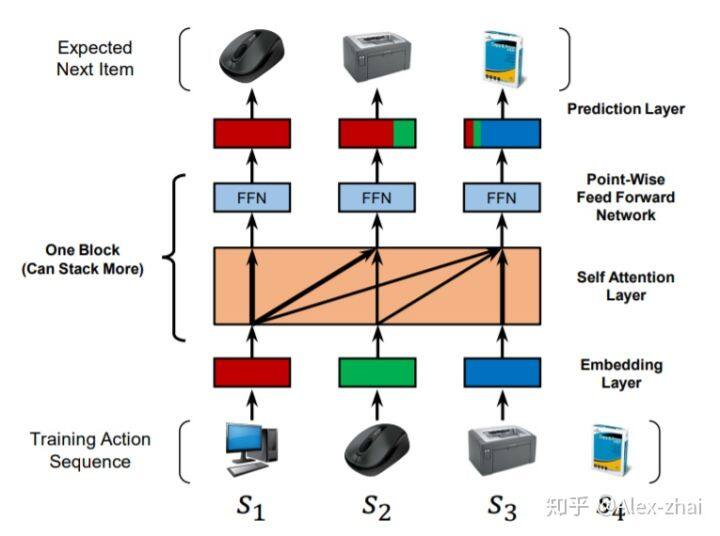
方法:
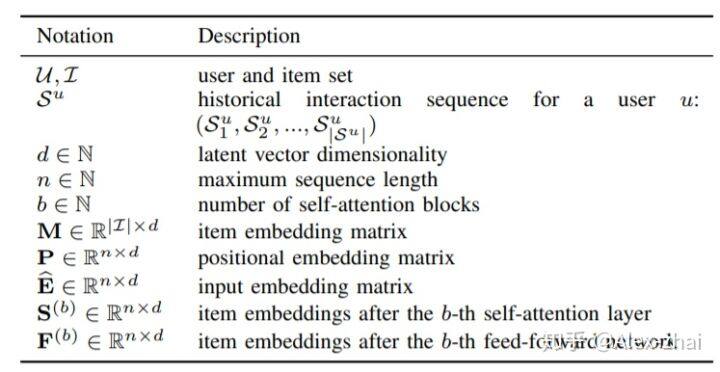
符号定义:
问题定义:模型输入是用户 u 的一个历史交互序列: [公式] , 其期望的输出是该交互序列一个时间刻的偏移: [公式] 。
Embedding 层
将输入序列 [公式] 转化成固定长度的序列 [公式] 。意思是如果序列长度超过 n,则使用最近 n 个行为。如果不足 n,则从左侧做 padding 直到长度为 n。
位置 embedding: 因为 self-attention 并不包含 RNN 或 CNN 模块,因此它不能感知到之前 item 的位置。本文输入 embedding 中也结合了位置 Embedding P 信息,并且位置 embedding 是可学习的:
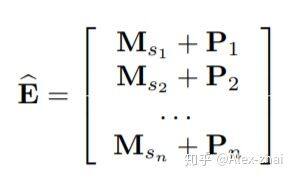
Self-Attention 层
Transformer 中 Attention 的定义为:
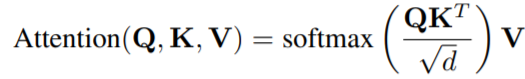
本文中,self-attention 以 embedding 层的输出作为输入,通过线性投影将它转为 3 个矩阵,然后输入 attention 层:
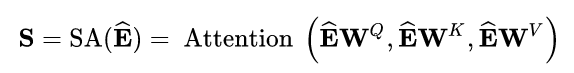
为了避免在预测 i 时刻的 item 时用到后续时刻的信息,本文将符合(j > i)条件的 [公式] 与 [公式] 之间的连接 forbidding 掉,这是因为 self-attention 每个时刻的输出会包含所有时刻的信息。
Point-wise 前馈网络
尽管 self-attention 能够用自适应权重并且聚焦之前所有的 item,但最终它仍是个线性模型。可用一个两层的 point-wise 前馈网络去增加非线性同时考虑不同隐式维度之间的交互:
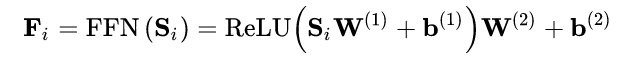
Self-Attention layer 的堆叠
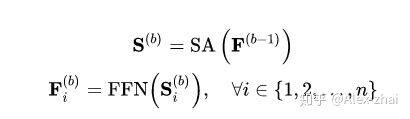
预测层
最后采用 MF 层来预测相关的 item i:
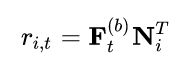
其中 [公式] 是给定 t 个 item,下一个 item i 的相关性。N 是 item embedding 矩阵。
为了减少模型尺寸及避免过拟合,共用一个 item embedding:
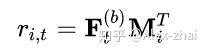
显式用户建模
为了提供个性化推荐,当前主要有两种方法:学习显式的用户 embedding 表示用户偏好(MF,FPMC,Caser);考虑用户之前的行为,通过访问过的 item 的 embedding 推测隐式的用户 embedding。本文采用第二种方式,同时额外在最后一层插入显式用户 embedding [公式] ,例如通过加法实现:
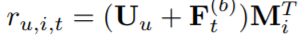
但是通过实验发现增加显式用户 embedding 并没有提升效果。
网络训练
定义时间步 t 的输出为:
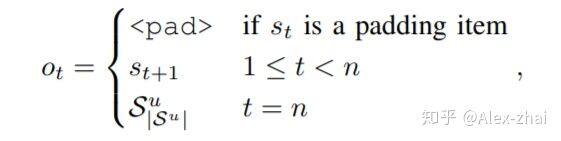
用二元交叉熵损失作为目标函数:
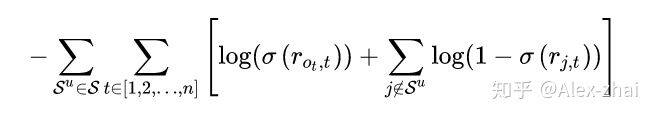
2. Next Item Recommendation with Self-Attention
模型:
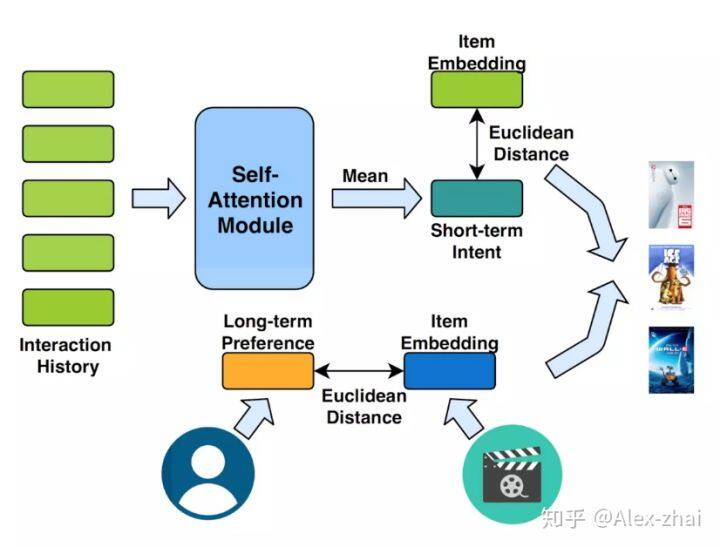
本文亮点是同时建模用户短期兴趣(由 self-attention 结构提取)和用户长期兴趣。其短期兴趣建模过程如下:
假定使用用户最近的 L 条行为记录来计算短期兴趣。可使用 X 表示整个物品集合的 embedding,那么,用户 u 在 t 时刻的前 L 条交互记录所对应的 embedding 表示如下:
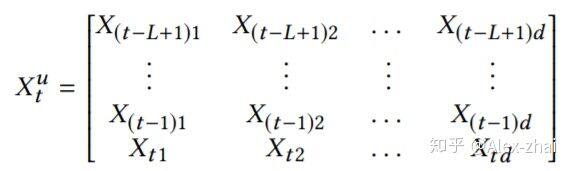
其中每个 item 的 embedding 维度为 d,将 [公式] 作为 transformer 中一个 block 的输入:
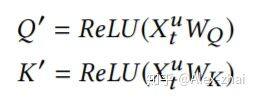
这里需要注意和传统 transformer 的不同点:
计算 softmax 前先掩掉 [公式] 矩阵的对角线值,因为对角线其实是 item 与本身的一个内积值,容易给该位置分配过大的权重。
没有将输入 [公式] 乘以 [公式] 得到 [公式] ,而是直接将输入[公式]乘以 softmax 算出来的 score。
直接将 embedding 在序列维度求平均,作为用户短期兴趣向量。
另外加入了时间信号:
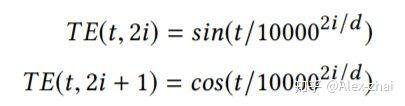
self-attention 模块只使用用户最近的 L 个交互商品作为用户短期的兴趣。那么怎么建模用户的长期兴趣呢?可认为用户和物品同属于一个兴趣空间,用户的长期兴趣可表示成空间中的一个向量,而某物品也可表示为成该兴趣空间中的一个向量。那如果一个用户对一个物品的评分比较高,说明这两个兴趣是相近的,那么它们对应的向量在兴趣空间中距离就应该较近。这个距离可用平方距离表示:
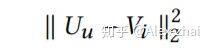
其中 U 是用户的兴趣向量,V 是物品的兴趣向量
综合短期兴趣和长期兴趣,可得到用户对于某个物品的推荐分,推荐分越低,代表用户和物品越相近,用户越可能与该物品进行交互:
模型采用 pair-wise 的方法训练,即输入一个正例和一个负例,希望负例的得分至少比正例高γ,否则就发生损失,并在损失函数加入 L2 正则项:
BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer
亮点:结合使用预训练的 BERT 模型
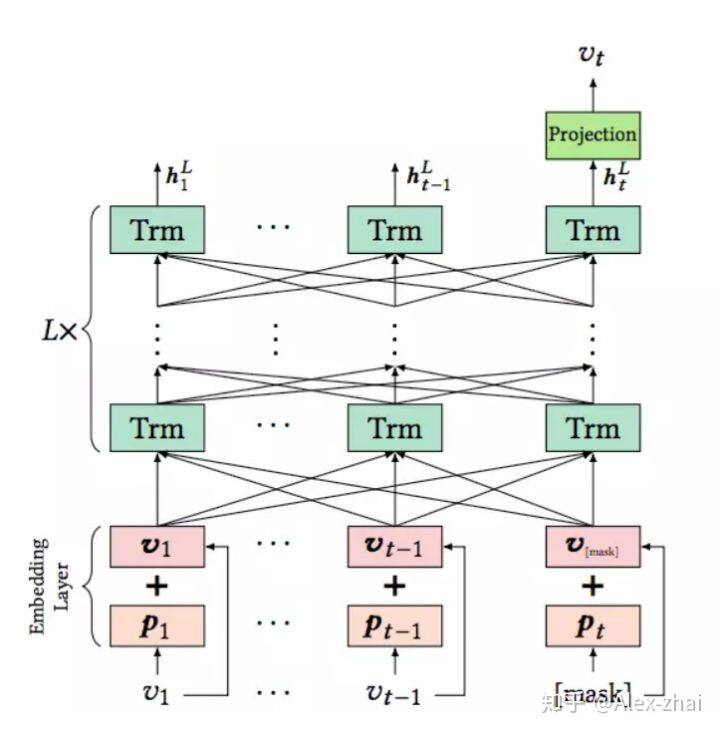
模型架构:
Embedding Layer
模型的输入是用户历史交互序列,对交互序列中的每一个物品 i,其 Embedding 包含两部分,一部分是物品的 Embedding,用 vi 表示,另一部分是位置信息的 Embedding,用 pi 表示。这里的 pi 是可学习的。
Transformer Layer
主要包括 Multi-Head Self-Attention 层和 Position-Wise Feed-Forward Network,其中 Multi-Head Self-Attention 计算过程如下:
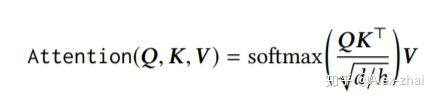
Position-Wise Feed-Forward Network 的作用是将每个位置(也可理解为每个时间刻 t)上的输入分别输入到前向神经网络中:
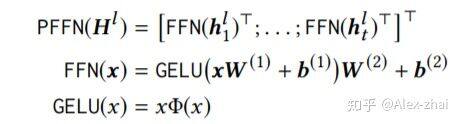
Stacking Transformer Layer
使用了类似于 resnet 的 skip 连接结构:
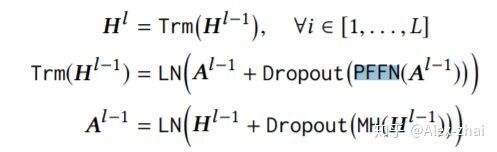
Output Layer
模型训练
因为在 BERT4Rec 中,输入历史序列[v1,v2,…,vt-1],输出的是包含上下文信息的向量[h1,h2,…,ht-1],这里每个向量 ht 都包含了整个序列的信息。如果要预测用户 t 时刻的交互物品 vt,如果直接把 vt 作为输入,那么其余每个物品在 Transformer Layer 中会看到目标物品 vt 的信息,造成一定程度的信息泄漏。因此可把对应位置的输入变成[mask]标记。打标记的方式和 BERT 一样,随机把输入序列的一部分遮盖住,然后让模型来预测这部分对应的商品:
最终的 loss 函数为:
4. Behavior Sequence Transformer
这里就不详细介绍了,可参考我之前的一篇文章:https://zhuanlan.zhihu.com/p/72018969
总结
transformer 结构可用于对用户短期内的行为序列进行建模(比如最近的 n 次行为序列),比起传统的 RNN、CNN 模型,transformer 的优势在于它在每个时刻 t 求得的隐藏向量 ht 都包含整个序列的信息(这其实就是 self-attention 结构的优势,可建模出任意一个时刻 item 和所有时刻 item 的相关性)。因此可将 transformer 结构用于用户的短期兴趣 embedding 建模,然后再将该 embedding 向量用于召回或者 ranking 阶段。
参考文献:
https://arxiv.org/pdf/1808.09781.pdf
https://arxiv.org/pdf/1808.06414.pdf
https://arxiv.org/pdf/1904.06690.pdf
https://arxiv.org/pdf/1905.06874.pdf
本文转载自 Alex-zhai 知乎账号。
原文链接:https://zhuanlan.zhihu.com/p/85825460

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论