
斯坦福大学、SambaNova Systems 和加州大学伯克利分校的研究人员提出了智能体情境工程(Agentic Context Engineering,ACE),这是一个旨在通过演变、结构化的上下文而非权重更新来改进大语言模型(LLM)的新框架。在相关学术论文中,ACE 被详细阐述为一种无需重新训练即可使语言模型自我改进的方法。
基于 LLM 的系统通常依赖于提示词或上下文优化来提升推理能力和整体性能。虽然像 GEPA 和动态备忘单这样的技术在一定程度上改善了模型表现,但它们往往过度追求简洁性,这可能导致“上下文坍缩”现象,即在反复改写过程中丢失关键细节。ACE 通过将上下文视为一种随着时间推移,通过模块化生成、反思和策划逐步发展的动态剧本,成功地解决了这一问题。
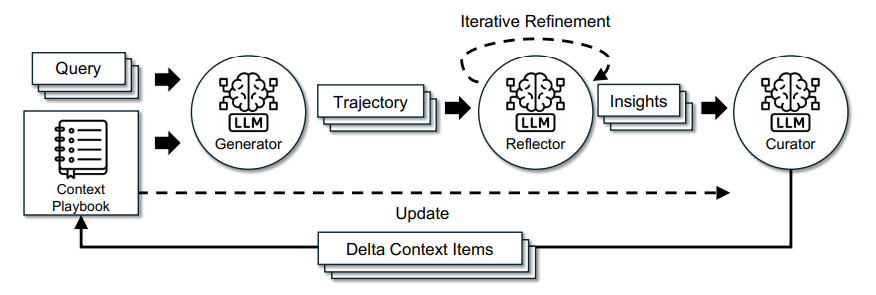
该框架将职责分配给三个关键组件:
生成器(Generator),生成推理追踪和输出
反思器(Reflector),分析成功和失败,从中总结经验教训
策划者(Curator),将这些经验教训作为增量更新进行整合
来源:https://www.arxiv.org/pdf/2510.04618
与传统的重写完整提示词不同,ACE 采用了增量更新策略,即局部编辑,积累新见解的同时保留先前的知识。此外,ACE 引入了一种独特的“生长与精炼”机制,通过基于语义相似性的分析合并或修剪上下文项目来管理扩展和冗余。
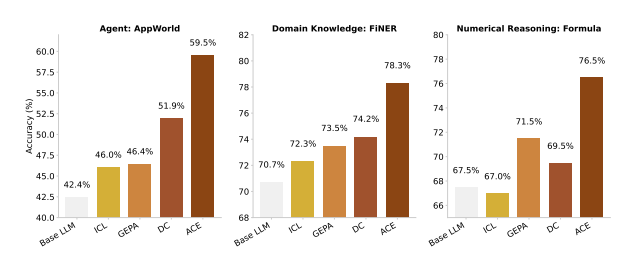
在性能评估中,ACE 在智能体任务和特定领域任务上均展现出了显著的性能提升。在 AppWorld 基准测试中,ACE 平均准确率达到 59.5%,比先前的方法高出 10.6 个百分点,并与公共排行榜上的顶级条目——一个基于 GPT-4.1 的 IBM 智能体不相上下。在金融推理数据集(如 FNER 和 Formula )上,ACE 实现了平均 8.6%的性能提升,尤其在有真实反馈的情况下,其表现尤为出色。
来源:https://www.arxiv.org/pdf/2510.04618
作者强调,在多数情况下,ACE 所实现的性能提升并未借助模型微调或标记监督,而是依靠诸如任务结果、代码执行结果等自然信号来驱动优化。他们报告称,相较于 GEPA 等既定基线方法,ACE 显著降低了适应延迟,降幅高达 86.9%,同时将计算展开量减少了 75% 以上。
研究人员指出,这种方法使模型能够通过上下文更新实现“学习”,同时保持可解释性——这对于金融或医疗保健等透明度和选择性遗忘至关重要的领域来说是一种优势。
社区对该研究的反应十分积极。例如,一位 Reddit 用户分享了自己的看法:
这确实令人振奋。这种方法看起来是一种更加智能的情境工程策略。如果将其与后处理以及其他模型开发中的“低垂果实”相结合,我相信我们将会看到更具性价比的改进。
ACE 证明了借助结构化且动态演变的上下文能够实现大语言模型的可扩展自我优化,为无需重新训练的持续学习开辟了一条全新的替代路径。
【声明:本文由 InfoQ 翻译,未经许可禁止转载。】
查看英文原文:https://www.infoq.com/news/2025/10/agentic-context-eng/




