

导语 本文分享了笔者在 STGW 现网遇到的一个文件下载慢的问题。最开始尝试过很多办法,包括域名解析,网络链路分析,AB 环境测试,网络抓包等,但依然找不到原因。然后利用网络命令和报文得到的蛛丝马迹,结合内核网络协议栈的实现代码,找到了一个内核隐藏很久但在最近版本解决了的 BUG。如果你也想了解如何分析和解决诡异的网络问题,如果你也想温习一下课堂上曾经学习过的慢启动、拥塞避免、快速重传、AIMD 等老掉牙的知识,如果你也渴望学习课本上完全没介绍过的 TCP 的一系列优化比如混合慢启动、尾包探测甚至 BBR 等,那么本文或许可以给你一些经验和启发。
问题背景
线上用户经过 STGW(Secure Tencent Gateway,腾讯安全网关-七层转发代理)下载一个 50M 左右的文件,与直连用户自己的服务器相比,下载速度明显变慢,需要定位原因。在了解到用户的问题之后,相关的同事在线下做了如下尝试:
从广州和上海直接访问用户的回源 VIP(Virtual IP,提供服务的公网 IP 地址)下载,都耗时 4s+,正常;

只经过 TGW(Tencent Gateway,腾讯网关-四层负载均衡系统),不经过 STGW 访问,从广州和上海访问上海的 TGW,耗时都是 4s+,正常;

经过 STGW,从上海访问上海的 STGW VIP,耗时 4s+,正常;

经过 STGW,从广州访问上海的 STGW VIP,耗时 12s+,异常。

前面的三种情况都是符合预期,而第四种情况是不符合预期的,这个也是本文要讨论的问题。
前期定位排查
发现下载慢的问题后,我们分析了整体的链路情况,按照链路经过的节点顺序有了如下的排查思路:
(1)从客户端侧来排查,DNS 解析慢,客户端读取响应慢或者接受窗口小等;
(2)从链路侧来排查,公网链路问题,中间交换机设备问题,丢包等;
(3)从业务服务侧来排查,业务服务侧发送响应较慢,发送窗口较小等;
(4)从自身转发服务来排查,TGW 或 STGW 转发程序问题,STGW 拥塞窗口缓存等;
按照上面的这些思路,我们分别做了如下的排查。
1.是否是由于异常客户端的 DNS 服务器解析慢导致的?
用户下载小文件没有问题,并且直接访问 VIP,配置 hosts 访问,发现问题依然复现,排除。
2.是否是由于客户端读取响应慢或者接收窗口较小导致的?
抓包分析客户端的数据包处理情况,发现客户端收包处理很快,并且接收窗口一直都是有很大空间。排除。
3.是否是广州到上海的公网链路或者交换机等设备问题,导致访问变慢?
从广州的客户端上 ping 上海的 VIP,延时很低,并且测试不经过 STGW,从该客户端直接访问 TGW 再到回源服务器,下载正常,排除。
4.是否是 STGW 到回源 VIP 这条链路上有问题?
在 STGW 上直接访问用户的回源 VIP,耗时 4s+,是正常的。并且打开了 STGW LD(LoadBalance Director,负载均衡节点)与后端 server 之间的响应缓存,抓包可以看到,后端数据 4s 左右全部发送到 STGW LD 上,是 STGW LD 往客户端回包比较慢,基本可以确认是 Client->STGW 这条链路上有问题。排除。
5.是否是由于 TGW 或 STGW 转发程序有问题?
由于异地访问必定会复现,同城访问就是正常的。而 TGW 只做四层转发,无法感知源 IP 的地域信息,并且抓包也确认 TGW 上并没有出现大量丢包或者重传的现象。STGW 是一个应用层的反向代理转发,也不会对于不同地域的 cip 有不同的处理逻辑。排除。
6.是否是由于 TGW 是 fullnat 影响了拥塞窗口缓存?
因为之前由于 fullnat 出现过一些类似于本例中下载慢的问题,当时定位的原因是由于 STGW LD 上开启了拥塞窗口缓存,在 fullnat 的情况下,会影响拥塞窗口缓存的准确性,导致部分请求下载慢。但是这里将拥塞窗口缓存选项 sysctl -w net.ipv4.tcp_no_metrics_save=1 关闭之后测试,发现问题依然存在,并且线下用另外一个 fullnat 的 vip 测试,发现并没有复现用户的问题。排除。
根据一些以往的经验和常规的定位手段都尝试了以后,发现仍然还是没有找到原因,那到底是什么导致的呢?
问题分析
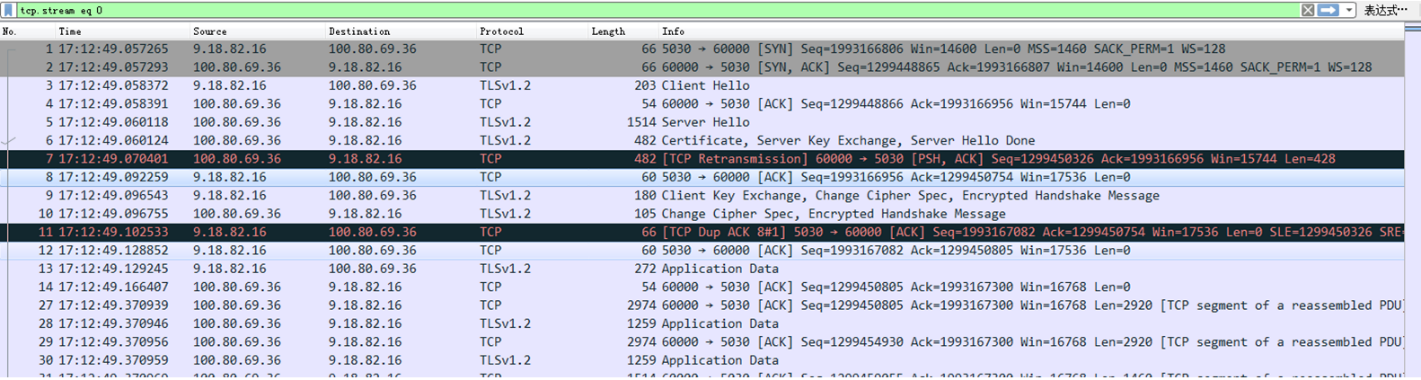
首先,在复现的 STGW LD 上抓包,抓到 Client 与 STGW LD 的包如下图,从抓包的信息来看是 STGW 回包给客户端很慢,每次都只发很少的一部分到 Client。
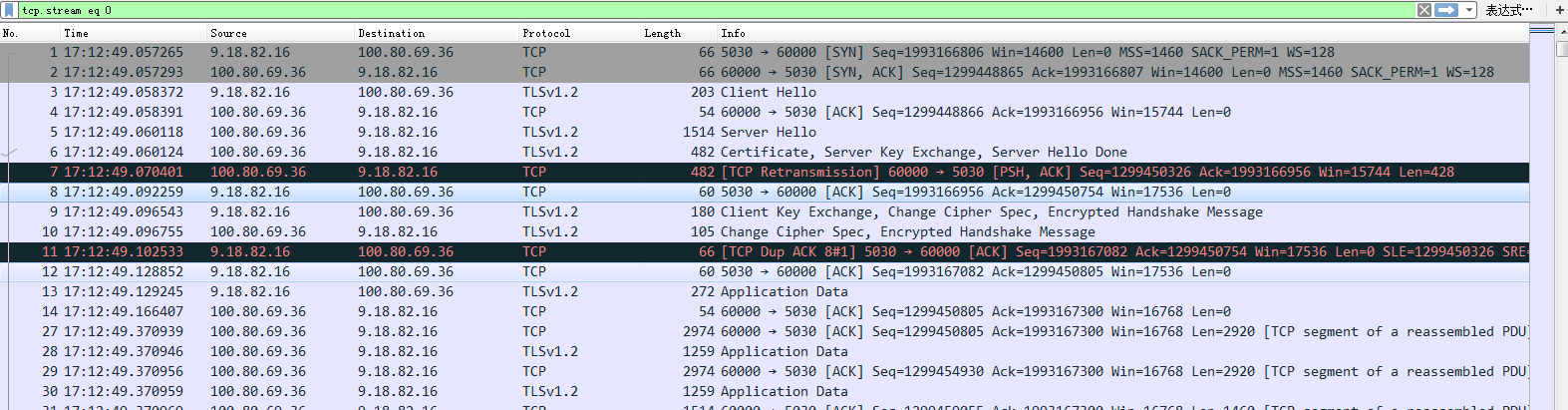
这里有一个很奇怪的地方就是为什么第 7 号包发生了重传?不过暂时可以先将这个疑问放到一边,因为就算 7 号包发生了一个包的重传,这中间也并没有发生丢包,LD 发送数据也并不应该这么慢。那既然 LD 发送数据这么慢,肯定要么是 Client 的接收窗口小,要么是 LD 的拥塞窗口比较小。
对端的接收窗口,抓包就可以看到,实际上 Client 的接收窗口并不小,而且有很大的空间。那是否有办法可以看到 LD 的发送窗口呢?答案是肯定的:ss -it,这个指令可以看到每条连接的 rtt,ssthresh,cwnd 等信息。有了这些信息就好办了,再次复现,并写了个命令将 cwnd 等信息记录到文件:
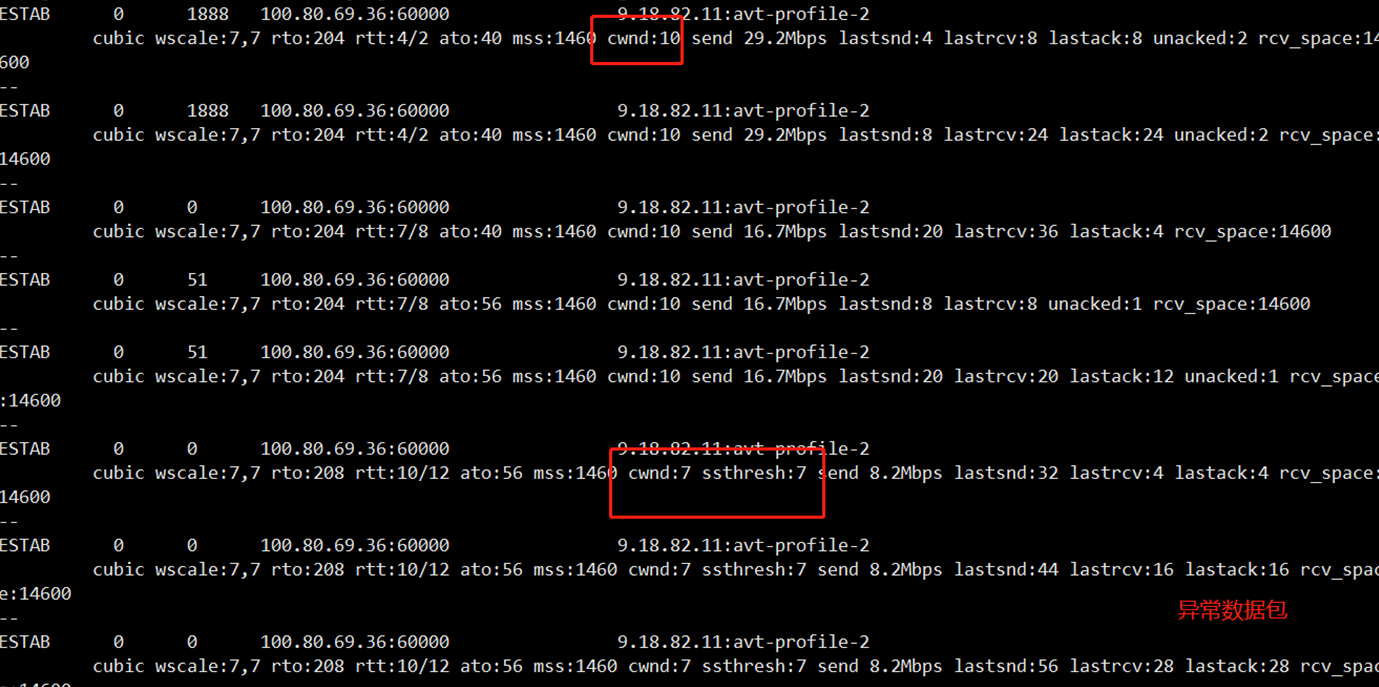
复现得到的 cwnd.log 如上图,找到对应的连接,grep 出来后对照来看。果然发现在前面几个包中,拥塞窗口就直接被置为 7,并且 ssthresh 也等于 7,并且可以看到后面窗口增加的很慢,直接进入了拥塞避免,这么小的发送窗口,增长又很缓慢,自然发送数据就会很慢了。
那么到底是什么原因导致这里直接在前几个包就进入拥塞避免呢?从现有的信息来看,没办法直接确定原因,只能去啃代码了,但 tcp 拥塞控制相关的代码这么多,如何能快速定位呢?
观察上面异常数据包的 cwnd 信息,可以看到一个很明显的特征,最开始 ssthresh 是没有显示出来的,经过了几个数据包之后,ssthresh 与 cwnd 是相等的,所以尝试按照"snd_ssthresh ="和"snd_cwnd ="的关键字来搜索,按照 snd_cwnd = snd_ssthresh 的原则来找,排除掉一些不太可能的函数之后,最后找到了 tcp_end_cwnd_reduction 这个函数。

再查找这个函数引用的地方,有两处:tcp_fastretrans_alert 和 tcp_process_tlp_ack 这两个函数。
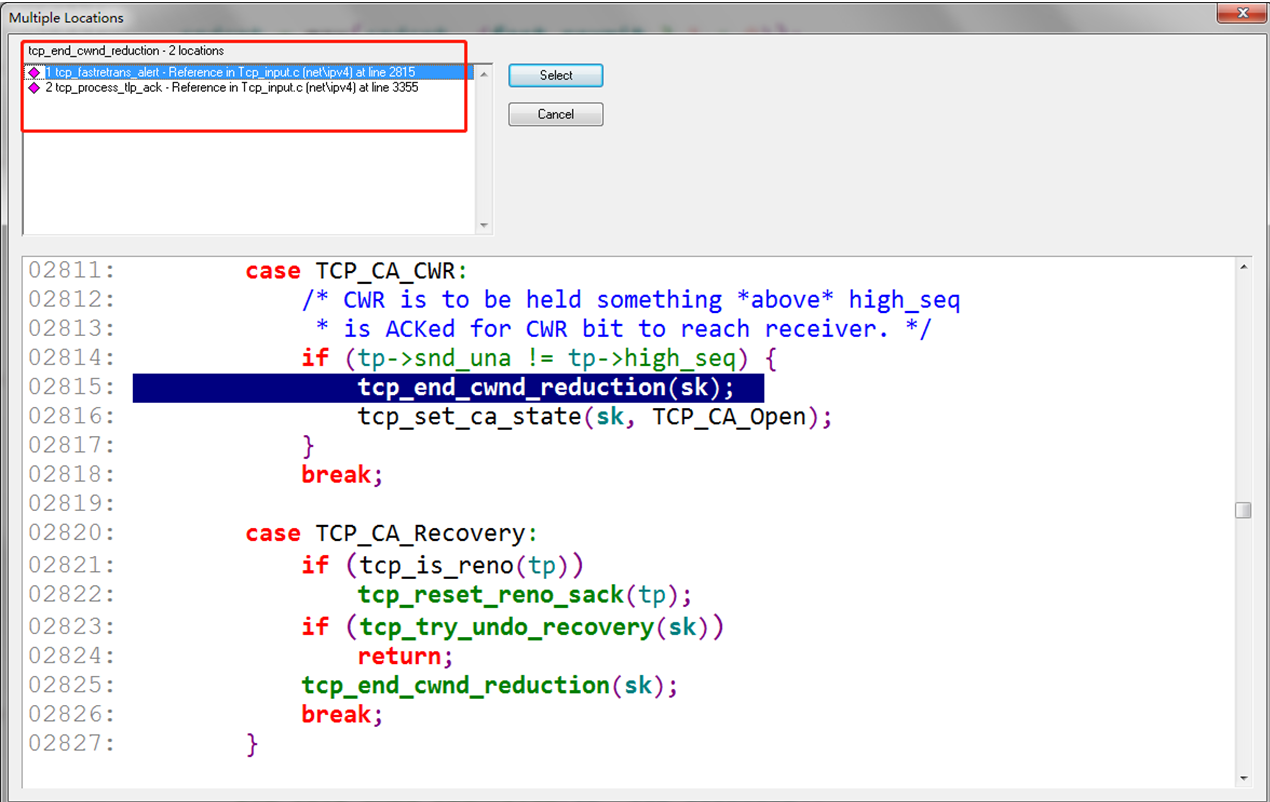
tcp_fastretrans_alert 看名字就知道是跟快速重传相关的函数,我们知道快速重传触发的条件是收到了三个重复的 ack 包。但根据前面的抓包及分析来看,并不满足快速重传的条件,所以疑点就落在了这个 tcp_process_tlp_ack 函数上面。那么到底什么是 TLP 呢?
什么是 TLP(Tail Loss Probe)
在讲 TLP 之前,我们先来回顾下大学课本里学到的拥塞控制算法,祭出这张经典的拥塞控制图。
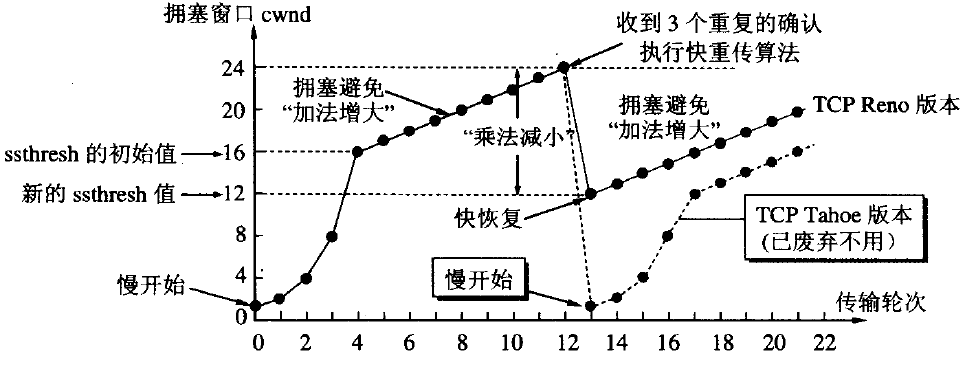
TCP 的拥塞控制主要分为四个阶段:慢启动,拥塞避免,快重传,快恢复。长久以来,我们听到的说法都是,最开始拥塞窗口从 1 开始慢启动,以指数级递增,收到三个重复的 ack 后,将 ssthresh 设置为当前 cwnd 的一半,并且置 cwnd=ssthresh,开始执行拥塞避免,cwnd 加法递增。
这里我们来思考一个问题,发生丢包时,为什么要将 ssthresh 设置为 cwnd 的一半?
想象一个场景,A 与 B 之间发送数据,假设二者发包和收包频率是一致的,由于 A 与 B 之间存在空间距离,中间要经过很多个路由器,交换机等,A 在持续发包,当 B 收到第一个包时,这时 A 与 B 之间的链路里的包的个数为 N,此时由于 B 一直在接收包,因此 A 还可以继续发,直到第一个包的 ack 回到 A,这时 A 发送的包的个数就是当前 A 与 B 之间最大的拥塞窗口,即为 2N,因为如果这时 A 多发送,肯定就丢包了。
ssthresh 代表的就是当前链路上可以发送的最大的拥塞窗口大小,理想情况下,ssthresh 就是 2N,但现实的环境很复杂,不可能刚好 cwnd 经过慢启动就可以直接到达 2N,发送丢包的时候,肯定是 N<1/2*cwnd<2N,因此此时将 ssthresh 设置为 1/2*cwnd,然后再从此处加法增加慢慢的达到理想窗口,不能增长过快,因为要“避免拥塞”。
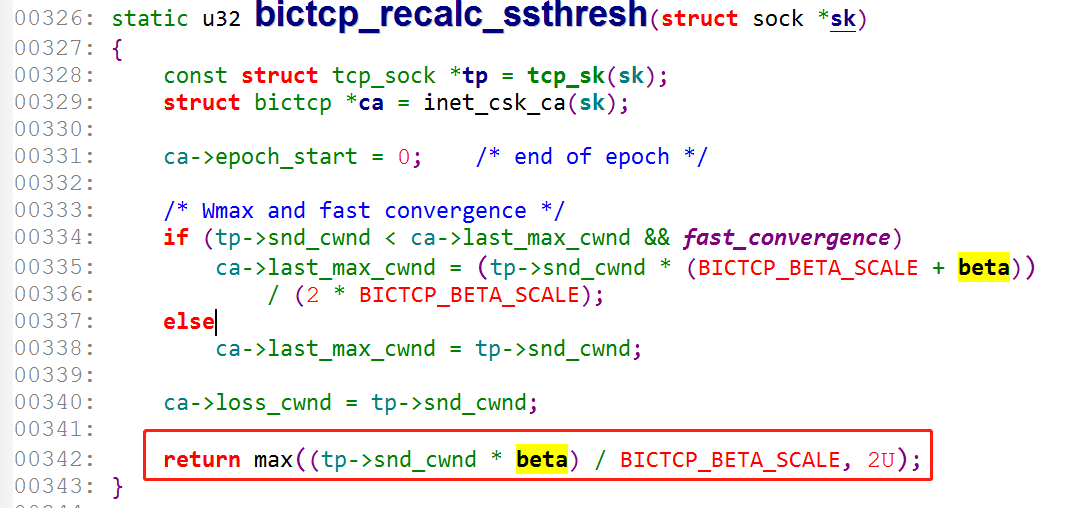

实际上,各个拥塞控制算法都有自己的实现,初始 cwnd 的值也一直在优化,在 linux 3.0 版本以后,内核 CUBIC 的实现里,采用了 Google 在 RFC6928 的建议,将初始的 cwnd 的值设置为 10。而在 linux 3.0 版本之前,采取的是 RFC3390 中的策略,根据不同的 MSS,设置了不同的初始化 cwnd。具体的策略为:
并且在执行拥塞避免时,当前 CUBIC 的实现里也不是将 ssthresh 设置为 cwnd 的一半,而是 717/1024≈0.7 左右,RFC8312 也提到了这样做的原因。
Principle 4: To balance between the scalability and convergence speed, CUBIC sets the multiplicative window decrease factor to 0.7 while Standard TCP uses 0.5. While this improves the scalability of CUBIC, a side effect of this decision is slower convergence, especially under low statistical multiplexing environments.
从上面的描述可以看到,在 TCP 的拥塞控制算法里,最核心的点就是 ssthresh 的确定,如何能快速准确的确定 ssthresh,就可以更加高效的传输。而现实的网络环境很复杂,在有些情况下,没有办法满足快速重传的条件,如果每次都以丢包作为反馈,代价太大。比如,考虑如下的几个场景:
是否可以探测到 ssthresh 的值,不依赖丢包来触发进入拥塞避免,主动退出慢启动?
如果没有足够的 dup ack(大于 0,小于 3)来触发快速重传,如何处理?
如果没有任何的 dup ack(等于 0),比如尾丢包的情况,如何处理?
是否可以主动探测网络带宽,基于反馈驱动来调整窗口,而不是丢包等事件驱动来执行拥塞控制?
针对上面的前三种情况,TCP 协议栈分别都做了相应的优化,对应的优化算法分别为:hystart(Hybrid Slow Start),ER(Early Retransmit)和 TLP(Tail Loss Probe)。对于第四种情况,Google 给出了答案,创造了一种新的拥塞控制算法,它的名字叫 BBR,从 linux 4.19 开始,内核已经将默认的拥塞控制算法从 CUBIC 改成了 BBR。受限于本文的篇幅有限,无法对 BBR 算法做详尽的介绍,下面仅结合内核 CUBIC 的代码来分别介绍前面的这三种优化算法。
1. 慢启动的 hystart 优化
混合慢启动的思想是在论文《Hybrid Slow Start for High-Bandwidth and Long-Distance Networks》里首次提出的,前面我也说过,如果每次判断拥塞都依赖丢包来作为反馈,代价太大,hystart 也是在这个方向上做优化,它主要想解决的问题就是不依赖丢包作为反馈来退出慢启动,它提出的退出条件有两类:
判断在同一批发出去的数据包收到的 ack 包(对应论文中的 acks train length)的总时间大于 min(rtt)/2;
判断一批样本中的最小 rtt 是否大于全局最小 rtt 加一个阈值的和;
内核 CUBIC 的实现里默认都是开启了 hystart,在 bictcp_init 函数里判断是否开启并做初始化
核心的判断是否退出慢启动的函数在 hystart_update 里
2. ER(Early Retransmit)算法
我们知道,快重传的条件是必须收到三个相同的 dup ack,才会触发,那如果在有些情况下,没有足够的 dup ack,只能依赖 rto 超时,再进行重传,并且开始执行慢启动,这样的代价太大,ER 算法就是为了解决这样的场景,RFC5827 详细介绍了这个算法。
算法的基本思想:
对应到代码里的函数为 tcp_time_to_recover:
delay ER 的定时器超时的处理函数 tcp_resume_early_retransmit。
内核提供了一个开关,tcp_early_retrans 用于开启和关闭 TLP 和 ER 算法,默认是 3,即打开了 delay ER 和 TLP 算法。
到此,这就是内核设计 ER 算法的相关的代码。ER 算法在 cwnd 比较小的情况下,是可以有一些改善的,但个人认为,实际的效果可能一般。因为如果 cwnd 较小,执行慢启动与执行快速重传再进入拥塞避免相比,二者的实际传输效率可能相差并不大。
3.TLP(Tail Loss Probe)算法
TLP 想解决的问题是:如果尾包发生了丢包,没有新包可发送触发多余的 dup ack 来实现快速重传,如果完全依赖 RTO 超时来重传,代价太大,那如何能优化解决这种尾丢包的情况。
TLP 算法是 2013 年谷歌在论文《Tail Loss Probe (TLP): An Algorithm for Fast Recovery of Tail Losses》中提出来的,它提出的基本思想是:
在每个发送的数据包的时候,都更新一个定时器 PTO(probe timeout),这个 PTO 是动态变化的,当发出的包中存在未 ack 的包,并且在 PTO 时间内都未收到一个 ack,那么就会发送一个新包或者重传最后的一个数据包,探测一下当前网络是否真的拥塞发生丢包了。
如果收到了 tail 包的 dup ack,则说明没有发生丢包,继续执行当前的流程;否则说明发生了丢包,需要执行减窗,并且进入拥塞避免。
这里其中一个比较重要的点是 PTO 如何设置,设置的策略如下:
对应到代码里的 tcp_schedule_loss_probe 函数:
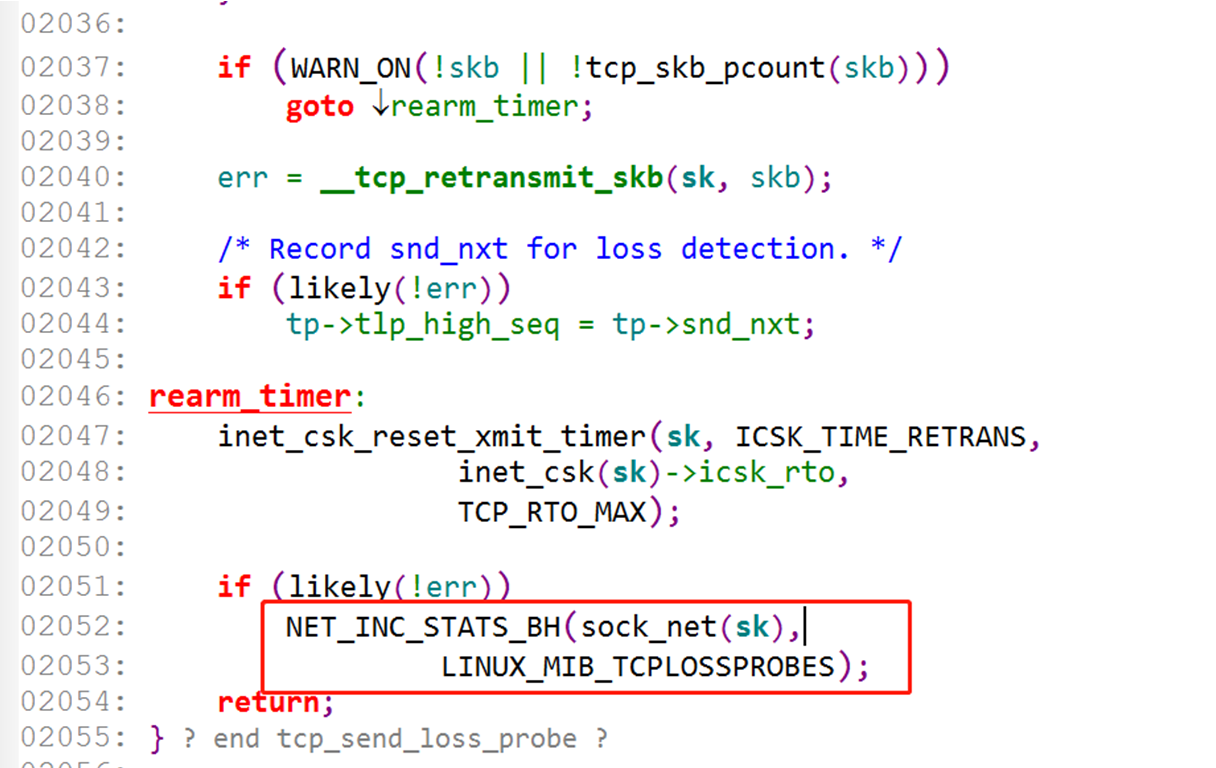
PTO 超时之后,会触发 tcp_send_loss_probe 发送 TLP 包:
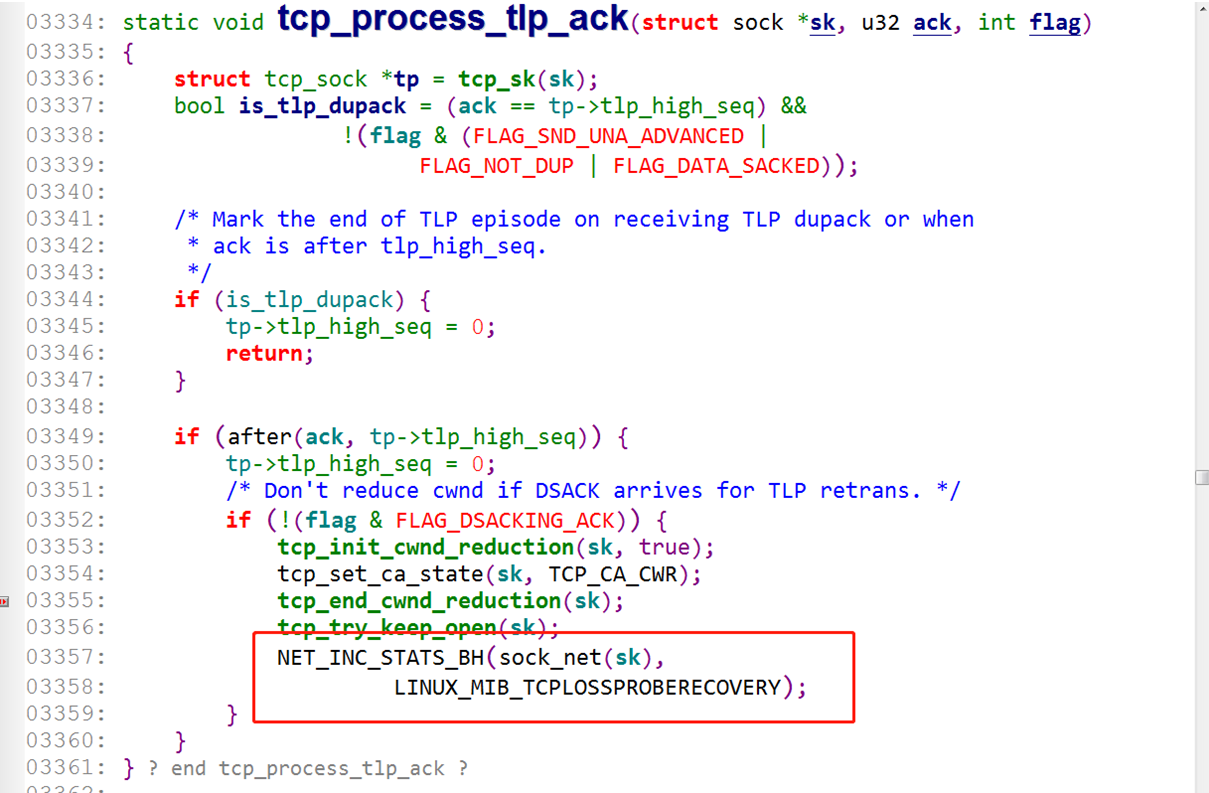
发送 TLP 探测包后,在 tcp_process_tlp_ack 里判断是否发生了丢包,做相应的处理:
TLP 算法的设计思路还是挺好的,主动提前发现网络是否拥塞,而不是被动的去依赖丢包来作为反馈。在大多数情况下是可以提高网络传输的效率的,但在某些情况下可能会"适得其反",而本文遇到的问题就是"适得其反"的一个例子。
问题的解决
回到我们的这个问题上,如何确认确实是由于 TLP 引起的呢?
继续查看代码可以看到,TLP 的 loss probe 和 loss recovery 次数,内核都有相应的计数器跟踪。

既然有计数器就好办了,复现的时候 netstat -s 就可以查看是否命中 TLP 了。写了个脚本将结果写入到文件里。
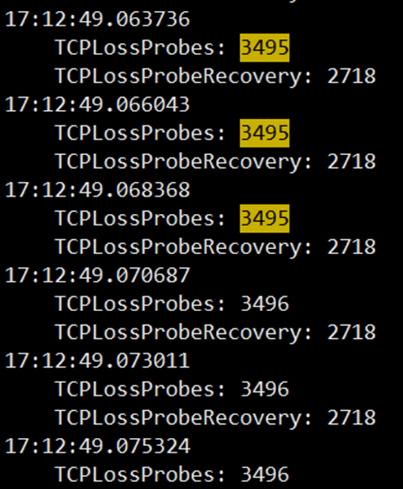
查看计数器增长的情况,结合抓包文件来看,基本确认肯定是命中 TLP 了。知道原因那就好办了,关掉 TLP 验证一下应该就可以解决了。
如上面介绍 ER 算法时提到,内核提供了一个开关,tcp_early_retrans 可用于开启和关闭 ER 和 TLP,默认是 3(enable TLP and delayed ER),sysctl -w net.ipv4.tcp_early_retrans=2 关掉 TLP,再次重新测试,发现问题解决了:
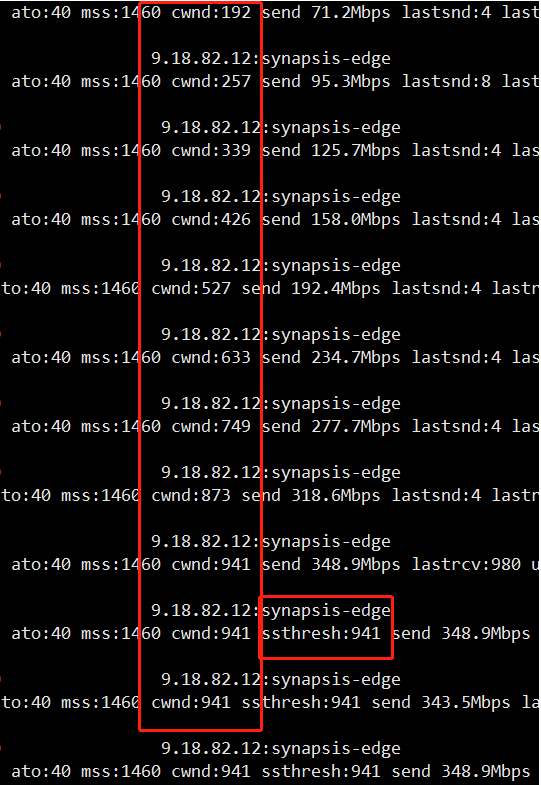
窗口增加的很快,最终的 ssthresh 为 941,下载速度 4s+,也是符合预期,到此用户的问题已经解决,但所有的疑问都得到了正确的解答了吗?
真正的真相
虽然用户的问题已经得到了解决,但至少还有两个问题没有得到答案:
1. 为什么会每次都在握手完的前几个包里就会触发 TLP?
2. 虽然触发了 TLP,但从抓包来看,已经收到了尾包的 dup ack 包,那说明没有发生丢包,为什么还是进入了拥塞避免?
先回答第一个问题,根据文章最前面的网络结构图可以看到,STGW 是挂在 TGW 的后面。在本场景中,用户访问的是 TGW 的高防 VIP,高防 VIP 有一个默认开启的功能就是 SYN 代理。
syn 代理指的是 client 发起连接时,首先是由 tgw 代答 syn ack 包,client 真正开始发送数据包时,tgw 再发送三次握手的包到 rs,并转发数据包。
在本例中,tgw 的 rs 就是 stgw,也就是说,stgw 的收到三次握手包的 rtt 是基于与 tgw 计算出来的,而后面的数据包才是真正与 client 之间的通信。前面背景描述中提到,用户同城访问(上海 client 访问上海的 vip)也是没有问题的,跨城访问就有问题。
这是因为同城访问的情况下,tgw 与 stgw 之间的 rtt 与 client 与 stgw 之间的 rtt,相差并不大,并没有满足触发 tlp 的条件。而跨城访问后,三次握手的数据包的 rtt 是基于与 tgw 来计算的,比较小,后面收到数据包后,计算的是 client 到 stgw 之间的 rtt,一下子增大了很多,并且满足了 tlp 的触发条件(PTO=max(2rtt, 10ms)),设置的 PTO 定时器超时了,协议栈认为是不是由于网络发生了拥塞,所以重传了尾包探测一下查看是否真的发生了拥塞,这就是为什么每次都是在握手完随后的几个包里就会有重传包,触发了 TLP 的原因。
再回到第二个问题,从抓包来看,很明显,网络并没有发生拥塞或丢包,stgw 已经收到了尾包的 dup ack 包,按照 TLP 的原理来看,不应该进入拥塞避免的,到底是什么原因导致的。百思不得其解,只能再继续啃代码了,再回到 tlp_ack 的这一部分代码来看。
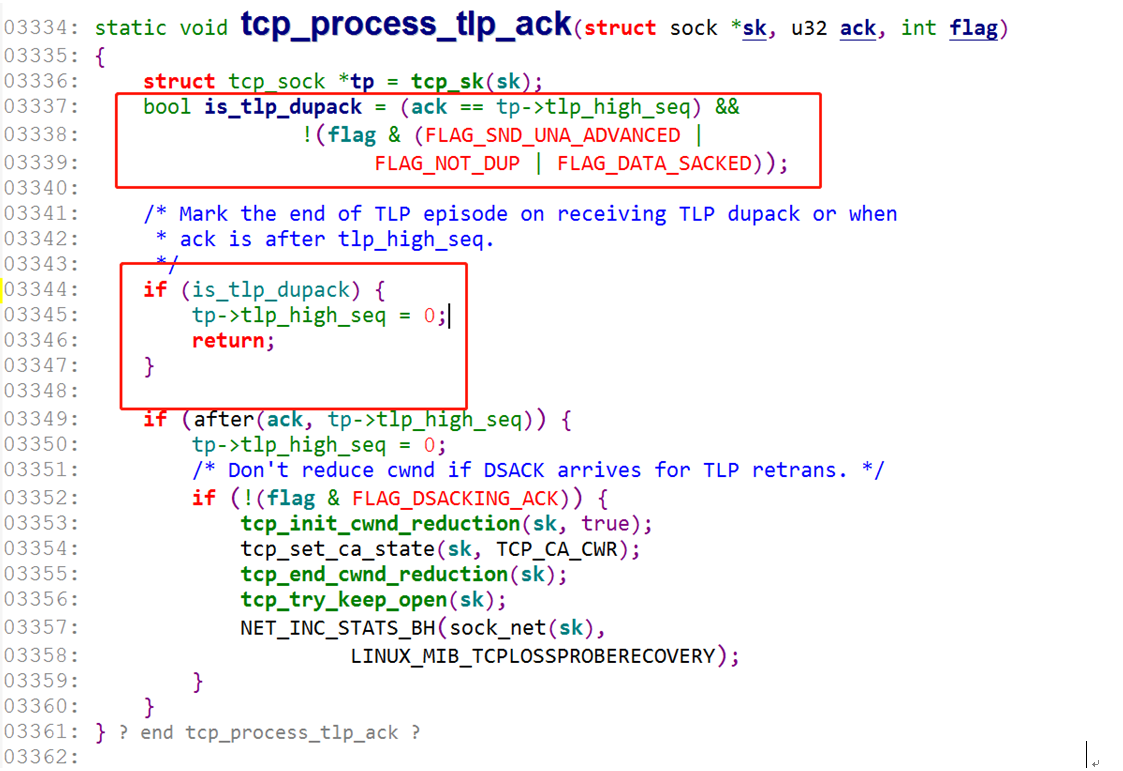
只有当 is_tlp_dupack 为 false 时,才会进入到下面部分,进入拥塞避免,也就是说这里 is_tlp_dupack 肯定是为 false 的。ack == tp->tlp_high_seq 这个条件是满足的,那么问题就出在了几个 flag 上面,看下几个 flag 的定义:
也就是说,只要 flag 包含了上面几个中的任意一个,都会将 is_tlp_dupack 置为 false,那到底 flag 包含了哪一个呢?如何继续排查呢?
调试内核信息,最常用的工具就是 ftrace 及 systemtap。
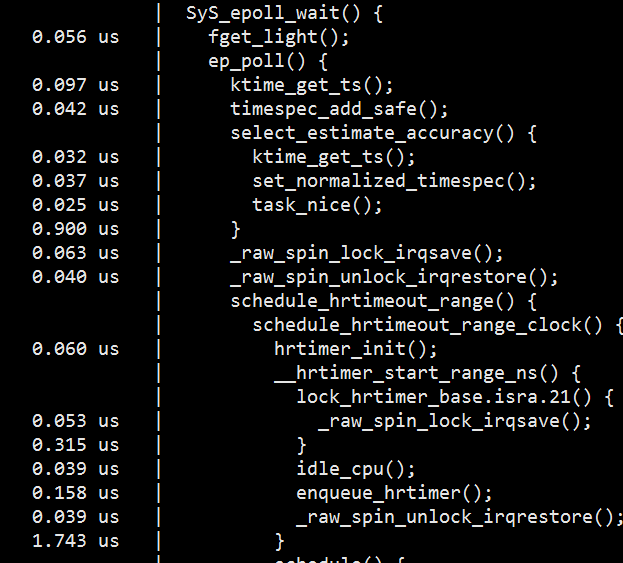
这里首先尝试了 ftrace,发现它并不能满足我的需求。ftrace 最主要的功能是可以跟踪函数的调用信息,并且可以知道各个函数的执行时间,在有些场景下非常好用,但原生的 ftrace 命令用起来很不方便,ftrace 团队也意识到了这个问题,因此提供了另外一个工具 trace-cmd,使用起来非常简单。
下图是使用 trace-cmd 跟踪的一个例子部分截图,可以看到完整打印了内核函数的调用信息及对应的执行时间。
但在当前的这个问题里,主要是想确认 flag 这个变量的值,ftrace 没有办法打印出变量的值,因此考虑下一个强大的工具:systemtap。
systemtap 是一个很强大的动态追踪工具,利用它可以很方便的调试内核信息,跟踪内核函数,打印变量信息等,很显然它是符合我们的需求的。systemptap 的使用需要安装内核调试信息包(kernel-debuginfo),但由于复现的那台机器上的内核版本较老,没有 debug 包,无法使用 stap 工具,因此这条路也走不通。
最后,联系了 h_tlinux_Helper 寻求帮助,他帮忙找到了复现机器内核版本的 dev 包,并在 tcp_process_tlp_ack 函数里打印了一些变量,并输出堆栈信息。重新安装了调试的内核,复现后打印了如下的堆栈及变量信息:
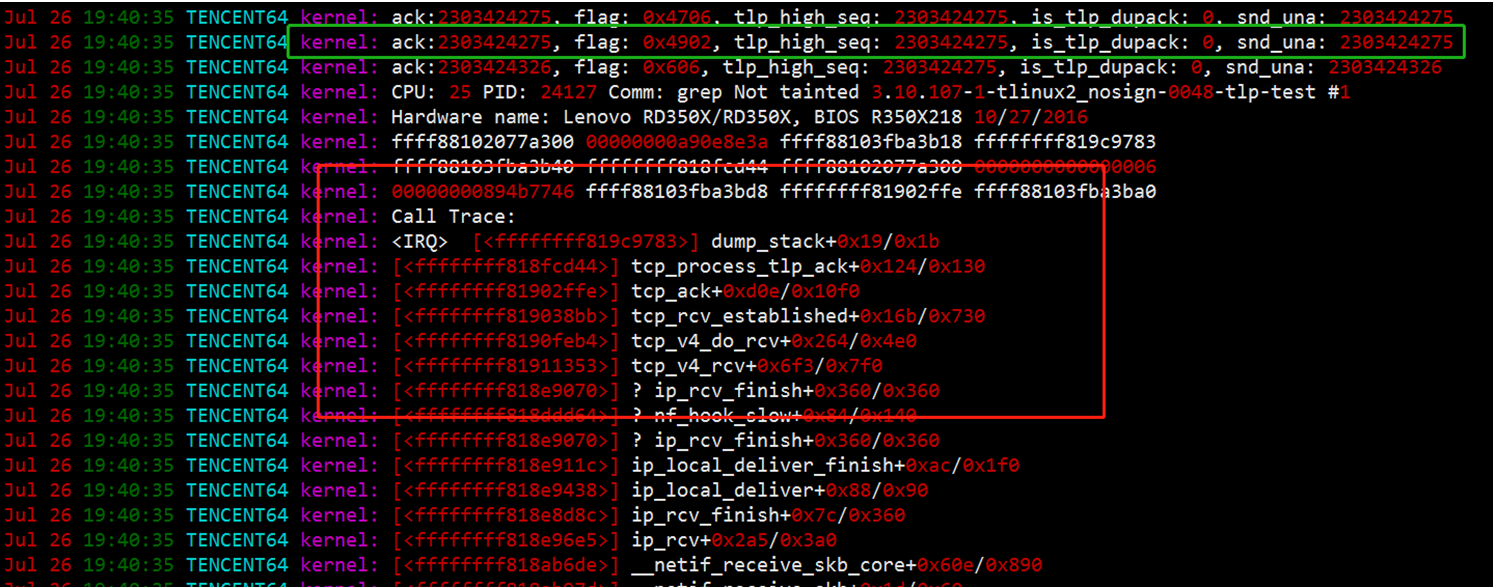
绿色标记处的那一行,就是收到的 dup ack 的那个包,可以看到 flag 的标记为 0x4902,换算成宏定义为:
再对照 tcp_process_tlp_ack 函数看一下,正是 FLAG_WIN_UPDATE 这个标记导致了 is_tlp_dupack = false。那在什么情况下,flag 会被置为 FLAG_WIN_UPDATE 呢?
继续看代码,对端回复的每个 ack 包基本会进入到 tcp_ack_update_window 函数。
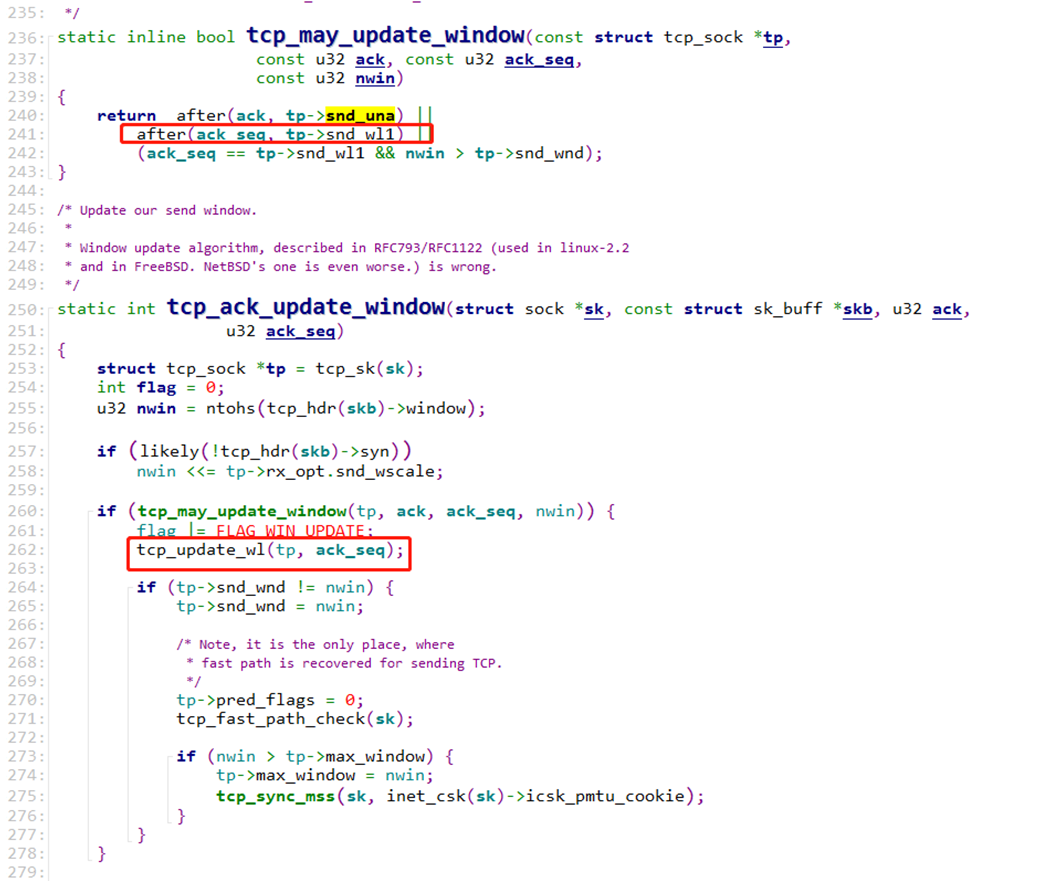
看到这里 flag 被置为 FLAG_WIN_UPDATE 的条件是 tcp_may_update_window 返回 true。
再看到 tcp_may_update_window 函数这里,after(ack_seq, tp->snd_wl1) 是基本都会命中的,因为不管窗口有没有变化,ack_seq 都会比 snd_wl1 大的,ack_seq 都是递增的,snd_wl1 在 tcp_update_wl 中又会被更新成上一次的 ack_seq。因此绝大多数的包的 flag 都会被打上 FLAG_WIN_UPDATE 标记。
如果是这样的话,那 is_tlp_dupack 不就是都为 false 了吗?不管有没有收到 dup ack 包,TLP 都会进入拥塞避免,这个就不符合 TLP 的设计初衷了,这里是否是内核实现的 Bug?
随后我查看了 linux 4.14 内核代码:
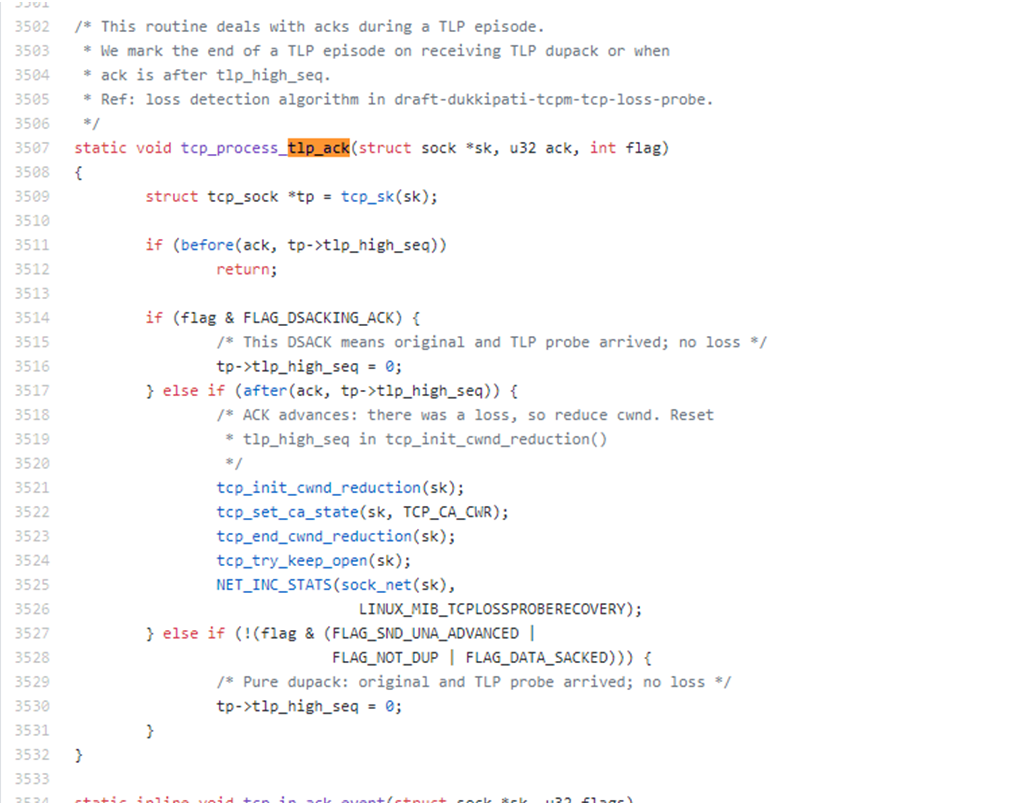
发现从内核版本 linux 4.0 开始,BUG 就已经被修复了,去掉了 flag 的一些不合理的判断条件,这才是真正的符合 TLP 的设计原理。
如果要避免这个问题,可以升级内核版本到 linux 4.0 及以上,或者 sysctl -w net.ipv4.tcp_early_retrans=2 关闭 TLP 特性。
到此,整个问题的所有疑点才都得到了解释。
总结
本文从一个下载慢的线上问题入手,首先介绍了一些常规的排查思路和手段,发现仍然不能定位到原因。然后分享了一个可以查询每条连接的拥塞窗口命令,结合内核代码分析了 TCP 拥塞控制 ssthresh 的设计理念及混合慢启动,ER 和尾包探测(TLP)等优化算法,并介绍了两个常用的内核调试工具:ftrace 和 systemtap,最终定位到是内核 TLP 实现 BUG 导致的下载慢的问题,从 linux 4.0 版本之后已经修复了这个问题。

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论 2 条评论